
bzip2を読む ハフマン符号7

こんにちは、junkawaです。
本記事では、ハフマン符号化で使用した情報を出力バッファに書き出す処理について紹介します。
コードの紹介
sendMTFValues() @ compress.c
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/compress.c#L239
57: /*---------------------------------------------------*/
58: #define bsNEEDW(nz) \
59: { \
60: while (s->bsLive >= 8) { \
61: s->zbits[s->numZ] \
62: = (UChar)(s->bsBuff >> 24); \
63: s->numZ++; \
64: s->bsBuff <<= 8; \
65: s->bsLive -= 8; \
66: } \
67: }
68:
69:一時バッファbsBuffにたまったビットを出力バッファs->zbitsに書き出します。
引数nzは使用しません。
bsLiveはまだ書き出していないビット数です。書き出していないデータはbsBuffにたまります。
上位ビットから順に溜まっていきます。
8ビット以上、書き出していないデータが溜まっていた場合、bsBuffの上位8ビットを出力バッファs->zbits[s->numZ]に書き出します。
bsBuffを8bit左シフトして、次の書き込みに備えます。
bsLiveから書き出した分の8bitを減算します。

s->bsLiveは、s->bsBuffに入っているデータのビット数です。
70: /*---------------------------------------------------*/
71: static
72: __inline__
73: void bsW ( EState* s, Int32 n, UInt32 v )
74: {
75: bsNEEDW ( n );
76: s->bsBuff |= (v << (32 - s->bsLive - n));
77: s->bsLive += n;
78: }
79:
80:出力バッファにnビットの値vを書き込みます。
bsNEEDW(n)で、未書き出しのデータs->bsLiveが7ビット以下になるまで、書き出します。
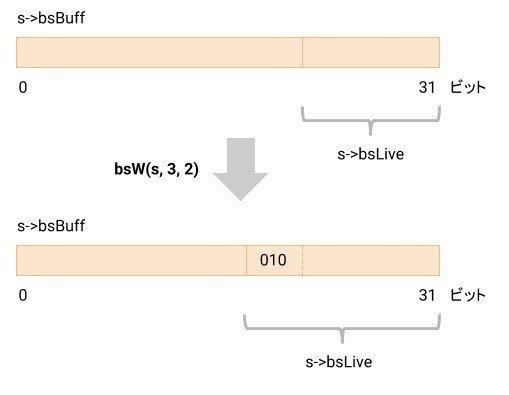
図では、bsW(s, 3, 2) 実行時の一時バッファs->bsBuffの変化を記しています。
bsW(s, 3, 2)は、s->bsBuffに3ビットで値2 (010) を書き出します。
s->bsLiveが8を超えた時、s->bsBuffをbsNEEDW()で書き出しバッファs->zbitsに書き出します。
81: /*---------------------------------------------------*/
82: static
83: void bsPutUInt32 ( EState* s, UInt32 u )
84: {
85: bsW ( s, 8, (u >> 24) & 0xffL );
86: bsW ( s, 8, (u >> 16) & 0xffL );
87: bsW ( s, 8, (u >> 8) & 0xffL );
88: bsW ( s, 8, u & 0xffL );
89: }
90:
91:出力バッファに32ビットの値uを書き込みます。
92: /*---------------------------------------------------*/
93: static
94: void bsPutUChar ( EState* s, UChar c )
95: {
96: bsW( s, 8, (UInt32)c );
97: }
98:
99:出力バッファに8ビットの値cを書き込みます。
494: /*--- Transmit the mapping table. ---*/入力データブロックにシンボルが含まれるかどうかを表すマッピングテーブルs->inUseを出力バッファに書き出します。
495: {
496: Bool inUse16[16];
497: for (i = 0; i < 16; i++) {
498: inUse16[i] = False;
499: for (j = 0; j < 16; j++)
500: if (s->inUse[i * 16 + j]) inUse16[i] = True;
501: }
502:s->inUse[0]〜s->inUse[255]を16分割し、inUse16にセットします。
16シンボル単位(例 s->inUse[0]〜s->inUse[15]) でFalseが続いた場合、inUse16[0]にFalseをセットします。一つでもTrueがあった場合、inUse16にTrueをセットします。
inUse16[0]がFalseの場合、s->inUse[0]〜s->inUse[15]は出力ファイルに書き出さないようにして、ファイルのサイズを小さくします。

503: nBytes = s->numZ;現在の出力バッファのサイズs->numZをnBytesに保存します。
504: for (i = 0; i < 16; i++)
505: if (inUse16[i]) bsW(s,1,1); else bsW(s,1,0);
506:inUse16を出力バッファに書き出します。
合計で16ビット(2バイト)書き出します。
507: for (i = 0; i < 16; i++)
508: if (inUse16[i])
509: for (j = 0; j < 16; j++) {
510: if (s->inUse[i * 16 + j]) bsW(s,1,1); else bsW(s,1,0);
511: }
512:s->inUse全てを書き出すのではなく、16分割した中で、Trueを含んでいる部分(inUse16がTrueの部分)だけを書き出します。
書き出すサイズは可変長となります。
参考
https://en.wikipedia.org/wiki/Bzip2#Sparse_bit_array
513: if (s->verbosity >= 3)
514: VPrintf1( " bytes: mapping %d, ", s->numZ-nBytes );
515: }
516:マッピングテーブルで出力したバイト数s->numZ-nBytesを出力します。
517: /*--- Now the selectors. ---*/
518: nBytes = s->numZ;現在の出力バッファのサイズs->numZをnBytesに保存します。
519: bsW ( s, 3, nGroups );ハフマンテーブル数nGroups(1〜6)を3ビットで出力バッファに書き出します。
520: bsW ( s, 15, nSelectors );セレクタ数(MTF後のデータを50シンボル単位で区切ったブロック数)nSelectorsを15ビットで出力バッファに書き出します。
521: for (i = 0; i < nSelectors; i++) {
522: for (j = 0; j < s->selectorMtf[i]; j++) bsW(s,1,1);
523: bsW(s,1,0);
524: }MTF変換後のセレクタの内容s->selectorMtfをUnary codingして出力バッファに書き出します。
Unary coding
https://en.wikipedia.org/wiki/Unary_coding
Unary codingによって、s->selectorMtfの符号長を短くできます。
If multiple Huffman tables are in use, the selection of each table (numbered 0 to 5) is done from a list by a zero-terminated bit run between one (1) and six (6) bits in length. The selection is into a MTF list of the tables. Using this feature results in a maximum expansion of around 1.015, but generally less. This expansion is likely to be greatly over-shadowed by the advantage of selecting more appropriate Huffman tables and the common-case of continuing to use the same Huffman table is represented as a single bit. Rather than unary encoding, effectively this is an extreme form of a Huffman tree where each code has half the probability of the previous code.
参考 https://en.wikipedia.org/wiki/Bzip2#Unary_encoding_of_Huffman_table_selection
s->selector配列には、ハフマンテーブル0〜5が入ります。s->selectorMtf配列にはs->selectorをMTF変換した値が入ります。MTF変換では、同じ値が連続すると0になります。Unary codingでは、下記表のようにシンボルを変換します。

シンボルの値の数だけビット1が連続し、ビット0で終端します。
これをみて分かるように、シンボルが小さいほど符号長が短くなります。
MTF変換では、一般に値が小さくなる傾向があるので(要出典)、Unary coding前にMTF変換を行うことで、符号長を短くできます。
525: if (s->verbosity >= 3)
526: VPrintf1( "selectors %d, ", s->numZ-nBytes );
527:ハフマンテーブル数、セレクタ数、セレクタデータで使用したバイト数を表示します。
528: /*--- Now the coding tables. ---*/
529: nBytes = s->numZ;
530:現在の出力バッファのサイズs->numZをnBytesに保存します。
531: for (t = 0; t < nGroups; t++) {
532: Int32 curr = s->len[t][0];
533: bsW ( s, 5, curr );
534: for (i = 0; i < alphaSize; i++) {
535: while (curr < s->len[t][i]) { bsW(s,2,2); curr++; /* 10 */ };
536: while (curr > s->len[t][i]) { bsW(s,2,3); curr--; /* 11 */ };
537: bsW ( s, 1, 0 );
538: }
539: }
540:ハフマンテーブル(シンボルと符号長の組)を差分符号化(Delta encoding)して書き出します。
差分符号化
https://ja.wikipedia.org/wiki/%E5%B7%AE%E5%88%86%E7%AC%A6%E5%8F%B7%E5%8C%96
まず533行目でハフマンテーブル0のシンボル0の符号長s->len[0][0]を5ビットで書き出します。s->len[0][0]をcurrに保存します。
次に535、536行目でシンボル1の符号長s->len[0][1]とcurr(s->len[0][0])の差分を書き出します。
s->len[0][1]の方が大きい場合、s->len[0][1]とs->len[0][0]の差分だけ2ビットで10を書き出します。例えば、s->len[0][1]が8でs->len[0][0]が5の場合、6ビットで101010を書き出します。
s->len[0][1]の方が小さい場合、s->len[0][1]とs->len[0][0]の差分だけ2ビットで11を書き出します。
最後に、1ビットで0を書き出します。
ここでcurrにはs->len[0][1]が入っています。
次のループでは、同様に、s->len[0][2]とcurr(s-len[0][1])の差分を書き出します。
541: if (s->verbosity >= 3)
542: VPrintf1 ( "code lengths %d, ", s->numZ-nBytes );
543:ハフマンテーブルで使用したバイト数を表示します。
まとめ
本記事では、ハフマン符号化で使用した情報を出力バッファに書き出す処理について紹介しました。
ご覧下さりありがとうございます。いただいたサポートは図書館への交通費などに使わせていただきます。