
bzip2を読む ブロックソート11

こんにちは、junkawaです。
本記事では、前回に続きブロックソートアルゴリズムの「巡回行列のソート」についてソースコードを交えて紹介します。
これまでの記事
https://note.mu/junkawashima/m/m3adbdc56f010
前回までのおさらい
前回は、fallbackSort()の紹介を行いました。
本記事では、fallbackSort() でバケツ内の要素をソートするために呼び出すfallbackQSort3()と、そこから呼び出すfallbackSimpleSort()を紹介します。
fallbackQSort3()では、fmap[lo]〜fmap[hi]の要素をソートします。ソート比較にはeclass[fmap[lo]]〜eclass[fmap[hi]]を使用します。
クイックソートfallbackQSort3() を用いて要素を分割していき、要素数が一定以下になったらシェルソートfallbackSimpleSort() に切り替えてソートします。
これはmainSort()のmainQSor3t()と同じ流れです。
ソースコード紹介
fallbackSimpleSort()@blocksort.c
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L32
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L24
〜
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L59
24: /*---------------------------------------------*/
25: /*--- Fallback O(N log(N)^2) sorting ---*/
26: /*--- algorithm, for repetitive blocks ---*/
27: /*---------------------------------------------*/
28: 29: /*---------------------------------------------*/
30: static
31: __inline__
32: void fallbackSimpleSort ( UInt32* fmap,
33: UInt32* eclass,
34: Int32 lo,
35: Int32 hi )
36: {fmap
入力:ソート対象のブロック番号
出力:ソート結果
eclass
入力:ソート時の比較に使用する値
lo
入力:fmapの先頭インデックス
hi
入力:fmapの末尾インデックス
37: Int32 i, j, tmp;
38: UInt32 ec_tmp;
39:
下で紹介します。
40: if (lo == hi) return;
41:lo == hi の時、比較する要素が1つだけなので、ソート不要です。
42: if (hi - lo > 3) {ソート対象が4個以上ある場合、4個おきにシェルソート(挿入ソート)を行います。
事前に大雑把にソートを済ませることで、52行目からの挿入ソートの高速化を図っています。
43: for ( i = hi-4; i >= lo; i-- ) {
44: tmp = fmap[i];
45: ec_tmp = eclass[tmp];
46: for ( j = i+4; j <= hi && ec_tmp > eclass[fmap[j]]; j += 4 )
47: fmap[j-4] = fmap[j];
48: fmap[j-4] = tmp;
49: }fmap[i]を、fmap[i+4]、fmap[i+8]、fmap[i+12]、... の中で適切な位置に挿入します。
46行目のループでは、fmap[i] と fmap[i+4]、fmap[i+8]、... を比較して、fmap[i]より小さい場合、左(低位のインデックス)に一つずらしていきます(47行目)。fmap[i]より大きいfmap[i+4*n] が見つかった場合、その一つ前にfmap[i]をセットします(48行目)。
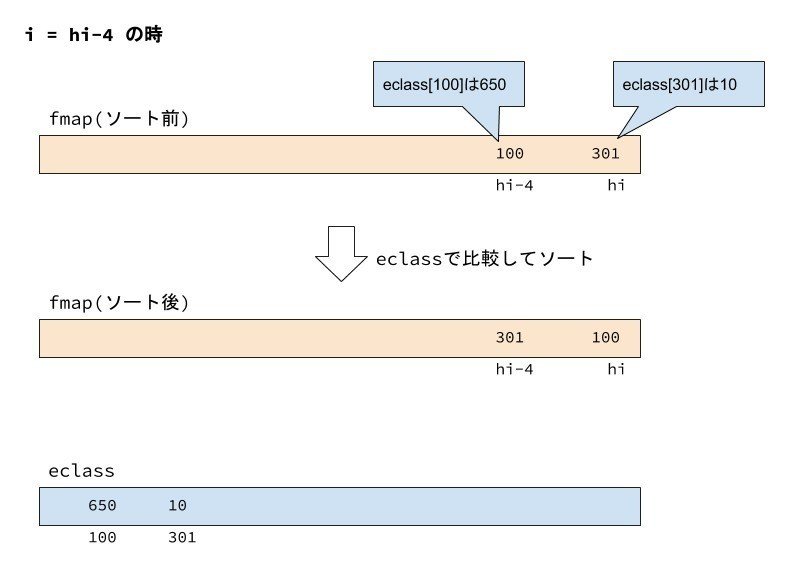
図は i=hi-4の時の比較を説明しています。
この時、fmap[hi-4]のブロック番号を、46〜48行で適切な位置に挿入します。
44行目でfmap[hi-4](=100)をtmpに退避します。
45行目では、ソート比較に用いる eclass[fmap[hi-4]](=650)をec_tmpにセットします。
46行目のループでは、i+4がhi-4 + 4 より、hiなので、j=hiとなり、ec_tmp(=650)とeclass[fmap[hi]](=eclass[301]=10)を比較して、ec_tmpの方が大きいのでループに入り、47行目を実行します。47行目では、fmap[hi-4] = fmap[hi] とブロック番号を入れ替えています。
j+=4として、ループ条件を確認すると、jがhi+4となっており、j<=hi がfalseとなるのでループを抜けます。
48行目で、fmap[hi] = tmp として、退避した100をfmap[hi]にセットします。
i=hi-4の時、fmap[hi-4] と fmap[hi] の eclass を比較してソートを行います。eclassが小さい方が左(低位のインデックス)になります。
図では、eclass[ fmap[hi-4] ] が 650、eclass[ fmap[hi] ] が 10 なので、eclass[ fmap[hi] ] の方が小さく、fmap[hi-4]の100とfmap[hi]の301を入れ替えています。

図は i=hi-5の時の比較を説明しています。
43行目のforループでは、iをデクリメントしていくので、i=hi-4で挿入ソートを行った次は、i=hi-5で挿入ソートを行います。
i=hi-5の時、fmap[hi-5] と fmap[hi-1] の eclass を比較してソートを行います。eclassが小さい方が左(低位のインデックス)になります。
図では、eclass[ fmap[hi-5] ] が 21、eclass[ fmap[hi-1] ] が 350 なので、ソートの必要はありません。

図は i=hi-8の時の比較を説明しています。
i=hi-8の時、fmap[hi-8] と fmap[hi-4] と fmap[hi] の eclass を比較してソートを行います。eclassが小さい方が左(低位のインデックス)になります。
ここで注意が必要なのは、fmap[hi-4]とfmap[hi]間のソートは、i=hi-4の時にすでに終了している、という点です。つまり、fmap[hi-8]がfmap[hi-4]より小さい場合、自動的にfmap[hi-8]はfmap[hi]より小さいことになり、fmap[hi-8]とfmap[hi]を比較する必要がありません。
このソート済みの fmap[hi-4]とfmap[hi]に対して、新規にソート対象として加えるのが fmap[hi-8]です。
まず、fmap[hi-8] と fmap[hi-4] を比較します。図では、eclass[ fmap[hi-8] ] が99、eclass[ fmap[hi-4] ] が 10 なので、fmap[hi-8] の250と fmap[hi-4] の301を入れ替えます。
図では、eclass[ fmap[hi-5] ] が 21、eclass[ fmap[hi-1] ] が 350 なので、ソートの必要はありません。
50: }
51: 52: for ( i = hi-1; i >= lo; i-- ) {
53: tmp = fmap[i];
54: ec_tmp = eclass[tmp];
55: for ( j = i+1; j <= hi && ec_tmp > eclass[fmap[j]]; j++ )
56: fmap[j-1] = fmap[j];
57: fmap[j-1] = tmp;
58: }fmap[i]を、fmap[i+1]、fmap[i+2]、fmap[i+3]、... 、fmap[hi] の中で適切な位置に挿入します。
55行目のループでは、fmap[i] と fmap[i+1]、fmap[i+2]、... を比較して、fmap[i]より小さい場合、左(低位のインデックス)に一つずらしていきます(56行目)。fmap[i]より大きいfmap[i+n] が見つかった場合、その一つ前にfmap[i]をセットします(57行目)。
比較の詳細については、前述の43〜49行のループと同じなので割愛します。

図は i=hi-1、i=hi-2、i=hi-3の時の、比較対象を示しています。
59: }
60:
61:fallbackQSort3()@blocksort.c
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L93
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L62
〜
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/blocksort.c#L180
62: /*---------------------------------------------*/
63: #define fswap(zz1, zz2) \
64: { Int32 zztmp = zz1; zz1 = zz2; zz2 = zztmp; }
65:zz1とzz2を入れ替えます。
66: #define fvswap(zzp1, zzp2, zzn) \
67: { \
68: Int32 yyp1 = (zzp1); \
69: Int32 yyp2 = (zzp2); \
70: Int32 yyn = (zzn); \
71: while (yyn > 0) { \
72: fswap(fmap[yyp1], fmap[yyp2]); \
73: yyp1++; yyp2++; yyn--; \
74: } \
75: }
76:
77:
zzp1〜zzp1+zzn-1と、zzp2〜zzp2+zzn-1の領域を交換する。
78: #define fmin(a,b) ((a) < (b)) ? (a) : (b)
79:a,b の小さい方の値を返します。
80: #define fpush(lz,hz) { stackLo[sp] = lz; \
81: stackHi[sp] = hz; \
82: sp++; }
83:3つのスタック、stackLo、stackHiへデータを積みます。
スタックポインタspをインクリメントします。
84: #define fpop(lz,hz) { sp--; \
85: lz = stackLo[sp]; \
86: hz = stackHi[sp]; }
87:スタックからデータを取り出します。
スタックポインタspをデクリメントします。
88: #define FALLBACK_QSORT_SMALL_THRESH 10ソート対象の、比較する要素数がFALLBACK_QSORT_SMALL_THRESH未満の場合、クイックソートをやめて、シェルソート(fallbackSimpleSort())を行います。
89: #define FALLBACK_QSORT_STACK_SIZE 100クイックソートを再帰ではなく、スタックで実装します。
スタックのサイズはFALLBACK_QSORT_STACK_SIZEです。
90:
91:
92: static
93: void fallbackQSort3 ( UInt32* fmap,
94: UInt32* eclass,
95: Int32 loSt,
96: Int32 hiSt )
97: {fmap
入力:ソート対象のブロック番号
出力:ソート結果
eclass
入力:ソート時の比較に使用する値
loSt
入力:fmapの下限インデックス
hiSt
入力:fmapの上限インデックス
98: Int32 unLo, unHi, ltLo, gtHi, n, m;
99: Int32 sp, lo, hi;
100: UInt32 med, r, r3;ローカル変数です。下記で紹介します。
101: Int32 stackLo[FALLBACK_QSORT_STACK_SIZE];
102: Int32 stackHi[FALLBACK_QSORT_STACK_SIZE];
103:クイックソートを再帰ではなくスタックに積むことでループとして実装しています。
stackLo[]、stackHi[]はソート対象の領域の下限と上限です。fmap[starkLo[i] .. starkHi[i]] の範囲をソートします。
104: r = 0;
105:乱数の初期値を0としています。
106: sp = 0;
107: fpush ( loSt, hiSt );
108:初期値としてスタックに、loSt、hiStをセットします。
109: while (sp > 0) {
110:spが0になる時は、全てのソートが終わった時です。
111: AssertH ( sp < FALLBACK_QSORT_STACK_SIZE - 1, 1004 );
112:sp >= 99 (FALLBACK_QSORT_STACK_SIZE - 1) の時、アサートします。
stackLo[0..99] なので、spが100の時にmpush()するとオーバーフローします。
アサートが発生するspが99の時、本whileループでは、fpop()が1回、その後にfpush()が2回発生するのでspが99でfpush()することになります。まだオーバーフローする段階ではないですが、余裕をもってアサートしているものと思われます。
113: fpop ( lo, hi );スタックからlo、hiを取り出します。
lo、hiはソート対象の領域の下限と上限です。fmap[lo .. hi] の範囲をソートします。
114: if (hi - lo < FALLBACK_QSORT_SMALL_THRESH) {ソート対象の数(hi-lo)が、FALLBACK_QSORT_SMALL_THRESH(10)未満の場合、対象のソート方法fallbackSimpleSort()に切り替えます。
115: fallbackSimpleSort ( fmap, eclass, lo, hi );fallbackSimpleSort () を実行します。
116: continue;fmap[lo..hi]の範囲についてfallbackSimpleSort()でソートが完了したので、スタックに積まれている次の範囲をソートするためにcontinueします。
117: }
118:以下は、fallbackSimpleSort()ではなく、クイックソートする処理です。
119: /* Random partitioning. Median of 3 sometimes fails to
120: avoid bad cases. Median of 9 seems to help but
121: looks rather expensive. This too seems to work but
122: is cheaper. Guidance for the magic constants
123: 7621 and 32768 is taken from Sedgewick's algorithms
124: book, chapter 35.
125: */通常、クイックソートでは要素の左端、中間、右端の値の中で中央値を基準値(ピボット)として、領域を二分割します。
ここでは、3値の中央値では、問題があると主張しています。
代わりに9値の中央値は良さそうですが、計算コストが高いとしています。
中央値の代わりに乱数を用いて、3値のどれを基準値として用いるかを決めます。
乱数の生成には、Sedgewick's algorithms Chapter 35 に出てくるマジックナンバー7621、32768を使用します。
126: r = ((r * 7621) + 1) % 32768;前回の値を元に乱数を生成します。
127: r3 = r % 3;乱数をもとに 0,1,2 のどれかの値を取得します。
128: if (r3 == 0) med = eclass[fmap[lo]]; else
129: if (r3 == 1) med = eclass[fmap[(lo+hi)>>1]]; else
130: med = eclass[fmap[hi]];
131:乱数に応じて基準値medを決定します。
r3が0の時、左端のeclass[fmap[lo]]。
r3が1の時、中間のeclass[fmap[(lo+hi)>>1]]。
r3が2の時、右端のeclass[fmap[hi]]。
132: unLo = ltLo = lo;
133: unHi = gtHi = hi;
134:3つの領域に分割するための区切りの変数unLo、ltLo、unHi、gtHiの初期値をセットする。
135: while (1) {ここでは、4つの領域(ピボットと一致、ピボットより小さい、ピボットより大きい、ピボットと一致)に分割する。
このループを抜けたところで、最初と最後のピボットと一致する領域を結合し、3つの領域(ピボットより小さい、ピボットと一致、ピボットより大きい)にします。
136: while (1) {
137: if (unLo > unHi) break;
138: n = (Int32)eclass[fmap[unLo]] - (Int32)med;
139: if (n == 0) {
140: fswap(fmap[unLo], fmap[ltLo]);
141: ltLo++; unLo++;
142: continue;
143: };
144: if (n > 0) break;
145: unLo++;
146: }
fmap[unLo]に対応するeclass[ fmap[unLo] ] がmedより小さい場合、unLoを右に進めます(145行目)。この時、ltLoはmedより小さい文字を指しています。
eclass[ fmap[unLo] ] がmedに一致する場合(139行目)、unLoとltLoを入れ替えます(140行目)。unLo>=ltLoとなっているので、medに一致する値はlo側にセットされ、medより小さい値はunLo側にセットされます。交換した時点では、ltLoはmedに一致する値を指しています。次の141行目で、ltLo++することで、medより小さい文字を指すようにします。また、unLo++することで次に確認する値を指します。
eclass[ fmap[unLo] ] がmedより大きい場合、ループから抜けます(144行目)。
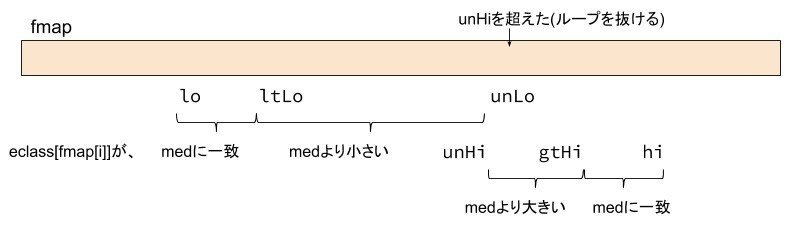
unHiを超えた場合、そこはすでにmedより大きい領域、またはhi(hi=unHiの時)を超えた領域なので、ループを抜けます。
直感的には、medより小さい、medに一致の順に並べ替えますが、ここではmedに一致、medより小さい、の順に並べ替えます。166行目でmedより小さい、medに一致の順に並べ直します。
147: while (1) {
148: if (unLo > unHi) break;
149: n = (Int32)eclass[fmap[unHi]] - (Int32)med;
150: if (n == 0) {
151: fswap(fmap[unHi], fmap[gtHi]);
152: gtHi--; unHi--;
153: continue;
154: };
155: if (n < 0) break;
156: unHi--;
157: }
fmap[unHi]に対応するeclass[ fmap[unHi] ]がmedより大きい場合、unHiを左に進めます(156行目)。この時、gtHiはmedより大きい文字を指しています。
eclass[ fmap[unHi] ]がmedに一致する場合(150行目)、unHiとgtHiを入れ替えます。unHi<=gtHiとなっているので、medに一致する値はhi側にセットされ、medより大きい値はunHi側にセットされます。交換した時点では、gtHiはmedに一致する値を指しています。次の152行目で、gtHi--することで、medより大きい文字を指すようにします。また、unHi--することで次に確認する値を指します。
eclass[ fmap[unHi] ]がmedより小さい場合、ループから抜けます(155行目)。

unLoを超えた場合、そこはすでにmedより小さい領域、またはlo(lo=unLoの時)を超えた領域なので、ループを抜けます。
直感的にはmedに一致、medより大きい、の順に並べ替えますが、ここではmedより大きい、medに一致、の順に並べ替えます。167行目でmedに一致、medより大きいの順に並べ直します。
158: if (unLo > unHi) break;unLo > unHi が成立する時、領域に振り分ける要素がないので、whileループを抜ける。
159: fswap(fmap[unLo], fmap[unHi]); unLo++; unHi--;
159行目の時点で、eclass[ fmap[unLo] ]はmedより大きい、eclass[ fmap[unHi] ]はmedより小さい、となっています(図の上部)。
unLoとunHiを入れ替えると、medより小さい領域とmedより大きい領域をそれぞれ拡張することができます(図の下部)。
160: }
161:
162: AssertD ( unHi == unLo-1, "fallbackQSort3(2)" );
163:上記のwhileループを抜けた時は、unHiとunLoは隣接し、unLo > unHi となることが期待されます。これを満たさない場合、アサートします。
164: if (gtHi < ltLo) continue;
165:
gtHi < ltLoとなるのは、loからhiまでの全てのソート対象がmedに一致した場合です。
この場合、この領域はこれ以上ソートすることができないので、continueして再度別の領域にクイックソートを行います。
166: n = fmin(ltLo-lo, unLo-ltLo); fvswap(lo, unLo-n, n);

medに一致する領域とmedより小さい領域を入れ替えます。
medに一致する領域のサイズ(ltLo-lo)とmedより小さい領域のサイズ(unLo-ltLo)の小さい方のサイズ分だけ入れ替え対象とします。
167: m = fmin(hi-gtHi, gtHi-unHi); fvswap(unLo, hi-m+1, m);
168:

medに一致する領域とmedより大きい領域を入れ替えます。
medに一致する領域のサイズ(hi-gtHi)とmedより大きい領域のサイズ(gtHi-unHi)の小さい方のサイズ分だけ入れ替え対象とします。
大きい方のサイズで入れ替えても、動作に支障は起きませんが、無駄な入れ替え(一致する領域から一致する領域への入れ替え、大きい領域から大きい領域への入れ替え)が発生してしまいます。
169: n = lo + unLo - ltLo - 1;
170: m = hi - (gtHi - unHi) + 1;
171:
medより小さい領域のサイズはunLo-ltLoです。medより小さい領域の先頭はlo、最後はlo+unLo-ltLo-1(=n)となります。
medより大きい領域のサイズはgtHi-unHiです。medより大きい領域の最後はhi、先頭はhi-(gtHi-unHi)+1(=m)となります。
172: if (n - lo > hi - m) {
173: fpush ( lo, n );
174: fpush ( m, hi );
175: } else {
176: fpush ( m, hi );
177: fpush ( lo, n );
178: }172行目で n-lo > hi-m がtrueとなるのは、medより小さい領域の要素数が、medより大きい領域の要素数より多い場合です。
この時、173、174行目で、medより小さい領域を先にスタックに積んでいます。
176、177行目は、medより大きい領域の要素数が、medより小さい領域の要素数より多い場合に実行されます。
この時、medより大きい領域を先にスタックに積んでいます。
どちらの場合でも、領域の要素数の多い方を先にスタックに積んでいます。言い換えると、要素数の少ない方を先にスタックから取り出すことになります。
サイズの小さい領域を優先的にソートすることで早めにソートを完了させ、スタックに積む回数が増えないようにしていると思われます。
179: }
180: }まとめ
本記事では、fallbackSort()でのクイックソートfallbackQSort3()とシェルソートfallbackSimpleSort()を紹介しました。
これで、blocksort.c のすべての処理の紹介が終わりました。
次回は、bzip2 の圧縮処理で、ブロックソートの次に実行する、MTF(Move To Frone)変換について紹介します。
ご覧下さりありがとうございます。いただいたサポートは図書館への交通費などに使わせていただきます。