
AWSを駆使したクラウドデータサイエンティストになるための教科書:ネットワークを理解しよう

EC2インスタンスを使ったデータ分析環境を構築しよう

データサイエンスを始めた頃は多くの場合、ご自身のローカルPCの実行環境でデータ分析を行っていると思います。しかし、扱うデータが大きくなるにつれ、より高スペックなマシンが必要になってきますが、それで数十万円、数百万もするようなデスクトップPC買える人はそう多くないでしょう。google colaboratoryを利用するという手もありますが、ビジネスユースの場合なかなか秘匿性の高いデータを扱うのは怖いですし、結局何かしらの本番環境で運用する必要がでてきた場合はAWS等のサービスを利用する場合がほとんどです。
そのため、データをクラウド環境で分析できるようになれると何かとキャリアアップにつながります。
本項ではそうしたクラウドデータサイエンティストになるために必要な知見をご紹介出来ればと思っています!
今回は特にAWSのec2インスタンスを立ち上げてデータ分析環境を構築できるように必要な学習をしていきましょう!
ネットワークを理解することの重要性

EC2のようなサービスを利用していく上でネットワークを理解しておくことはとても大切です。なぜなら結局はこうしたEC2インスタンスは何かしらの通信を外部と行うことになるためです。むやみに変な通信を受けたり、逆に誤って大切なデータをどこかに送信してしまわないようにネットワークがどう行ったものかを理解しておくのは避けては通れない道なのです。
AWS特有のネットワークを理解する前に一般的なネットワークを理解しよう
AWSのネットワークを勉強しようとすると実に様々な専門用語が出てきます。VPCやIWG、NATゲートウェイなどなど、数多くの用語の出現に独学でネットワークを勉強しはじめて挫折した方も多いのではないでしょうか。その気持ちは痛いほどよく分かります。私も何度も挫折してきたその1人です。(笑)
ただでさえデータサイエンティストからしたらネットワークは興味の中心ではないので勉強のモチベーションはダダ下がりです。
加えてネットワークの勉強は体系的に理解しないと理解しづらい部分が多く断片的にバラバラに概念を学んでも意味のつながりが理解できません。ネットワークと言うだけにその学習もまた、点ではなく点を繋げた線で理解することが必要です。
そういう意味でchatGPTも点の解説をしてくれますがなかなか全体像を線で教えてくれないので独学には本当に骨が折れます。
この記事ではできるだけネットワークというものを線で感覚的に理解していただけるように解説していきます。そしていきなりVPCのようなAWSの概念から説明するのではなくネットワーク全体を理解するところから入りますので安心してください。
では早速ネットワークの解説に入っていきたいと思います。
通信の基本

ネットワークは何をする場所でしょうか。ズバリ通信です。そして通信は、ネットワークという仮想世界における荷物配送です。荷物配送なのでそこには送り主、宛先、荷物という3つの要素が存在します。ネットワークを勉強する時はこの3点を意識すると理解しやすいです。なぜならネットワークにまつわる概念の多くはいかに安全に、そして効率的に正しい荷物を送ったり受け取ったりできるようにできるかといったものだからです。
さて通信は現実世界における荷物配達だと説明しました。それをネットワークの配送と置き換えた時に次のように言うことが出来ます。
ネットワークにおける通信は
・ 荷物=パケット(何をやりとりするのか)を
・ From(どこかのIPアドレス)から
・ To(どこかのIPアドレスに)届ける
ということです。
IPアドレスは後で解説しますがネットワークにおける住所です。皆さんは自分が荷物を送ったり、貰ったりあるいは時には配送会社になった気持ちで視点を切り替えながら理解をしてみてください。
現実世界の荷物配送とネットワーク空間の荷物配送の根本的な違い

さて、ネットワークの通信は仮想世界における荷物配送ではあるのですが一点だけ現実世界とは根本的に違う点があります。それは仮想世界における荷物配送は基本的にリクエストして荷物が配送されるという点です。現実世界でも誰かに荷物を送る時はその人から荷物送ってと頼まれたから送るといケースもあります。現実世界でネットワークの配送を例えるなら、まずリクエストが書かれた紙だけを配送し、そのリクエストを受け取った人はリクエスト内容に基づいて荷物を送り返すと言った感じです。この点だけは予め理解しておくと混乱が防げると思います。
荷物を送りあうためのネットワーク上の住所:IPアドレス
Ipアドレスはネットワーク空間において通信を行うデバイスを特定するためのいわば住所の役割を果たしています。現実世界でも住所の書き方は、日本なら「都道府県ー市区町村ー番地」というルールの元表記をすることで誰しもが住所を認識理解することができます。
IPアドレスにも記法にルールがあります。そのルールの元で表現をすることで仮想空間上での住所の共通認識ができているのです。
IPアドレスは歴史上の理由からIPv6とIPv4の2種類があり、それぞれに書き方のルールがあります。まだまだIPv4の方が主流ですが今後はいIPv6が主流となっていくと考えられます。
IPv4とIpv6とは?

どちらもネットワーク空間での住所を示す記法ですがこれまではIpv4しかありませんでした。しかしインターネットの普及によってこの住所の番号が枯渇して対応しきれなくなったためIpV6が誕生しました。ここでは現在も主に使われているIpv4nに限って説明します。
IPv4は32bitで表現する住所の書き方
Ipv4は32bit(ビット)で示すことができるIPアドレスです。ビットとは0と1の組み合わせで、コンピュータの世界ではこのOn/Offのスイッチのような0と1で全ての情報が表現されます。32ビットとはつまりon/offスイッチが32個あるという意味になります。0か1の2通りのスイッチが32個あるので、2の32乗の組み合わせ=約43億個の住所をIPv4は表現することが出来ます。逆に言えばそれIpv4がアドレスを表現できる限界になります。
「あれ、私が知っているIPアドレスは、確か192.111.11.1のようなものだった気がしたんだけど」
そう思われた方もいらっしゃると思います。
確かに私たちが一般によく見かけるIpv4のIPアドレスは「192.111.11.1」のような数値であり、32個の0と1の組み合わせではありません。実はこれは2進法と10進法による表現の違いであり、同じものを指しています。たいていの人は2進法に普段から慣れていないので、32ビットを10進法に変換しているのです。
「あと、数字の間にあるドットはなにか意味があるの❓」
よく見るとIPアドレスは数字の間に4つのドットがあります。これは、コンピュータというのは基本的に1ビットごとに何か処理をするのではなく8ビット単位で処理をすることに由来していると言われています。また純粋にドットなしの数字の羅列は可読性が低いという理由からドットを打って読みやすくしているとされています。なので、32ビットですが、通常は4つの8ビットという形で表現するということを理解しておいてください。またドットごとに区切られた範囲をオクテットと呼んだりもします。
■ 32ビットを2進法で示した場合
例:11000000101010000000000100000001
■ 4つの8ビットを2進法で示した場合(確かに上と比較しても可読性が上がりますね)
例:11000000. 10101000. 00000001 . 00000001
■32ビットを10進法で示した場合
例:19216811
■4つの8ビットを10進法で示した場合
例:192.168.1.1
確かに上で並べた時に10進法のドットありが1番間違いなく数字を理解出来ますよね。
8ビットの2進法を10進法に変換する方法
11111111が8ビット2進法の最大値ですので、これを10進法に変換してみましょう。
変換ルールは難しくありません。
「2の(桁数-1分の乗数)に各桁の数をかける。それらを足し上げる」
$$
(2^7 \times 1) + (2^6 \times 1) + (2^5 \times 1) + (2^4 \times 1) + (2^3 \times 1) + (2^2 \times 1) + (2^1 \times 1) + (2^0 \times 1)
$$$$
128 + 64 + 32 + 16 + 8 + 4 + 2 + 1 = 255
$$つまり、8ビットは10進法で最大数は255になります。
そのため、10進法で示すIpv4のIPアドレスは0~255の間の数をとる4つのセットで表現されることになります。
10進法で表現するIPv4
0-255.0-255.0-255.0-255各オクテットは何を意味するのか?
4つのオクテットは、意味があります。
前半の3つのオクテット(つまり8ビット×3=24ビット)はネットワーク部、最後のオクテット(8ビット)はホスト部を示すということです(例外もあります)。
ネットワーク部とは現実世界でいうとあなたの自宅を示す住所そのものです。一方でホスト部は自宅の誰宛なのか、つまりその自宅というネットワーク内のどのデバイスなのかを特定するための番号になります。
例えば192.111.11.1をIPとして持つルーターと192.111.11.2のIPをもつスマホがあったとします。2つのIPアドレスがあった場合に前半3つのオクテット192.111.11は共通しています。これはこのふたつが同じ住所にあることを示しています。そして最後の1と2でルータなのかスマホなのかを識別しているのです。
ただし、あなたのスマートフォンのIPアドレスについて外部からネットワーク部とホスト部両方知られていては、なんか危険だと思いませんか?それはあなたのスマホに直接変な情報を通信して送り付けられるリスクがあることを示します。そのため実際にはあなたのスマホの住所はインターネット(自宅外)外には晒されていません。インターネット側に住所が晒されているのは一般的なご家庭のネットワークであれば実はルーターだけなのです。また晒されている住所というのはIPアドレスの中でもグローバルIPと呼ばれるものです。グローバルIPに対して、自宅のネットワークのように内側のネットワークで利用されるIPはプライベートIPと呼ばれるものです。グローバルIPがあることで、ご自宅のスマホ等のデバイスのIPアドレスを晒すことなく外側との通信が可能になっているのです。またグローバルIPがあることで実質的に43億個以上のデバイスが通信を行うことができています。
グローバルIPは外との通信で利用されるIPでネットワークを特定することに利用される。プライベートIPはネットワーク内のデバイスを特定してするのに利用される
Ipv4は32ビットなのでIPアドレスは約43億個だと説明しました。IPアドレスが開発された1970年代では43億個もIPアドレスがあれば十分だったのですが、今は一人1台スマホを持つような時代です。80億人の人間が地球上にいる中で43億個のIPアドレスはとっくに枯渇しているはずです。しかし、いまだに皆さんのデバイスとかでIPアドレスを確認するとIpv4の32ビットのアドレスも使われています。
これは、グローバルIPがあることで実質的に43億個以上のデバイスを管理できるようになっているためです。
グローバルIPとは世の中にあるネットワークを特定するために利用されます。
イメージしてみてください。あなたの自宅ではインターネットを契約していて、自宅ではパソコンやスマホ、テレビ等をインターネットにつなげていますよね?この時Wifiでつないでいるなら例えば「Buffalow-A-XXXX」のようなものにつないでいますよね?それはパソコンだろうがスマホだろうがつなげているものはみんな「Buffalow-A-XXXX」のようなもののはずです。この「Buffalow-A-XXXX」が一つのネットワークです。
別の言い方をすればこのネットワーク内にはあなたの自宅のパソコン、スマホ、テレビなどのデバイスが参加していることになります。
もしグローバルIPとプライベートIPという区別なく世の中が一種類のIPアドレスでやり取りしていたなら、パソコン、スマホ、テレビで3つのIPアドレスを消費してしまいますね?しかし、グローバルIPとプライベートIPがあることによって、グローバルIP上では、特定されるのはネットワークのみです。より具体的にはグローバルIPは基本的にあなたのネットワークのルータにのみ割り当てられます。あなたのパソコンやスマホなどはグローバルIPを普通は持っていないのです。
では、なんでネットワーク空間上の住所であるIPアドレスを持たないあなたのスマホはインターネット空間から荷物(情報)を送受信できているのでしょう?それはあなたの家にあるルーターが一旦ネットワーク空間から情報を受信し、ルーターが適切なデバイスに情報を受け流しているからなのです。この時に利用されるのがプライベートIPアドレスです。プライベートIPとは一つのネットワーク空間内でデバイス等を管理するために利用されるIPアドレスです。そしてネットワークが異なればプライベートIPは重複して利用することができます。これによって43億個以上のデバイスを管理することができるようになっているのです。
ちなみにプライベートIPで利用できるIPアドレスは43億個のうち、以下の範囲で利用できるルールになっています。
10.0.0.0 ~ 10.255.255.255(10.0.0.0/8) → 約1億6,700万個
172.16.0.0 ~ 172.31.255.255(172.16.0.0/12) → 約1,048万個
192.168.0.0 ~ 192.168.255.255(192.168.0.0/16) → 約655,000個
※4つのオクテットの後ろに「/8」とか書いてあるのはネットワーク部のビット数を示す表記方法でサブネットマスクと呼ばれます。この場合32ビットのうち最初の8ビットをネットワーク部としてIPアドレスを利用しているという意味になります。ちなみにIPアドレスは8ビット単位のオクテットで管理されやすいという話をしました。なので昔はネットワーク部で利用するのが1オクテット、2オクテット、3オクテットでそれぞれクラスA、クラスB、クラスCのようなネットワーク部の管理をしていました。しかし、これではネットワーク部とホスト部のIPアドレス32ビット分を無駄なく使うことができないケースがあります。だって8ビットでネットワーク部足りなかったら次は16ビットになっちゃいます。これをオクテットの単位に縛られずに1ビット単位で効率的にネットワーク部とホスト部のIPアドレスを管理できるようにした新たな方式をCIDR方式と呼びます。上記の例の/12はまさしくCIDR方式だから実現できるものです。これは最初の12ビットをネットワーク部に利用していることになるので、8ビットでも、16ビットでも32ビットでもありません。
逆に言えば、これ以外のIPアドレスの範囲で利用できるIPアドレスが基本的にはグローバルIPで利用できる範囲になります(一部例外はあります)。
つまり全世界のデバイスの数分だけIPアドレスがある必要はなく、全世界のネットワークの数だけIPアドレスがあればいいのです。まぁ、それでも1世帯に1台のルータがあってインターネットに接続したり、1企業にもネットワークは1つはほぼ確実にあるわけですから、IPアドレスは足りなくなってきます。そう、だからIPv6が生み出されているのです。
「あれ、でもルータはどうやってプライベートIPを通じてインターネットからの受信情報を適切なデバイスにパスできるんだ?」
そういう疑問を持った方は鋭いです。仮にグローバルIP側から通信があったとしてグローバルIPはネットワークの特定しかできないので、そのネットワーク内のどのデバイスに情報を届けるべきかを情報として保持していません。でもよく考え見てください。あなたはスマホであるサイトを閲覧しようとしてURLをクリックします。するとそれは「このサイトページの情報をくれ」というリクエストをまずあなたのスマホから送信していることになります。そしてそのリクエスト情報はまずルータに送られます。ルータはこのリクエスト情報をあなたのスマホから受信した時点で「このリクエストはスマホから来たものだ」と記録をしているのです。そして改めリクエストに対してインターネット空間からレスポンスがあなたのネットワークに帰ってきたらまずルータがその情報を受信し、「このIPにリクエストしたのはスマホだから、スマホに返す」という感じで情報をスマホに返すのです。これによって実際には通信が成立するのです。冒頭で現実世界とネットワークの通信は配送作業だけど根本的に違う点があるという点を説明しましたが、その特性はこういう部分で生かされています。
Portについて

通信はIPアドレスによって送り先から宛先へと到達します。現実世界でいえばそれで問題ないのですが、実はネットワークでは通信を効率的に成立させるためにもう少し工夫が必要です。例えば、現実世界で届けられる荷物は葉書であっても、配送物であっても郵便ポスト、宅配ボックス、直接受け取りをすればそれでで済みます。一方でネットワークでは、基本的にネットワーク空間内のデバイスがリクエストし、そのレスポンスをデバイスに戻すような双方向の配送業務です。仮にその通信でやり取りしているものがWebページのHTTPだとしたら、それはWebブラウザのようなアプリケーションが「Webページをください」というリクエストをそのWebサイトを管理しているどこかのサーバーに送信し、最終的にデバイスのそのWebブラウザにサーバーからレスポンスが渡されなければいけません。これが仮にレスポンスがデバイス内のメーラーのような別のアプリケーションに渡されてしまっては通信が成立しないのはなんとなくわかりますよね?このようなことがないようにデバイス内のどのアプリケーションに通信の内容を渡すのかを定義するのがPortです。言い換えれば、このPortを通った通信はこのアプリケーションに渡すとか、こっちのPortではいってきたものはこの通信プロトコルなので、こっちで処理する、といった具体にポートによってデバイス内でその通信を最終的にどう処理すべきかを定義しているのです。
通信でやりとりされる荷物「パケット」

これまでネットワーク内の荷物がFrom(誰から)、To(誰に)対して送られるのか、その際に利用される住所はなんなのかについてを詳しく解説してきました。ここではそもそもそこでやり取りされている荷物そのものを解説していきます。
基本的にネットワーク空間でやり取りされている情報(データ)は「パケット」という単位で送受信がされています。要は現実世界の荷物はネットワーク空間では「パケット」なのです。
現実世界でも大きな荷物は一つの段ボールでなく、複数の段ボールに分けて配送されますよね?パケットはこの一つ一つの段ボールのイメージに近いです。大きなウェブサイトの情報を得るときは複数のパケットに分けて通信が行われます。現実世界とちょっと違うのは、基本的に現実世界なら複数の段ボールは同じトラックで運送されますが、パケットはたとえ一つの荷物の小分けだとしても違うトラックでしかも別の配送経路で配達されることもあります。
ちなみにこうしたパケットによる通信ではないものがストリーミング方式です。よくライブ配信やWeb会議などをやりますが、こうした際の通信は連続で通信結果を安定的に届ける必要があるため、ストリーミング方式というパケット方式とは異なった方式の通信方法がとられます。
さて、ネットワークの世界では、先に欲しい荷物をリクエストし、リクエストされた側はその内容に則した荷物をレスポンスとして返送します。ここではHTTPリクエストとレスポンスの例で荷物について詳しくみていきます。HTTPレスポンスとは、あなたがスマホでChromeブラウザでたとえばAmazonのサイトURLをクリックするようなアクションです。そうすると瞬時にAmazonのサイトがスマホ画面に表示されますね?あれがレスポンスです。
データサイエンティストとしてはWebスクレイピングをしているときにHTTPレスポンスはよくお世話になりますね。中身はHTMLなどで書かれたファイルです。それがHTTPレスポンスの荷物の中身ってことですね。HTTPリクエストとレスポンスには荷札がついていて、その荷札によって送信元や送信先等の情報がやり取りされています。
パケットの具体例:HTTPリクエストでWebページのアクセスを求める
パケットには荷札がついています。現実世界と少し異なり、リクエストしてレスポンスがくるので、「どこに何を」リクエストし、そのレスポンスをもらうか?という荷札がついています。荷札は一枚じゃなく、複数枚ついていて、それぞれに異なる情報が書かれています。
🔸 アプリケーション層の荷札(HTTPデータ)
GET / HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0
Accept: text/htmlこんな感じでHTTPリクエストのアプリケーション層の荷札には、この通信が
・荷物をどうしたいのか(GET/POST)
・宛先(HOST):宛先となるURL
・送付元(User-Agent):送付元となるアプリケーション
・どういう荷物なら受け取れるか(Accept)
という情報が記載されます。
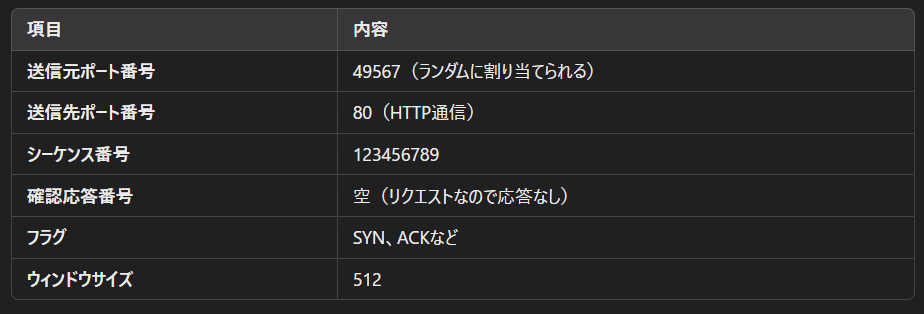
🔸 トランスポート層の荷札(TCPヘッダー)
トランスポートの荷札には以下の情報が記載れています。
送信元のポート番号
送信先のポート番号
シーケンス番号:複数のパケットにわかれたときにシーケンス番号によって順番が定期されています。最初のシーケンス番号(ISN: Initial Sequence Number)はランダムに設定されます。
確認応答番号 (ACK):受信側が次に受け取りたいデータの番号
フラグ:通信のステータスを示します。SYNなら通信を開始、ACKならデータを受信した、FINなら通信の終了といった具体です。
ウィンドウサイズ:受信側のデバイスが現在受け入れ可能なデータ量をバイト数で示しています。送信側はウィンドウサイズ以上のデータを送っても受信側がデータを受信できないと理解できるということです。なおウィンドウサイズ以外にもパケットのサイズを制限するルールがあり、それはMTUと呼ばれます。MTUは一パケットあたりの最大バイト数です。そのためMTU以上に大きなバイト数をもつパケットにならないように通信は分割されます。
🔸 ネットワーク層の荷札(IPヘッダー)
送信元IPアドレス:この例ではプライベートIPのように記載されていますげ、現実的にはホームネットワークからのリクエストならルータのグローバルIPとなります。
パケット識別番号:通信が複数のパケットに分割されたとき、同じ一つの大きなパケットであることを示す番号です。例えばパケット45678が2つのパケットに分割されたとして、それらのパケットは両方ともパケット識別番号に45678を持つので通信が到着した後で適切に同じパケットだと同定することができます。
TTL:あるパケットが通過することができるルータの最大数を示します。ルータがパケットを転送するたびに、TTLの値は1ずつ減少します。TTLが0になると、そのパケットはネットワーク上で破棄され、送信元にエラーメッセージ(ICMPメッセージ)が返されます。これにより、パケットがループすることを防ぎます。

🔸 データリンク層の荷札(イーサネットヘッダー)
これまでMACアドレスの説明はしていませんでした。上記まででは例えば一般的なホームネットワークであればネットワーク層の送信元IPアドレスがルータのグローバルIPをさし、ルータがNAT機能でホームのローカルネットワーク内のプライベートIPに対して適切に通信をより分けることで通信が成立すると説明してきました。しかしより厳密にはプライベートIPだけではデバイスを特定することができません。デバイスを特定するためには各デバイスが一意にもつMACアドレスというIDとプライベートIPを紐づけることで初めて実現します。物理世界で考えるならプライベートIPは土地そのものを特定するものだと考えるといいかもしれません。荷物の届け先はその土地に立っている家ですよね?家には表札があります。この表先がMACアドレスだとイメージしてください。その土地に住む人が変われば表札も変わりますよね?つまりその土地を一意に特定したとしてその土地に建つ家と土地がきちんと紐づいていなければ荷物は届かないのです。

補足ですがHTTPリクエストに紐づく4つの荷札はすべてがリクエスト先のサーバーに届くわけではありません。データリンク層の荷札はルータで留め置かれます。なのでインターネット空間にあなたのデバイスのMACアドレスがさらされることはありません。
パケットの具体例:HTTPリクエストでWebページのレスポンスがくる
以下のようなHTTPヘッダーに加えてリクエスト時のTCPヘッダーとIPヘッダーが付与された状態で一つのパケットとして通信が送り返されます。
🔸 HTTPレスポンス
HTTP/1.1 200 OK
Date: Fri, 13 Dec 2024 12:34:56 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 138
Connection: keep-alive
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Example Page</title>
</head>
<body>
<h1>Welcome to Example.com</h1>
<p>This is an example HTTP response.</p>
</body>
</html>
ステータスライン
HTTP/1.1 200 OK
HTTP/1.1 は使用されているHTTPのバージョンを示します。
200 はステータスコードで、リクエストが成功したことを示します(200 OK は最も一般的な成功ステータスコードです)。
レスポンスヘッダー:
Date: Fri, 13 Dec 2024 12:34:56 GMT: レスポンスが送信された日時。
Server: Apache/2.4.41 (Ubuntu): サーバーソフトウェアの情報。
Content-Type: text/html; charset=UTF-8: レスポンスボディの内容タイプと文字エンコード。
Content-Length: 138: レスポンスボディの長さ(バイト単位)。
Connection: keep-alive: 接続を維持するかどうかを指定。keep-alive は接続を閉じずに再利用することを意味します。
その他のHTTPステータスコード例
200 OK: リクエストが成功し、要求されたデータが正常に返された場合。
301 Moved Permanently: リソースが恒久的に移動した場合。
404 Not Found: リクエストしたリソースが見つからなかった場合。
500 Internal Server Error: サーバー内でエラーが発生した場合。
HTTPレスポンスは、ステータスコードとヘッダー、そしてボディで構成されており、リクエストに対して必要な情報をクライアントに提供します。
終わりに
いかがでしたでしょうか。今回はAWSのネットワークを理解するために一般的なネットワークについて解説しました。実際にどんなプライベートIPが利用されているのかなどはルータの管理画面から確認することができますし、IPアドレスの振り分けなども一部のルーターでは設定することができます(ちなみにルーターに割り当てられるグローバルIPは基本的に契約しているインターネットプロバイダが割り当てを行っています)。またHTTPリクエストやレスポンスが具体的にどういう感じなのかを可視化してくれるWebサービスも世の中にはあるので、実際に確認してみたいという方は一度見てみてよ理解を深めるのもいい勉強だと思います。
次回以降はAWSのネットワークについて解説を行っていきます。