DETR(DEtection TRansformer)解説

DETRは、物体検出タスクに革新をもたらしたモデルです。以下にDETRの主要な特徴と仕組みをまとめます。DETRの正式な発音は明確に定義されていないようですが、一般的には "ディーター" または "デトル" と呼ばれることが多いようです。
概要
DETRは「DEtection TRansformer」の略で、Facebookの研究チームによって2020年に発表されました。このモデルは、Transformerアーキテクチャを物体検出に初めて適用した画期的なアプローチです。論文はこちら。
特徴は?って聞かれたらコレを答えよう!
End-to-End設計: 従来の物体検出手法で必要だった複雑な後処理(NMSなど)を排除し、入力画像から直接物体の位置とクラスを予測します
シンプルなアーキテクチャ: CNNバックボーンとTransformerエンコーダ・デコーダの組み合わせによる簡潔な構造を持ちます
並列処理: Transformerの特性を活かし、物体の検出を並列的に行うことができます
適応性: デコーダ層の数を調整することで、再学習なしに推論速度を柔軟に変更できます
アーキテクチャ
Backbone: CNNを用いて画像の特徴量を抽出します
Transformer:
エンコーダ: 抽出された特徴量を処理します。
デコーダ: オブジェクトクエリを用いて物体の位置とクラスを予測します
FFN (Feed-Forward Network): Transformerの出力を最終的な予測結果に変換します
Positional Encoding:
Spatial positional encoding: 特徴マップに位置情報を付与
Object queries: デコーダの入力およびPositional Encodingとして機能
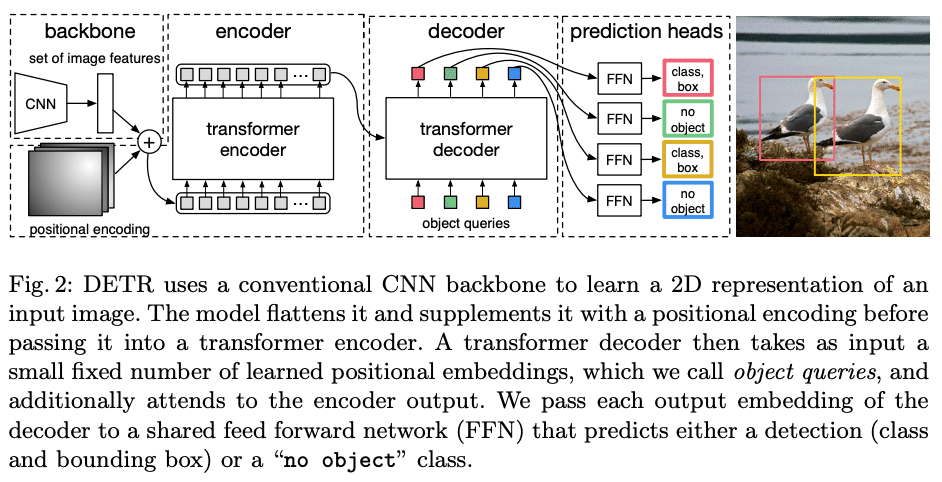
学習と推論
ハンガリアンマッチング: 予測と正解のペアリングを最適化します
損失関数: クラス分類の損失とバウンディングボックスの位置の損失を組み合わせて使用します
推論: 固定数(例:N=100)の物体候補を出力し、「no object」クラスを含めて分類します
利点
ハイパーパラメータの削減: アンカーボックスやNMSの閾値などの手動設定が不要
拡張性: セグメンテーションタスクへの応用が容易
性能: 従来のFaster R-CNNと同等以上の精度を達成
DETRと従来の物体検出手法の違いアーキテクチャの違い
アーキテクチャ
エンドツーエンドのアプローチ: DETRは物体検出をセット予測問題として扱い、1回のパスで物体の位置とクラスを直接予測します
Transformerの活用: DETRはTransformerアーキテクチャを採用し、自己注意機構を通じて画像全体のコンテキストを捉えます
アンカーボックスの排除: DETRはアンカーボックスを使用せず、直接オブジェクトの位置を予測します
処理方法の違い
並列処理: DETRは並列でオブジェクトを予測します
後処理の簡素化: DETRはNon-Maximum Suppression(NMS)などの複雑な後処理を必要としません
グローバルコンテキストの活用: DETRは画像全体の関係性を考慮できるため、複雑なシーンでも効果的です
学習と推論の違い
エンドツーエンドの学習: DETRはすべてのコンポーネントを同時に学習できます
ハンガリアンマッチング: DETRは予測と正解のペアリングにハンガリアンアルゴリズムを使用し、最適な割り当てを行います
固定数の予測: DETRは固定数のオブジェクト予測を行い、「オブジェクトなし」クラスを含めて分類します
これらの違いにより、DETRは従来の物体検出手法と比較して、よりシンプルで効率的なアーキテクチャを実現しています。ただし、計算リソースの消費が多いなどの課題もあり、研究が進められています。
DETRは物体検出タスクに新しいパラダイムをもたらし、その後のRT-DETRなどの発展型モデルの基礎となっています。シンプルな構造と高い拡張性により、今後さらなる改良と応用が期待されています。