【2021JDSCアドベントカレンダー】datahubをちょっと触ってみた

アドベントカレンダー日程表
こちら日程表になります。他記事にも飛べますのでぜひご覧くださいませ!
ごあいさつ
こんにちは。データサイエンティストの Kensaku Okada です。
アドベントカレンダーに2本投稿しちゃいました。1本目はこちらなので、よかったら読んでくださいね!
メタデータを管理したい
皆さんはデータカタログを使ったことがありますか?個人で開発したりデータいじる分には気にしなくて良いですが、チームで大きめのシステムを作る場合、DB管理するデータソースやデータテーブルが大量に発生し、「このデータ、何のデータだっけ?」と思うことがよく起こります。そこで大事になってくるのが、各データソース・テーブルやカラムのメタデータを適切に管理することであり、管理しようとした結果できるメタデータの辞書をデータカタログと呼びます。
クラウドのマネッジドサービスだと、GCPではGCP Data Catalog、AWSではAWS Glue、AzureだとAzure Data Catalogがデータカタログを作るためのツールとなりますが、扱うデータサイズが大きくなりメタデータ管理の重要性が注目されている昨今、これら以外にもいろいろなツールやサービスが生まれています。
今回は、その中の一つであるDataHub(https://github.com/linkedin/datahub)を触ってみたので、具体的にどんな操作をしたのか、使用感や改善されると嬉しいなと思ったことを書きたいと思います。
1.文献調査
過去DataHubをレビューした方がいるか調べたところ、Classmethodさんのブログがあった。
https://dev.classmethod.jp/articles/linkedin-datahub-getting-started/
しかし執筆年が2021年1月21日と若干古く、Quick StartもDataHubのリポジトリ記載のものとは異なっていた。とはいえ、サービスのコンセプトは変わらないのと思うので、本ブログでは執筆時点(2021年12月)の操作感・使用感にフォーカスする。
*本ブログ内容も時間と共に古くなると思うので、もし執筆時から大きく時間が経っていたら公式ドキュメントで最新情報を参照いただきたい。
2.インストール方法
以下のQuickstart Guideに従えば簡単にインストールできる。その際、Dockerに割り当て必要なコンピュータリソースをあらかじめ割り当てておく。
https://github.com/linkedin/datahub/blob/master/docs/quickstart.md
執筆者の環境では以下のように割り当てた。
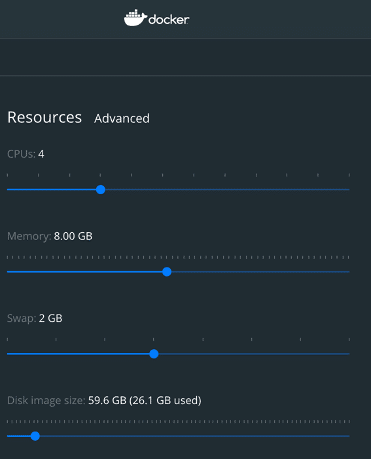
なお、執筆者の実行環境は以下

Quickstart Guideのリンクにもあるが、DataHubを立ち上げる時は、`datahub docker quickstart`を実行する。これによってDocker Composeが立ち上がり、コンテナとコンテナネットワークがビルドされる。
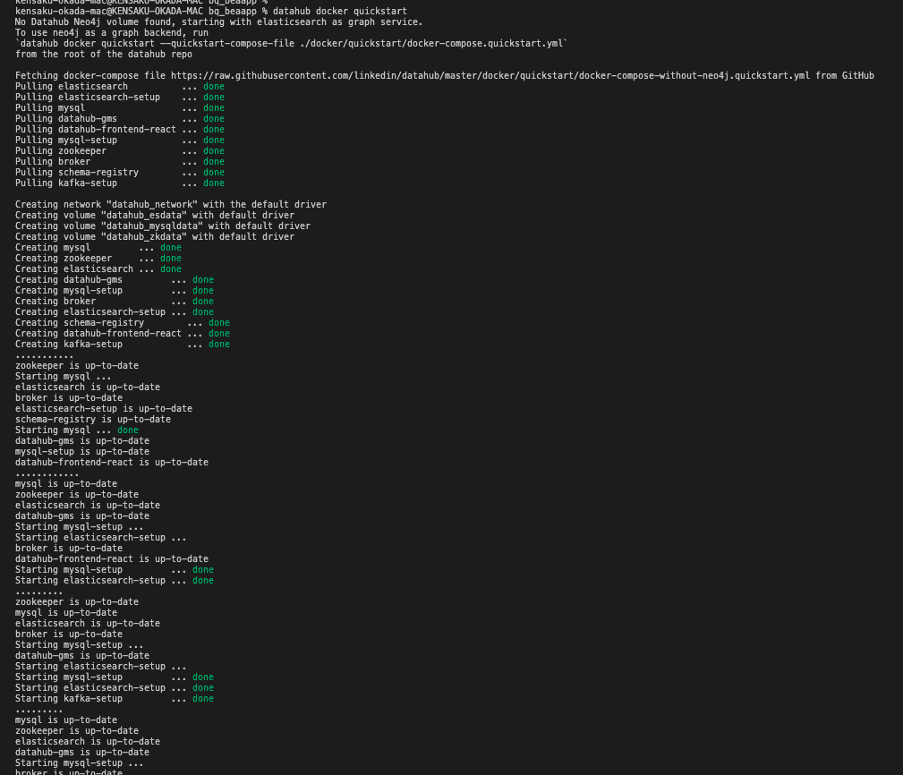
成功すると、最後に以下のようなメッセージが表示され、ブラウザでhttp://localhost:9002/にアクセスするとDataHubのトップページが表示される。


停止したい場合はターミナルで`datahub docker nuke` コマンドを実行する(サンプルデータなど、あらかじめ取り込んだデータをキープしたければ`datahub docker nuke –keep-data`とする)。
3. データの取り込み方法
ここでは、弊社でよく使うBigQueryからDatahubにデータを取り込む方法を紹介する。と言っても、方法はそんなに難しくはない。まず、以下リンクの指示に従い` pip install 'acryl-datahub[bigquery]' `コマンドを実行しプラグインパッケージをインストールする。
その後、任意の名前のyamlをファイルを作成し(ここではbq_to_datahub_sink_rest_api.yamlとする)、以下のコマンドを実行すると、yamlで設定した情報に基づきデータがDataHubに取り込まれる。
`datahub ingest -c ./datahub/bq_to_datahub_sink_rest_api.yaml`
ここで少し詰まるのが、yamlファイルの設定方法。上記公式リンクのサンプルだと、sinkの記述がないので、別途sinkを設定するスクリプトを探す必要がある。
sinkとsourceの一覧は以下のリンクにあるので、sinkに記述するスクリプトは当該リンク先のコマンドを確認して欲しい。
https://github.com/linkedin/datahub/blob/master/metadata-ingestion/README.md
現在、sinkとしてはREST API、file, console, kafkaが選べる。サンプルではREST APIとしてローカルでDataHubを立ち上げた時のURLが書かれているが、これを別のアプリケーションのサーバーのURLに変更することで、任意の分析やサービスへの利用が可能になると思われる。
執筆者の環境では以下のようにyamlファイルを設定することで、ローカルのDataHubにメタデータを取り込むことができた。
source:
type: bigquery
config:
# Coordinates
project_id: hogehoge-sandbox # ここを読者の環境に併せて変える
table_pattern:
ignoreCase: True
sink:
# sink configs
type: "datahub-rest"
config:
server: "http://localhost:8080"
ちなみに、サーバーのアドレスだが、立ち上がっているコマンドを確認すると、”linkedin/datahub-gms:head”というコンテナのポートと一致しており、こちらが入り口になっていることがわかる。

実際のデータを使って、BQのメタデータが本当にDataHubに取り込まれたのか、GUIで確認してみる。
以下のようなダミーデータセットとダミーデータをBQに用意する。
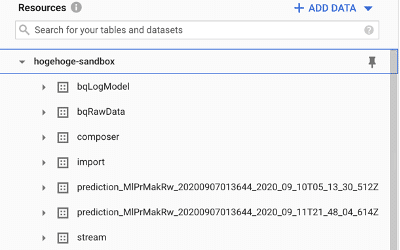
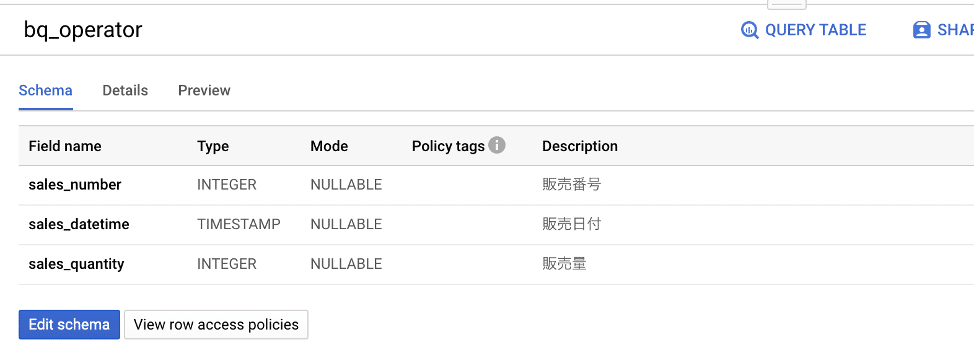
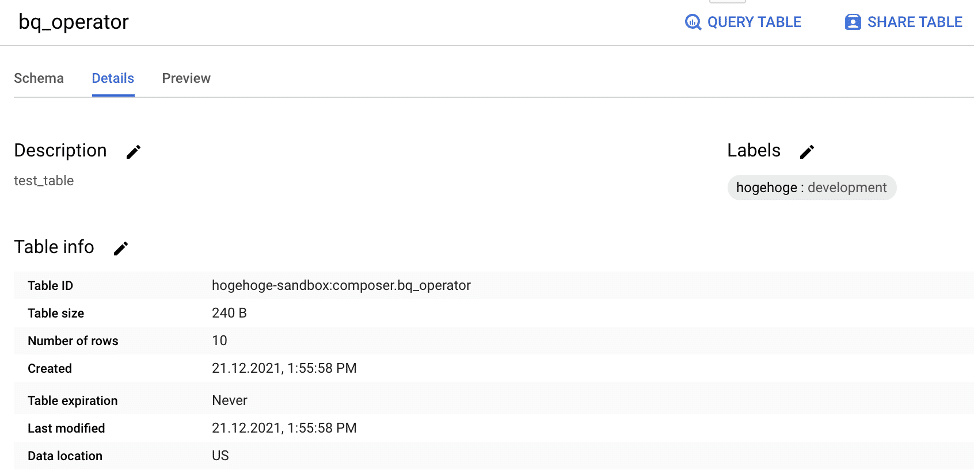
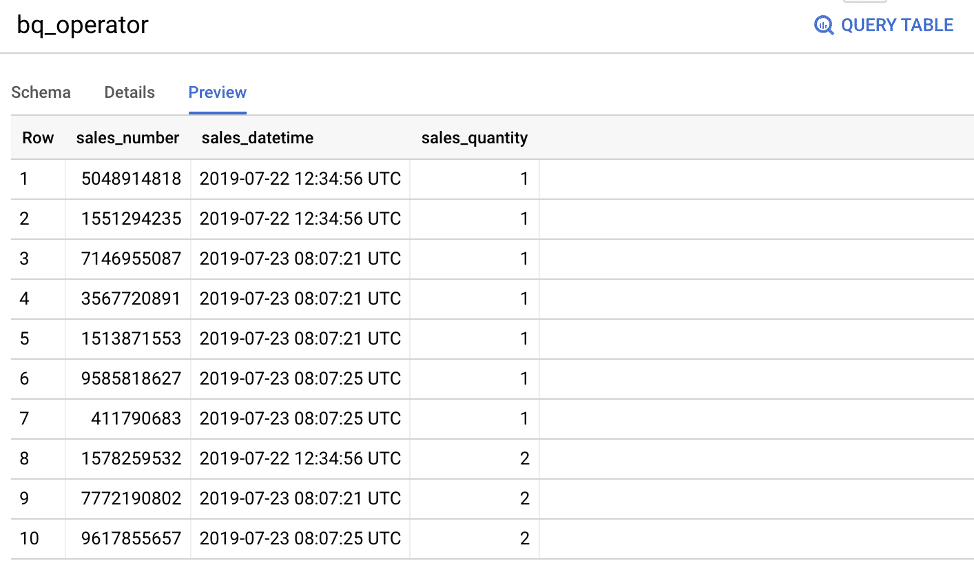
これを、前述した方法でDataHubに取り込むと以下のように、カラム名ごとに型とBQのGUIで指定したDescriptionが表示される(DataHub上で変更も可能)。また、TagsやTermを任意に付けることで(Termsの付け方はこちらを参照)、各カラムの検索性向上やより意味が分かりやすく管理できる。
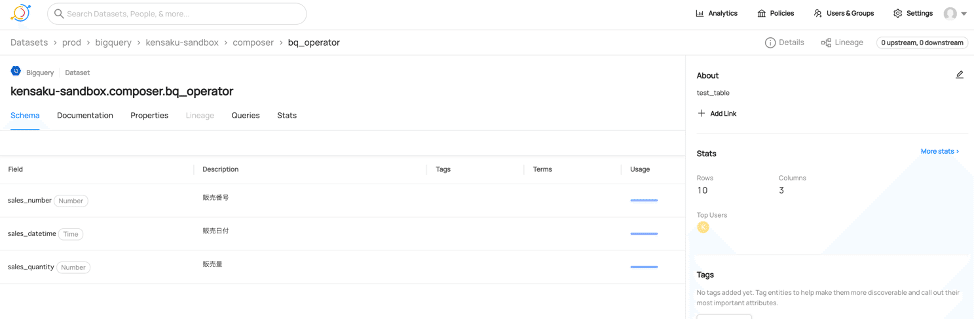
例えば、以下のようにTagをつけて、左上の検索窓で”fugafuga”と検索すると、
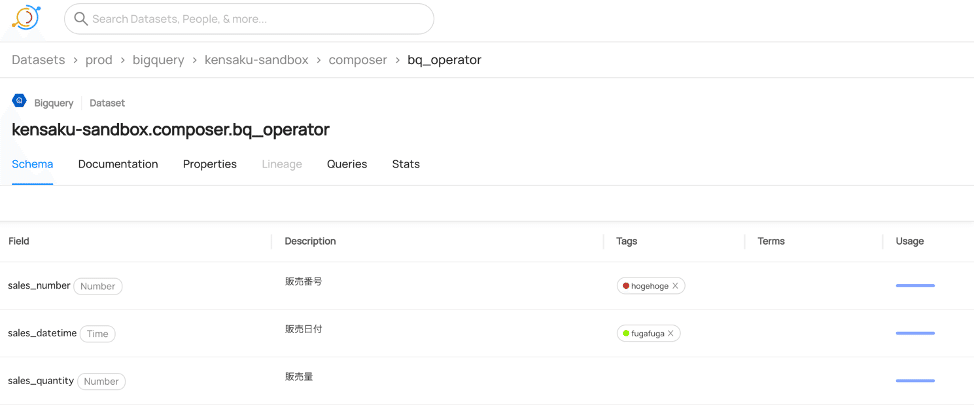
このように”fugafuga”と検索したカラムが一覧表示される。
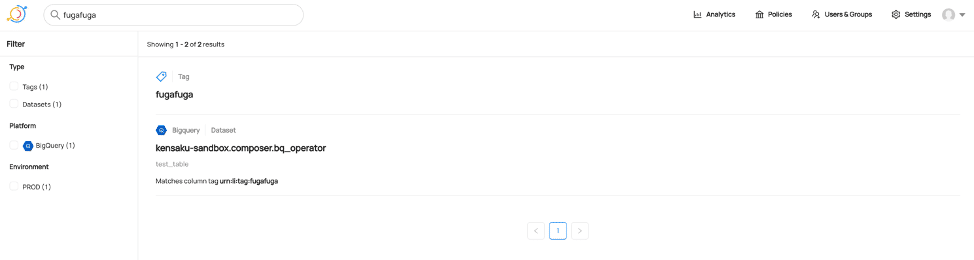
もちろんテーブル横断的に検索できるし、DataHubはさまざまなデータソースに対応しているので(現時点で対応しているSourceとSinkはこちらを参照)、タグ付けしてこれらを横断的に検索・管理できるのはメタデータ管理上かなりありがたいと思った。
Documentation タブでは、テーブルのDescriptionが表示される。
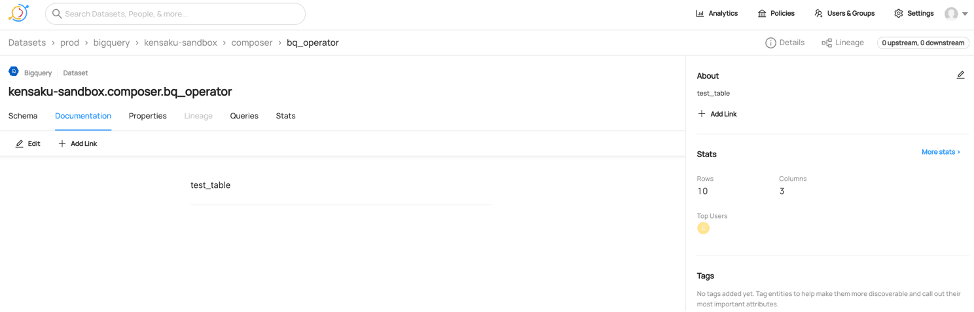
さて、これまでBQからDataHubにメタデータを取り込む方法を見てきたが、逆にDatahubで設定したメタデータをBQに持っていくことはできるのだろうか?執筆者が調べた限りでは、それを簡単に実現する方法はリポジトリのREADMEからは見つからなかった。おそらく現時点で実現するには、yamlファイルで設定するREST APIリクエストを受けるサーバーを自前で立てて、そこからBQのAPIを叩いて反映する必要があると思われる。もしこれが実現できたら、メタデータの入力管理はGUIで行い、その情報をBQのGUIに常に同期されることでBQ上のユーザビリティが増すのでは、と思った(が、ブラウザをそれぞれ立ち上げて、別ウィンドウでクエリエディタとしてのBQのGUIとDataHubをそれぞれ表示すれば、同じような経験を得られるので費用対効果は高くないかもしれない。。。)。
4. 他に試したこと
4-1 他のSinkを試した
前述したようにREST API、file, console, kafkaが選べ、今回は手軽にできるfileとconsoleを試した。Fileの場合は、yamlファイルを以下のように設定する。
source:
type: bigquery
config:
# Coordinates
project_id: hogehoge-sandbox
table_pattern:
ignoreCase: True
sink:
type: file
config:
filename: ./datahub/bq_to_file.json # 任意の出力先ファイルパス
すると、指定したパスにjson形式でメタデータ情報が出力されるので、例えばこの操作をあるサーバーで行い、出力されたjsonファイルを自社のシステムや別のサービスに送りそちらで管理する、という操作も可能になる。
Consoleの場合は、さらにシンプルに以下のように書く。これによって、jsonファイルに出力された内容を、ローカルのコンソールに出力できる。これはもっぱらデバッグ用と思われる。
source:
type: bigquery
config:
# Coordinates
project_id: hogehoge -sandbox
table_pattern:
ignoreCase: True
sink:
type: "console"
4-2追加で欲しい・更新して欲しいと思った機能
OSSでここまでの機能があり、多くのソースに対応したプラグインが既にあるが、一方で「業務で使うにはこういう機能も欲しい」と思った箇所がいくつかあった。
・データの型が(少なくとも表示形式が)BQのそれとは異なる
今回作成したダミーデータでは、BQでは(INTEGER, TIMESTAMP, INTEGER)となっているが、DataHubでは(Number, Time, Number)となっている。この差分は、FLOAT型、NUMERIC型、TIME型などのデータが入ってきたり、他のデータソースと連携したりするときに問題となる可能性がある。
・BQの方で持っている全てのメタデータをDatahubに連携できているわけではない
BQで設定した“Labels” (hogehoge: development)やCreated, Table expiration, Last modifiedなどのテーブル情報はDatahubで確認できなかった。
4-3 SQL Pipelines Pluginを使った
以下のSQL Pipelines Pluginも試しに使ってみた。具体的な使用方法は以下リンク内のREADMEに記載されている。
READMEの記載通りにメタデータを取り込むと、各テーブルの統計情報や、Query Historyを解析してテーブル間の依存関係を自動的に可視化してSQLDagを作ってくれる。このように、データバリデーションができる機能はデータサイエンスの前処理やEDA的にはとてもありがたい(魔改造することで、これをトリガーにして特徴量ドリフトや機械学習モデルの予測精度劣化のアラートを投げることができるかも)。
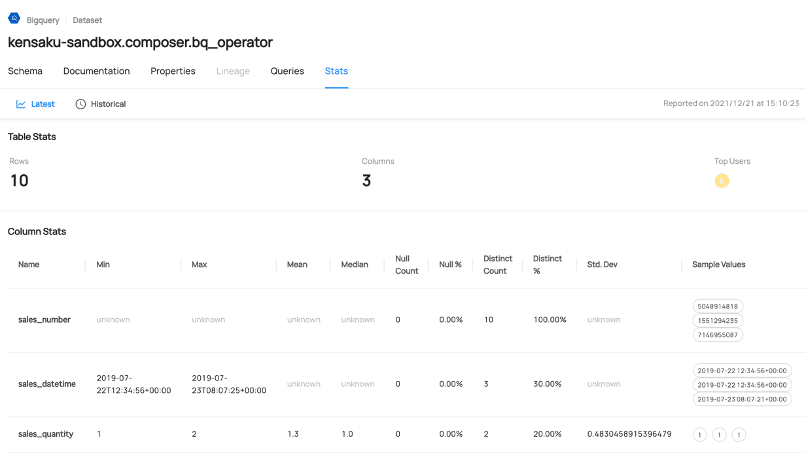
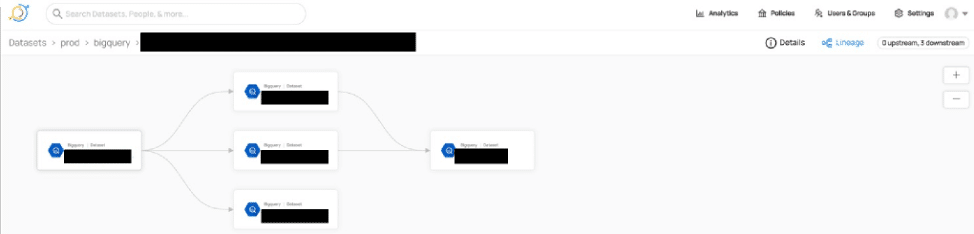
4-4 UIを色々いじった
その他、表示されているボタンを色々叩いてみて、以下の機能があることがわかった。
権限管理・カスタムポリシーの作成:DataHubにアクセスできるユーザーの管理や、各ユーザーがアクセスできるデータセットの種類の制御ができる。
ユーザーグループの作成:ユーザー個別に権限管理・カスタムポリシーを設定するのでなく、ユーザーを一つのグループにまとめて、グループ単位で管理できる。
DataHub全体のAnalytics:Weekly Active UsersやTop Viewed Datasetを見ることができる。
これからどのような機能拡張がされるのか、これからも注視していきたい。
5. 最後に – 理想のメタデータ管理について思いを馳せる
データ分析やデータエンジニアリング系の仕事をしていると、クライアントからデータを受領してモデル作ったりBI作ったりすることがよくある。その時、カラムの定義がよく分からない(e.g. カラムの説明がよくわからない、カラム名が意味不明)、カラムの定義が間違ってる(e.g. データ定義書にNot nullと書いてるのにnullがあった、INTEGERと書いてるのに文字列が混ざっていた)、と言った問題はほぼ確実に起こる。
こう言った問題を少しでも緩和して、データガバナンスを効かせるためには、現状BQとDataHubに入力できるメタデータではどちらも足りない気がしている。
ではどう言ったメタデータがあれば良いのか?社内プロジェクトで考え中だが、追加で以下のようなメタデータカラムがテーブル形式でまとめられていたり、メタデータ管理機能としてあると良いと思う(一部、BQを使うことを前提としている)。
どのカラムがpartition key/clustering keyになっているか(これらに指定されたカラムにnullが入っていたらwarningを出す)
文字列型カラムに対しては正規表現が書け、入力される内容を説明・制限する
区分値型カラムに対しては、辞書型で入力される数字と、対応する文字列が書ける
各カラムの用途(e.g. 何のKPIを計算するのに使うのか。何の業務に使うのか)が書ける
各カラムの発生元 (e.g. どのデータソースで生まれたデータなのか)が書ける
各カラムのデータが変わる頻度が書ける
データ分析上使用すべきでないカラムか否か(e.g. 古いIDのみを格納したカラム、途中でデータ定義の変わったカラム)が書ける
テーブルを横断的にみた時、似たような名前のカラムがあってDescriptionがない場合、Warningを上げる機能
取り込んだデータをもとにして作られたSQLDagをもとに、特定のKPI(Martで作った、可視化用に最終的に欲しいカラム)がどのカラムをもとにして計算されたかをSQLDag上でハイライトできる機能