
BQテーブルをCSV化してAWS s3へ定期実行で送信する方法(TBL1GB 超でもOK)

BigQueryでデータ分析を行ったり基盤構築してたりすると、BigQueryのテーブルをCSV化して他社へデータ連携する必要が出てきたので、今回はそのやり方の解説になります。
(自分の場合は、B-dash(AWS s3)への連携時によく使ってました。)
BigQueryテーブルが1GB未満であれば、特に問題なくCSV化できると思うんですが、ただ問題は1GBを超えた場合ですね。
GCPの制約上、1GBを超えるテーブルをCSV化する場合、分割でCSV化する必要があり、出力されるファイル名も番号だけのファイル名でちょっと扱いづらいです。
今回は、
①1GB超えCSVを分割CSV化
②分割したCSVをGCP内でマージして1つのCSVファイルにする
③マージされたCSVをAWS s3へ転送
・・・までに使用した手順を解説します。
🔸使うもの
・BigQuery(SQL)
・スケジュールクエリ
・AWS認証情報(アクセスキー・シークレットアクセスキー)
・CloudFunction(Python)
※PythonでCSVマージしたい場合も参考になると思います。
🔹SQLとスケジュールクエリの設定
EXPORT DATA OPTIONS (
uri = 'gs://"バケット名"/"フォルダ名称(必要があれば)"/*.csv'
, format = 'CSV'
, overwrite = true
, header = true
, field_delimiter = ','
) AS ( SELECT * FROM PJ名.データセット名.TABLE_ID );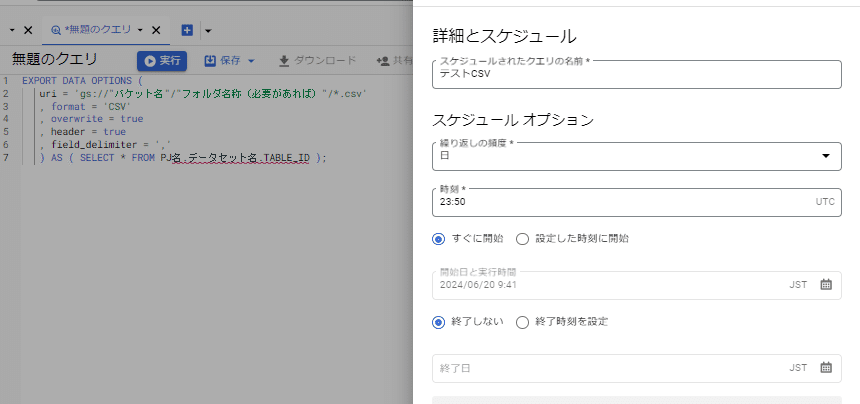
こんな感じで分割してCSV出力するSQLをスケジューラーで設定してあげます。すると、トリガーで任意のタイミングでCSV出力を定期的に行うことができるようになりますね。

🔹分割CSVのマージ
分割されたCSVについてはPythonの「Pandas」を使えば簡単にマージできるので、Pandasを使います。
Cloud FunctionのPython 3.11で動作は確認済みです。
#requirements.txt
google-auth==2.16.0
oauth2client==4.1.3
google-cloud-storage==2.7.0
google==2.0.3
google-auth-oauthlib==0.4.6
google-cloud-bigquery==3.4.2
google-cloud-bigquery-storage==2.18.1
pandas==2.0.3# main.py
import csv
import pandas as pd
import glob
from io import BytesIO
from google.cloud import storage
from datetime import datetime
from datetime import timedelta
from datetime import timezone
def merge_csv(event, context):
# GCSのクライアントを作成する
client = storage.Client()
# 結合するファイルのバケット名とプレフィックスを指定する
bucket_name = 'バケット名'
prefix = 'フォルダ名称(必要があれば)/'
JST = timezone(timedelta(hours=+9), 'JST')
target_datetime = datetime.now(JST)
suffix = target_datetime.strftime('%Y%m%d') + '_09:00:00.csv'
filename_1 = "CSV名称" + "_" + suffix
# ex.) "CSV名称"_20230611_09:00:00.csv
# バケットからファイル名を取得する
blobs = client.list_blobs(bucket_name, prefix=prefix)
blob_names = [blob.name for blob in blobs if blob.name.endswith('.csv')]
i = 0
# ファイルを結合する
with open('/tmp/merged.csv', 'w') as outfile:
writer = csv.writer(outfile)
for blob_name in blob_names:
blob = client.bucket(bucket_name).get_blob(blob_name)
content = blob.download_as_bytes()
if i == 0:
df = pd.read_csv(BytesIO(content))
i = 1
else:
df2 = pd.read_csv(BytesIO(content))
df = pd.concat([df, df2])
df.to_csv('/tmp/merged.csv',index=False)
# GCSに結合したファイルをアップロードする
bucket = client.bucket(bucket_name)
blob = bucket.blob(filename_1)
blob.upload_from_filename('/tmp/merged.csv')main.py・requirements.txtの中身としてはこんな感じです。
あとはデプロイして実行します。上記のコードだと分割されたCSVの1つ上の階層にマージされたCSVが出来上がってるはずです。
あと定期実行したい場合はトリガーを設定すればOKです。
🔹AWS s3にCSVを転送しよう
こちらも同じくCloud Functionで実行します。結論コードは何でもいいんですが自分が慣れているPythonを使います。
# requirements.txt
google-auth==2.16.0
oauth2client==4.1.3
google-cloud-storage==2.7.0
google==2.0.3
google-auth-oauthlib==0.4.6
google-cloud-bigquery==3.4.2
google-cloud-bigquery-storage==2.18.1
boto3==1.26.89# main.py
from datetime import datetime
from datetime import timedelta
from datetime import timezone
import tempfile
import os
from google.oauth2 import service_account
from google.cloud import storage
import boto3
def transfer(event, context):
# 送信先AWS認証情報の設定
AWS_ACCESS_KEY_ID="AWS_ACCESS_KEY_ID"
AWS_SECRET_ACCESS_KEY="AWS_SECRET_ACCESS_KEY"
Bucket = 'Bucket名称'
target_s3client = boto3.client('s3',
aws_access_key_id = AWS_ACCESS_KEY_ID,
aws_secret_access_key = AWS_SECRET_ACCESS_KEY,
region_name='ap-northeast-1'
)
# 送信元の情報
project_name = 'PJ名'
bucket_name = 'Bucket名称'
storage_client = storage.Client(project_name)
bucket = storage_client.bucket(bucket_name)
# 転送用日次ファイル
filename_1 = "CSV名称.csv"
Key_prefix = 'Bucket名称/フォルダ名称/'
Key_1 = Key_prefix + filename_1
# 転送対象ファイルのtempファイル名(プログラム実行時に一時ファイルとして保持する)
_, temp_local_filename = tempfile.mkstemp()
# ◆UPLOAD_1: filename_1
blob = bucket.blob(filename_1)
blob.download_to_filename(temp_local_filename)
file_size = os.path.getsize(temp_local_filename)
target_s3client.upload_file(temp_local_filename, Bucket, Key_1)
# 一時保持したファイルを削除
os.remove(temp_local_filename)main.py・requirements.txtの中身としてはこんな感じです。
あとはデプロイして実行します。これで対象のS3配下にCSVが転送されてるはずです。
とまぁ、今回は割と実用的な内容について解説してみました。
クラウドサービスの利用はだんだんと増えてきていますが、AWSの方が人気な様でGCPを使ったサービスに関してはまだまだ少ないかな〜って印象です。