Python 機械学習による銀座の地価変動予測

本記事の概要
・銀座における土地価格(公示地価)の今後の推移予測
参考サイト
はじめに
不動産に関わる仕事を始め、早5年が経過いたしました。
それまで営業をしていた私はこれまで不動産に関する知識はゼロの状態。
にも関わらず社内の部署異動で不動産関連に従事し、毎日知らない分野で齷齪していたものの、色々と経験を積みどうにか日々の業務をおこなっております。
初めて現在の仕事についてから、これまで聞いたことのあるニュースでも意識が変わりました。特に、
「日本で一番地価の高い地域 - 銀座 -」
この記事を読んでいただいている方も聞いたことはあると思います。
銀座4丁目交差点
この場所はこれまでどのように地価が推移してきたのか、そして今後はどのように推移していくのか、せっかく学んだ知識を活かし予測していきたいと思います。
本題にあたり、土地価格について簡単に補足いたします。
土地の値段とは?「一物四価」
同じ土地であっても目的別に4つの価格があるという考えです。
①公示地価
全国で定められた基準地での一般取引の指標価格。毎年国土交通省が発表している。
②実勢価格
実際の取引価格で、売る人・買う人間で合意した価格
③固定資産税評価額
土地所有者に課される各租税(固定資産税など)や不動産取得税などの算定基準となる価格評価額の見直しは3年毎。
④相続税評価額(相続税路線価)
土地の相続税や贈与税の算定基準となる価格
この内①の公示地価をベースに③④の価格の設定をされている点と、ある種相場以上の売りたい人・買いたい人の合意で価格が決まる②の実勢価格は予測が困難な点から今回は①の公示地価にフォーカスをして検討しいきます。
筆者のレベルと環境
レベル
プログラミング初心者。
環境
・Mac Book Air
・Chrome
・Google Colaboratory
データの準備
上記の参考サイトから東京都中央区銀座の地価データcsvをダウンロードし、中身を確認してみます。

データとしては1983年から2023年まで、指定された地域(住所)毎、年度別にされておりました。
ただし、今後の分析においてはいくつかの下準備をしておきたいと思います。
・公示地価以外・また一地域もデータのない年度データの削除(今回の目的はあくまで公示地価推移)
・日本語表記 → 英語・アルファベット表記へ
・行と列の入れ替え
下準備完了後のデータが以下となります。

ここで実際にgoogle Colaboratoryにてcsvファイルを取り込んで確認いたします。
#csvファイルのアップロード
from google.colab import files
uploaded = files.upload() 
headを使って上の5行だけ出力して状態を確認
import pandas as pd
ginza_land_price = pd.read_csv('./ginza_land_price.csv', engine='python', header=0,index_col=0,encoding = 'shift_jis')
print(ginza_land_price.head())取り組んだcsvデータ「ginza_land_price」には銀座12地点のデータと、その平均を取った計13の列データがあります。
平均のデータを用いて、一度時系列解析を行ってみます。
時系列解析
時系列解析とは
ここで時系列解析に関して簡単にご説明いたします。
データが時間の経過とともに変化するときに、その変化のパターンや特徴を分析する手法。時系列データは、時間に関連するデータポイントの系列であり、例えば株価、気温、売上データなどが該当。
時系列解析の目的は、過去のデータを分析し、将来の動向や予測を行うこと。
データのトレンド(長期的な変化)、季節性(周期的な変化)、周期性(周期的な変動)、ノイズなどの要素を分析し、そのパターンや関係性を把握。
様々な手法やモデルがあり、代表的な手法には、
「移動平均法、指数平滑法、自己回帰モデル(ARモデル)、移動平均自己回帰モデル(ARMAモデル)、自己回帰移動平均モデル(ARIMAモデル)、ベクトル自己回帰モデル(VARモデル)などがある。
時系列解析の実装
公示地価平均データ分析
それでは実際に実装していきます。
まずは必要なモジュールをインポートします。
#必要なモジュールの準備
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inlineここからはデータの準備をしていきます。
#データの読み込み
ginza_land_price = pd.read_csv(
filepath_or_buffer="./ginza_land_price.csv",encoding="Shift-JIS",
dtype={'x02': 'float64'})
#データの整理
#indexに期間を代入
index = pd.date_range('1984', '2024', freq='Y')
#indexを代入
ginza_land_price.index = index
#カラムを削除
del ginza_land_price['Year']現在のcsvデータには先に記載した通り計13列のデータがあります。
そのうち、全年度のデータが整っている「ginza official land price average」の列のみを抽出します。
# ginza official land price averageの抽出
ginza_land_price_average = ginza_land_price["ginza official land price average"].replace(",", "", regex=True).astype(int)ここでポイントとして記載いたします。
ginza_land_price_average = ginza_land_price["ginza official land price average"]最初は上記のコードで進めておりましたが、この先の時系列解析の実装時に下記のエラーが発生いたしました。
ValueError: attempt to get argmin of an empty sequence
その原因としては、準備したcsvデータにありました。改めてcsvデータをよくみてみると、、

数値データに「 , 」があり、これがエラーの原因となっておりました。
機械学習時はまずはデータの下準備をしっかりと確認することを忘れないようにしたいと思います。
ginza_land_price_average = ginza_land_price["ginza official land price average"]
↓
ginza_land_price_average = ginza_land_price["ginza official land price average"].replace(",", "", regex=True).astype(int)ここで現在のデータ状況を確認します。
私のように初心者、まだまだ不慣れな人間はしつこいぐらい都度確認してみてもいいかと思います。
print(ginza_land_price_average.head())
続いていよいよ時系列解析の関数を設定いたします。
# orderの最適化関数
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]モデルを構築します。
# SARIMAモデルを用いて時系列解析
best_params = selectparameter(ginza_land_price_average, 12)
print(best_params)
SARIMA_ginza_land_price_average = sm.tsa.statespace.SARIMAX(ginza_land_price_average, order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()
それではいよいよ予測してみます。ここでは2070年までのデータを予測してみましょう。
# 予測
# predに予測期間での予測値を代入してください
pred = SARIMA_ginza_land_price_average.predict('1984', '2070')
# グラフを可視化してください。予測値は赤色でプロットしてください
plt.plot(ginza_land_price_average)
plt.plot(pred, "r")
plt.show()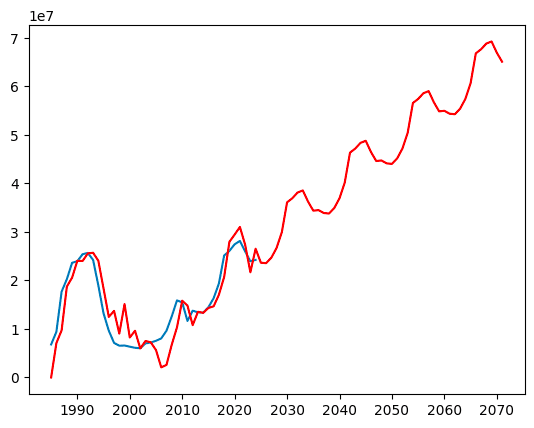
この赤い線が今回のSARIMAモデルを用いた銀座の土地価格(公示地価)の価格推移予測となります。
上記によると、今後の2045年ごろの銀座の土地価格は1㎡で大凡5,000万円になる、、、恐ろしい金額ですね。。
ただし、このモデルは見る限り今後基本的には価格が上がり続けてしまうように見受けられます。
最高値地点と最安値地点
ここからはもう少し予測の精度を高めていき、また「ginza official land price average」以外のデータ、特に直近で最高値となっている「4-5-6 ginza Chuo-ku TOKYO」と反対の最安値「2-16-12 ginza Chuo-ku TOKYO」についても調べていきたいと思います。
ちなみに「4-5-6 ginza Chuo-ku TOKYO:東京都中央区銀座4-5-6」と
「2-16-12 ginza Chuo-ku TOKYO:東京都中央区銀座2-16-12」はここです。
『東京都中央区銀座4-5-6』

『東京都中央区銀座2-16-12』

『東京都中央区銀座4-5-6』は銀座4丁目の交差点、和光や山野楽器のところですね。
予測の精度確認
先ほどのコードにおいて
# SARIMAモデルを用いて時系列解析
best_params = selectparameter(ginza_land_price_average, 12)ここでパラメータを12で設定しておりました。
例えば気温データなどであれば1年毎の周期となり、12ヶ月=12で設定することとなりますが、今回のような解析では周期が明確に●●と言いにくい状況ですので、この12という値をいくつか変えて試してみます。
best_params = selectparameter(ginza_land_price_average, 6)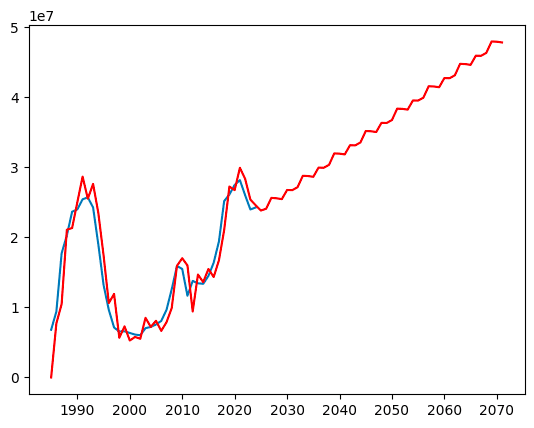
best_params = selectparameter(ginza_land_price_average, 18)
best_params = selectparameter(ginza_land_price_average, 24)
パラメータを6.12.18.24で確認してみましたが、グラフの波形をみると12が1番に見受けられます。
それではここから12の地点のうち最安値『東京都中央区銀座2-16-12』と最高値『東京都中央区銀座4-5-6』についても同様に時系列解析をしていきたいと思います。
『東京都中央区銀座2-16-12』
まずは『東京都中央区銀座2-16-12』について
ここで改めてcsvデータを確認してみます。
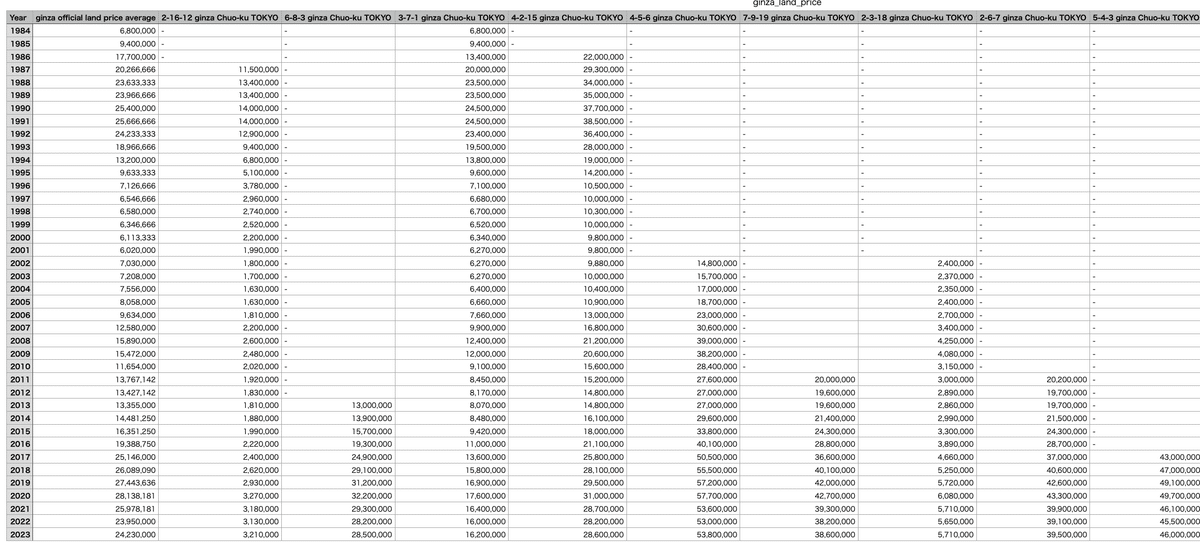
先ほど平均である『ginza official land price average』について抽出しましたが、今回の『2-16-12 ginza Chuo_ku TOKYO』ではデータに欠損があります。
現在欠損値は「 - 」となっておりますが、このまま行の抽出をすると「 - 」が悪さをしてしまい、エラーが発生してしまいました。
同時にカラム名称にも『2-16-12』のように「 - 」を用いていたため、このタイミングでではありますが、一度csv自体を加工いたしました。

欠損値「 - 」を「NaN」に、そしてカラム名称も「 - 」ではなく「 _ 」にいたしました。
今後はデータ前処理において、事前に扱いやすいデータに整えておくことを忘れないようにしたいと思います。
それでは改めて、『2-16-12 ginza Chuo_ku TOKYO』について
欠損値「NaN」を今回は0で置き換えいたします。
#最安値である住所での予測
# 2_16_12 ginza Chuo_ku TOKYOの抽出
ginza_land_price_2_16_12= ginza_land_price['2_16_12 ginza Chuo_ku TOKYO'].fillna(0)
ginza_land_price_2_16_12= ginza_land_price_2_16_12.replace(",", "", regex=True).astype(int)
print(ginza_land_price_2_16_12.head())
#モデルの構築
best_params = selectparameter(ginza_land_price_2_16_12, 12)
print(best_params)
SARIMA_ginza_land_price_2_16_12 = sm.tsa.statespace.SARIMAX(ginza_land_price_2_16_12, order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()# 予測
pred = SARIMA_ginza_land_price_2_16_12.predict('1984', '2070')
# グラフを可視化
plt.plot(ginza_land_price_2_16_12)
plt.plot(pred, "r")
plt.show()
『東京都中央区銀4-5-6』
同様に、最高値『東京都中央区銀座4-5-6』について
#最高値である住所での予測
# 4_5_6 ginza Chuo_ku TOKYOの抽出
ginza_land_price_4_5_6= ginza_land_price['4_5_6 ginza Chuo_ku TOKYO'].fillna(0)
ginza_land_price_4_5_6= ginza_land_price_4_5_6.replace(",", "", regex=True).astype(int)
print(ginza_land_price_4_5_6.head())
#モデルの構築
best_params = selectparameter(ginza_land_price_4_5_6, 12)
print(best_params)
SARIMA_ginza_land_price_4_5_6 = sm.tsa.statespace.SARIMAX(ginza_land_price_4_5_6, order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()# 予測
pred = SARIMA_ginza_land_price_4_5_6.predict('1984', '2070')
# グラフを可視化
plt.plot(ginza_land_price_4_5_6)
plt.plot(pred, "r")
plt.show()
可視化と考察
ここで3つのグラフが出揃いましたのでmatplotlibを用いて、一括出力してみたいと思います。
比較
可視化するためのコード
#figure()でグラフを表示する領域をつくり,figというオブジェクトにする.
fig = plt.figure()
#add_subplot()でグラフを描画する領域を追加。行,列,場所
ax1 = fig.add_subplot(3, 1, 1)
ax2 = fig.add_subplot(3, 1, 2)
ax3 = fig.add_subplot(3, 1, 3)
c1,c2 = "blue","red" # 各プロットの色
ax1.plot(ginza_land_price_average, color=c1)
ax1.plot(pred1, color=c2)
ax2.plot(ginza_land_price_2_16_12, color=c1)
ax2.plot(pred2, color=c2)
ax3.plot(ginza_land_price_4_5_6, color=c1)
ax3.plot(pred3, color=c2)
これで銀座12地点公示地価の平均価格と最高値地点・最安値
地点の3つのデータが揃いました。
考察
今回の分析結果のグラフから確認できる事実として
・銀座の平均価格は今後緩やかに上昇
・最安値地点、銀座2丁目に関しては1990年ごろをピークに2000年頃からは横ばい
・最高値地点は計測されたから上昇傾向が続いている。
事実事項からの今後の予測としては
・最安値地点は時系列解析によると今後の地価としては上昇も下落もしないことが予測される。
・最高値地点は今後も更なる地価高騰が予測でき、2050年頃には現在のおよそ2倍の価格、2070年頃にはおよそ3倍ほどまでの高騰が予測される。
・最安値はほぼ横ばいながら平均価格も今後上昇が予測されることから、
今回計測していない地点の10地点の地下においても下落は起こりにくく、
いずれの地点でも横ばいもしくは上昇が考えられる。
以上の点から銀座における不動産地権者に関しては今後も土地所有により資産価値としては上昇していくが、一方で土地価格が上がると伴い固定資産税も高騰していく。
また新規でデベロッパーなど、土地所有での事業を考えている際には時間を掛ければ書けるほど土地価格は高騰していくため、早めに着手するに越したことはないだろう。
最後に
冒頭にも記載したが、今回の分析はあくまで国が公表する公示地価による変動の分析である。
実際に土地の取引における”値段”というのは「相場」と「買い手の事情」「売り手の事情」、土地の状況(土壌汚染や既存建物有無)や地区計画、再開発計画など、様々な用件によって複雑であり、一方で当事者同士の利害だけで決まるものでもあります。
大切なことは相場はあくまで相場。そして大きな金額で取引される不動産という点において、今後の地価をどのように予測していくかが重要であると考えます。
今回は公表されているデータを活用して分析したため、地点毎に異なる年度でのデータであり、そもそものデータ数としても決して十分なものが揃っていたとは言えません。
今回のをきっかけに、今後もデータ分析に取り組んでいきたいと思います。