
bzip2を読む ハフマン符号3

こんにちは、junkawaです。
本記事では、カノニカルハフマン符号(Canonical Huffman Code)によって、符号長が決まったシンボルに、符号を割り当てる方法を紹介します。
当該関数は、BZ2_hbAssignCodes() @ huffman.c です。
カノニカルハフマンについて
通常のハフマン符号では、ハフマン木が完成して符号長が決まっても、木の各枝に0、1の符号を割り当てる順番は自由なため、符号長から符号は一意に決まりません。
bzip2では、カノニカルハフマンという、ハフマン符号に制約を設けた符号化を用いるため、符号長から符号が一意に定まります。
一般的なハフマン符号では、符号の割当(枝への0,1の割当)は自由なのですが、カノニカルハフマンでは、「符号長が同じシンボルは、符号の辞書式順とシンボルの順序が同じ」になるように符号を割り当てる、という制約があります。
参考
https://en.wikipedia.org/wiki/Bzip2
https://en.wikipedia.org/wiki/Canonical_Huffman_code
下記、岡野原さんの解説ではカノニカルハフマンの制約は「各文字の符号の辞書式順序は、文字の出現確率の大きい順序と一致する」とのことで、bzip2の(Wikipediaの)カノニカルハフマンの定義とは若干違うようです。カノニカルハフマンにもいくつか方法があるのでしょうか。
https://codezine.jp/article/detail/376
符号の辞書式順とは、100 → 101 → 110 のように、0、1の符号の組み合わせの順序です。0が1より小さくなります。
シンボルの順序とは、0〜257のシンボルの数値順です。
符号の割り当て方
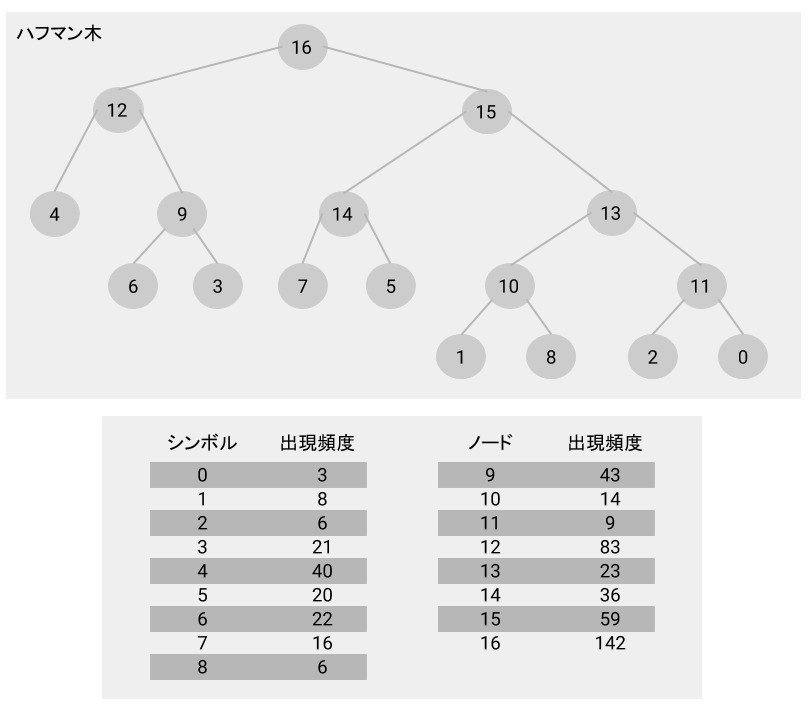
図では、シンボルの出現頻度から生成したハフマン木を表しています。
葉ノード(0〜8)がシンボルに対応します。
葉ノードより上はノード(9〜16)となります。
ノード(9〜16)の出現頻度は、子ノードの出現頻度を合わせたものになります。
例えば、ノード9の出現頻度は、葉ノード6と葉ノード3の出現頻度22と21を足した43となります。また、ノード12の出現頻度は葉ノード4とノード9の出現頻度40と43を合わせた83となります。
このハフマン木は、前回紹介した BZ2_hbMakeCodeLengths()で生成します。

図では、ハフマン木から符号を割り当てています。
ハフマン木の葉ノードがシンボルに対応しています。
また、根ノードから葉ノードまでの高さが符号長となります。
符号長2のシンボルは4のみです。
符号長3のシンボルは6、3、7、5 の4つです。
符号長4のシンボルは1、8、2、0 の4つです。
カノニカルハフマンの「符号長が同じシンボルは、符号の辞書式順とシンボルの順序が同じ」になるように符号を割り当てるために、符号長3のシンボルの符号割当順序を3、5、6、7とします(シンボルの順序)。また、符号長4のシンボルの符号割当順序を0、1、2、8とします。
符号の割当は、下記のとおりです
始めに符号長が最も短い文字(出現確率が高い文字)の符号を「0..0」とします。それ以外の文字の符号は、前の文字の符号に1を加え、文字符号長が長くなる場合は長くなった分0を最後につけます。
https://codezine.jp/article/detail/376?p=2
図の例では、符号長2のシンボル4に、「00」を割り当てます。
次に符号長3のシンボル3に、「010」を割り当てます。これは、前の符号「00」に1を加え(「01」)、符号長が2から3に長くなったので、最後に0をつけたものです。
シンボル4に「011」を割り当てます。前の符号「010」と符号長が変わらないので、最後に0はつけません。同様にシンボル5に「011」を割り当てます。
このようにして、全てのシンボルに符号を割り当てます。
コードの紹介
BZ2_hbAssignCodes() @ huffman.c
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/huffman.c#L152
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/huffman.c#L151
〜
https://github.com/junkawa/bzip2/blob/master/bzip2-1.0.6/huffman.c#L166
151: /*---------------------------------------------------*/
152: void BZ2_hbAssignCodes ( Int32 *code,
153: UChar *length,
154: Int32 minLen,
155: Int32 maxLen,
156: Int32 alphaSize )
157: {code [出力] シンボルの符号
length [入力] シンボルの符号長
minLen [入力] 最小符号長
maxLen [入力] 最大符号長
aplhaSize [入力] シンボル数
シンボルの符号長をもとに、シンボルの符号を割り当てます。
158: Int32 n, vec, i;
159: 160: vec = 0;vec には符号が入ります。値の意味がビット単位の符号なのでvec (vector)と呼んでいるのだと思われます。
161: for (n = minLen; n <= maxLen; n++) {
162: for (i = 0; i < alphaSize; i++)
163: if (length[i] == n) { code[i] = vec; vec++; };
164: vec <<= 1;
165: }minLen、maxLenは無駄なループを回さないために用います。
minLen、maxLenはBZ2_hbAssignCodes() 呼び出し前に求めています(compress.c#484〜487)。
minLen、maxLenがない場合、0<=n<=17 でループを回さなければならず、1回のループで内側のループをalphaSize回まわさなければならないため非効率です。
始めに符号長が最も短い文字(出現確率が高い文字)の符号を「0..0」とします。それ以外の文字の符号は、前の文字の符号に1を加え、文字符号長が長くなる場合は長くなった分0を最後につけます。
https://codezine.jp/article/detail/376?p=2
162〜164行では、上記を実現しています。
vecの初期値が0なので、length[minLen]となる最初のシンボルは0..0 (minLenの長さ分0が続く)です。次に、vec++により、前の符号に1を加えています。符号長が長くなる場合は、164行目のvec <<= 1 により、符号の最後に0をつけます(左シフト)。
166: }まとめ
カノニカルハフマン符号による、シンボルへの符号割当を紹介しました。
次回は、今回紹介した関数を使って、MTF後のデータにハフマン符号を適用する部分を紹介します。
ご覧下さりありがとうございます。いただいたサポートは図書館への交通費などに使わせていただきます。