
ヒストグラムソートとランキングフィルター続編

ヒストグラムソートとランキングフィルター続編
2024年10月30日初稿
解説エッセイ『ヒストグラムソートとランキングフィルター
』の続きです!
1.ランキングフィルター
普通の読者様には、「ランキングフィルター」とは、
何ぞや、英単語的に分解すると「ランキング」⇒
「順位付け」と「フィルター」⇒「濾過器」⇒一般家庭で
料理的に使用する場合は、コーヒー・ドリップ用の
紙フィルターとかネル・フィルター及び、「漉し網」等の
意味でコンピューターを使用する場合は、ソーティングに
馴染みが有る読者様なら、UNIXの文字列コマンドで
パイプライン的に操作する方式が馴染みが有るでしょう!

このUNIXコマンドが、フィルターと呼ばれる物です!
これは、UNIX流の文字データ等やバイナリーデータを
ソーティングにするフィルターですが、画像処理では、
似た様な物ですが、少し違います!
基本、画像(カメラで撮影した映像)に対してフィルターを
掛けると言う事なので純粋アナログ的な光学処理(
レンズ系の話)に似た処理をデジタル的に行う事が、
コンピュータプログラミングでの「フィルター」処理です!
分かり易い例と「ランキングフィルター」に近い処理として
「平滑化フィルター」⇒「平均値フィルター」と呼ばれる
処理を紹介しましょう!何をしているかと言うと、
アナログの光学フィルターで「ソフトフォーカス処理」を
行う事です?!
写真技術や画像処理に馴染みの無い読者様にも【ぼかし処理
】と言ったら、分かって頂けるかな「TVで匿名の人物や
隠す必要が有る部分、更に言えば、AV(アダルトビデオ)
で性器等を隠蔽する手段」ですと言う訳で
「平均値フィルター」の解説を先ず、行います!
解説エッセイ『画像フィルターの実例として平滑化を具体的
に説明』を参考にして下さい!
2.ランキングフィルターのソースコード
以下に画像処理ライブラリに記載しているランキング
フィルターのソースコードを示し、解説して行こうと
思います!
(1)画像処理ライブラリに格納して有るソースコードで「public」属性のライブラリを利用する
アプリで使用許可する部分
code:
int Filter::RankingFilter(
TypeArray *ps, // S画像情報
TypeArray *pd, // D画像情報
int rank, // 順位 1..361
int wh, // 水平Win幅
int wv, // 垂直Win幅
int a, // 下限
int b, // 上限
int sw, // 内部演算指定SW
// 0→Histgram方式
// 1→汎用Sort方式
int mode // 周辺処理指定
// 0:周辺処理無
// 1:周辺0クリア
// 2:周辺コピー
){
TypeArray imgS; // S画像情報:最小サイズ
TypeArray imgD; // D画像情報:最小サイズ
void *ptrs; // S画像Ptr
void *ptrd; // D画像Ptr
int h; // 水平幅
int v; // 垂直幅
int incs; // S画像増加幅
int incd; // D画像増加幅
int sti; // ステータス情報
sti = CheckMinMaxFilterImage( ps, pd, // SD画像検査
wh, wv ); //
if( sti != END_STI ){ // エラー在りなら
return( sti ); // ステータスを返す
} //
if( wh <= 0 || wh > 19 || wv <= 0
|| wv > 19 ){ // WindowSize違反時
return( STI_FLG ); // 左記を返す
} //
if( rank <= 0 || rank > wh * wv ){ // 順位の範囲外なら
return( STI_FLG ); // 左記を返す
} //
h = ps->h; // 最小の水平幅を
if( h > pd->h ){ // SDから
h = pd->h; // 取り出す
} //
v = ps->v; // 最小の垂直幅を
if( v > pd->v ){ // SDから
v = pd->v; // 取り出す
} //
imgS.subset( ps, 0, 0, h, v ); // 部分画像を
imgD.subset( pd, 0, 0, h, v ); // 作成し
ps = &imgS; // 画像情報ポインタを
pd = &imgD; // 付け替える
ptrs = (void*)ps->adr; // SD画像の画像Ptr
ptrd = (void*)pd->adr; // 始点を取り出す
incs = ps->inc; // SD画像の増加幅
incd = pd->inc; // を取り出す
if( ps->w == 1 ){ // BYTE単位画素なら
if( sw == 0 ){ // Histogram方式で
if( a < 0 || b < 0 || b > 255 // 処理不能な上下限
|| a >= b ){ // 範囲の場合は
a = 0; // 0..255の範囲に
b = 255; // 補正する
} //
} //
ranking_byte_filter( // 左記で処理
(BYTE*)ptrs, (BYTE*)ptrd, //
h, v,incs, incd, rank, //
wh, wv, a, b, sw ); //
}else if( ps->w == 2 ){ // short単位画素なら
if( sw == 0 ){ // Histogram方式で
if( a < 0 || b < 0 || b > 65535 // 処理不能な上下限
|| a >= b ){ // 範囲の場合は
sw = 1; // Sort方式にする
} //
} //
ranking_short_filter( // 左記で処理
(short*)ptrs, (short*)ptrd, //
h, v,incs, incd, rank, //
wh, wv,a, b, sw ); //
}else{ // long単位画素なら
ranking_long_filter( // 左記で処理
(long*)ptrs, (long*)ptrd, // (Sort方式)
h, v, incs, incd, rank, //
wh, wv ); //
} //
if( mode == 1 ){ // 1:外周クリア時は
ClearRoundImageBase( pd, 0, // 外周クリア
wv / 2, wh / 2 ); //
}else if( mode == 2 ){ // 2:コピー時は
CopyRoundImageBase( ps, pd, // 外周コピー
wv / 2, wh / 2 ); //
} //
return( END_STI ); // 正常終了
}を検査するのと、画像の種類≪1バイト(8ビット)系
画像・2バイト(16ビット)系画像・4バイト(32
ビット)系画像≫に依って処理を分け≪8ビット⇒此処で
は、「BYTE」型=ファイル「ImageFuncDef.h」で定義と
「unsigned chae」で詰り「0,1,2,3....254,255」の範囲の
整数値が、使える単純データ構造で、ヒストグラムソート用
のヒストグラムデータ配列のサイズが、256個あれば可能
な場合ですし、16ビット系では-32768⇒0⇒
32767、32ビット系では、整数値全体に成るので
ヒストグラムデータを作成する事は実質的に無理&効率的に
無駄なのでソートを別の方式(此処では、クイックソート
アルゴリズムを使用)≫と処理を画像の種類に依って分けた
り、細かい引数が処理可能な範囲に有るか否かの検査を行っ
て居る所です!解説『解説クラスTypeArray』と
解説『解説クラスCopyClear』に使用して居る
関数の解説が存在します!
(2)画像処理ライブラリに格納して有るソースコードで「private」属性で実質的に動作を記述して有る本体
今回は、ヒストグラムソートを使用する方式を解説するので
「ranking_byte_filter()」を動作させる場合に付いて説明
して行きます!
では、先ず、そのソースコードを示します!
code:
void Filter::ranking_byte_filter(
BYTE *ps, // S画像Ptr
BYTE *pd, // D画像Ptr
int h, // 水平幅
int v, // 垂直幅
int incs, // S画像増加幅
int incd, // D画像増加幅
int rank, // ランク順位1..361
int wh, // 水平win幅 1..19
int wv, // 垂直win幅 1..19
int a, // 下限
int b, // 上限
int sw // 内部演算指定SW
// 0→Histgram方式
// 1→汎用Sort方式
){
int hstbuf[ 256 ]; // Histogram演算Buf
pd += wh / 2 + ( wv / 2 ) * incd; // Dptr格納位置補正
h -= wh / 2 * 2; // 水平処理幅を補正
v -= wv / 2 * 2; // 垂直処理幅を補正
if( sw == 0 ){ // Hist方式ならば
up_fill_int( 0, hstbuf, 256 ); // HistogramBuf CLR
if( rank <= ( wh * wv ) / 2 ){ // 順位が始..中なら
while( --v >= 0 ){ // 垂直方向処理繰返
rank_line( hstbuf, ps, pd, // 水平の処理を行う
h, incs, rank, wh, wv, a, b ); // :ヒストグラム版
ps += incs; // 垂直方向増加:S
pd += incd; // 垂直方向増加:D
} //
}else{ // 順位が中..終なら
while( --v >= 0 ){ // 垂直方向処理繰返
rank_line_rev( hstbuf, ps, pd, // 水平の処理を行う
h, incs, rank, wh, wv, a, b ); // :Hist版:逆順
ps += incs; // 垂直方向増加:S
pd += incd; // 垂直方向増加:D
} //
} //
}else{ // Sort方式ならば
while( --v >= 0 ){ // 垂直方向処理繰返
ranking_byte( ps, pd, h, incs, rank, // 水平の処理を行う
wh, wv ); // :ソート版
ps += incs; // 垂直方向増加:S
pd += incd; // 垂直方向増加:D
} //
} //
}(2-1)先ず、仮引数の説明として
code:
void Filter::ranking_byte_filter(
BYTE *ps, // S画像Ptr
BYTE *pd, // D画像Ptr
int h, // 水平幅
int v, // 垂直幅
int incs, // S画像増加幅
int incd, // D画像増加幅
int rank, // ランク順位1..361
int wh, // 水平win幅 1..19
int wv, // 垂直win幅 1..19
int a, // 下限
int b, // 上限
int sw // 内部演算指定SW
// 0→Histgram方式
// 1→汎用Sort方式先ず、S画像・D画像と言う表現≪S=ソース(詰り、
加工前のオリジナル元画像)、D=ディスティネーション
(詰り、加工後の結果画像の送り先⇒格納先)を示し、
この画像処理ライブラリの用語として使用します!
そして両者のデータType=「BYTE」⇒
「unsigned char」と符号無し8ビット整数
(0,1,2,....,254,255)にしています!
このBYTEだからこそ、ヒストグラムソートが現実的に使用
出来る≪ヒストグラムデータを算出する配列が、
この関数内部で使用される「int hstbuf[256];」で
間に合う事に注目して下さい≫、次の「水平幅・垂直幅」
は、解説『基本構造』で説明しているし、この文章内でも
何回か紹介している画像の横方向が水平方向(x座標方向
とも説明)、縦方向が垂直方向(y座標方向とも説明)
している画像自体のサイズを示しています!
次に増加幅ですが、垂直方向にポインタを移動する為の
サイズだと考えて下さい?!
分かり難いかもしれませんが、解説『解説クラスTypeArray』で説明している事が解かって居る事が今回の説明にも必須ですので
宜しくお願いします!
何故、水平幅と増加幅と別れて居るかは、【部分画像】を
取り扱える様にした為です!
部分画像に関しても、解説『解説クラスTypeArray』で説明しています!
此処までの引数は、「S⇒D」と画像を加工する関数に共通
する部分ですが「ランク順位」これは、処理ウインドウ≪
水平win幅1..19 ×垂直win幅1..19と指定したサイズ無いで
ランキング演算する範囲を示す≫
中の順位(最小=1×1=1、最大=19×19=361まで)の
中での任意の値として順位を設定出来る事を示します!
今回は、3×3の処理ウインドウで中央値にする為、
「rank=5」詰り小さい順から5番目を示します!
水平win幅 1..19、垂直win幅 1..19は、先程解説した通り
です!次に「下限・上限」ですが、これは、画像内の画素の
値が最小値が何か、最大値が何か分かって居る場合設定する
仮引数です?!
今回は、データをタイプ「BYTE」にしている為、
下限「a=0」、上限「b=255」と成ります!
そして内部演算指定SWとは、ヒストグラムソート方式を
ランキングフィルターに応用するか、或いは、一般的な
ソートアルゴリズム(クイックソート)を使用するかの切り
替え用のスイッチです!ココの解説は、ヒストグラムソート
を使用した事を解説して居るので勿論「sw=0」です!
(2-2)次にデータ構造の説明として
code:
int hstbuf[ 256 ]; // Histogram演算Buf
とヒストグラムソートを行う為のバッファ配列を用意している事を示します
(2-3)実際のランキングフィルターの説明として
code:
pd += wh / 2 + ( wv / 2 ) * incd; // Dptr格納位置補正
h -= wh / 2 * 2; // 水平処理幅を補正
v -= wv / 2 * 2; // 垂直処理幅を補正
if( sw == 0 ){ // Hist方式ならば
up_fill_int( 0, hstbuf, 256 ); // HistogramBuf CLR
if( rank <= ( wh * wv ) / 2 ){ // 順位が始..中なら
while( --v >= 0 ){ // 垂直方向処理繰返
rank_line( hstbuf, ps, pd, // 水平の処理を行う
h, incs, rank, wh, wv, a, b ); // :ヒストグラム版
ps += incs; // 垂直方向増加:S
pd += incd; // 垂直方向増加:D
} //
}else{ // 順位が中..終なら
while( --v >= 0 ){ // 垂直方向処理繰返
rank_line_rev( hstbuf, ps, pd, // 水平の処理を行う
h, incs, rank, wh, wv, a, b ); // :Hist版:逆順
ps += incs; // 垂直方向増加:S
pd += incd; // 垂直方向増加:D
} //
} //ここで今回は、3×3の処理ウインドウで中央値なので
「wh=3,wv=3,rank=5」の値が引数で与えられたとして
解説して行きます!
code:
pd += 1 + incd; // Dptr格納位置補正
h -= 2; // 水平処理幅を補正
v -= 2; // 垂直処理幅を補正pd += 1 + incd; // Dptr格納
ソースコードの読解力の有る読者様には、蛇足かも知れま
せんが上記3行で結果画像が一回り内側、実際に結果として
も内側のサイズ範囲に結果格納ポインタの先頭もサイズも
成って居る事が判るでしょう!
code:
up_fill_int( 0, hstbuf, 256 ); // HistogramBuf CLRでヒストグラム演算(計数)用バッファーの初期化
(0クリア)を示します!
ここで特筆すべき事は、この画像のランキングフィルターを
行う時にココ1回だけバッファーの初期化を行って居る
事です!
毎回、3×3の処理ウインドウ毎に初期化を行って無いので
画像全体としたら処理が高速化する事に成ります!
code:
if( rank <= ( wh * wv ) / 2 ){ // 順位が始..中なら
・・・・・・ // 今回は説明は省略する!
}else{ // 順位が中..終なら
while( --v >= 0 ){ // 垂直方向処理繰返
rank_line_rev( hstbuf, ps, pd, // 水平の処理を行う
h, incs, rank, wh, wv, a, b ); // :Hist版:逆順
ps += incs; // 垂直方向増加:S
pd += incd; // 垂直方向増加:D
} //
} //何故、「今回は説明は省略」と記載したのは、この場所を通
ら無いからだ!
だから、「}else{・・・}」の「順位が中..終なら」の
ブロックが使用される事が分かるでしょう!
今回は、その部分の動作を解説して行きます!
code:
while( --v >= 0 ){ // 垂直方向処理繰返
rank_line_rev( hstbuf, ps, pd, // 水平の処理を行う
h, incs, 5, 3, 3, a, b ); // :Hist版:逆順
ps += incs; // 垂直方向増加:S
pd += incd; // 垂直方向増加:D
} //先ず、「while( --v >= 0 ){・・・}」の構文だが、
お馴染みの「for( int i=0; i < v; i++){・・・}」と記載
した物と動作は同じですが何故、この様に記載したかは
私がケチ≪元々組み込み機器(大本はADS社画像処理装置
用に搭載する基本コード)≫だったので少しでもターゲット
の機械コードが少無く成る方式を模索(CPU68Kで
ツールMCC68Kで色々コンパイルしたアセンブリコード
を検証)し最小のコードが出る方法として「--v」と
ココでは変数(v)が破壊≪値が変わっても大丈夫な応用≫
で使用する方法として採用したソースコード記述方法
です?!
最も破壊されては駄目な変数にはコノ方法は使用して無い
筈です!
で、このループは、読解力の有る読者様は何回か解説して
居るから、慣れているでしょう?!
勿論、垂直(y座標)方向へ画像全体を処理して行く
ブロックで「ps += incs;pd += incd;」でS画像・D画像
への処理ポインタを進行している事は理解して頂いて居る
と思います?!
そして処理自体は、下請け的なサブルーチン
「rank_line_rev(・・・)」で実際の水平方向の処理を
行います≪何回も呼ばれるサブルーチン関数で無く専用の
ルーチンなのでコノブロックで記述する事も可能ですが、
ループの段数が増える等、依り複雑に成るので下請け
作業用の名前を付けて処理しました⇒
下請け関数の名前「rank_line_rev」は、「rank」で
ランキングフィルター処理を示し、「line」でライン(
詰り水平方向)を示し、「rev」で☆此処がポイント:
逆方向⇒ヒストグラム結果の昇順(小→大)で順番を数
えるので無く降順(大→小)で数えた方が有利☆
との事ですが、中央値なので何方も大差無いが、「rank」
で最小値から最大値まで指定出来る関数なのでコノ様に
成っています!
例えば、最大値フィルター指定(rank=9)
したのにヒストグラムデータの最小値から順番に数えて
最大値の所を探すのは、極めて効率が悪いが、
逆に最大値から逆順に数えれば、即、演算が終了します!
と書いたのは、ランキングフィルターで使用する結果画素
データはヒストグラム結果の順番の値が反映されます!≫、
因みに下請けの関数名を命名する所が、実は一番
プログラマーのセンスが問われるところですが、私の場合、
元の演算・何処を処理する・属性と並べていますが、
参考に成りましたでしょうか?!
私としては、統一性を持って命名した心算です!
では、次から、下請け関数「rank_line_rev」の処理に付い
て解説します
(3)下請け関数「rank_line_rev」
以下に下請け関数「rank_line_rev」のソースコードを
示します!
この関数での説明コソが、「コペルニクス的転回」を
起こした程の効率の良い処理方法だと読解力の有る
読者様には、分かって貰えると思います!
code:
void Filter::rank_line_rev(
int hstbuf[], // Histogram演算用Buffer
BYTE *ps, // S画像Ptr
BYTE *pd, // D画像Ptr
int h, // 水平幅
int incs, // S画像増加幅
int rank, // ランク順位 1..361
int wh, // 水平のWindow幅 1..19
int wv, // 垂直のWindow幅 1..19
int a, // 下限
int b // 上限
){
BYTE tmpbuf[ 19*19*4 ]; // 局所画素一時保存用
BYTE *pend; // Bufferへの終点Ptr
BYTE *pw; // Bufferへの書込Ptr
BYTE *pe; // Bufferの消去用Ptr
int *phstbuf; // Histogram演算用BufPtr
BYTE *psy; // Sのy軸Ptr
int i; // カウンタ
int data; // データ
int max_win; // Window内の最大Data
rank = wh * wv - rank + 1; // 逆順の順位算出
up_fill_int( 0, &hstbuf[a], b - a + 1 ); // HistogramBufのクリア
max_win = 0; // 最大データ初期化
pend = &tmpbuf[ 19*19*4 - wh * wv ]; // 終点Ptrをセット
pw = tmpbuf; // 局所BufPtr登録用Set
pe = tmpbuf; // 局所BufPtr削除用Set
for( ; --wh >= 0; ps++ ){ // 最初のWindowのHST処理
psy = ps; // 局所ポインタのセット
for( i = wv; --i >= 0; psy += incs ){ // 局所1列分の処理
data = *psy; // 画素データを取り出し
hstbuf[ data ]++; // HistogramをCntUPし
*pw++ = data; // 局所BufferへData保存
if( max_win < data ){ // Window内の最大値を
max_win = data; // 更新
} //
} //
} //
phstbuf = &hstbuf[ max_win ]; // HistogramBufferへの
data = 0; // Ptrを最大値でSetし
i = max_win + 1; // 順番も最大値からCNT
for( ; data < rank; i--, phstbuf-- ){ // し、設定された順番の
data += *phstbuf; // 中央値をこのデータ
} // から求める(逆順)
*pd++ = i; // 結果画像に書き込み
--h; // 水平方向SIZE補正
for( ; --h >= 0; ps++ ){ // 水平方向に繰返し
for( i = wv; --i >= 0; ){ // HistogramDataから
hstbuf[ *pe++ ]--; // 古いデータを取り除く
} //
if( pe >= pend ){ // Buffer一周時は
pe = tmpbuf; // 先頭へ補正
} //
psy = ps; // 局所ポインタのセット
for( i = wv; --i >= 0; psy += incs ){ // 局所1列分の処理
data = *psy; // 画素データを取り出し
hstbuf[ data ]++; // HistogramをCntUPし
*pw++ = data; // 局所BufferへData保存
if( max_win < data ){ // Window内の最大値を
max_win = data; // 更新
} //
} //
if( pw >= pend ){ // Buffer一周時は
pw = tmpbuf; // 先頭へ補正
} //
phstbuf = &hstbuf[ max_win ]; // HistogramBufferへの
data = 0; // Ptrを最大値でSetし
i = max_win + 1; // 順番も最大値からCNT
for( ; data < rank; i--, phstbuf-- ){ // し、設定された順番の
data += *phstbuf; // 中央値をこのデータ
} // から求める(逆順)
*pd++ = i; // 結果画像に書き込み
} //
}仮引数に関しては、理解されていると思いますので省略し
ます!
ここではコノ中で使用されるデータ構造を解説します
(3-1)「rank_line_rev()」内部のデータ構造
(a)内部のデータ構造
code:
BYTE tmpbuf[ 19*19*4 ]; // 局所画素一時保存用
BYTE *pend; // Bufferへの終点Ptr
BYTE *pw; // Bufferへの書込Ptr
BYTE *pe; // Bufferの消去用Ptr
int *phstbuf; // Histogram演算用BufPtr
BYTE *psy; // Sのy軸Ptr
int i; // カウンタ
int data; // データ
int max_win; // Window内の最大Data特徴的なのは、「BYTE tmpbuf[19194];」と使用した
画素データを一時的に保存するバッファ配列です!
文字通り画素データの一時保存用に使用しサイズは、
最大処理ウインドウ(19×19)のサイズに安全率を掛け
た値にしています!
そしてこのバッファを操作するためのポインタ変数「pend、
pw、pe」を定義しています!
そして「int *phstbuf;」は、ヒストグラムデータ演算用の
バッファーへの作業用ポインタで有る事は、理解して貰っ
ていますね!
(b)データ構造初期化
code:
rank = wh * wv - rank + 1; // 逆順の順位算出
up_fill_int( 0, &hstbuf[a], b - a + 1 ); // HistogramBufのクリア
max_win = 0; // 最大データ初期化
pend = &tmpbuf[ 19*19*4 - wh * wv ]; // 終点Ptrをセット
pw = tmpbuf; // 局所BufPtr登録用Set
pe = tmpbuf; // 局所BufPtr削除用Set先ず、逆順なので「rank = wh * wv - rank + 1;」此処
では、「rank = 3 * 3 - 5 + 1;」⇒
「rank = 9 - 5 + 1;」⇒「rank = 3;」と成ります!
何で、この計算式に成ったか?今と成っては作者の私にも
実はワカラナイのだが、解説して行く内に理解できると思
います!
次は、「up_fill_int(・・・)」と画像処理ライブラリでの
細々とした汎用に使用出来るサポート関数で
解説『解説クラスSupport』で説明している関数を
使用してヒストグラム演算用バッファー「hstbuf[]」の
必要な場所を0クリアしています!
「max_win=0」は、最大値を算出する前の準備です!
「pend、pw、pe」と「tmpbuf[]」操作用≪バッファ配列へ
登録したケツと場所を示す値と、登録/削除の操作用の
ポインタ≫です!
(c)実際の動作解説
(c-1)最初の処理ウインドウのヒストグラム演算処理
code:
for( ; --wh >= 0; ps++ ){ // 最初のWindowのHST処理
psy = ps; // 局所ポインタのセット
for( i = wv; --i >= 0; psy += incs ){ // 局所1列分の処理
data = *psy; // 画素データを取り出し
hstbuf[ data ]++; // HistogramをCntUPし
*pw++ = data; // 局所BufferへData保存
if( max_win < data ){ // Window内の最大値を
max_win = data; // 更新
} //
} //
} //以下に図示した黄色枠内のヒストグラム演算を行います!
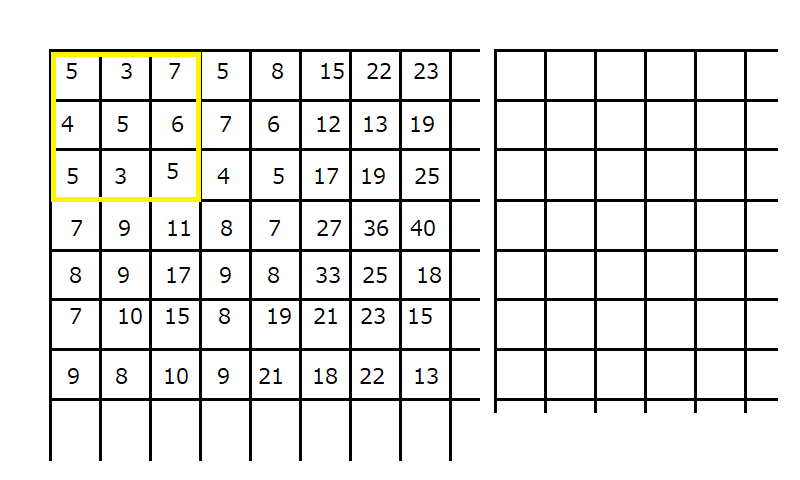
ソースコードの読解力の有る読者様には簡単に
「rank_line_rev()」と言う名称の「line」と一行≪
水平(x座標)方向≫の先頭、詰り、図示上で左端の
3×3枠内の処理を示します!「hstbuf[ data ]++;」と
前述で解説したヒストグラム演算をコノ3×3枠内で行って
居る事は理解出来ていますね!
次は、「*pw++ = data;」とバッファ配列へ登録を行って
居る事に注意して下さい⇒
後で意味を持ちますから覚えて置いて下さい!
次に「if(max_win<data){max_win = data;}」と最大値を
算出しています!これも覚えて下さい!
(c-2)最初の処理ウインドウのヒストグラム演算処理から画像結果反映
code:
phstbuf = &hstbuf[ max_win ]; // HistogramBufferへの
data = 0; // Ptrを最大値でSetし
i = max_win + 1; // 順番も最大値からCNT
for( ; data < rank; i--, phstbuf-- ){ // し、設定された順番の
data += *phstbuf; // 中央値をこのデータ
} // から求める(逆順)
*pd++ = i; // 結果画像に書き込み「&hstbuf[max_win]」が、ヒストグラムを演算した配列の
画素データ最大の値での頻度カウント数とは理解してます
ね!
そして「i=max_win+1;」で合計値を計算する回数を
算出し、合計値「data」が、
「for(;data<rank;i--,phstbuf--){data+=*phstbuf;}」と
「data<rank」条件で指定された「rank」以上に成れば
カウントを終了し、
最大値から何番目の場所が「i」に残る事は理解できる
でしょう?!
そして「*pd++=i;」で結果画像に中央値の値として格納
される事は、理解して頂いたと思います?!
えっ同じ事をするのにモット分かり易く書ける筈と指摘され
る読者様も当然存在すると思いますが、ナニブンニモ画像
処理装置メーカーADS社の装置としてCPU68kの
コンパイルツールMCC68Kで最も効率の良いオブジェク
トコードが出力される方法を模索したらコノ記述に成り
ましたと言い訳して置きます!
(c-3)先頭以降の処理ウインドウの処理
code:
--h; // 水平方向SIZE補正
for( ; --h >= 0; ps++ ){ // 水平方向に繰返し
for( i = wv; --i >= 0; ){ // HistogramDataから
hstbuf[ *pe++ ]--; // 古いデータを取り除く
} //
if( pe >= pend ){ // Buffer一周時は
pe = tmpbuf; // 先頭へ補正
} //
psy = ps; // 局所ポインタのセット
for( i = wv; --i >= 0; psy += incs ){ // 局所1列分の処理
data = *psy; // 画素データを取り出し
hstbuf[ data ]++; // HistogramをCntUPし
*pw++ = data; // 局所BufferへData保存
if( max_win < data ){ // Window内の最大値を
max_win = data; // 更新
} //
} //
if( pw >= pend ){ // Buffer一周時は
pw = tmpbuf; // 先頭へ補正
} //
phstbuf = &hstbuf[ max_win ]; // HistogramBufferへの
data = 0; // Ptrを最大値でSetし
i = max_win + 1; // 順番も最大値からCNT
for( ; data < rank; i--, phstbuf-- ){ // し、設定された順番の
data += *phstbuf; // 中央値をこのデータ
} // から求める(逆順)
*pd++ = i; // 結果画像に書き込み
} //上記部分が、先頭の3×3以降の水平方向処理を示しますが
先ず、2番目を図示して置きます!

黄色の枠は、前回説明した最初に演算する3×3の処理
ウインドウですが、今回の緑色の3×3の処理ウインドウが
「2番目の処理ウインドウ」です!
注意して欲しいのは、黄色枠だけで重なって無い所
(黄色円で目立たせています)・両方が重なって居る所・
そして緑色枠だけで重なって無い所(▲緑色で目立たせて
います)と3ヵ所有る事です!
code:
--h; // 水平方向SIZE補正
for( ; --h >= 0; ps++ ){ // 水平方向に繰返し
・・・・・・・// 内部の処理ブロック解説は後で行います!
} //「--h;」で先頭部分は処理を終えて居るので処理サイズを
一つ減らす!
「for(;--h>=0;ps++){}」で先頭以降の処理をするループを
示します!その中身をコレから解説して行きます!
【A】
解説して行くループの中身ブロック全体を再び遠くに
成ら無い様に再登載
code:
for( i = wv; --i >= 0; ){ // HistogramDataから
hstbuf[ *pe++ ]--; // 古いデータを取り除く
} //
if( pe >= pend ){ // Buffer一周時は
pe = tmpbuf; // 先頭へ補正
} //
psy = ps; // 局所ポインタのセット
for( i = wv; --i >= 0; psy += incs ){ // 局所1列分の処理
data = *psy; // 画素データを取り出し
hstbuf[ data ]++; // HistogramをCntUPし
*pw++ = data; // 局所BufferへData保存
if( max_win < data ){ // Window内の最大値を
max_win = data; // 更新
} //
} //
if( pw >= pend ){ // Buffer一周時は
pw = tmpbuf; // 先頭へ補正
} //
phstbuf = &hstbuf[ max_win ]; // HistogramBufferへの
data = 0; // Ptrを最大値でSetし
i = max_win + 1; // 順番も最大値からCNT
for( ; data < rank; i--, phstbuf-- ){ // し、設定された順番の
data += *phstbuf; // 中央値をこのデータ
} // から求める(逆順)
*pd++ = i; // 結果画像に書き込み【B】
ヒストグラムデータから古いデータを取り除く
code:
for( i = wv; --i >= 0; ){ // HistogramDataから
hstbuf[ *pe++ ]--; // 古いデータを取り除く
} //
if( pe >= pend ){ // Buffer一周時は
pe = tmpbuf; // 先頭へ補正
} //「(c-2)最初の処理ウインドウ」の解説の中で
「*pw++ = data;」とバッファ配列へ登録を行って居る
事は覚えて置いて下さいと記載しましたが、
ここで局所バッファ配列「tmpbuf[]」へ格納された
データ≪図で示した黄色円で示した縦一列のデータ≫を
ヒストグラムデータから削除≪
詰り「hstbuf[ *pe++ ]--;」とカウントダウン≫して居る
事です!
「if(pe>=pend){pe = tmpbuf;}」は、
良くバッファ配列を巡回バッファーとして使用する為の
テクニックと一般的な手法ですが、理解出来ていますね!
【C】
新しく緑枠3×3ヒストグラムデータを算出する
code:
psy = ps; // 局所ポインタのセット
for( i = wv; --i >= 0; psy += incs ){ // 局所1列分の処理
data = *psy; // 画素データを取り出し
hstbuf[ data ]++; // HistogramをCntUPし
*pw++ = data; // 局所BufferへData保存
if( max_win < data ){ // Window内の最大値を
max_win = data; // 更新
} //
} //
if( pw >= pend ){ // Buffer一周時は
pw = tmpbuf; // 先頭へ補正
} //「(c-1)最初の処理ウインドウのヒストグラム演算
処理」の中の局所1列分の処理
「for(i=wv;--i>=0;psy+=incs){・・・}」と似た縦一列分
データ≪図で示した緑色▲で示した縦一列のデータ≫の
ヒストグラム演算≪「hstbuf[data]++;」とカウント
アップ≫して居る事を示します!
そして「if(pw>=pend){pw=tmpbuf;}」でリングバッファと
して処理≪局所画素一時保存用バッファーへデータ保存
する場所が最後に成ったら、先頭に強制的に戻す事で巡回
バッファーとして使用とコンピュータプログラミングに
慣れている読者様には、お馴染みの「リングバッファ」
手法だが、プログラミングでも行って見ようと考えられ始め
た読者様には、初耳かも知れないので良く使われる
一般的な方法で有ると覚えて置いて下さいとだけ?言って
置きます!≫する為のポインタを配列の先頭へ移動させてい
る事と理解して下さい!
そして先頭の処理「(c-1)最初の処理ウイ・・・」と
同じ様に「ヒストグラム演算」と
「局所バッファへの登録」を行って居る事は理解出来たと
思います!
「【B】ヒストグラムデータから古いデータを取り除く」で
黄色●を削除し今回、緑色▲の画素データを演算した事で
緑色3×3の処理ウインドウを処理した事が
わかるでしょう!!
このように水平(x座標)方向に元(S)画像への処理が
進んで行きます!
【D】
結果画像に中央値を算出し格納
code:
phstbuf = &hstbuf[ max_win ]; // HistogramBufferへの
data = 0; // Ptrを最大値でSetし
i = max_win + 1; // 順番も最大値からCNT
for( ; data < rank; i--, phstbuf-- ){ // し、設定された順番の
data += *phstbuf; // 中央値をこのデータ
} // から求める(逆順)
*pd++ = i; // 結果画像に書き込み「(c-2)最初の処理ウイン・・・・から画像結果反映
」で解説したソースコードと同じソースコードを並べて有る
事は理解出来ますね?!
これで下請け関数「rank_line_rev」の動作は理解して頂け
たと思います!
(4)改めて、ヒストグラムソートを中央値フィルターに使用した方が、効率が良く成ったか説明?!
上記までを辛抱強くソースコードを理解して頂いたと
思いますが、念の為に説明します!
(a)
3×3の演算ウインドウが、右側の縦一列分だけ、
詰り3個だけ、ヒストグラム演算≪対応する画素カウンター
をカウントアップ≫すれば良いと中身の9個を
ソーティングアルゴリズムを適応する必要が無い事です!
(b)
今のコンピューター≪CPUと半導体メモリ≫で
構成されている装置で処理時間が物理的に掛かるのは、
CPUやメモリ内部での処理時間で無くCPUと半導体
メモリチップ間の導線上の電気信号遅延≪主に導線と導線や
導線とアース間の電気容量(コンデンサ成分)とで導線の
長さに原因する電気誘導(コイル的なリアクタンス成分)で
遅延が生じる≫で有ってCPU内部での演算やデータ参照&
書き換えは、CPUのパイプライン処理と言う並列処理と
CPUに内蔵されたキャッシュメモリ内にアクセスする
データが存在する場合は、導線上にデータが流れないので
遅延は発生シナイ事が、知られています。
今回、解説したソースコードで遅延が生じるデータが導線を
流れるのは、画像メモリ(S/D)へのアクセスを行った時
だけです!
ヒストグラム演算に使用する「int hstbuf[256];」や局所
保存バッファ「BYTE tmpbuf[19194];」1回アクセス
すれば、その時点で多くのCPUはキャッシュメモリに全て
置き換えられる筈です!
詰り、このランキングフィルターのソースコードは、
極めて現代的なCPUを使う上では、キャッシュメモリを
使う事で効率的なソースコードに成っているのです!
(5)私が、コペルニクス的転回を起こした処理時間
実際にベンチマークテストを割と大き目の画像で行った場合
平均値フィルタ≪7×7のフィルター演算ウィンドウ幅≫
より早く処理が終了したので処理時間に驚き、考察して見た
のだ!
※備考※平均値フィルタと比べたのは、ランキングフィル
ター演算の中で中央値と言う平均値と似た処理だからです!