
bzip2を読む ブロックソート10

こんにちは、junkawaです。
本記事では、前回に続きブロックソートアルゴリズムの「巡回行列のソート」についてソースコードを交えて紹介します。
これまでの記事
https://note.mu/junkawashima/m/m3adbdc56f010
前回までのおさらい
ブロックソートでは巡回行列のソートが必要です。
前回までは、ソートを行うmainSort()の紹介を行いました。
本記事では、mainSort()の代替となるfallbackSort()を紹介します。
入力データブロックサイズが10,000バイト未満の場合、入力データ中に同じシンボル、パターンの繰り返しが多く含まれている場合、mainSort()ではなくfallbackSort()を使用して、巡回行列のソートを行います。
ソースコード紹介
fallbackSort()@blocksort.c
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L212
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L191
〜
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L329
図中のビット表現は、左側を低位ビットとして表記しています。
191: /*---------------------------------------------*/
192: /* Pre:
193: nblock > 0
194: eclass exists for [0 .. nblock-1]
195: ((UChar*)eclass) [0 .. nblock-1] holds block
196: ptr exists for [0 .. nblock-1]
197: 
eclass8[0..nblock-1]に入力データが入っています。
196行目のptrとは、fmapのことです。
198: Post:
199: ((UChar*)eclass) [0 .. nblock-1] holds block
200: All other areas of eclass destroyed
201: fmap [0 .. nblock-1] holds sorted order
202: bhtab [ 0 .. 2+(nblock/32) ] destroyed
203: */
204: 
fmapにソート結果が入ります。
eclass8[0..nblock-1]は一時的に破壊され、eclass[0..nblock-1]として扱われますが、関数の最後で復元されます。
bhtabへのアクセスが、確保したメモリ領域を超えないか
bhtab[0..2+nblock/32]の領域を使用します。
nblockが最大900,000だとして、8+nblock/8は、112501。Uint32の配列要素数にすると、112501/4で28126。これは65537以下なので bhtabは十分な領域です。
205: #define SET_BH(zz) bhtab[(zz) >> 5] |= (1 << ((zz) & 31))bhtab配列のzzビット目にフラグを立てる。
206: #define CLEAR_BH(zz) bhtab[(zz) >> 5] &= ~(1 << ((zz) & 31))bhtab配列のzzビット目のフラグをクリアする。
207: #define ISSET_BH(zz) (bhtab[(zz) >> 5] & (1 << ((zz) & 31)))bhtab配列のzzビット目のフラグがセットされているか確認する。
208: #define WORD_BH(zz) bhtab[(zz) >> 5]zzビット目が含まれるbhtab配列の値(4バイト)を取得する。
209: #define UNALIGNED_BH(zz) ((zz) & 0x01f)
210: zzが32の倍数の時に0、32の倍数以外の時に非0となります。
211: static
212: void fallbackSort ( UInt32* fmap,
213: UInt32* eclass,
214: UInt32* bhtab,
215: Int32 nblock,
216: Int32 verb )
217: {
218: Int32 ftab[257];
219: Int32 ftabCopy[256];
220: Int32 H, i, j, k, l, r, cc, cc1;
221: Int32 nNotDone;
222: Int32 nBhtab;下で紹介します。
223: UChar* eclass8 = (UChar*)eclass;
224: eclass8は入力データを1バイトずつアクセするために使用します。
225: /*--
226: Initial 1-char radix sort to generate
227: initial fmap and initial BH bits.
228: --*/巡回行列の各行の先頭バイトで基数ソートを行い、fmapとBHビットの初期設定を行います。
229: if (verb >= 4)
230: VPrintf0 ( " bucket sorting ...\n" );基数ソート(バケツソート)していることを出力します。
231: for (i = 0; i < 257; i++) ftab[i] = 0;
232: for (i = 0; i < nblock; i++) ftab[eclass8[i]]++;入力データブロック eclass8 に含まれる各シンボルの出現回数をftabに記録します。
シンボル i の出現回数は ftab[i] となります。
シンボルの出現回数は、そのシンボルから始まる行の数と同じです。
233: for (i = 0; i < 256; i++) ftabCopy[i] = ftab[i];出現回数をftabCopyにftabの内容を退避します。
234: for (i = 1; i < 257; i++) ftab[i] += ftab[i-1];
235: ftab[i]にftab[0]、ftab[1]、...、ftab[i-1]を加算します。

図では、232行目後のftabを積算前ftab、234行目後のftabを積算後ftabとしています。
積算後ftab[i]-1は、fmap上で、シンボルiから始まる行の先頭ブロック番号をセットする位置の末尾を指します。
これは、巡回行列の各行の先頭シンボルでソートする際の、バケツソートの各バケツの末尾となります。
236: for (i = 0; i < nblock; i++) {
237: j = eclass8[i];
238: k = ftab[j] - 1;
239: ftab[j] = k;
240: fmap[k] = i;
241: }
242: 先頭バイトでソートした結果のfmapの先頭インデックスがftabに入ります。
fmapは(mainSortのptrに相当します)。先頭バイトでソートした結果のブロック番号が順に入ります。

図では i=15の時、eclass8[15] が 2 なので、237行目でj=2となり、238行目のk=ftab[2]-1より k=17-1でk=16となります。
239行目でftab[2]=16と更新し、240行目でfmap[16]=15としてソート結果を格納しています。
図の例では、eclass8[15]のように、2から始まる行は巡回行列中に5個あるとしています。この5個を格納する場所をfmap上に確保するためにftabを利用しています。
具体的にはfmap[2]が17で、fmap[1]が12なので、13〜17の間に2から始まる行のブロック番号をセットします。
ここまでで、先頭シンボルでのソートが完了しました。
i=0から昇順にeclass8を見て、後ろから入れてるので安定ソートではなくなります。
mainSort()の最初の計数ソートは安定ソートだったので、mainSort()とfallbackSort()では異なるソート順になるかもしれません。
しかし、その場合もBWT後文字列に変更はないので圧縮に問題はないと思われます。
243: nBhtab = 2 + (nblock / 32);nBhtabは、244行目でbhtabの初期化に使用する、配列の最大インデックスです。
fmap[i] の iに対応するビットをbhtabにセットします。
iは0以上nblock未満となります。bhtabはUInt32型の配列なので、bhtab[0]には32bit入ります。
したがって、bhtab[nblock/32+1] だけ必要となります。
また、254行で (nblock+63)ビットまでアクセスしているため、nBhtab = 2 + (nblock/32) まで初期化していると思われます。
(厳密にはnblock+63ビットまで初期化するには 3+ (nblock/32)が必要ですが...)
244: for (i = 0; i < nBhtab; i++) bhtab[i] = 0;hbtabを0で初期化します。
245: for (i = 0; i < 256; i++) SET_BH(ftab[i]);
246: ftabの値に対応する位置に、 bhtab のビットを立てます。

fmapは、バケツソートした結果を格納しています。
236行目のforループにより、各行の先頭シンボルによるソートは完了しています。
図では、fmap[0..9]に、先頭シンボルが0である行の番号が入っています。
ここで、fmap[0..9]を先頭シンボル0のバケツ、fmap[10,11]を先頭シンボル1のバケツ、fmap[12..16]を先頭シンボル2のバケツ、... と呼ぶようにします。
bhtabは、バケツの先頭インデックスを見つけるために使用します。
bhtabのビットが1の位置がバケツの先頭インデックスに対応します。
図では、0ビット目、10ビット目、12ビット目、17ビット目、25ビット目が1となっており、fma[0]、fmap[10]、fmap[12]、fmap[17]、fmap[25]がバケツの先頭であることを示しています。
247: /*--
248: Inductively refine the buckets. Kind-of an
249: "exponential radix sort" (!), inspired by the
250: Manber-Myers suffix array construction algorithm.
251: --*/
252: 論文 Suffix Arrays: A new method for on-line string searches. Udi Manber; Gene Myers. May 1989. を参考に、指数関数的にソート対象の先頭シンボル数を増やして、基数ソートを行います。
253: /*-- set sentinel bits for block-end detection --*/
254: for (i = 0; i < 32; i++) {
255: SET_BH(nblock + 2*i);
256: CLEAR_BH(nblock + 2*i + 1);
257: }
258: 
バケツの終端検知用にフラグをセットします。
バケツの先頭にフラグを立てて、バケツの終端を検出しますが、最後のバケツは終端を検出できなくなるため、nblockビットを立てて、検出できるようにしています。
最長でアクセスされるのは、おそらく 281 行目で k が nblock となる時です。
この時、WORD_BH(k)により、nblock〜nblock+31ビットにアクセスされます。
nblock+32〜nblock+63が何のために用意されているのかは不明です。
259: /*-- the log(N) loop --*/
260: H = 1;ここまでで、先頭シンボルでのソートは完了しています。
H=1の時、先頭シンボルと2バイト目のシンボル(先頭から2バイト)で基数ソートを行います。
331行目で、H*=2されます。
H=2の時、先頭から4バイトで基数ソートを行います。
H=4の時、先頭から8バイトで基数ソートを行います。
以下、H=8,16,32… の場合にHがnblockを超えるか、ソート対象がなくなるまで(312行目のif文)、同様に基数ソートを行います。
261: while (1) {
262: Hを増加して基数ソートを行うためのループです。
263: if (verb >= 4)
264: VPrintf1 ( " depth %6d has ", H );
265: 今回のループのHを表示します。
266: j = 0;
267: for (i = 0; i < nblock; i++) {
268: if (ISSET_BH(i)) j = i;
269: k = fmap[i] - H; if (k < 0) k += nblock;
270: eclass[k] = j;
271: }
272: 268行目でセットされるjは、ISSET_BH(i)がtrueの時にセットされるので、バケツの先頭インデックスiとなります。
269行目。H=1の時、ブロック番号 k から始まる行は、先頭シンボルでソート済みです。
jには、ブロック番号fmap[i]から始まる行の先頭バイトのシンボルが属するバケツの先頭インデックスが入っています。
k = fmap[i] - 1なので、eclass[k] にはブロック番号kから始まる行の2バイト目のシンボルが属するバケツの先頭インデックスjが入っています。
H=1の時、すでに行の先頭バイトでバケツにソートなので、2バイト目以降で比較を行いたいです。ここでは、2バイト目を比較してソートを行います。
kから始まる行の2バイト目(fmap[i])については、fmap[i]から始まる行がすでにソート済みなので、その情報 j (fmap[i]が属するバケツの先頭インデックス)を使ってソートを行います。kから始まる行の比較にjを使うので、270行目でeclass[k]にjをセットしています。
つまりバケツの先頭インデックスで比較を行うことで、大小関係を比較できます。
eclass[k]に2バイト目のシンボルが属するバケツの先頭インデックスが入っているので、eclassを比較することで2バイト目を比較することができます。
これでH=1の時、先頭2バイトでソートを行います。
H=2の時、ブロック番号 k から始まる行は、先頭2バイトでソート済みです。また、fmap[i]から始まる行も、先頭2バイトでソート済みです。
jには、ブロック番号fmap[i]から始まる行の先頭2バイトが属するバケツの先頭インデックスが入っています。
k = fmap[i] - 2なので、eclass[k] にはブロック番号kから始まる行の3,4バイト目のシンボルが属するバケツの先頭インデックスjが入っています。
H=2の時は、先頭2バイトがソート済みなので、3バイト目以降で比較したいです。ここでは、3,4バイト目を比較してソートします。
kから始まる行の3,4バイト目は、3バイト目から始まる行(fmap[i]から始まる行)としてすでにソート済みなので、そのソート済み情報 j (fmap[i]が属するバケツの先頭インデックス)を使ってソートします。kから始まる行の比較にjを使うので、270行目でeclass[k]にjをセットしています。
このようにしてH=2の時、3,4バイト目でソートを行うので、結果として先頭4バイトでのソートが完了します。
H=4の時も同様です。
kから始まる行の1,2,3,4バイト目でのソートが完了しているので、5,6,7,8バイト目でソートを行います。5バイト目(fmap[i])から始まる行はすでにソート済みなので、そのソート済み情報(fmap[i]が属するバケツの先頭インデックス) j を使ってソートします。
H=8の時も同様に行い、このように、Hが1,2,4,8と指数関数的に増加していきます。
270で入力データブロックeclass8の領域を壊していますが、326行目で戻します。
eclass8の情報はfmapとftabCopyから復元できます。ここではeclass8の領域を入力データとは別の目的で使用するために破壊します。
eclass[k]はUInt32型なので4バイトアクセスになります。arr2はmalloc時に、nblockの最大値*4バイトの領域を確保しているので問題ありません。

図で説明します。
上記は H=1 の時の図です。
bhtabでは、0,10,12,17,20 ビットが1になっています。
fmap[0]、fmap[10]、fmap[12]、fmap[17]、fmap[20]が、バケツの先頭となります。
fmap[0]は先頭シンボルが0の行
fmap[10]は先頭シンボルが1の行
fmap[12]は先頭シンボルが2の行
fmap[17]は先頭シンボルが3の行
fmap[20]は先頭シンボルが4の行
267行目のforループで、i=10の時、268行目でISSET_BH(10)が1なので、j=10となります。
269行目でfmap[10]が510なので、k=fmap[10]-1でk=509となります。
(kが-1の時、k+=nblockで、k=nblock-1となり巡回します)
270行目でeclass[509]=jでeclass[509]は10となります。
i=11の時、ISSET_BH(11)が0なので、jは10のままです。
269行目でfmap[11]が210なので、k=fmap[11]-1でk=209となります。
270行目でeclass[209]=jでeclass[209]は10となります。
i=17の時、268行目でISSET_BH(17)が1なので、j=17となります。
269行目でfmap[17]が221なので、k=fmap[17]-1でk=220となります。
270行目でeclass[220]=jでeclass[220]は17となります。
i=18の時、268行目でISSET_BH(18)が0なので、j=17のままです。
269行目でfmap[18]が100なので、k=fmap[18]-1でk=99となります。
270行目でeclass[99]=jでeclass[99]は17となります。
i=19の時、268行目でISSET_BH(19)が0なので、j=17のままです。
269行目でfmap[19]が15なので、k=fmap[19]-1でk=14となります。
270行目でeclass[14]=jでeclass[14]は17となります。
ここで、eclassの使い方を説明するために、fmap[20]、fmap[21]、fmap[22]をソートすることを考えます。
fmap[20]、fmap[21]、fmap[22]には、先頭シンボルが4の行が入っています。
fmap[20]、fmap[21]、fmap[22]のソート比較には、eclass[fmap[20]]、eclass[fmap[21]]、eclass[fmap[22]]を使用します。
eclass[fmap[20]] は、eclass[509]で10です。これは、ブロック番号509から始まる行の2バイト目、つまりブロック番号510から始まる行が属するバケツの先頭インデックスです。
eclass[fmap[21]] は、eclass[220]で17です。これは、ブロック番号220から始まる行の2バイト目、つまりブロック番号221から始まる行が属するバケツの先頭インデックスです。
eclass[fmap[22]] は、eclass[14]で17です。これは、ブロック番号14から始まる行の2バイト目、つまりブロック番号15から始まる行が属するバケツの先頭インデックスです。
fmap[20]とfmap[21]を比較する時、eclass[fmap[20]]とeclass[fmap[21]]を比較します。これは10と17なので、fmap[20]の方が小さいです。
この比較の意味するところは、fmap[20]とfmap[21]のそれぞれの行の2バイト目(fmap[20]から始まる行の2バイト目は1、fmap[21]から始まる行の2バイト目は3)で比較しているということです。
H=1の時は、2バイト目だけの比較なので、バケツの先頭インデックスではなく2バイト目のシンボルを比較すればよい、と思ってしまいますが、H=2以降では複数バイトのシンボル比較を行うことは難しいため、バケツの先頭インデックスで比較します。バケツの先頭インデックスが小さいほうがソート順でも小さいため、シンボルの比較の代わりにバケツの先頭インデックスの比較を使用できます。
273: nNotDone = 0;
274: r = -1;
275: while (1) {
276:
277: /*-- find the next non-singleton bucket --*/
278: k = r + 1;初回ループ時は、r=-1なので、k=0となります。
2回目以降は、前回のループ時のr(fmap上のソート対象の右端)の次の値(r+1)をkとします。
279: while (ISSET_BH(k) && UNALIGNED_BH(k)) k++;ソートが進むと、ほとんどのバケツの要素数が1になります。要素数1のバケツはソートが完了しているバケツなので、ソート不要です。
このwhileループは、そんな要素数が1のバケツを飛ばして、要素数が2以上のバケツを見つけるための処理です。
280〜283行では、4バイト単位(32ビット)で要素数1のバケツをスキップします。
これは、kを32個ずつ、まとめて確認します。
その前準備として、kが32の倍数になるまで増加させる処理が279行目となります。
もちろん、要素数が1のバケツが連続する場合だけに行うことなので、ISSET_BH(k)がfalse、つまり要素数が2以上になるバケツだと判明したらすぐにループを抜けます。
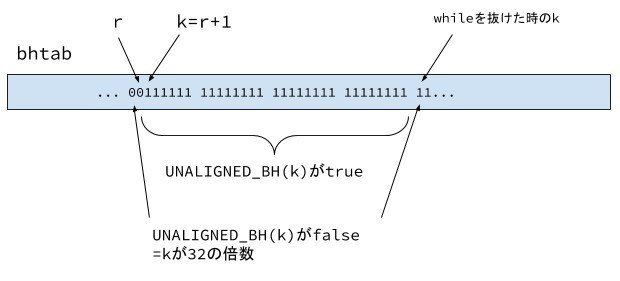
上記図は、kが32の倍数ではない値から始まって、32の倍数になるまでずっとISSET_BH(k)がtrueである場合です。
この場合、whileループを抜けるのはkが32の倍数になりUNALIGNED_BH(k)がfalseになる時です。

上記図は、kが32の倍数ではない値から始まって、32の倍数になる前にISSET_BH(k)がfalseとなってループを抜けた場合です。
ISSET_BH(k)がtrueとなるkについて
H=1の時、ここでfmapは先頭1バイトでソート済みです。先頭バイトがシンボル0の行が、fmapの先頭の方にセットされています。その後に先頭バイトがシンボル1となる行がセットされています。この、シンボル0とシンボル1の境目、つまりシンボル1となる行の先頭の、fmapインデックスとなる k では、 ISSET_BH(k)がtrueとなります。これは先頭バイトで基数(バケツ)ソートした時の各シンボルのバケツの先頭といえます。
H=2の時、fmapは先頭2バイトでソート済みです。先頭2バイトが[0,0]からなる行がfmapの先頭にセットされています。その後に先頭バイトが[0,1]となる行がセットされています。この[0,0]、[0,1]の境目となる fmap のインデックス k は、ISSET_BH(k)がtrueとなります。これは先頭2バイトで基数(バケツ)ソートした時の各2シンボルのバケツの先頭といえます。
kが、ブロック番号fmap[k] であるシンボル(つまりeclass8[fmap[k]]) の fmap上での先頭となる場合、ISSET_BH(k)はtrueとなります。
UNALIGNED_BH(k)がtrueとなるkについて
kが32の倍数でない時に、UNALIGNED_BH(k)はtrue となります。
kがインクリメントされるのは、fmap[k]がバケツの先頭で、かつ32の倍数でない時です。
ループが回る最大回数は31です。この時、k+=31となります。
k%32が1で、fmap[k]〜fmap[k+30]が全てバケツの先頭(=要素が1個のバケツ)の時です。
ループ初回時はk=0は ISSET_BH(k)はtrueです(ftab[0]が0なので、245行目でSET_BH(0)するため)。
UNALIGNED_BH(0)がfalseなので、whileループには一回も入りません。
ループ2回目以降は、rがバケツの終端なので、r+1は ISSET_BH(k)がtrueとなります。
280: if (ISSET_BH(k)) {ここでISSET_BH(k)がtrueとなるのは、279でループを抜けた時にISSET_BH(k)がtrueでUNALIGNED_BH(k)がfalseとなる時です。
つまり k が32の倍数なので、281行目のように4バイト単位で比較することが可能です。
281: while (WORD_BH(k) == 0xffffffff) k += 32;k〜k+31の全てが要素が一つのバケツの場合、k+=32として、次の32個を調べるます。
282: while (ISSET_BH(k)) k++;32個連続して要素が一つのバケツではない場合、4バイト単位未満のフラグ1の連続を検出してスキップします。
283: }ここでは、ISSET_BH(k)がfalseで、ISSET_BH(k-1)がtrueとなっています。
つまり、kから始まるバケツは要素が2つ以上存在するということです。
もしくは、lがnblockの場合は最後のバケツの要素が1つだったことになります。
284: l = k - 1;要素が2以上のバケツの左端をlとします。これが今回ソート対象とするfmapの左端のインデックスです。

上図は、281〜284行の処理を表したものです。
281行目のループで、32bit全てビットが立っている場合の比較を行います。
282行目のループで、ビットが連続して立っている箇所を、1ビットずつ比較します。
282行目に入った時点で、WORD_BH(k)が0xffffffffではないので、k〜k+31の間にビットが0の場所が見つかります。282行目のループを抜けた時、kはそのビットが0の場所を指しています。
284行目で、l=k-1として、連続する値1となるビットの中で最後のビットを l とします。これが、要素2以上のバケツの先頭 (fmap[l]) インデックスとなります。
285: if (l >= nblock) break;l が nblock以上の時(終端確認のビットで終端を見つけた場合、lはnblockより大きくなる)、現在のバケツでのループが完了したので、Hを増やして(=バケツを細かく分割して)再度バケツソートを行うために275行目のwhileループを抜けます。
286: while (!ISSET_BH(k) && UNALIGNED_BH(k)) k++;279行目では、連続してBHフラグが立っている箇所を検出してスキップしていましたが、286行目では、連続してBHフラグが立っていない箇所を検出してスキップします。
BHフラグはバケツの先頭なので、BHフラグが立っている所から次のBHフラグが立つ所までのビット数が、そのバケツの要素数となります。

図では、lビット目の後に、0が連続して6個続いています。この場合、バケツの要素数は7となります。
ビット0が続く場合、kが32の倍数になるまで、kを進めます。
ビットが立った時はすぐにループを抜けます。
287: if (!ISSET_BH(k)) {ここでBHフラグが0の場合(!ISSET_BH(k)がtrueの場合)、286行目で連続してフラグ0が見つかった
ここで!ISSET_BH(k)がtrueとなるのは、286でループを抜けた時に、!ISSET_BH(k)がtrueでUNALIGNED_BH(k)がfalseとなる場合です。
つまり k が32の倍数なので、288行目のように4バイト単位で比較することが可能です。
288: while (WORD_BH(k) == 0x00000000) k += 32;4バイト単位(32ビット)でビット0が連続する場所をスキップしています。
289: while (!ISSET_BH(k)) k++;4バイト単位未満のフラグ0の連続を検出してスキップします。
290: }ここでは、ISSET_BH(k) が true ( !ISSET_BH(k) が fals) で、ISSET_BH(k-1) が false ( !ISSET_BH(k-1) が true) となっています。
つまり、kが次のバケツの先頭だということです。
291: r = k - 1;k-1にして、一つ前のバケツの最後を、今回ソート対象とするfmapのインデックスの右端とします。

図は、286〜291行の処理を図示したものです。
286行目で、!ISSET_BH(k)はtrueで、UNALIGNED_BH(k)もtrueです。
kを進めていき、UNALIGHNED_BH(k)がfalseとなった時に、288行目のwhileループに入ります。ここで、WORD_BH(k)が0x00000000なのでwihleループを1回実行し、k+=32して次の4バイトを確認します。32進めたkのWORD_BH(k)が0x00000000ではないので、ループを抜け、289行目のループに入ります。
連続する値0のビットの間、kを進め、値が1になった時にループを抜けます。
291行目でr=k-1として、連続する値0の最後のビットをrとしています。
292: if (r >= nblock) break;
293: fmapの右の端までいったら、ループを抜けます。307行目。
厳密に言えば、これは起こらないと思われます。
255行目により、nblockは1となっています。
nblock-1が1の時、lがnblockとなり、285行目でループから抜けます。
nblock-1が0の時、rはnblock-1となります。次のループでlがnblockとなり、285行目でループから抜けます。
どちらにしても、rがnblock以上になってループから抜けることはないと思われます。
294: /*-- now [l, r] bracket current bucket --*/
295: if (r > l) {r > l がfalseとなる時は、1) r<l か2) r==lのときです。
l = k - 1、r = k - 1で、kは減算されないので、1)は起こりません。
2)が起こるのは、286〜289行で一度もkが増加しない時です。
284行目の時点で、bhtabのkビットは0となっています。
kが32の倍数の時、286のループに入らないでkが増加しないです。
また、288行目のループに入らないでkが増加しないこともありえます。
しかし、289行目のループは必ず1回は実行されるので、kは必ず増加します。
したがって2) も起こりません。
以上より、if (r > l) は常に成り立ちます。
296: nNotDone += (r - l + 1);ソート完了したバケツは要素数が1となり、296行目まではきません
nNotDone は、ソート未完了の要素数となります。
297: fallbackQSort3 ( fmap, eclass, l, r );
298: fallbackQSort3 ()では、fmap[l]〜fmap[r]に対応する巡回行列の各行をソートします。
比較にはeclassを使用します。(fmap[i]とfmap[j]の比較にeclass[i]とeclass[j]を使います)
fallbackQSort3()は次回の記事で紹介します。
299: /*-- scan bucket and generate header bits-- */
300: cc = -1;ソート対象の fmap[l] 〜 fmap[r] で、先頭H*2バイトでのソートが完了しました。
fmap[l]〜fmap[r]の各行は、先頭Hバイトが同じ行です。
今回のソートでは、先頭Hバイトに続くHバイトでソートを行いました。
結果、全体でみると、先頭H*2バイトでソートされたことになります。
301: for (i = l; i <= r; i++) {
302: cc1 = eclass[fmap[i]];
303: if (cc != cc1) { SET_BH(i); cc = cc1; };
304: }ソートが完了したので、その結果に従い BHフラグをセットし直します。
次回のループでは、新たなBHフラグに従いより細かいバケツを使ってソートを行います。
eclass[fmap[i]]には、fmap[i]+Hが属するバケツの先頭インデックスが入っています。
今回のソートの比較はeclassを使って行ったので、eclassが同じ場合(cc==c1)、比較結果が同じだったということで、同じバケツにソートされたことになります。
また、eclassが異なる場合(cc!=c1)、そこがバケツの境目なのでフラグを立てます。
300行目でcc=-1としており、eclassに入る値は0以上のため、fmap[l] の時 cc!=cc1が成り立ち、SET_BH(l)でlビット目のフラグが立ちます。
(今回ソートしたバケツの左端は分割したバケツでも左端になるため、フラグを立てます)

上は、301行目のforループでl=20、r=26とした時の図です。
i=20の時、cc1=eclass[fmap[20]]より、eclass[280]で0となります。
ここで、300行目でccが-1となっているのでcc!=cc1が成立し、303行目でSET_BH(20)します。また、ccを0で更新します。
i=21の時、cc1=eclass[fmap[21]]より、eclass[210]で10となります。
ccが0なのでcc!=cc1が成立し、303行目でSET_BH(21)します。またccを10で更新します。
i=22の時、cc1=eclass[fmap[22]]より、eclass[504]で10となります。
ccが10なのでcc!=cc1が成立しないので、bhtabの22ビット目は立てません。またccも更新しません。
以下、同様にiが26の時までループを回します。
結果、20,21,24,25,26にbhtabのビットを立ちます。
これは、ソート前に要素が20〜26だったバケツが、20、21〜23、24、25、26と5個のバケツに分割されたことを意味します。
ここで、20、24、25、26は要素数が1のバケツなので、この位置でソート完了したことになります。
305: }次のバケツ領域を見つけに 275行目のwhileループに戻ります。
306: }
307: 275行目のwhileループに対応します。
H=1の時、先頭2バイトでソートが完了しました。
H=2の時、先頭4バイト
H=4の時、先頭8バイト
308: if (verb >= 4)
309: VPrintf1 ( "%6d unresolved strings\n", nNotDone );
310: ここでは今回ソート対象とした要素数を表示します。
311: H *= 2;Hを増やして(ソート対象の文字列を増やして) 261行目のwhileループに戻ります。
312: if (H > nblock || nNotDone == 0) break;Hがnblockを超える場合、全ての行を一意にバケツにソートし終わっているため、ソート完了としてwhileループを抜けます。
nNotDoneが0の時、全ての行が要素数1のバケツにソート済みなので、ソート完了としてwhileループを抜けます。
313: }
314: ここでは、全ての行のソートが完了しています。
fmapにソート後の結果が入っています。
315: /*--
316: Reconstruct the original block in
317: eclass8 [0 .. nblock-1], since the
318: previous phase destroyed it.
319: --*/先程破壊したeclass8の領域(eclass8[0..nblock-1])を元に戻します。
320: if (verb >= 4)
321: VPrintf0 ( " reconstructing block ...\n" );入力ブロックeclass8 を元に戻すことを表示しています。
322: j = 0;
323: for (i = 0; i < nblock; i++) {
324: while (ftabCopy[j] == 0) j++;
325: ftabCopy[j]--;
326: eclass8[fmap[i]] = (UChar)j;
327: }
fmapはソートされた結果が入っています。
ftabCopyは先頭バイトの出現頻度が入っています。

図では、シンボル0、1がどうやってeclass8に復元するかを図示しています。
ftaCopy[0]が10なので、シンボル0から始まる行のブロック番号が fmap[0]〜fmap[9] にセットされていることが分かります。
また、ftaCopy[1]が15なので、シンボル0から始まる行のブロック番号が fmap[10]〜fmap[14] にセットされていることが分かります。
323行目のループで i=0 の時、jが初期値の0なので(322行目でセット)、324行目ではftabCopy[j]が非0になるまでjをインクリメントします。
図の例では、ftabCopy[0]は10なので、whileループに入りません。
325行目で、ftabCopy[0]--として、シンボル0のブロックを1個復旧させたことを覚えておきます。今回の場合、残り9個、復旧させる必要があります。
324行目の処理は、先頭シンボルがjである行が存在しない場合と、そのシンボルがeclass8に復旧し終えた場合(325行目のデクリメントで復旧し終えたシンボルのftabCopyは0になります)に、そのシンボルをスキップして次のシンボルを復旧させるためのものです。
326行目では、fmap[0]が100のため、 eclass8[fmap[i]] = j で、eclass8[100] = 0 として、シンボル0をブロック番号100に復旧しています。
328: AssertH ( j < 256, 1005 );最後のシンボルjが255以下でないとき、アサートします。
シンボルは0〜255です。
329: }まとめ
本記事では、fallbackSort()のバケツソート部分を紹介しました。
指数関数的に、ソート対象のシンボル数を増やしてバケツソートを行うので、exponential radix sort と呼びます。
次回は、内部で呼び出しているクイックソートfallbackQSort3() を紹介します。
ご覧下さりありがとうございます。いただいたサポートは図書館への交通費などに使わせていただきます。