
LangChainで3大クラウドのLLMを使ってみる

本記事は、Japan Digital Design Advent Calendar 2023 の21日目の記事になります。
三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でTech PM(Technichal Project Manager)をしている吉竹です。PM職ですが、技術検証やアーキテクチャ検討、開発も行っています。
はじめに
業界に大きな影響を与える大規模言語モデル(LLM)ですが、LLMをアプリケーションに統合するためのフレームワークとしては LangChain が広く知られています。LangChainの大きな特徴として、様々なLLMを抽象化して利用できることがあげられます(*1)。これにより、OpenAI, Google, Anthropic といったプロパイダーが提供するLLMを、統一的なインタフェースで利用できます。
LangChainの公式ブログにも以下の通り記載されています。Google 翻訳と合わせて引用します。
One of the objectives of LangChain has always been to allow for interoperability between language model providers
---
LangChain の目的の 1 つは、言語モデル プロバイダー間の相互運用性を可能にすることです。
LLMのプロパイダーとしてはやはりOpenAIが有名です。一方で、LLMをアプリケーション内から利用する方法として、いわゆる「3大クラウド」が提供する以下のサービスを経由する選択肢も考慮に入れられるでしょう。
Azure
Azure OpenAI Service
利用できるモデル:GPT-4, GPT-3.5, etc.
Google Cloud
Vertex AI
利用できるモデル:PaLM 2 for Text, Codey for Code Completion, etc.
参考:Explore AI models in Model Garden | Vertex AI | Google Cloud
2023/12/14 にGemini Proもプレビューになりました。
AWS
Amazon Bedrock
利用できるモデル:Claude v2.x (Anthropic), Titan Text G1 - Express v1 (Amazon), etc.
本記事では、3大クラウド経由で利用できるLLMを、LangChainにより統一的なインタフェースで利用する方法についてご紹介させていただきます。
注意事項
LLMおよびLangChainは非常に進歩が速い分野です。本記事は2023年12月時点の情報で執筆していますが、時間の経過と共に利用方法等が変わる可能性も高いためご注意ください。
3大クラウド上でLLMをセットアップする方法や、LangChainについての基礎的な説明は割愛させていただきます。
本記事はLLMの精度や精度向上の方法を検証するものではありません。
(*1) 利用できるモデルは公式ドキュメントご参照ください。
Python版:Model I/O | 🦜️🔗 Langchain
JavaScript版:Model I/O | 🦜️🔗 Langchain
環境
node: 18.12.1
TypeScript: 5.3.3
macOS: 13.6.2
langchainjs: 0.0.207
JavaScript(TypeScript)版のLangChainを用いて解説を行います。
一方で、Python版のLangChainでもほぼ同様の関数を使って実装が可能ですので、Pythonユーザーの方もこの内容を参考にしていただければと思います。
#私も本当はPythonユーザーで、ほぼ同じ処理を先にPythonで書いていたりします。
前提知識
本記事では、LLMの代表的なユースケースとされるRetrieval-augmented generation (以下、RAG) アプリケーションを実装します。RAGをご存じの方は、このセクションを読み飛ばしていただいて問題ありません。
RAGとは?
RAGについては、Python版LangChainの公式ドキュメントにわかりやすい説明がありますので、そちらを引用します。RAGにより、LLMが学習していない最新の情報やプライベートな社内情報を基にした推論が可能になります。
RAG is a technique for augmenting LLM knowledge with additional, often private or real-time, data.
LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model’s cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG).
---
RAG は、プライベート データやリアルタイム データを追加して LLM の知識を強化するための技術です。LLM は幅広いトピックについて推論できますが、その知識はトレーニングを受けた特定の時点までの公開データに限定されています。 プライベート データやモデルの終了日以降に導入されたデータについて推論できる AI アプリケーションを構築したい場合は、必要な特定の情報でモデルの知識を強化する必要があります。 適切な情報を取得してモデル プロンプトに挿入するプロセスは、検索拡張生成 (RAG) として知られています。
LangChainを使ったRAGのアーキテクチャ
こちらも公式ドキュメントを基に説明します。
ユーザーからの質問を回答するRAGアプリケーションを題材に考えます。このアプリケーションは、大きく分けて2つのコンポーネントで構成されます。
Indexing
Retrieval and generation
Indexing
LLMにデータを追加して知識を拡張するコンポーネントです。
追加するのはマークダウンやPDF、JSONなど様々なテキストデータです。これらをベクトル化して保存しておき、推論時に利用します。
以下の図は、Indexing の流れを表したものです。
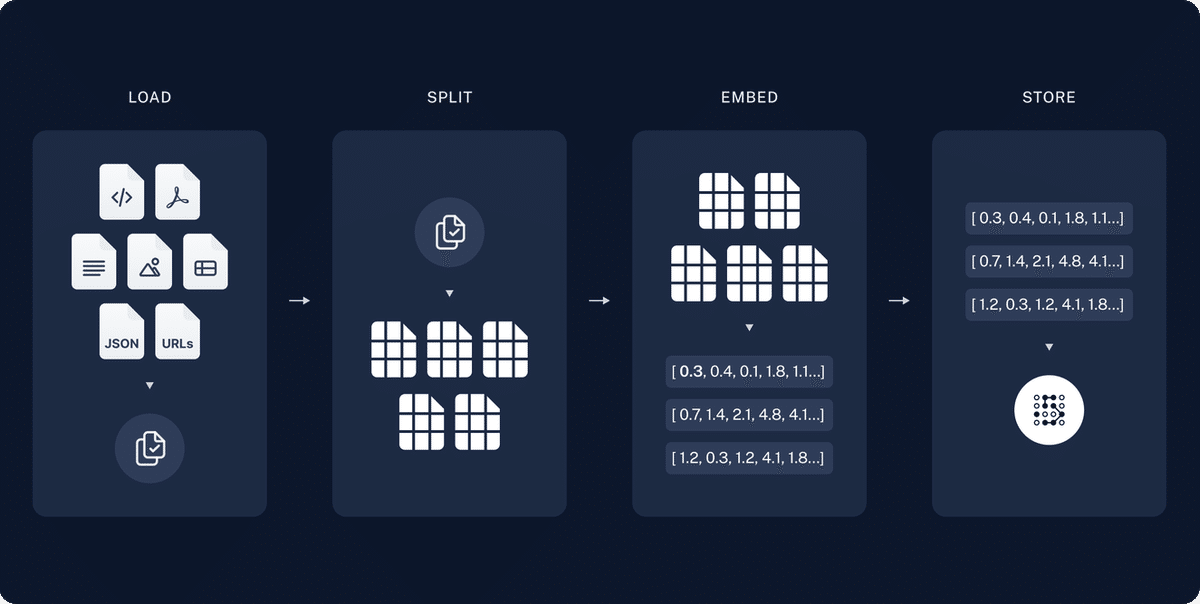
Load
ファイル等からテキストデータを読み込む処理
Split
テキストデータを chunk と呼ばれる小さな単位に分割する処理
抽象化して Transform と記載されることもあります。
Embed(Embeddings)
分割したテキストデータをベクトル化する処理
Store
ベクトル化したデータを保存する処理
Retrieval and generation
ユーザーからの質問に回答するコンポーネントです。
受け取った質問に対し、Indexingのプロセスで保存されたデータを利用してLLMが回答を行います。
流れを表したのが以下の図です。
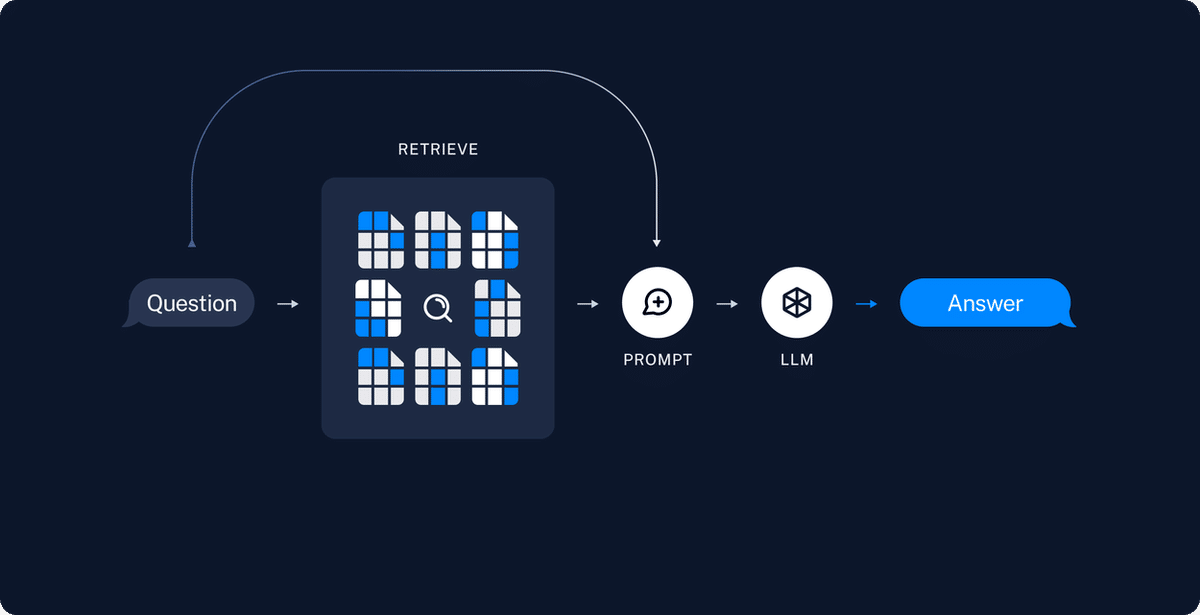
Retrieve
ベクトルの類似度またはキーワードマッチにより、ユーザーからのインプットに関連する情報をStoreから取得する処理
Prompt / LLM (Generate)
LLMが取得したデータとプロンプトを基に回答を生成する処理
LangChainでRAGを実装すると、上記のアーキテクチャをそのまま落とし込むようなコードになります。
準備
利用するモデル
アーキテクチャのうち、以下の処理ではプロパイダーから提供されるモデルを利用します。これがLangChainによりほぼ統一的なインタフェースで扱える部分です。
本記事ではそれぞれ以下のモデルを利用します。

追加する情報
今回は、LLMが学習していない情報として、2023/12/7にGoogleから発表された Gemini の情報を追加します。各LLMに Gemini のことを聞くと、いずれも正しいとは言えない回答が返ってきます。このことから、Geminiの情報はまだ学習していないことが伺えます。
# プロンプト
Google Geminiの概要を1文で説明してください。
# gpt-4 (Azure OpenAI)
Google Geminiは実際に存在しないサービスであり、おそらくGoogleの検索エンジンや広告プラットフォームと関連したコンテキストで言及されることがあるかもしれませんが、特定の「Google Gemini」という名前の製品やサービスはありません。
# chat-bison@001: (Vertex AI)
Google Geminiは、ウェブブラウザで広告をブロックし、ユーザーにプライバシーを提供することを目的とした、開発中のオープンソースのWebブラウザです。
# anthropic.claude-v2 (Amazon Bedrock)
Google GeminiはGoogleの大規模な検索エンジンのアップグレードであり、より関連性の高い検索結果を提供することを目的としています。
追加する情報は以下のページです。これをマークダウンに変換して、./target-docs/gemini フォルダに格納しておきます。
対象ページ:最大かつ高性能 AI モデル、Gemini を発表 - AI をすべての人にとってより役立つものに
コード
前置きが長くなりましたが、ここから実際のコードになります。
なお、簡易化のため Indexing と Retrieval and generation は1つのコードとしています。
Azure OpenAIの場合
今回は、API KEYを使ってAzure OpenAIへ接続します。API KEY は Azure OpenAIのコンソールから確認できます。
import { DirectoryLoader, UnknownHandling } from 'langchain/document_loaders/fs/directory'
import { TextLoader } from 'langchain/document_loaders/fs/text'
import { ChatOpenAI } from 'langchain/chat_models/openai'
import { OpenAIEmbeddings } from 'langchain/embeddings/openai'
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter'
import { MemoryVectorStore } from 'langchain/vectorstores/memory'
import { RetrievalQAChain } from 'langchain/chains'
process.env.AZURE_OPENAI_API_KEY = 'XXXX'
process.env.AZURE_OPENAI_API_INSTANCE_NAME = 'XXXX'
process.env.AZURE_OPENAI_API_VERSION = '2023-05-15'
const main = async () => {
// target-docs/geminiのディレクトから.mdファイルを読み込み
const loader = new DirectoryLoader(
'target-docs/gemini',
{
'.md': (path: string) => new TextLoader(path),
},
undefined,
UnknownHandling.Ignore // .md以外のファイルは無視
)
const docs = await loader.load()
// ドキュメントを分割
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 400, // chunkSizeは適当な値としています
chunkOverlap: 0,
})
const texts = await textSplitter.splitDocuments(docs)
// Embeddings
const embeddings = new OpenAIEmbeddings({
azureOpenAIApiDeploymentName: 'XXXX', // デプロイしたモデル名を設定
})
// Store
const vectorStore = await MemoryVectorStore.fromDocuments(texts, embeddings)
// Retrieverの作成とchainの作成
const retriever = vectorStore.asRetriever()
const model = new ChatOpenAI({
azureOpenAIApiDeploymentName: 'XXXX', // デプロイしたモデル名を設定
})
const chain = RetrievalQAChain.fromLLM(model, retriever)
const query = 'Google Geminiの概要を1文で説明してください。'
const res = await chain.call({
query: query,
})
console.log(res.text)
}
main()
このコードを実行すると以下の結果が得られます。
Google Geminiは、テキスト、画像、音声を含むマルチモーダルデータを理解し、科学から金融に至る多様な分野で洞察を提供する強力な人工知能モデルです。
Geminiの情報が追加されていることが確認できました!
Azure OpenAI を使う際のポイント
モデルを利用するにはLangChainの ChatOpenAI , OpenAIEmbeddings をimportします。JavaScript版のLangChainではAzure OpenAIとOpenAIは同じクラスを使っていますが、Azure OpenAIでは設定するパラメータまたは環境変数が異なります。
補足ですが、Python版のLangChainでは AzureOpenAI , AzureOpenAIEmbeddingsのクラスを利用します。同じPython版でもバージョンによって異なりますのでご注意ください。
LangChainは、デフォルトでは環境変数に設定された API KEY や INSTANCE_NAME を取得します。これにより、Azure上にデプロイされたモデルを利用できます。new ChatOpenAI のタイミングで直接指定することも可能です。
参考:Azure ChatOpenAI | 🦜️🔗 Langchain
Vertex AIの場合
Vertex AI API が有効化されたプロジェクトへ接続するため、事前に以下を行う必要があります。
公式ドキュメントを参考に、サービスアカウントキーを作成します。認証を行う方法はいくつかありますが、今回は簡易化のためキーを利用します。作成したファイルは ./.config/ に保存しています。
Google公式の Auth Client をインストールします。
npm install google-auth-libraryこれで準備ができました。
コードですが、Azure OpenAI のセクションに載せたコードから以下を変更するのみで済みます。
利用するChat とEmbeddings のモデルを変更
環境変数の設定(プロジェクトへの認証情報設定のため)
変更したコードは以下の通りです。(...は省略箇所です)
// import するクラスの変更
import { ChatGoogleVertexAI } from 'langchain/chat_models/googlevertexai'
import { GoogleVertexAIEmbeddings } from 'langchain/embeddings/googlevertexai'
...
// GCP用の環境変数を設定
process.env.GOOGLE_APPLICATION_CREDENTIALS = './.config/application_default_credentials.json'
process.env.GOOGLE_CLOUD_PROJECT = 'XXXXX' // プロジェクトID
...
const main = async () => {
...
// Vertex AI の Embeddings モデル
const embeddings = new GoogleVertexAIEmbeddings({
model: 'textembedding-gecko@002',
})
...
// Vertex AI の Chat モデル
const model = new ChatGoogleVertexAI({
model: 'chat-bison@001',
})
...
}インターフェイスも、先ほどと同じような書き方で利用できることがわかると思います。
省略した箇所と合わせて実行結果は以下の通りです。
Gemini は、Google の次世代の AI モデルであり、テキスト、画像、音声、動画、コードなど、さまざまな種類の情報を一般化してシームレスに理解、操作、組み合わせることができます。
こちらも、Geminiの情報が追加されていることが確認できました!
Amazon Bedrockの場合
他クラウドと同じように、AWSアカウントへの認証を行う必要があります。
AWS CLIを設定します。
依存するパッケージをインストールします。
npm install @aws-crypto/sha256-js @aws-sdk/credential-provider-node @smithy/protocol-http @smithy/signature-v4 @smithy/eventstream-codec @smithy/util-utf8 @aws-sdk/types更にEmbeddings が依存するパッケージもインストールします
npm install @aws-sdk/client-bedrock-runtime@^3.422.0これで準備ができました。
AWSアカウントへの接続時には、AWS CLIで設定されたプロファイルの認証情報が利用されます。
デフォルトのプロファイルで良ければ環境変数等の設定は不要です。
コードの変更箇所は、利用するChat とEmbeddings のモデルを変更するのみです。
// import するクラスの変更
import { BedrockChat } from 'langchain/chat_models/bedrock'
import { BedrockEmbeddings } from 'langchain/embeddings/bedrock'
...
const main = async () => {
const region = 'us-east-1'
...
// Bedrockで提供される Amazon の Embeddings モデル
const embeddings = new BedrockEmbeddings({
region: region,
model: 'amazon.titan-embed-text-v1',
})
...
// Bedrockで提供される Anthropicの Chat モデル
const model = new BedrockChat({
region: region,
model: 'anthropic.claude-v2',
maxTokens: 1000,
})
...
}省略した箇所と合わせた実行結果は以下の通りです。
Geminiは、Googleが開発した大規模な多目的学習モデルです。
随分とあっさりした回答が返ってきました…
間違ってはなさそうですが、確認のため少し質問を変えます。
# 質問
Google Geminiとは何か、100字以内で説明してください。
# 回答
Geminiは、Googleが開発した大規模な多目的学習モデルです。テキスト、画像、音声などのデータを理解し、複雑な質問に答えたり、推論を行ったりすることができます。
無事にGeminiの情報が追加されていることが確認できました。
コードについて一点補足です。BedrockChat の生成時にmaxTokens を設定していますが、これはデフォルトだとBedrockの回答が短いためです。一文で回答してもらうような質問であれば良いのですが、それ以外だと回答が途切れるようなことがあったため設定しています。
以上で、3大クラウド上で利用できるLLMを、LangChain経由で使うことができました。
応用に向けて
今回は、LangChainによる抽象化にフォーカスしたため、非常に簡素化したコードでした。ただ、応用するには修正する点が多数ありますので、その一例を紹介します。
IndexingとRetrieval and generationの分離
Indexingは追加学習データを読み込む処理なので、事前にオフライン実行することが可能です。ユーザーからの問い合わせの都度、データの読み込みとEmbeddings を行うのは、パフォーマンスやコスト的にも良くありません。そのため、これらの処理は分離すべきです。
プロンプトの設定
コードではLLMへの入力(質問)を固定していますが、実際の入力は可変であることがほとんどです。Prompt や Chain 等を用いて、入力に対してインタラクティブに回答できるようにする必要があります。
Vector storesの利用
ベクトルデータの保存先としてMemoryVectorStore を利用しましたが、永続化のためには何かしらのデータベースを利用する必要があります。各クラウド上で提供されるものとしては以下のようなサービスがあります。
Azure AI Search
Google Vertex AI Matching Engine
OpenSearch
これらもLangChainから抽象化して利用することが可能です。利用方法は公式のドキュメントを参照してみてください。上記以外にも利用できるVector storesが多数掲載されています。
(Azure AI Searchは、執筆時点でPython版のみのようです。)
参考:Vector stores | 🦜️🔗 Langchain
パラメータの設定
LLMによる回答をコントールするパラメータとして、TemperatureやTop_p(*1)等が広く知られていると思います。これらの設定もLangChainで行うことが可能です。
以下はChatGoogleVertexAI での例です。
const model = new ChatGoogleVertexAI({
temperature: 0.9,
model: 'chat-bison@001',
})参考:ChatGoogleVertexAI | langchain - v0.0.209
なお、パラメータはモデルごとに異なりますので、設定方法は上記LangChainのAPIリファレンスを参照してください。
(*1)パラメータの概要については、各クラウドの公式ドキュメントや以下サイトが参考になると思います。
最後に
長くなってしまいましたが以上となります。
LLM及びLangChainは、日々進化する技術分野であり、その活用については様々な議論が行われています。今後もこの進化を継続的にキャッチアップしていければと思います。
本記事がどなたかのお役に立てば幸いです。最後までご覧いただきありがとうございました。
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちら
Technology & Development Div
Naoki Yoshitake