
【準備編】低スぺPCでもStableDiffusionでAIお絵描きを楽しんじゃおう!(NVIDIA GeForce GTX1650 VRAM4GB)


がっつりAIお絵描きにハマってしまいました。。。
GoogleColabが使えなくなり、お金のない私は最低スペックのローカル環境で使うことを余儀なくされました、が結構楽しめてるのでみんなもやってみよう、というお話。
Colabに1000円課金するお金あったら家族の夕飯つくれちゃうもんね。(投げ銭;;)
・ネギ塩豚丼最後に炙って温玉のせる
・えだまめとカニカマの茶わん蒸し
・キャベツの千切りに新玉ねぎの食べる玉ねぎドレッシング
・豆腐とわかめの味噌汁
子供のフォートナイト用に購入した最低限のスペックのゲーミングノートPCで私なりのAIお絵描きの楽しみ方を伝えたいと思います。
PCのスペックが低いので超高画質高解像度の作品は作れませんが、十分に満足のいく素敵なイラストは生成できるので、低スぺPCの皆様もがんばってみて下さい。パソコン新調とかお金かかりますからね。
ちなみに今のところイラスト特化です、エッチなのも興味ありません。


StableDiffusionのインストールから設定までの流れ(5/14/2023)

画像生成AIはその名の通りAIが画像を作成してくれるものですが、使ったことがない人が想像すると思われるいわゆる「AIに簡単な指示を出して生成ボタン一発ポン」で素敵な画像ができるものではありません。
各種設定やこまごまとしたパラメータ、沢山の機能拡張などを使いこなしてはじめてイラストレーターさん(には遠く及ばないと思いますが)のような画像が生成できます。そこで、低スぺでも満足する結果を出すために必要だと思われる設定など、画像作成の前段階までをここでは解説していきたいと思います。

🧁StableDiffusionのインストール

Pythonなにそれ?Gitなにそれ?という方のために、最近はスタンドアロン型というんでしょうか?PythonもGitも別途インストールしなくていいインストーラー型のものがあるのでそれでインストールしていくと簡単です。
▶ https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases ◀
リンク先からv1.0.0-preを探して▲Assetsの中のsd.webui.zipをダウンロードしてインストールしていけば大丈夫です。
詳しい使い方は下記のBlogで紹介されていたので参考にしてください。
v1.0.0なので最新版ではないんじゃないかと心配になると思いますが、出来上がったStableDiffusionフォルダにupdate.batがついているのでそちらを起動すると最新版にupdateできますので心配ないです。
通常起動するときはrun.batでStableDiffusionを起動します。

🧁WebUIの設定

●起動オプション
💡低スぺPoint💡
"C:\*****\StableDiffusion\webui\webui-user.bat"
↑のファイルをノートブックなどのテキストエディタで開いて該当箇所を書き換えます。
set COMMANDLINE_ARGS= --autolaunch --precision full --no-half --lowvram --opt-split-attention --xformers
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6, max_split_size_mb:128参考にしたのはこちらのサイトです。
lowvramの部分をmedvramに書き換えると生成時間は早くなるのですが、512×512あたりが限界です、ちょっとLoRAを適用したりすると512×512でもエラーになります。
なので最初から潔くlowvramでいくとよいと思います。ちなみにlowvramは生成に時間がかかりますが所詮低スペックで生成できるサイズでやるのでたかが知れてます。

●UIの設定
Settingsの中のUser Interfaceに[info] Quicksettings listというのがあります。こちらにsd_vaeを追加します、記入するだけです。設定を適用し、リロードすると画面一番上、Stable Diffusion checkpointのプルダウンの並びにVaeを選択するプルダウンが表示されるので便利というか絶対やったほうがいいと思います。

User Interfaceの設定としてはGradio theme (requires restart)でテーマカラーを変更できます。白背景はチカチカするので、黒系にすると良いです。
それから設定の中のStableDiffusionにあるIgnore selected VAE for stable diffusion checkpoints that have their own .vae.pt next to themのチェックを外すのと、Clip skipを2にするともっと良いかと思います。

🧁Model,VEAのダウンロード

●Model/Checkpointをダウンロード
Model/Checkpointは絵柄事に使い分けます。ここではイラストを作成したいのでイラスト系のモデルをダウンロードします。
この2つのサイトにたくさんのモデルがあるのですが、civitaiのほうが探しやすいです。
💡低スぺPoint💡
ここで低スぺの皆様はSD1.5基準のモデルを使ってください。SD2基準だと標準サイズが大きくlowvramでも作成できる画像は512×640程度です。
そして出来ればVAE内臓のものを選ぶとメモリの節約になります。
とりあえず最初は有名どころのCounterfate2.5をダウンロードしてみたいと思います。(vaeもtextualinversionも揃っていて初歩にちょうどよいため)
↑こちらのHuggingFaceのページからFiles and Versionsのタブ行ってもらって
Counterfeit-V2.5_fp16.safetensors
Counterfeit-V2.5.vae.pt
この二つをダウンロードします。一つは本体、vaeと書かれているのは画質を良くするための補助です。
ダウンロードしてきたモデル本体は↓のフォルダの中に入れます。
"C:\*****\StableDiffusion\webui\models\Stable-diffusion\"
Vaeはこちらのフォルダの中です↓
"C:\*****\StableDiffusion\webui\models\VAE\"
ちなみにVAEがモデルそのものに含まれている場合や、専用vaeがないので適当に合わせて使うモデルなどいろいろあります。

さて、モデルとVAEをインストール出来たと思うのでWebUIで読み込んで早速生成してみましょう。promptは1girlのみです。



2枚を比べると結構違いますよね、Modelをダウンロードしたけどなぁーんか色に乏しい、、、くすんでて灰色っぽいんだけど、と思ったらVaeが必要な場合がありますので覚えておいてください。

🧁EasyNegativeのダウンロード

画像の生成はできたけど、なんか微妙、、、いや、1girlしかPrompt指定してないのであたりまえっちゃ当たり前なのですが、ここで便利なのがEasyNegativeです。こういうのはダメっていう集合体。
↑こちらのページからFiles and Versionsタブを開きEasyNegative.safetensorsをダウンロードします。
ダウンロードしたファイルは↓のフォルダに入れます。
"C:\*****\StableDiffusion\webui\embeddings\"

それでは使ってみましょう、画像生成ボタンの下にある花札ボタンを押します。するとタブが開きますのでtexualinversionの中のEasyNegativeを確認します。
NegativePrompt欄にカーソルを合わせてEasyNegativeを押すとNegativePromtにEasyNegativeと出てくると思います。これだけで適用されます、では生成してみましょう。
Promptは1girl、NegativePromptにはEasyNegativeです。

(EasyNegative:1.5)と書くともっと強くなります。画像がさらに明るくなりましたね。

他にもbadhandやdeepnegativeなどもあります。EasyNegativeもVersion2があるようです、組み合わせて使っても大丈夫です。

何個か適用させてみました。ちょっと詳細な書き込みが増えたでしょうか?指も整った感じがしますね。

🧁LoRAのダウンロード

LoRAは既存のモデルの上から特定の絵柄を追加で上乗せしてくれるものです。イラストのスタイルだったり、特定のキャラだったり、色味だったり、それはそれはたくさんのLoRAが配布されています。
civitaiは絵柄から探すことができますのでとても使いやすいです。
ここで低スぺおすすめのLoRAを紹介します、ダウンロードしておきましょう。
💡低スぺPoint💡
これは画像の書き込みを量を増やしてくれるLoRAです。高解像度で出力できない低スぺには必須なのではないかと思います。
ほぼ同じ(正反対?)のLoRAで日本人作者のFlat2というのがありますが、描きこみ量を増やすために使う場合は、名前が紛らわしいので上で紹介したDetailTweakerで良いと思います。名前の通り<lora:add_detail:1>とPrompt欄に描きこむとで詳細を描き込み、<lora:add_detail:-1>でフラットになります。
ダウンロードしたLoRAは↓のフォルダに入れます。
"C:\*****\StableDiffusion\webui\models\Lora\"
LoRAを使用するには生成ボタンの下の花札ボタンからLoRAタブを開き、クリックするとPrompt欄に入るので、そのまま生成するだけです。
Minimalist Anime Styleという超オシャンなLoRAもマイナス指定すると画像の情報量が増えるようです。いろいろありますね。

では、先ほどのDetailTweakerを適用して画像を生成してみます。

どうですか?だいぶ詳細が描き込まれて512×512の画像なのに十分可愛く生成できてますよね?
ここまで来たらStableDiffusionのインストールから設定編はあと少しで完了です。

🧁ControlNetのインストール

最後にいきなりですが、低スぺPCの弱みは何だと思いますか?
大きな画像が作れないので詳細が描きこまれない!というのはEasyNegativeをちょいと強めに使う&詳細な描き込みはLoRAを適用する事でなんとかごまかすことが出来ますが、他にもガチャが回せない!というのがあります。
要は、同じプロンプトで一気に何十枚出力するとかができないわけです。1回とか2回とかで勝負しなくてはならないのです。
💡低スぺPoint💡
そこで、指定したいポーズや構図がある場合はControlNetを使うのが確実で良いと思います。
ガチャガチャでPromptがうまく反映されるのを期待するより、決め打ちで出してあげることが出来ます。
ここではポーズを指定できるOpenPoseを使ってみることとします。
インストールなど結構複雑なので↓のサイトを参考にしてください。詳しく紹介されています。
先ほどと同じPromptでOpenPoseを適用した画像になります。Promptでポーズを指定しなくても決め打ちできます。顔が小さくなる分崩れますが仕様です。後でちょっと画像を拡大するときになんとか修正できます。

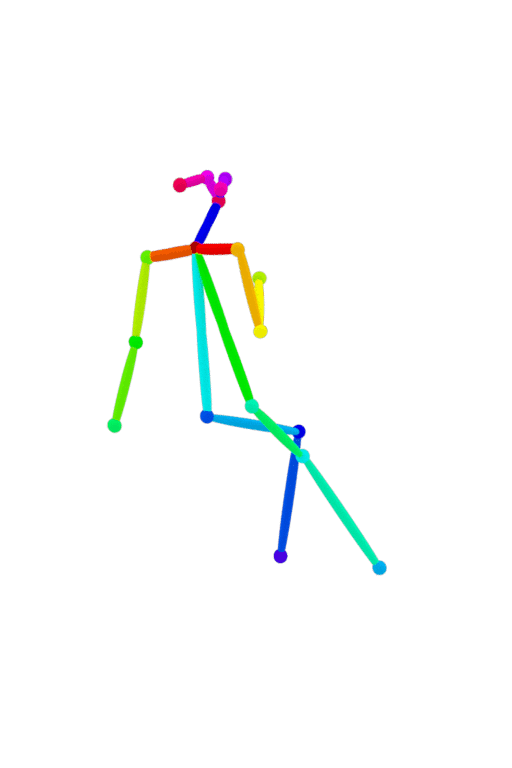
棒人間は自分で作成しなくても↓でダウンロードすることが出来ますよ。Filterの中にPosesってのがあります。

🧁アップスケーラーのインストール

💡低スぺPoint💡
画像を拡大すると同時に詳細な書き込みが増えるのですが、拡大にはマシンパワーが必要です。標準のものだとすぐエラーになるので、Scriptから使えるようになるUltimateSDUpscalerを使用しています。
アップスケーラーは何種類かありますが、これが一番メモリエラーが出なかったです。
下記ブログを参考にしてください。

次回はイラストを実際に生成してみるよ!

お疲れさまでした。以上で低スぺPCでも楽しくお絵描きができる準備ができました。
次の投稿では実際に画像を生成していきたいと思います。
▼こんなイラストを一緒に作っていきたいと思います。

いいなと思ったら応援しよう!
