
言語モデルの知識に対する削除・Unlearning・検出ーNLP2024参加報告③

はじめまして、三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)に所属する上野です。
3月11日~15日にかけて神戸で開催されたNLP2024 (言語処理学会第三十回年次大会)に参加してきました。JDDでは参加メンバーそれぞれが興味深かった発表についてまとめています。
本記事では、NLP2024で発表された言語モデルが獲得した知識の削除や検出に関連する論文を3つ紹介いたします。
1. 言語モデルからの知識削除:頻出実体の知識は副作用が破滅的

最初に紹介するのは言語モデルからの知識削除についての取り組みです。LLMのみならず大量のデータを用いて学習したAIモデルにはプライバシー情報が含まれてしまう可能性があります。そのような観点からMachine UnlearningやKnowledge Editingと呼ばれるような研究が盛んになっています。紹介する論文では、エンティティの頻出度合の違いによってAIモデルの知識を削除した際の影響を明らかにすることを目的にしています。
内容
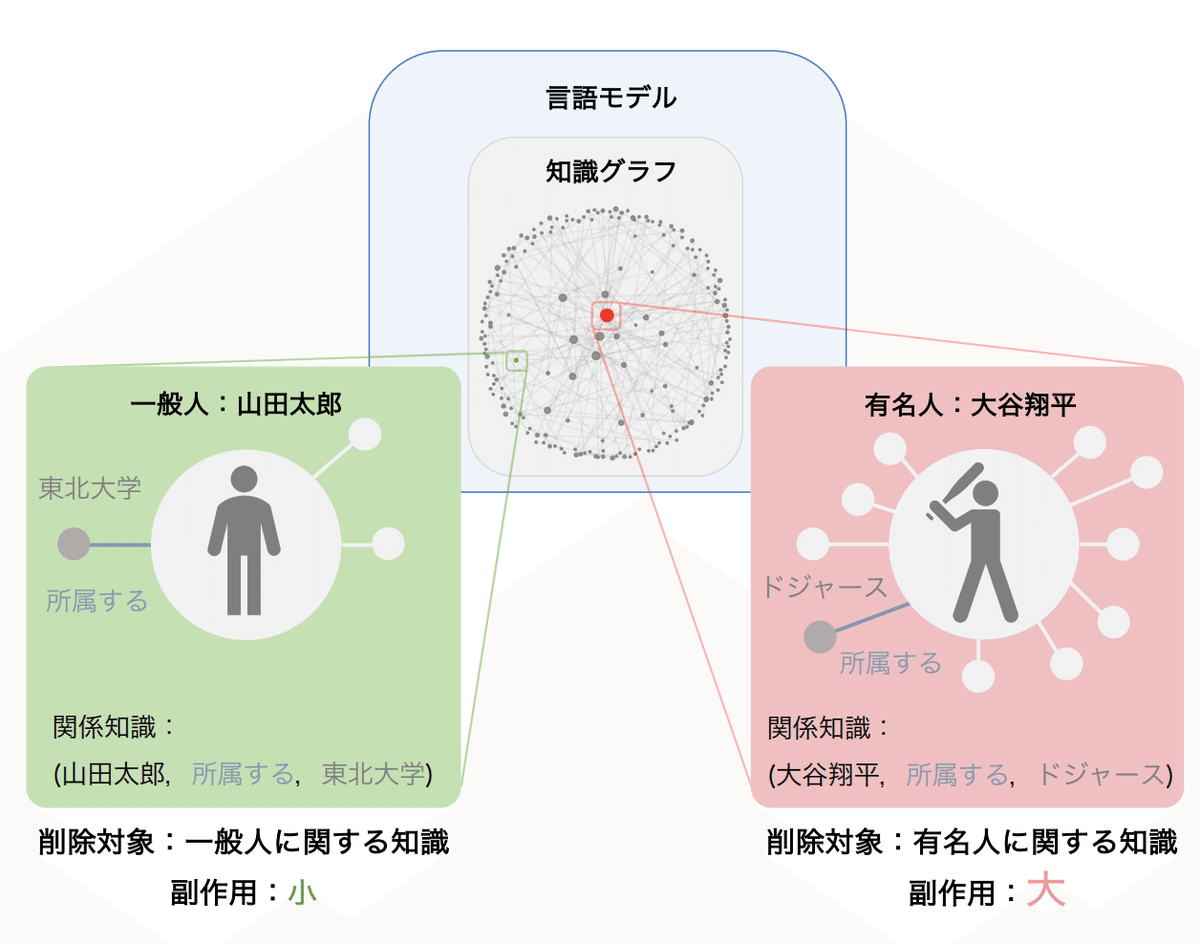
言語モデルを活用する際にはプライバシーに関する課題や、言語モデルの知識が学習データとして収集された時点までしか持てないという課題があります。それらの課題に対処するために言語モデル(LM)の知識削除や知識編集に関する研究が行われていますが、LMに学習させる知識の構造を考慮した分析は少ないです。知識の構造に着目すると、例えば、図にあるように一般人の山田太郎というエンティティを削除した時よりも、関連しているエンティティが多く結びついている有名人である大谷翔平というエンティティを削除した場合の方が影響が大きいのではないか?と考えられます。本論文では、そのような知識の構造に着目して分析を実施した結果に基づいて、頻繁に出てくる知識の削除は大きな副作用を伴うことを明らかにしています。
これを検証するために、当該論文では制御された知識構造として、(subject, relation object)のトリプレットで表現される2種類の人工的な知識グラフを構築します。一つはノード間にエッジを張る確率が一定となるErdos-Renyi(エルデシュ・レーニィ、ER)グラフ、もう一つはより実世界に近いノードの次数がべき乗則に従うBarabasi-Albert(バラバーシ・アルベルト、BA)グラフです。
これらの知識グラフを用いて検証を行う手順について説明します。最初にそれぞれの知識グラフをGPT-2と同様のアーキテクチャを持つLMを用いて学習させます。次に、学習させたLMに対して主要な知識編集手法の一つであるROMEを用いて知識の削除を行います。知識編集では通常、 (s, r, o*) というように新たに別のエンティティに関連づけますが、この論文では
(s, r, e_deleted) のように削除されたことを表すエンティティを用意してそれに関連づけるように編集することを知識の削除と定義しています。知識削除はCausal TracingとRank-One Model Editing(ROME)という2つのステップで行います。Causal Tracingでは、知識に関する情報を予測する際のモデルの隠れ状態の寄与を分析し、重要な役割を果たすモデル構成要素を特定するのが目的です。次にCausal Tracingで特定したfeed-forward層における重みをkeyとvalueのペアとみなし、新しいkey-valueペアに更新するように重みを修正するRank-One Model Editingという方法で知識を編集します。

上のグラフはエンティティ(実体)の次数と削除による影響度(知識削除前後の知識全体の正解率の差)の関係を示しています。グラフを見ると、実世界と異なる構造のERグラフにおいては次数の大きさと影響度の大きさに関係が見られませんでした。一方で、実世界に似た構造のBAグラフにおいては次数の高いエンティティから次数の低いエンティティへ概ね右肩下がりに影響度が落ちていることが確認できます。また、モデルサイズを変更しても同様の関係が見られたとのことで、本実験設定ではモデルサイズに対してロバストな現象が明らかとなりました。このことから頻出エンティティとそれに結びついているエンティティの効果的な編集への応用につながることが期待できます。
2. 逆学習による言語モデルの解析

次に紹介するのは、上の論文と同様に言語モデルに学習された知識(データ)の忘却に関する研究です。LLMが学習する大量のコーパスには倫理的問題やセキュリティ、プライバシー上問題のあるコンテンツを含んでしまっている場合があります。それらによって、LLMが偏見のあるコンテンツやプライバシー情報を曝露するようなコンテンツを生成してしまう可能性があります。そのような問題を防ぐためにLLMを再学習させることはコストがかかるため、特定の知識をUnlearningする方法は代替手段として有望です。紹介する論文ではUnlearningを活用して要因となる特定のデータセットを検出する手法について提案しています。
内容
ChatGPTやGeminiなどの普及により大規模言語モデル(LLM)はアカデミックに留まらず実社会にもインパクトを与えています。一方でLLMは上記で述べた通り有害な文章を生成する可能性があり、安全性について懸念があります。LLMの高い能力を維持しつつ、生成時に有害な影響を及ぼす原因となる学習データの特定を行うための理想的な方法は、各学習データを除いてモデルを再学習し、評価データにおける性能の変化を測る方法(leave-one-out)が考えられます。ですが、この方法は計算コストが膨大になり現実的ではありません。他の方法としてHessian-based Influence Functions(HIF)やTracInといった方法が提案されてきましたが、膨大な計算量やチェックポイントが必要となります。この論文では上記の課題を解決するため学習データを除く代わりに、学習済みモデルから有害なデータを忘却させる方法として注目されている逆学習(Unlearning)を応用して学習データの影響を推定する2つの手法を提案しています。

1つは評価データセットに対する影響を推定するUnTracです。UnTracでは学習データセットのバッチを用いて逆学習の各ステップで勾配上昇法により損失関数を最大化するようにモデルを更新し、更新前後のモデルの差分を用いて評価データセットに対する影響を推定します。もう1つは学習データセットの数に対してスケーラブルな方法であるUnTrac-Invです。UnTrac-Invでは、UnTracで用いていた学習データセットの代わりに評価データセットを用いて逆学習を行いモデルを更新します。評価時には学習データセットに対する損失関数の差分を計測して影響を推定します。また、UnTrac-Invは逆学習のステップ数が少なく、バッチサイズが大きい場合にUnTracと等価であり有効であることが示唆されています。
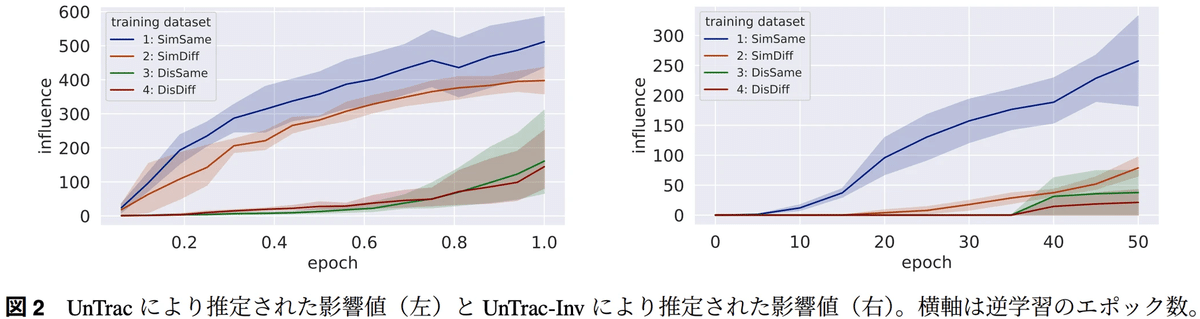
提案手法の検証においてはファインチューニングにおける場合と事前学習における場合とに分けて実験を実施しています。ファインチューニングの実験では事前学習済みモデルを複数のタスクでファインチューニングし、それぞれの学習タスクの影響を正確に推定できるかを検証しています。その際、モデルの出力とタスクのタイプの影響に対処するため、学習タスクを評価タスクと類似する/しない、出力形式が同じ/異なるという4つ用意することでこの問題に対処しています。実験に用いるモデルはT5(3B)を採用し、実験のデータセットを上記の評価データセットと対応する4つの学習データセットを作成し実験を実施しています。グラフを見るとUnTracとUnTrac-Inv両手法とも類似タスク(SimSame, SimDiff)の影響が非類似タスク(DisSame, DisDiff)よりも高く推定されていることが実験結果から確認できます。

事前学習における影響の推定に対する実験では、有害なコンテンツの生成に対する事前学習データセットの影響に対する推定の正確さについて検証を行なっています。検証用のモデルにはBookCorpus, CC-Storiesなど8つのデータセットを学習させたopen pre-trained transformer(OPT)を用いています。また、提案手法のロバスト性を検証するために学習データセットの混合比率を均一な場合と不均一の場合に分けて実験が実施されています。評価データセットとして差別やバイアスを含む文書が格納されているToxiGen, WinoBiasと不正確な回答が格納されているTruthfulQAを用いて各学習データセットの影響を推定しています。評価方法としてleave-one-outにより算出された実際の影響と、既存手法も含む各手法で推定された影響とのピアソン相関係数を採用しています。表2を見ると、UnTracとUnTrac-Inv両手法はHIFやTracInなどの既存手法と比べ、実際の影響を比較的高い精度で推定できていそうです。また、逆学習のステップ数と影響値の推定精度との関係の検証結果である図3を確認すると、UnTracはバッチサイズに関わらず逆学習のステップが進むにつれ精度が安定する一方で、UnTrac-Invはバッチサイズが小さい場合やステップ数が大きい場合に有効でないことが示されています。そのため、一定の条件下では有効であると考えられ、この技術を用いた効率的な知識編集への応用可能性を個人的に期待しています。
3.大規模言語モデルに対するサンプリングを活用したメンバーシップ推論攻撃

最後に、学習に使われたデータをモデルの出力から検出するメンバーシップ推論攻撃(Membership Inference Attacks; MIA)に関する研究について紹介します。MIAはブラックボックスな機械学習モデルに対する攻撃手法で、特にプライバシー情報の漏洩などに関する領域で扱われてきました。LLMにおいてはプライバシー情報の曝露という文脈に加えて、学習データに含まれている著作物の特定を目的としたMIAの応用の研究も進んでいます。
内容
OpenAIやGoogleなどの開発者は大規模言語モデル(LLM)に使われた学習コーパスについて公表を控えており、LLMの生成テキストについて著作権侵害のリスクが生じます。また、評価用のベンチマークがLLMの学習に含まれている場合にモデルの性能を適切に評価できないという問題も存在しています。本論文ではメンバーシップ推論攻撃(MIA)を応用してLLMの学習データに検出対象のテキストが含まれていたかを判定する手法を提案しています。モデルの学習データに含まれるテキストは含まれないテキストよりも尤度が高くなるという考えに基づいて、MIAの既存研究ではモデルの尤度を計算できることが前提となっており、ChatGPTやGeminiなどの尤度が提供されないモデルには適用できないという課題があります。この課題に対して、論文では尤度に依存しないサンプリングベース・メンバーシップ推論攻撃(Sampling-based Membership Inference Attacks; SaMIA)という手法を提案しています。

具体的には検出対象テキストの冒頭部分(プレフィックス)をLLMに入力として与え、その続きをサンプリングにより複数生成します。検出対象テキストの冒頭以降を参照テキスト、複数生成されたテキスト群を候補テキストとし、それらのテキストの単語の一致度合を計算します。一致度合の計算として、テキスト要約の評価指標でよく用いられるROUGE-Nとzlib圧縮エントロピーを併用した手法を提案しています。zlib圧縮エントロピーを用いたのは、未学習データの生成によく見られる繰り返し生成(例:”I love you, I love you….”)に対する性能改善が目的となっています。

提案手法の評価として、WikiMIAというベンチマークを用いてLOSSやPPL/zlibといった既存のMIA検出指標との比較実験を行っています。評価に際して、MIAの性能がテキストの長さに依存するという点を考慮して32~256の異なる単語数での検出評価と、事前学習されていない新しい情報を保証するために2023年以降のイベントを未学習データとして扱っています。評価モデルとしてはHuggingFaceで公開されている事前学習データのカットオフ日が2022年9月以前のGPT-J6B, OPT-6.7B, Pythia-6.9B, LLaMA2-7Bを用います。評価指標は、既存研究と同様にAUCスコアと低偽陽性率(FPR)に対する真陽性率(TPR)を評価指標としています。最後に、提案手法であるSaMIAとSaMIA*zlibについて候補テキストのサンプル数を10と設定し、単語単位での一致を評価するROUGE-1用いて評価します。
表2の結果を確認するとAUCによる実験の評価は、単語数が多い場合(256)の場合にSaMIAが既存手法を上回っているようです。Avg.列を見ると総合的にSaMIA*zlibの性能が一番高いこともあり、zlibを用いた冗長性の考慮が効果的であることが確認できます。これは尤度を用いない手法でも従来の尤度を用いた手法と比肩する、場合によっては上回ることが示唆される大変興味深い結果となっています。

また、SaMIAの性能に影響を与えるROUGE-N、候補テキストのサンプル数、テキストの長さについての分析では、ROUGE-Nにおいてはユニグラム(N=1)を用いた方が性能が良いこと、サンプル数においては増やすことで性能が改善するが5を超えると横ばいとなること、テキストの長さにおいてはプレフィックスや参照テキストが長い時に正解に関する情報が増えることで検出性能が向上することが確認されています。
まとめ
高性能なLLMを構築するためにOpenAIやGoogleはRedditやstackoverflowなどと提携し、大量のデータを集めています。それらデータが原因となってLLMによる有害コンテンツの生成やプライバシー情報の曝露、著作権の侵害といったリスクが生じる可能性があります。一方でLLMの学習には多大なコストがかかり、LLMの内部情報を効率よくアップデートする技術が求められています。今回ご紹介した論文の学習情報の編集や削除、学習データの特定といった技術は安全性の面においてもLLMの学習やアップデートの効率化においても実務的観点、研究的観点で共にチャレンジングで重要な技術であると個人的に考えているため、上記の論文をご紹介させていただきました。
JDDのM-AISチームではLLMに関するテーマも含めてR&D活動として国内外の学会参加および発表を積極的に実施しています。ぜひ、以下記事もご覧ください。
また、NLP2024においてJDDから2件発表しましたので今後のnote記事で紹介いたします。
最後に
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集しております。カジュアル面談も実施しておりますのでぜひこちらの採用情報からお気軽にお問合せください。