

#OCR

きっぷの文字認識結果をマッピングする
前回の続き。名鉄ミューチケットの色を落とすことによって、Googleドキュメントでいい感じに認識ができました。
では、Google Vision APIで位置情報と合わせて取ってみましょう。
使う画像は境界値(R,G,B)=(120,120,120)で色を落とした画像です。
で、検出した位置情報を四角で囲う。
検出も大きい単位からblock単位、paragraph単位、word単位があるので、


APIを使ってみよう(Google Vision API)
この記事で、GoogleドキュメントのOCR機能を使いました。
でも、Googleドライブにアップして、Googleドキュメントで開く、というのを毎回実行するのは手間です。
画像を渡したら、文字認識した結果だけ返してくれればいいんだけど。
もっと自動でできないもんかね?
という感じに、プログラムの「一部機能だけが欲しい」といったことはありませんか?膨大な機能の中の、一部だけが使いたい。付随す
画像の文字起こしをしてみよう
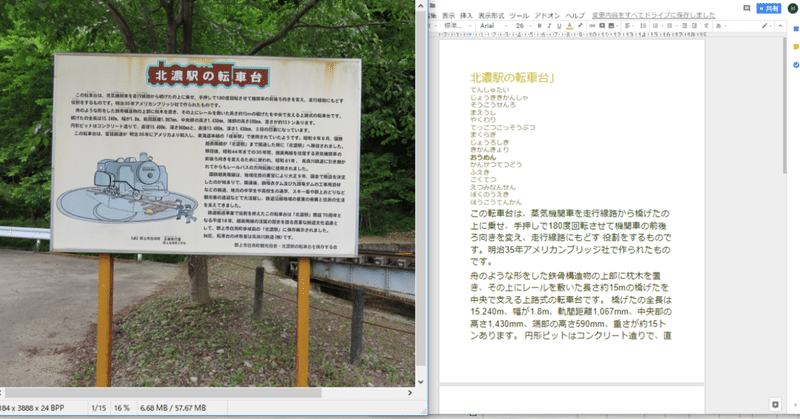
こんな画像から文字起こしをしたいと思ったことはありませんか?
観光地に行くと、こんな掲示は結構見ます。
「写真を撮っておいて後で見返そう!」と思っても、ファイルは画像のままなので、検索にも使いづらい。せいぜい、いつどこで撮ったっけ?と思い出して探すくらいです。
検索とか翻訳にも使うなら文字起こしして、テキスト情報にする必要がありますが、手作業で書き起こすとなると大変ですよね。
そこで、OCR