
Data + AI Summit 2024 圧倒的性能のサーバレスに驚き データエンジニア注目のアップデート-参加報告③

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でTechnology & Development Divisionに所属しているデータエンジニアの佐川です。
今回は、サンフランシスコで行われた「Data+AI Summit 2024」(以下DAIS)の参加レポート第3弾としてご紹介させていただければと思います。
過去の参加レポートはこちらをご覧ください。
今年のDAISのメインテーマは「DATA INTELLIGENCE FOR ALL」となっており、「データの民主化」が掲げられていました。DX推進などで「データの民主化」は主要なテーマとしてよく語られますが、これらの推進のためには、データエンジニアリングの観点では以下の点があるかと思います。
データ授受プロセスの高速化、簡易化
今、何が起きているのかデータを通じて「知る」ために、簡単に、より早くデータを受け取るユーザーアクセスの適切な権限管理
データに触れていい人、触れてはいけない人を管理する分析のためのメタデータ管理
データ自身のもつデータの意味、来歴(データリネージ)を管理・共有する結果データの共有
分析したデータを管理・共有する
これらの「管理」を「適切に」と言う点がなかなか難しい部分でもあるかと思います。今回DAISがデータ民主化をテーマとして開催されたのは、こういった管理を行うためのアーテクチャが一通り揃ったので、今年は次のステージへというDatabricksさんの意思の表れかなと思った次第です。
では、今回のDAISで参加したセッションをピックアップしていくつか共有いたします。私はデータエンジニアリングが主たるジョブなので、興味・関心に偏りがあることをご了承ください。
1.Delta Live Tables in Depth: Best Practices for Intelligent Data Pipelines

YouTube : https://www.youtube.com/watch?v=p05eVVnvV3k
このセッションでは、DatabricksのETLフレームワークである「Delta Live Table(DLT)」について説明されていました。DLTは弊社でも積極的に導入を進めています。データエンジニアが、データパイプラインを宣言的に記述でき、エラー処理やスケーリング、監視などの複雑な処理を自動化できる便利な機能です。セッションでは、DLTの新機能、サーバレスコンピューティングの導入による性能向上とコスト削減効果が強調されていました。特に、サーバレスDLTについての2つのベンチマークは興味深い結果がでていました。

YouTube : https://www.youtube.com/watch?v=p05eVVnvV3k
10万個のJSONファイル(合計約2TB)を取り込む実験となります。
サーバーレスDLTは従来のDLTと比較して、以下の結果となりました。
スループットが4倍向上
コストが32%削減
価格性能比で約5倍の改善
YouTube : https://www.youtube.com/watch?v=p05eVVnvV3k
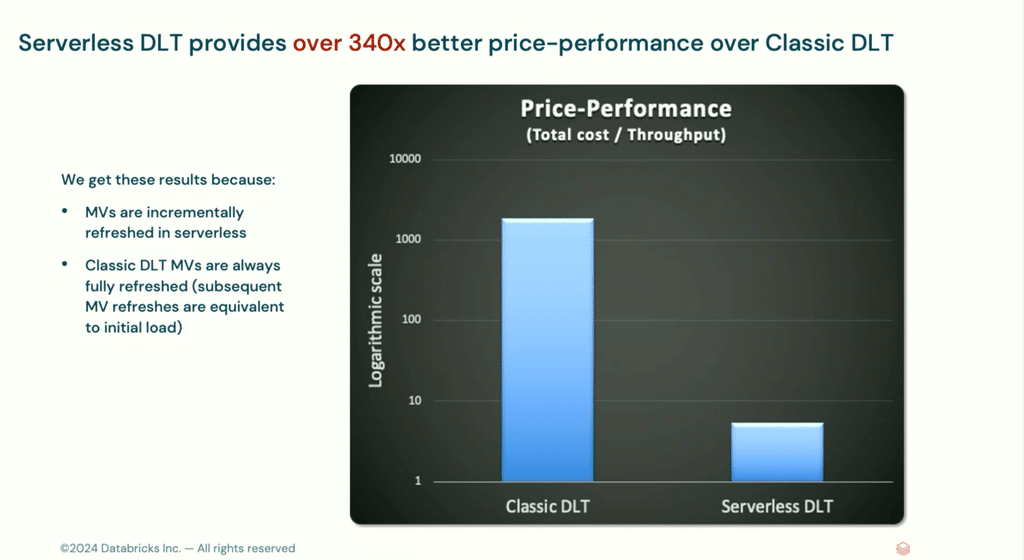
マテリアライズドビューの更新実験として、200億行のデータに対するマテリアライズドビューの作成と更新を行いました。
初回の更新(フル更新):サーバーレスDLTは2倍高速で、コストが45%削減
後続の更新(増分更新):サーバーレスDLTは6.5倍高速で、コストが大幅に削減(クラシックDLTの$1000に対し、サーバーレスDLTは$10以下)
価格性能比で約340倍以上の改善
特に、増分更新の効率性が顕著に改善されていることが強調されていました。
2.Rise of the Medallion Mesh

YouTube : https://youtu.be/K7OFKdjwPxE
Databricksでは、メダリオンアーキテクチャというデータを3つのレイヤー層にわけて管理するデータ設計のパターンを提唱しています。このアーキテクチャをベースに、このセッションでは、データメッシュ、FinOps、MLOps、DevOpsなどの最良の部分を組み合わせ、ビジネスに最適な形で統合するアプローチとして、「メダリオンメッシュ」という新しい概念を提案しています。
私はモダン化という言葉に弱いミーハーエンジニアですので、初めはなんとなく聞いていたんですが、登壇者が、データの重複を避けることの重要性について、特に強調していて、その点が非常に刺さりました。
データ重複の課題として以下の3点を挙げています。
コストの増加:クラウド環境では、データ量が直接コストに影響する。重複はストレージコストを不必要に増加させる。
データの整合性の問題:同じデータが複数の場所に存在すると、更新や管理が複雑になり、不整合が生じる可能性が高くなる。
パフォーマンスの低下:重複データの処理は、計算リソースを無駄に消費し、全体的なパフォーマンスを低下させる。
また、コピーを避けるというのは、単一の信頼できる情報源(Single Source of Truth)を維持するための重要な原則でもあります。

YouTube:https://youtu.be/K7OFKdjwPxE
では、安易なコピーを行わないためにどうすれば良いかというと
Delta LakeやIceberg等のオープンフォーマットを使用し、異なるツールやプラットフォーム間でデータを共有
Lakehouse Federationを活用して、データを物理的に移動せずに異なるソースからクエリできるようにする
Unity Catalogを使用して、全てのデータアセットを一元管理
必要に応じてデータをマテリアライズし、パフォーマンスを向上させつつ重複を最小限に抑える
などを提唱していました。考え方自体は、ある意味基本といった感じなのですが、とても勉強になりました。
3.LAKEFLOW CONNECT: INTRODUCING DATABRICKS’ NEW NATIVE INGESTION CONNECTORS

YouTube: https://www.youtube.com/watch?v=knZY5Nh0FrU
最後にご紹介するセッションは、Databricksの新機能であるLakeFlow Connectに関するものです。従来のデータ取り込み方法の大きな課題として、SaaSアプリケーションのAPIの複雑さ、パイプラインの設定と維持の難しさ、専門的なデータエンジニアの不足などが挙げられます。Lake Flow Connectは、これらの問題に対処するために設計されており、シンプルな設定、統合された管理、効率的なデータ処理を特徴としています。
アーキテクチャとしては、前段でご紹介したDelta Live Tableの前の段階に実行されるもので、ETLの「E」にあたるExtract=抽出の部分を特別な実装なしで簡単に実現するための仕組みといったところでしょうか。


YouTube: https://www.youtube.com/watch?v=knZY5Nh0FrU
セッションでは、SalesforceとSQL Serverからのデータをわずか数ステップで設定できることが紹介されていました。Lake Flow Connectで現在利用可能なコネクタは以下の通りです。
Salesforce Sales Cloud
Workday Reports
Azure SQL DB
AWS RDS for SQL Server
これらのコネクタは今後さらに多く追加される予定があることも言及されていました。
最後に
個人的には、今回初めて、海外の技術カンファレンスに参加してきました。少し驚いたのは、会場に女性の方が非常に多かったことです。基調講演で、ゲストとして登壇されたスタンフォード大、ワシントン大の教授も女性の方であり、セッションの登壇者も、肌感としては、3〜4割くらいは女性の方でした。Databricks自身でも「Women in data + ai brunch and learn」というセッションをやっており、女性の参加に対する啓発活動に非常に力をいれているようでした。
日本の技術イベントでは、ほとんど見ない光景なので、アメリカのダイバーシティを強く印象付けられました。
以上となります。最後までお読みいただきありがとうございました。
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちらにお願いします。