
AI Agentがブラウザを操作する「Browser Use」を試してみよう!

「Browser Use」って何?
先日、いつも通りXを徘徊してたらLangChainのアカウントから面白いポストを発見。
AI Agentがブラウザに簡単にアクセスできるっぽい。
🛜 Browser Use
— LangChain (@LangChainAI) December 22, 2024
Make websites accessible for AI agents 🤖
Browser use is the easiest way to connect your AI agents with the browser
Use any LLM supported by LangChain (e.g. gpt4o, gpt4o mini, claude 3.5 sonnet, llama 3.1 405b, etc.)https://t.co/x9hRshFEk5 pic.twitter.com/28n9697WJU
「LangChainを使ってAI Agentがウェブサイトにアクセスできるだと…?」
「しかもOSS…?」
「しかも数行のコードで…?」
こりゃ試してみるしかない!ってことで試してみたら簡単にできました!
ということで「Browser Use」の試し方を今回は書いていこうと思います。
「Browser Use」お試し準備
今回は以下の環境で試しました。WSLでやろうと思いましたがブラウザ操作で躓きそうな気がしたのでとりあえずホスト上に直接実行環境を準備します。venvで仮想環境つくればまぁいいかの精神。
実行環境
Windows11
cursor
Python 3.11.6
Powershell
venvで仮想環境準備
任意のフォルダを作成します。cursorで作成したフォルダを開いたらターミナル(Powershell)で以下のコマンドを実行して仮想環境を作成&アクティベート。
python -m venv compute-use-env
.\compute-use-env\Scripts\activate 仮想環境をアクティベートしたら以下のコマンドを実行します。playwrightとは、Microsoftが開発したオープンソースのエンドツーエンドテスト自動化ツールです。これを使ってブラウザを操作をしているみたいです。
pip install browser-use
playwright install.envファイルを作成&APIキーを設定
続いて、APIキーを設定します。以下のコマンドで.envファイルを作成してください。
New-Item -Path ".env" -ItemType "file"作成出来たらファイルを開いてAPIキーを入力してください。筆者はOpenAIのAPIキーを今回は使用しました。
デフォルトの設定だとテレメトリを送っている(個人情報は取得してないらしい)ので送らないようにANONYMIZED_TELEMETRYをfalseにします。
OPENAI_API_KEY=
ANTHROPIC_API_KEY=
ANONYMIZED_TELEMETRY=false
ブラウザを操作するAgentの準備
では最後の準備としてAgentのコードを作成します。以下のコマンドを実行してpythonのファイルを作成します。
New-Item -Path "compute-use.py" -ItemType "file"ファイルを作成したら以下のコードを入力してください。コード自体はGithubに載っているコードをそのまま使用しています。taskの部分だけ、Agentにブラウザ操作させたいことに変更しましょう。
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
async def main():
agent = Agent(
task="東京都のおすすめの焼肉屋を調べてください。",
llm=ChatOpenAI(model="gpt-4o-mini"),
)
result = await agent.run()
print(result)
asyncio.run(main())「Browser Use」を実行してみる
準備が整ったので早速試してみます。
ターミナルから以下のコマンドを実行し、作成したプログラムを実行します。
python .\compute-use.py実行するとブラウザが自動的に立ち上がります。ターミナルにログを出力しながらAgentが与えられたタスクにしたがってブラウザ操作していきます。
Agentが自分でタスクを分解してステップを一つずつ進めていく様子が見れるのはめちゃくちゃ面白いです。
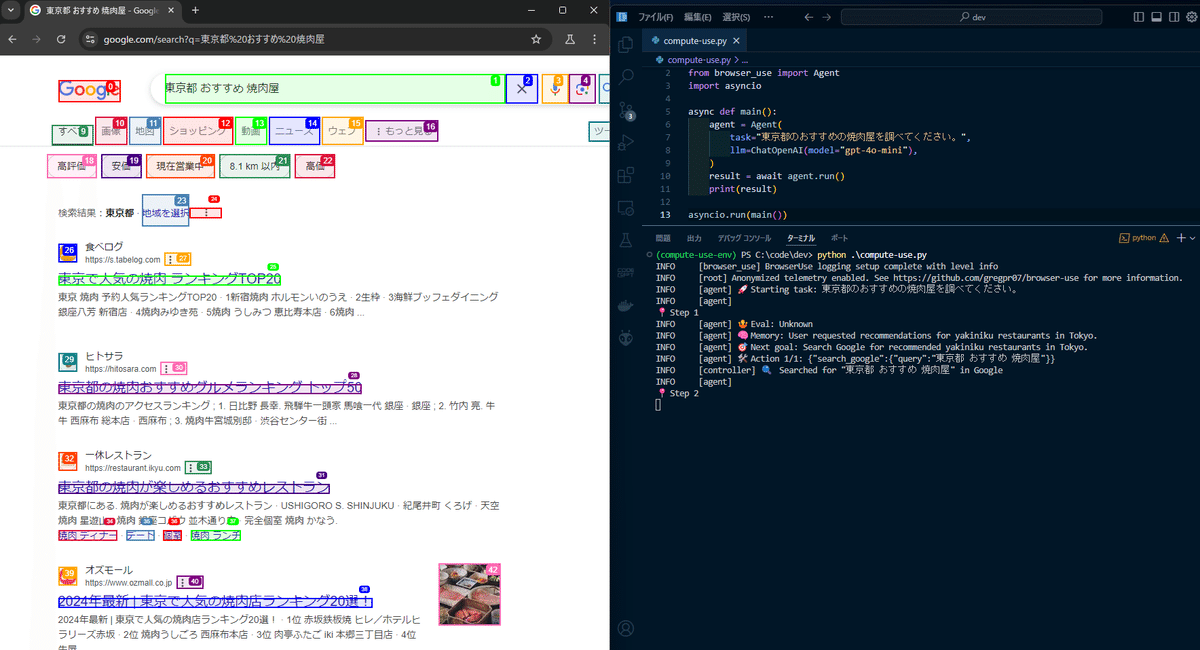
ブラウザ操作が終わると自動的にブラウザが閉じられます。ターミナルを確認し、以下のような結果のログが出力されていれば成功です。
INFO [agent] 📄 Result: Here are the top recommended yakiniku restaurants in Tokyo:
1. **新宿焼肉 ホルモンいのうえ**
- Rating: 3.48
- Location: 新宿西口、西武新宿、西新宿
- Price: ¥4,000~¥4,999
- Reservations: Highly recommended
2. **生粋**
- Rating: 3.71
- Location: 末広町、湯島、上野広小路
- Price: ¥8,000~¥9,999
- Reservations: Available
INFO [agent] ✅ Task completed successfully終わりに
DifyなどでAgentがツール(API)を使ってWeb検索をすることはよくありますが、Agentがブラウザを操作する姿を見るのはめちゃくちゃ面白かったです。今回は調べものをさせてみましたが、例えばUIのテストなどは簡単な指示を出すだけで試すようなことも出来そうです。Agentの活用の幅が一気に広がったように感じたお試しでした。
(補足)トラブルシューティング
筆者の場合は最初に実行したときに以下のエラーが発生しました。
ImportError: lxml.html.clean module is now a separate project lxml_html_clean.
Install lxml[html_clean] or lxml_html_clean directly.以下のコマンドを実行することで解決。
python.exe -m pip install --upgrade pip
pip install "lxml[html_clean]"