
Pythonで株価予測にチャレンジ!

はじめに
こんにちは。jundoです。40代に突入し、自分の将来を考え、これからの時代はAIだっ!と一念発起!Aidemyにて機械学習を学んでいます。
今回は、これまでの学習を振り返りながら、Pythonで株価の予測にチャレンジしたいと思います。
実行環境
Python3
Windows11
Chrome
Google Colaboratory
私のレベル
プログラミング全くの未経験
セットアップ
必要なライブラリのインポート
まずは株価予測に必要になりそうなライブラリをインストールします。
import math
import pandas_datareader as web
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM
import matplotlib.pyplot as plt
import datetime
plt.style.use('fivethirtyeight')
stooqからメルカリ社の株価のデータを引用する
今回は、実際に私が現在保有している【4385 メルカリ】社の
株価を予測します。
2019/1/1~2022/7/8までのデータを利用します。
df = web.DataReader('4385.jp', data_source='stooq', start='2019-01-01', end='2022-07-08’)データを確認すると下記のように降順になっています。
昇順にする為、下記のコードを追加します。

df = df.sort_index()昇順になりました。

終値をプロットする
取得したデータに間違いないか確認も含め、チャートを表示させてみます。

ディープラーニングモデルの作成
では、ディープラーニングモデルを作成してみましょう。
#dfから終値だけのデータフレームを作成する。(インデックスは残っている)
data = df.filter(['Close'])
#dataをデータフレームから配列に変換する。
dataset = data.values
#トレーニングデータを格納するための変数を作る。
#データの75%をトレーニングデータとして使用する。
#math.ceil()は小数点以下の切り上げ
training_data_len = math.ceil(len(dataset) * .75)
#データセットを0から1までの値にスケーリングする。
scaler = MinMaxScaler(feature_range=(0, 1))
#fitは変換式を計算する
#transform は fit の結果を使って、実際にデータを変換する
scaled_data = scaler.fit_transform(dataset)
#正規化されたデータセットを作る。データ数はトレーニングデータ数にする
len(scaled_data)
train_data = scaled_data[0:training_data_len, :]
len(scaled_data)
#91番目の終値を予測するため、過去90日間の終値を含むトレーニングデータセットを作成します。
#x_trainデータセットの最初の列には、インデックス0からインデックス89までのデータセットの値(合計90個の値)が含まれ、
#2番目の列にはインデックス1からインデックス90までのデータセットの値(90個の値)が含まれます。
#y_trainデータセットには、最初の列のインデックス90にある91番目の値と、
#2番目の値のデータセットのインデックス91にある92番目の値が含まれます。
#データをx_trainとy_trainのセットに分ける
x_train = []
y_train = []
for i in range(90, len(train_data)):
x_train.append(train_data[i-90:i, 0])
y_train.append(train_data[i, 0])
x_train, y_train = np.array(x_train), np.array(y_train)
#LSTMに受け入れられる形にデータをつくりかえます
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
#LSTMモデルを構築して、50ニューロンの2つのLSTMレイヤーと2つの高密度レイヤーを作成します。(1つは25ニューロン、もう1つは1ニューロン)
#Build the LSTM network model
model = Sequential()
model.add(LSTM(units=50, return_sequences=True,input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dense(units=25))
model.add(Dense(units=1))
#平均二乗誤差(MSE)損失関数とadamオプティマイザーを使用してモデルをコンパイルします。
model.compile(optimizer='adam', loss='mean_squared_error’)
#モデルをトレーニングする
model.fit(x_train, y_train, batch_size=1, epochs=1)
#Test data set
#test_dataはtraining_dataから90コ減らしたデータ
#つまり90日間の終値から将来の終値を予測するためにtest_dataを用意する
test_data = scaled_data[training_data_len - 90: , : ]
#Create the x_test and y_test data sets
x_test = [] #予測値をつくるために使用するデータを入れる
y_test = dataset[training_data_len : , : ] #実際の終値データ
for i in range(90,len(test_data)):
x_test.append(test_data[i-90:i,0]) #正規化されたデータ
#Convert x_test to a numpy array
x_test = np.array(x_test)
#LSTMで受け入れられる形状にデータを再形成します
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
#テストデータを使用してモデルから予測値を取得します。
#モデルの予測価格値の取得
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)
#RMSEの値を計算/取得する
平方平均二乗誤差とは、誤差の二乗を平均して平方根した数字のことです。
生じた誤差を評価する指数、精度を表してくれます。
数字が小さいほど精度がいいということになります。
from sklearn.metrics import mean_squared_error
rmse = np.sqrt(np.mean(((predictions - y_test) ** 2)))
#rmse = np.sqrt(mean_squared_error(predictions, y_test))
rmse
予測結果
データをプロットして視覚化します。
train = data[:training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
#Visualize the data
plt.figure(figsize=(16,8))
plt.title('Model')
plt.xlabel('Date', fontsize=18)
plt.ylabel('Close Price ', fontsize=18)
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right')
plt.show()
損失関数、評価関数をグラフ化
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.layers import Dense, Activation, Dropout
from tensorflow.keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 784)[:6000]
X_test = X_test.reshape(X_test.shape[0], 784)[:1000]
y_train = tf.keras.utils.to_categorical(y_train)[:6000]
y_test = tf.keras.utils.to_categorical(y_test)[:1000]
model = tf.keras.Sequential()
model.add(Dense(256, input_dim=784))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation("sigmoid"))
model.add(Dropout(rate=0.5))
model.add(Dense(10))
model.add(Activation("softmax"))
sgd = tf.keras.optimizers.SGD(lr=0.1)
model.compile(optimizer=sgd, loss="categorical_crossentropy", metrics=['accuracy'])
# epochs数は5を指定
history = model.fit(X_train, y_train, batch_size=500, epochs=5, verbose=1, validation_data=(X_test, y_test))
#acc, val_accのプロット
plt.plot(history.history['accuracy'], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.plot(history.history['loss'], label="loss", ls="-", marker="o")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
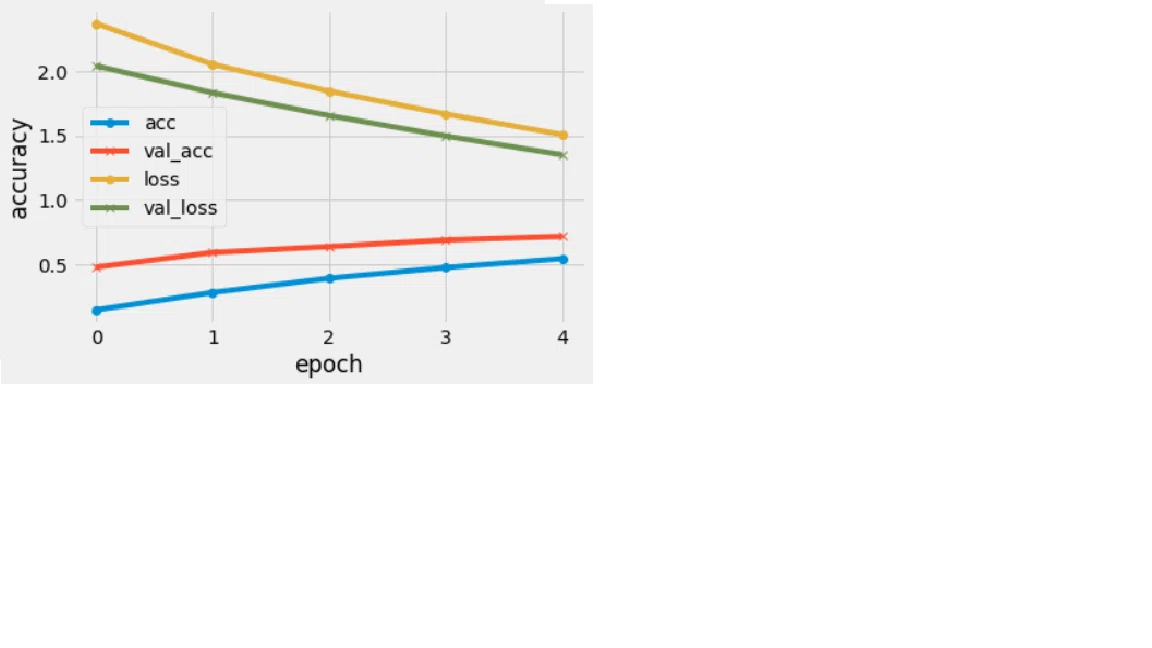
性能評価・考察
accuracy(正答率)を見ると、学習用データの結果(accuracy)、検証用データの結果(val_accuracy)ともに精度が右肩上がりです。しかしながら、0.5以下と、株価を予測するにはいささか精度が低過ぎます。
loss(損失値・誤差)は、検証データ(valid_ loss)、学習用データ(loss)共に右肩下がりなので過学習が発生している可能性があります。
まとめ
精度はイマイチでしたが、初めて自分で成果物を作成する事で、これまで学んできた事の復習になりました。
今回は説明変数として個別銘柄の過去のデータを用いただけの簡易的なものです。
今後の課題として、日経平均やTOPIX、NYダウや為替など、関連する指標を組み合わせて、より精度の高い予測モデルを作成したいと思っています。