
KDD 2024参加報告②-金融でのAI利用やLLM・グラフを中心に学会聴講

本記事は、Japan Digital Design Advent Calendar 2024の25日目の記事になります。ついにAdvent Calendar 最終日を迎えました。
三菱UFJフィナンシャル・グループの戦略子会社であるJapan Digital Design株式会社でデータサイエンティストをしている高田珠武己 (たかだかぶき) です。
本記事は、2024年8月25日から29日までにスペインのバルセロナで開催された、データサイエンスや機械学習に関する国際学会KDD 2024 (30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining) の参加報告の第2弾です。第1弾はAdvent Calendar 8日目の記事として弊社データサイエンティストの永友遥さんが書いていますので、そちらもぜひご覧ください。
KDD 2024について
KDDはACM (Association for Computing Machinery、米国計算機学会) のデータマイニング分野の分科会です。機械学習・人工知能に関するトップカンファレンスの中では、純粋に学術的な価値だけでなく実社会の課題解決という観点でも研究が評価されやすいことが特徴です。そのためビジネスへの実応用に根差した研究も多く発表されます。KDDの一般研究発表はResearch TrackとApplied Data Science (ADS) Trackの2つに分かれており、後者は特に応用研究の傾向が強いです。

今回のKDDでは、大規模言語モデル (LLM)、グラフ (ネットワーク)、推薦に関する研究発表が流行っていた印象です。特にLLMに関連するセッションは聴講者も多いように感じられました。また、複数の技術領域にまたがるセッション (例えばResearch TrackのGraphs+LLMs & RAG) も開催されていました。
金融への応用という意味では、Research TrackのFinance Session、ADS TrackのFintech Sessionが設けられたり、Workshop (特定分野の招待講演や研究発表がなされる会) のMachine Learning in FinanceやSpecial Day (一日中開催される特定分野の招待講演中心の会) のFinance Dayが開催されたりするなどの盛り上がりを見せていました。
KDD 2024の論文は、学会ホームページ内のProgram > KDD Proceedingsをクリックしてから論文ページを開くことで無料で閲覧することができます (初めから論文ページを開くと "Get Access" と表示されて購入を案内されます)。また、YouTubeでOpening Session, Keynote Talks, ADS Invited Talksなどが公開されていますので、ご興味ある方は以下の公式プレイリストをご覧ください。
論文紹介 (要旨)
以下では、私が現地で聴講した研究発表から選んだ6本の論文の要旨を紹介します。前半3本は金融に関連する論文となっています。また、最初の論文以外はLLMまたはグラフニューラルネットワーク (GNN) に関する内容となっています。各論文タイトルはリンク付きとなっており、括弧書きでトラックとセッション名を記載しています。記事の後半では各論文の詳細な内容を紹介していますので、興味を持った論文があればぜひ後半の詳細をご覧ください。
金融関連
Cost-Efficient Fraud Risk Optimization with Submodularity in Insurance Claim (Research Track - Finance Session)
本論文では、不正調査にかかるコストを抑えつつ効率的に医療保険の保険金請求の不正を発見するために、事実確認すべき病院を最適に選択する手法が提案されました。提案手法は、請求情報と病院の特徴量から不正が確認される確率を推定する深層学習モデル、コストの制限下で不正が確認される確率を最大化するアルゴリズムの2つから成ります。実験では不正確率推定モデルの性能が他手法よりも高いこと、不正確率最大化アルゴリズムが他手法よりも速く収束することが示されました。提案手法はAlipayで実装されているそうです。
SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning (ADS Track - Marketing Applications Session)
本論文は説明性を持つ不正検知用GNNを提案しました。不正ノードを予測するモデルの中に、予測結果への各ノード特徴量の寄与度、各エッジの寄与度が組み込まれており、これらが説明性の役割を果たします。そのため、不正の予測とは別で説明用のモデルを学習する必要がありません。実験では不正検知性能と説明性の観点から、定量的かつ定性的に提案手法の有効性が検証されました。提案モデルは中国工商銀行の不正検知サービスに実装されているそうです。
Dólares or Dollars? Unraveling the Bilingual Prowess of Financial LLMs Between Spanish and English (ADS Track - Fintech Session)
本論文では、スペイン語と英語に対応した金融向けLLMを初めて開発したと報告されました。具体的には、ファインチューニング用データセットと評価用ベンチマークデータセットが整備され、オープンソースLLM (LLaMA2 7B) のファインチューニングが行われました。開発されたモデルは、英語データセットに対してはSOTAを達成していないものの、一部のスペイン語データセットに対してはSOTA (GPT-4を含む他LLMを上回る性能) を達成しました。
金融関連以外
From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models (Research Track - LLMs Session)
本論文では表データに関する分類と回帰をするLLMが開発されました。提案手法ではテキストに変換した大量の表データを使い、LLMを継続事前学習させます。学習後は別の表データを用い、ゼロまたは数十以下のショット (例示する特徴量・目的変数の組) を与えた後に予測と評価をします。実験結果において提案モデルをLLM以外のモデルと比較すると、ショット数が少ない場合には提案モデルの方が高い性能となりました。また、GPT-4を含むLLMに比較対象を限定すると、提案モデルが最高性能または2位の性能となりました。
ProCom: A Few-shot Targeted Community Detection Algorithm (Research Track - Clustering & Community Detection Session)
本論文では、取引ネットワーク上で不正を働く集団などのような、特定の性質を満たす集団をGNNで検知する手法が提案されました。提案手法ではグラフ内の潜在的な集団を理解するためのGNNを事前学習したあと、「プロンプト」として指定した少数の正解集団に類似する集団を予測します。実験では、提案手法が先行手法よりも高い検知性能を発揮しました。また提案モデルは、事前学習とプロンプトのデータセットを変えた場合も、変えない場合と同程度以上の検知性能を発揮し、異なるデータセットへの転移が可能であることが示されました。
Killing Two Birds with One Stone: Cross-modal Reinforced Prompting for Graph and Language Tasks (Research Track - Graphs+LLMs & RAG Session)
本論文は、クロスモーダルな強化学習で生成したプロンプトを用い、LLMとGNNの間で知識を転移する手法を提案しました。提案手法では、LLM用プロンプトを生成するエージェントとGNN用プロンプトを生成するエージェントが協力するように強化学習を行います。LLM用プロンプトはLLMのファインチューニングに、GNN用プロンプトはGNNの訓練に利用されます。実験は3種類のグラフタスク・言語タスクの組 (ノード分類・出版物分類、リンク予測・質問回答、グラフ分類・映画分類) について行われ、LLMやGNNに対して提案手法を組み合わせることで概ね予測性能が上がることが示されました。
以下は本記事の目次なので、詳細な内容をご覧になりたい論文については、論文紹介 (詳細) 以下の論文タイトルをクリックするとその論文の詳細な紹介に飛ぶことができます。
おわりに (一旦)
本記事ではKDD 2024の参加報告として、金融分野や流行の技術領域の研究発表をいくつか紹介しました。
現地で学会に参加することで、分野の流行を感じ取ったり、他の参加者の方々と直接コミュニケーションをとったりすることができ、有意義な出張となりました。またKDDでは、金融事業者を含むさまざまな企業の実サービスへ使われている技術に関する発表も多くなされるため、企業でデータサイエンス・機械学習を扱う者として良い刺激を受けました。
記事の後半では上記で紹介した論文の詳細を説明していますので、ぜひそちらもご覧ください。記事をお読みいただきありがとうございました。
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちら
Japan Digital Design株式会社
M-AIS
Kabuki Takada (高田珠武己)
論文紹介 (詳細)
Cost-Efficient Fraud Risk Optimization with Submodularity in Insurance Claim (Research Track - Finance Session)
本論文では、コストを抑えつつ効率的に保険金請求の不正を調査する手法が提案されました。不正な保険金請求は保険業者にとって余計な出費となるだけでなく、善良な顧客にとっても保険料増加や保険金請求時の調査回数増加といった負担を強いられる可能性があります。したがって不正を検知する必要がありますが、不正の調査は保険業者にとってコストとなります。本論文で主に想定している医療保険では、不正調査のために事実確認すべき病院を効率的に選ぶことが重要となります (下図を参照)。

本論文の手法は不正検知モデルというよりも、保険金の請求に対して事実確認すべき病院を、調査コストの制限下で最適に選ぶ手法となっています。この手法を論文著者らはCEROS (Cost-Efficient fraud Risk Optimization with Submodularity) と呼んでいます。CEROSは下図のように、請求情報と病院の特徴量から不正が確認される確率を推定する深層学習モデル (SSCM)、コストの制限下で不正が確認される確率を最大化するアルゴリズム (PDA-SP) の2つから成ります。1つの請求に対して複数の病院を選択してもよく、病院間の相関を考慮したモデルになっていることが特徴です。CEROSはAlipayで実装されているそうです。

SSCM (Submodular Set-wise Classification Model) は、入力した請求情報と複数の病院の特徴量に対して不正確率を出力するモデルとなっています。SSCMは請求と各病院の特徴量を別個にベクトル化するEmbedding Layer、請求と1つ1つの病院のベクトルを1つのベクトルに変換するPoint-wise Encoding Layer、複数の請求・病院ペアのベクトルを1つにまとめるSet-wise Aggregation Layer、不正確率を推定するFraud Probability Estimation Layerにより構成されます。また、SSCMは劣モジュラ性 (Submodularity) という数学的性質を満たすように構築されているため、後続の不正確率最大化アルゴリズムが高速に動くようになります。
SSCMで推定した不正確率を (ある期間内の) すべての請求について足したものが最大となるように、各請求に対する病院集合 (病院数は固定ではありません) を選びます。ただし、病院調査のコストに制約があるという状況を考えます。このような制約条件下の最適化問題は、補助変数を導入することで制約条件なしの最適化問題に置き換えることができ、双対最適化問題と呼ばれます。この双対最適化問題を解くアルゴリズムとして本論文はPDA-SP (Primal-Dual Algorithm with Segmentation Point) を提案しています。PDA-SPは病院集合に関する最大化においてSSCMの劣モジュラ性を利用するとともに、補助変数に関する最小化において区分線形性を利用することで、アルゴリズムが高速に収束するようにしています。このアルゴリズムでは勾配を利用せず、傾きの変化点まで補助変数を更新します。
実験ではAlipayにおける医療保険の保険金請求情報をもとにしたHosInvestigationデータセットを用い、SSCMとPDA-SPそれぞれの有効性が示されています。下図のように、請求と病院集合に対して不正が確認されるか否かを分類する問題について、SSCMのAUC (Area Under the ROC Curve) が他手法を上回っています。Treeは病院集合ではなく単一の病院と請求に対する不正有無データを使って訓練されたGBDT (勾配ブースティング決定木) モデルです。DRSA-NetはSSCMと構造が似ていますが、活性化関数や重みの値の範囲などが異なります。SSCM_IndはSSCMと同じ構造ですが、単一の病院と請求のデータで訓練されたモデルです。この結果から、SSCMのように病院間の相関を考慮したモデルが有効であることがわかります。論文では保険申込に対する承認確率を表すデータセット (InsComAllocation) を使った実験、各請求に対して調査する病院数を固定した場合の実験も行われているので、結果は論文を参照してください。

次に、PDA-SPについてはHosInvestigationデータセットを用い、勾配を利用した双対最適化アルゴリズム (PDA-Adam, PDA-Adam-lrDecay, PDA-Adam-GRS) よりも速く収束することが示されています (下図を参照)。下図の (a)-(c) は3通りの制約条件に対応しています。(a) は不正確率合計を制約条件とした場合、(b) は不正確率合計とビジネス要件に基づく病院調査コスト合計を制約条件とした場合、(c) は不正確率合計と過去データに基づく病院調査コスト合計を制約条件とした場合です。下図の (d) はPDA-Adamに対するPDA-SPの高速化率を示しています。

論文では上記の実験に加え、AlipayにおけるオンラインA/BテストによるCEROSの優位性も示されており、CEROSは不正確率に関する制約条件を満たしつつ他手法よりも病院調査コストを抑えるという結果になりました。詳細は論文をご覧ください。
本論文は、コストを抑えつつ効率的に医療保険の保険金請求の不正を発見するために、照会先の病院を最適に選択する手法を提案しました。提案手法のCEROSはAlipayで実装されています。単に不正検知をする機械学習モデルはさまざまなものが提案されていると思いますが、あくまで不正の調査や最終的な判断は人間が行う必要があるという状況下で、その調査を効率的に行おうという問題設定が独創的と感じました。
SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning (ADS Track - Marketing Applications Session)
本論文では、説明性を持つ不正検知用GNNが提案されました。下図のように、不正と予測されたノードの特徴量のスコア、周辺のエッジのスコアが予測結果への寄与度を表しており、説明性を担保しています。提案モデル自体が説明性を持っているため、不正の予測後に別途説明用のモデルを学習する必要がありません。提案モデルはSEFraud (Self-Explainable Fraud Detection Method) と呼ばれ、中国工商銀行 (ICBC) の不正検知サービスに実装されているようです。
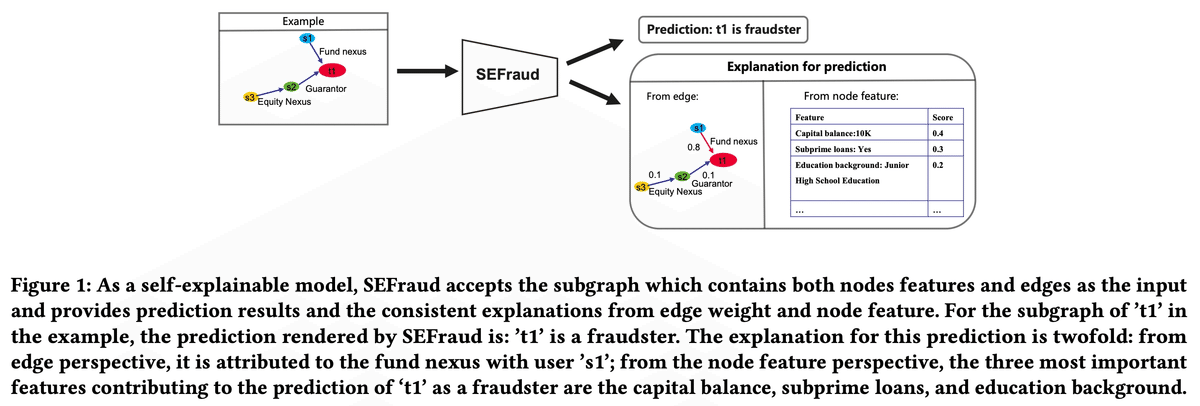
グラフ上の機械学習による不正検知はアンチマネーロンダリング、不正アカウント検知、スパムによるレビューの検知などに利用できる可能性があります。特に、GNNを使った不正検知についてはさまざまな手法が提案されてきましたが、透明性や解釈性に欠ける手法が大半を占めていました。一方、例えば金融領域における不正検知では予測結果の説明性が要求されます。また、先行研究の中にもGNNExplainerやPGExplainerのようにGNNの予測結果に説明性を付加する手法はありますが、GNNExplainerは不正の予測後にインスタンスごとの再訓練が必要で計算コストが高い、PGExplainerはエッジによる説明性を付与していてノードによる説明性は見過ごしているといった課題がありました。
これらの課題を解決するため、本論文ではモデルそのものがエッジとノードによる説明性を持つようにしました。下図にモデルの構造を示します。入力データは異種グラフ (複数種類のノードとエッジを持つグラフ) です。エッジの重みはありませんが、ノードは特徴量を持ちます。まず、ノードの特徴量をHeterogeneous Convolution Layer (Heterogeneous Graph Transformer) に通し、ノード埋め込み特徴量を作ります (実際にはHeterogeneous Graph Transformerを複数層積み重ねています)。そして、ノードの種類、埋め込み特徴量、元の特徴量をFeature Attention Network (FNet) に入力してノード特徴量マスクを作り、元の特徴量とかけ合わせたものをノード新特徴量とします。一方エッジについては、その種類と両端ノードの埋め込み特徴量をEdge Attention Network (ENet) に入力し、エッジマスクを作ります。このようにしてノードが新特徴量を持ち、エッジがエッジマスクの重みを持つような異種グラフを作り、GNNに入力します。その出力がノードのラベルの予測スコアとなります。学習後のモデルのノード特徴量マスクとエッジマスクは予測結果への寄与度を表します。

損失関数はノードのラベルを予測するためのクロスエントロピー損失とContrastive Triplet Lossからなります。Contrastive Triplet Lossはノード特徴量マスクとエッジマスクの学習のための損失、すなわち説明性のための損失です。具体的には、ノードの正解ラベルと予測スコアが近くなるようにする一方で、(おそらく) 仮にマスクの符号を逆にした場合 (負の重みを与えた場合) の予測スコアが正解ラベルと離れるように損失を構成しており、対照学習 (Contrastive Learning) の一種となっています (マスクの符号を逆にするという点について論文内に "if the weights are reversed, the results will also be drastically interfered", "if we assign negative weights to the masks, the model's prediction results should diverge significantly" という文があるものの、定義が明示的に与えられていないため「おそらく」と書きました)。このように学習することで、予測において重要なマスクの値が大きくなるようにしています。
実験は不正検知性能と説明性の観点から行われました。下表が不正検知性能の結果です。データセットはYelp (スパムとそうでないレビューのデータ)、Amazon (不正なユーザーとそうでないユーザーによるレビューのデータ)、ICBC (中国工商銀行の統計データをもとに生成された金融の不正検知用データ) の3個です。比較手法はすべてGNNであり、同種グラフ用 (GCN, GAT, GraphSAGE, GeniePath)、異種エッジを持つグラフ用 (RGCN, CARE-GNN)、異種ノード・エッジを持つグラフ用 (xFraud) の手法に分けられます。xFraudはGNNExplainerとグラフ上の中心性指標を利用して説明性を付加する手法となっています。

上表の通り、AUC (Area Under the ROC) とRecall (再現率) ともに提案モデルのSEFraudが最高性能となっています。また、アブレーションスタディとしてSEFraudからContrastive Triplet Loss、ノード特徴量マスク、エッジマスクのどれを除いても性能が下がることが示されており、すべての要素が必要だとわかります。
説明性についてはまず下図のような合成データ (BA-2motifs, BA-Shapes, Tree-Cycles, Tree-Grids) を用いて検証されました (なお、BA-CommunityとMUTAGは今回の紹介論文では使われていません)。データセットはベースとなるグラフ (BA-...はBarabasi-Albertグラフ、Tree-...はツリー型グラフ) の一部に「異常な」形のモチーフを付加するように作られており、いずれもノードの特徴量はありません。BA-2motifsはバイナリのグラフ分類用データセットであり、Label 0とLabel 1のいずれかのモチーフがベースグラフに付加されています。BA-2motifs以外はノード分類用データセットであり、下図においてノードの色がラベルを表します (BA-Shapesは4クラス分類、Tree-CyclesとTree-Gridsはバイナリ分類)。

上記のデータセット内のインスタンスについて、提案手法の中のマスク学習のしくみ (SE-Mask) とGNNExplainer, PGExplainerを比較すると、下図のようにSE-Maskが正しく説明性を付与している (モチーフに属するエッジが太くなっている、すなわちマスクが高い値となっている) ことがわかります。なお、提案手法と比較手法ともに予測モデルはいずれもグラフ畳み込みネットワーク (GCN) です。

このような説明性に関する性能を定量的に評価するため、本論文は各エッジがモチーフに属するかを当てる問題をエッジのバイナリ分類問題と捉えました。すなわち、モチーフに属するエッジはラベル1、その他のエッジはラベル0とし、エッジマスク (各エッジの予測結果への寄与度) を予測スコアと見なしました。その上で計算されたAUCが (エッジによる) 説明性の評価指標です。説明性の評価結果は下表のようになり、Tree-Cyclesを除いてSE-Maskが最高性能となりました。

説明性を1つのインスタンスへ付与するのにかかる時間については、下表のようにSE-Maskが最も速いという結果になりました。これは予測モデルのGNNの訓練時にエッジマスクが自ずと計算されるからと言えるでしょう。

加えて、説明性の定性的な検証として、ICBCデータセットの中でSEFraudが不正と予測したノードを100個抽出し、中国工商銀行の専門家による確認が行われました。その結果、SEFraudによるノード特徴量とエッジを使った説明は専門家の見識と一致するものだったそうです。下図は説明性の例です。t1, t2がターゲットノード、緑色のノードが不正と判断されたノードを表します。

さらに、中国工商銀行の実データにSEFraudを適用した結果、不正ノード予測のAUCは97%、Recallは98%となり、予測された不正ノードに対する説明性についても専門家からの評判が良かったようです。
本論文は、学習後にノード特徴量マスクとエッジマスクが自ずと説明性の役割を果たすような不正検知用GNNを提案しました。提案手法のSEFraudは中国工商銀行の不正検知サービスに実装されています。不正検知においては説明性を必要とされる場面が多いと思われるため、不正検知自体の正確さだけでなく説明性においても高い性能を持つモデルが提案されたことは重要だと思います。ただし、エッジによる説明性は定量的に検証された一方で、ノード特徴量による説明性に関しては定量的に検証されていない点は課題と言えるでしょう。説明性を定量的に評価するためのデータセットや枠組を作ることに難しさがあるのかもしれません。
Dólares or Dollars? Unraveling the Bilingual Prowess of Financial LLMs Between Spanish and English (ADS Track - Fintech Session)
本論文では、スペイン語と英語の2言語に対応した金融向けLLMを初めて開発したことが報告されました。スペイン語は世界で4番目に多く話される言語ですが、スペイン語LLMの開発は限定的となっています。主に英語や中国語へ対応した金融向けLLMは存在しますが、スペイン語を中心に訓練された金融向けLLMは本論文より前に存在しませんでした。また、金融に限らずオープンソースLLMの開発状況という意味でも、英語や中国語のLLMが複数ある一方で、スペイン語LLMはLince-zeroのみとなっていました。
スペイン語と英語に対応した金融向けLLMを開発するため、本論文ではファインチューニング用データセットと評価用ベンチマークデータセットが整備され、オープンソースLLM (LLaMA2 7B) のファインチューニングが行われました。
ファインチューニング用データセットはFIT-ESと呼ばれ、下表のように7種類の金融関連タスクに対する計15個のデータセット (スペイン語または英語) からなります。

これをLLMのInstruction Tuning用データセット (タスク説明、入力テキスト、期待する出力テキストの形式) に変換します。タスク説明は下表の例に示すような、1つのデータセットの中で共通のプロンプトです。

そして、LLaMA2 7BをInstruction Tuningによってファインチューニングします。完成したモデルはFinMA-ES-Bilingualと呼ばれています。なお、スペイン語データセットのみでファインチューニングされたモデルFinMa-ES-Spanishも構築されました。
本論文で整備された評価用ベンチマークデータセットはFLARE-ESと呼ばれ、下表のように9種類の金融関連タスクに対する計21個のデータセットからなります。そのうち線で区切られた上部の15行はファインチューニング用データセットと同種ですが、下部の6行は未知のデータセットです。さらに、一番下の3行のタスクcredit scoring (信用スコアリング)、hawkish-dovish classification (タカハト分類) は、それ自体が未知のものです。なお、Evaluation列においてEM AccuracyはExact Match Accuracy、MCCはMatthews Correlation Coefficientの略です。

FinMA-ES-Bilingual, FinMa-ES-Spanishと比較モデルのFLARE-ESに対する性能は下表の通りです。2重線で区切られた一番上がスペイン語データセット、真中がファインチューニング用データセットと共通する英語データセット、一番下がファインチューニング用データセットに含まれない英語データセットです。

FinMA-ES-Bilingualのパラメータ数はおそらくGPT-4よりも圧倒的に少ないですが、スペイン語データセット6個のうち4個についてFinMA-ES-Bilingualの性能がGPT-4を上回っており、そのうち3個はSOTAを達成しています。また、スペイン語データセットの中では1個を除いてFinMA-ES-Bilingualの性能はFinMa-ES-Spanishとほぼ同等かそれ以上となっており、多言語データセットによる学習の重要性が示唆されます。一方、英語データセットについてはいずれもFinMA-ES-BilingualがSOTAを達成していません。
本論文はスペイン語と英語に対応した金融向けLLM (FinMA-ES-Bilingual) を初めて開発し、その過程でファインチューニング用データセットFIT-ESと評価用データセットFLARE-ESを整備しました。FinMA-ES-Bilingualは一部のスペイン語データセットに対してSOTAを達成しました。ただし、スペイン語データセットについてはすべてファインチューニング用と評価用で共通しているため、ファインチューニング用に含まれないスペイン語のデータセットやタスクでモデルを評価することは今後の課題と言えるでしょう。また、2言語対応LLMの構築という観点では、英語データセットについていずれもFinMA-ES-BilingualがSOTAを達成していない点は課題が残る結果と言えるかもしれません。
From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models (Research Track - LLMs Session)
本論文では、表データに関する予測 (分類、回帰) をするLLMが開発されました。表データは弊社が属する金融業界を含むさまざまな業界で基本的なデータ形式であり、勾配ブースティング決定木や深層学習などによる予測モデルが提案されてきました。しかし、このような予測モデルの多くは個別のタスクに特化して学習させられたモデルであり、さまざまなドメインへの適用を考慮すると、知識の転移や限られたデータへの汎化が可能な普遍的なモデルの構築が必要となります。この課題を解決するため、本論文ではLLMを大量の表データで学習し、別の表データに対してzero-shotまたはfew-shotで予測を行いました。
提案手法はGenerative Tabular Learning (GTL) と呼ばれています。下図にGTLの概略を示します。GTLでは大量の表データを使ってLLMを継続事前学習させます。
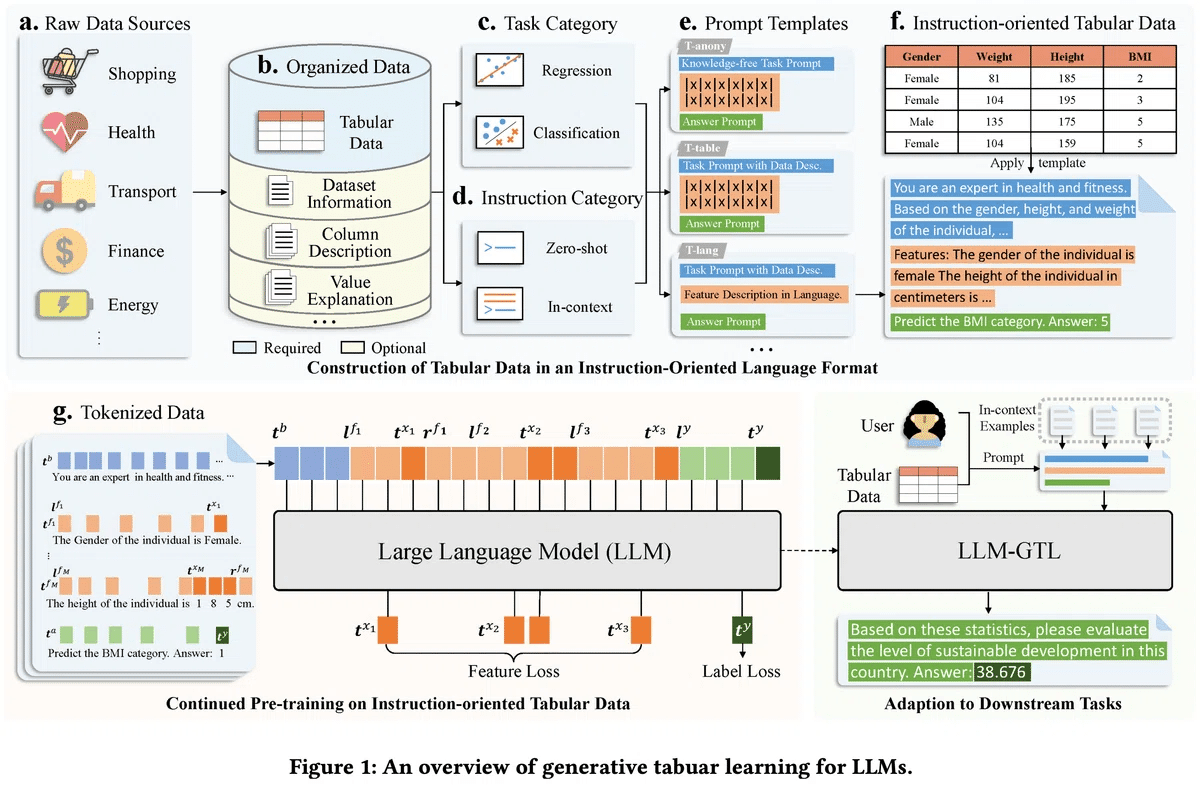
GTLでは、まず何らかのテンプレートを使って表データをテキストに変換します。本論文ではT-lang, T-table, T-anonyという3種類のテンプレートが提案されました。大雑把に説明すると、T-langでは特徴量と目的変数を
性別は女性です。体重は81 kgです。身長は185 cmです。BMI: 2
性別は男性です。体重は135 kgです。身長は175 cmです。BMI: 5のような文章に変換し、T-tableでは
|性別|体重|身長|BMI|
|女性|81|185|2|
|男性|135|175|5|のようなテキスト形式の擬似的な表に変換します。T-anonyはT-tableからカラム名などのメタ情報を取り除いたものです。
表データをテキストに変換したあと、テキストをトークン化し、LLMに継続事前学習させます。zero-shot学習の場合、1サンプルのテキストはメタ情報 (タスクの説明、各カラムの説明など) と特徴量・目的変数の値から成ります。few-shot学習の場合、1サンプルはzero-shot学習のテキストに加え、少数の例となるサンプルの特徴量・目的変数の値から成ります。GTLの継続事前学習では、特徴量と目的変数の同時分布を自己回帰モデル (t番目のトークンの確率分布がt-1番目までのトークンの条件付き分布として与えられるモデル) として表現し、特徴量と目的変数に関する損失関数を最小化します。なお、メタ情報に関する損失はマスク化します。
学習後の予測時には、表データをいずれかのテンプレートでテキストに変換したものをプロンプトとし (目的変数の値の部分はマスク化します)、LLMに目的変数の値を予測させます。few-shotの予測の場合は、少数の例となるサンプルの特徴量・目的変数の値もLLMに入力します。下記の実験では、メタ情報がないデータセットの場合T-anony、メタ情報があるデータセットのうち分類問題をzero-shotで予測する場合T-lang、その他の場合 (メタ情報があるデータセットのうち、分類問題をfew-shotで予測する場合または回帰問題の場合) T-tableが使われました。T-langは最も自然言語に近いテンプレートである一方でトークン消費が激しいため、意味的情報が重要なzero-shot分類のみT-langを使ったようです。
実験はKaggleの384データセット (176は分類、208は回帰) で行われ、340データセットが継続事前学習用として、44データセットが評価用として使われました。
継続事前学習では、各データセットに対して4通りの目的変数が選ばれ、例示するサンプル数は0, 4, 8, 16, 32, 64のいずれか (0はzero-shot学習、それ以外はfew-shot学習)、テキスト化のテンプレートは上述の3通りのいずれかとされました。そして、データセット、目的変数、例示サンプル数、テンプレートの各組合せに対して64サンプルを選んだ後、トークン数が4,096以下のテキストを抽出して得られる640kサンプルが継続事前学習用データセットとされました。継続事前学習を適用したLLMはLLaMA-2-7B/13Bです。
評価用データセットも継続事前学習と同様の方法で構築され、88kサンプルが作られました。評価指標は分類ならAUROC (Area Under the ROC curve)、回帰ならNMAE (Normalized Mean Absolute Error) です。
下表が分類、回帰の評価結果です。"-GTL" と付いたモデルが提案手法 (GTLを適用したLLM) であり、決定木系モデル (LightGBM, XGBoost, CatBoost)、ロジスティック回帰 (LR)、ニューラルネットワーク系モデル (FTTransformer, XTab, TabPFN (分類のみサポート))、GTLを適用していないLLM (LLaMA-7B/13B, GPT-3.5-turbo/4) と比較しています。LLMとTabPFN以外のモデルについては、ショット数のデータで訓練した後に予測をしています。TabPFNはLLMと同様、事前学習の後に勾配に基づくパラメータ更新が不要なモデルとなっています。


LLM以外のモデルと比較すると、ショット数が少ない場合 (分類ではショット数4-16、回帰ではショット数4-32) はLLaMA-13B-GTLの方が高い性能となっています。ショット数が多くなるとLLM以外のモデルの性能を下回るようです。
次に比較対象をLLMに限定します。分類問題では、LLaMA-13B-GTLがzero-shotを除き最高性能となっており、zero-shotの場合もGPT-4に迫る2位の性能となっています。回帰問題ではzero-shotで最高性能であり、zero-shot以外でもGPT-4に近い2位の性能です。GPT-4はおそらくLLaMA-13B-GTLよりも圧倒的に多いパラメータ数を持っていること、評価用データセット (Kaggleの公開データセット) はGPT-4の学習に使われているかもしれないことを考慮すると、LLaMA-13B-GTLがGPT-4に匹敵するかそれ以上の性能を発揮しているという結果はGTLの有効性を示していると言えるでしょう。
本論文は、表データに関する分類と回帰をするLLMの学習方法を提案し、評価結果を非LLMや他のLLMと比較しました。一般的に表データに関する予測を勾配ブースティング決定木などで行う機会は多いですが、本論文は表データという自然言語とは異なる領域のデータにLLMを適用するという点で時代を感じる研究だと思いました。
ProCom: A Few-shot Targeted Community Detection Algorithm (Research Track - Clustering & Community Detection Session)
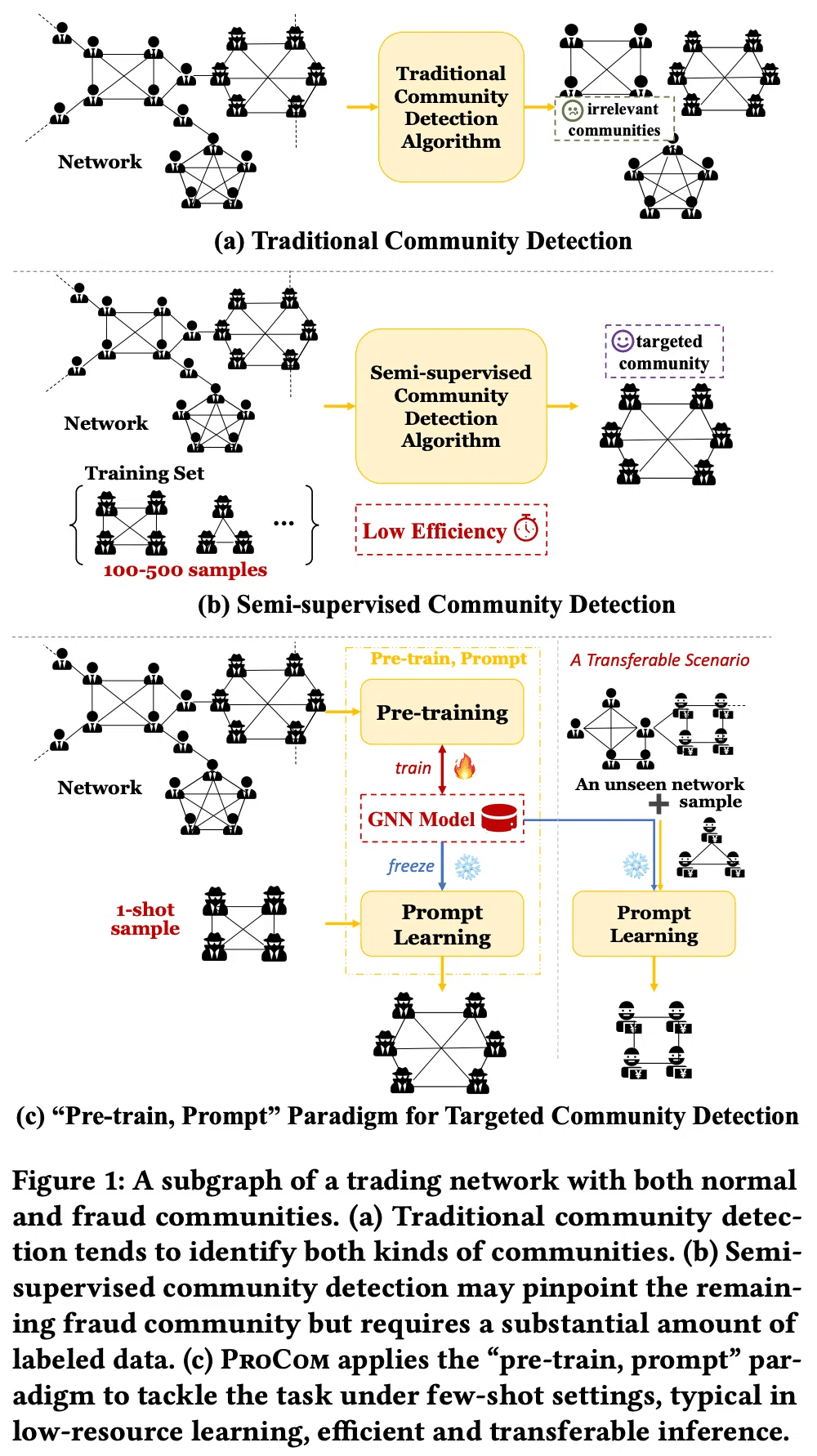
本論文は、取引ネットワーク上で不正を働く集団やソーシャルネットワーク上でスパムを送る集団などのような、特定の性質を満たす集団をGNNで検知する手法を提案しました。
伝統的な集団検知手法は所望の性質を満たさない集団 (例えば不正を働いていない集団) も検知してしまうという問題を抱えています。半教師あり集団検知手法は所望の性質を満たす集団のみを抽出できる手法として先行研究で提案されましたが、大量のラベル付きデータが必要である、異なるデータセットへの適応性が低いといった課題があります。
提案手法のProCom ("pre-train, PROmpt" paradigm for targeted COMmunity Detectionの意味) はこれらの課題を解決するため、グラフ内の潜在的な集団を理解するためのGNNを事前学習したあと、「プロンプト」として指定した少数の正解集団 (特定の性質を満たす集団) に類似する集団を (GNNは固定したままに) 予測する手法となっています。下図に先行手法と提案手法の比較を示します。
ProComの概略は下図の通りであり、GNNの事前学習部分 (Dual-level Context-aware Pre-trainingと論文著者らは呼んでいます)、プロンプトの学習・プロンプトをもとにした予測の部分 (Prompt Learning) から成ります。

Dual-level Context-aware Pre-trainingでは、Node-to-Context ProximityとContext Distinctionという2つ (dual) の損失を使ってGNNの学習を行います。ここでのコンテキスト (Context) はノードを取り囲む環境を指しており、具体的には各ノードのkホップ以内のノードからなる部分グラフのことです。GNN自体は各ノードの表現ベクトルを出力するモデルですが、本手法ではコンテキスト内のノードを足し上げることでコンテキストの表現ベクトルを算出します。
Node-to-Context Proximityはノードとコンテキストの関係性を学習するための損失であり、各ノードとそのコンテキストの表現が近くなるようにする一方で、各ノードと自分以外のランダムなノードのコンテキストの表現は遠くなるようにします (一種の対照学習です)。Context Distinctionはコンテキストどうしの関係性を学習するための損失であり、コンテキストからランダムにノードまたはエッジを除いたとしてもコンテキストの表現があまり変わらないようにする一方で、別のランダムなコンテキスト (からランダムにノードまたはエッジを除いたもの) の表現は遠くなるようにします。
Prompt Learningは各ノード周辺の集団候補を生成するためのプロンプトの学習、プロンプトと類似する最終的な予測の2段階から成ります。各ノード周辺の集団候補はそのノードのコンテキストから類似度が閾値以上のノードだけ抽出したものです。ただし、ここでの類似度は多層パーセプトロンで推定しており、プロンプト (集団の例) に属するか否かを正解ラベルとして学習しています。プロンプトの学習後はすべてのノード周辺で集団候補を生成し、各プロンプト集団と比べて表現が近い順に選んだ集団候補を最終的な予測集団とします (検知したい集団数がN、プロンプト集団数がmなら、1つのプロンプト集団に対してN/m個の集団候補を選びます)。なお、プロンプト集団や集団候補の表現は、集団に属するノードの表現を足し上げたものです。
実験では、集団に属するノードにラベルが付いたグラフデータセットを複数用い、ProComが先行手法 (伝統的な教師なし集団検知手法、半教師あり集団検知手法) よりも高い検知性能 (Bi-matching F1 ScoreとBi-matching Jaccard Score) を発揮することが示されました (下表を参照)。なお、半教師あり集団検知手法とProComのみ10集団を訓練データまたはプロンプトとして使いました。

また、事前学習とプロンプトのデータセットを変えた場合も、下表のようにProComはデータセットが同じ場合と同程度かそれを超える検知性能を発揮し、異なるデータセットへの転移が可能であることが示されました。

本論文は特定の性質を満たす集団をプロンプト (少数の集団例) として指定し、GNNで類似の集団を検知する手法を提案しました。一般的に、不正を働く集団など特定の性質を満たす集団の正解データが潤沢にあるとは限らないため、本論文の手法において集団のアノーテーション負荷が少ないという点は重要だと思いました。
Killing Two Birds with One Stone: Cross-modal Reinforced Prompting for Graph and Language Tasks (Research Track - Graphs+LLMs & RAG Session)
本論文は、クロスモーダルな強化学習で生成したプロンプトを利用し、LLMとGNNの間で知識を転移する手法を提案しました。
LLMとGNNを合体させることは双方の面からメリットがあると考えられています。LLMはGNNの訓練に必要なアノーテーションの負荷を軽減するかもしれません。一方で、GNNはLLMに対し、テキスト属性を持つ構造の有益なパターンを与えるかもしれません。しかし、言語とグラフのようにマルチモーダルなタスクに対する一般的な学習の枠組を作るには2つの課題が存在していました。第1に、下流タスクの言語コーパスはグラフデータと異なるため、言語とグラフという2つのモーダルの間で知識のギャップを埋めることは困難です。第2に、すべての知識が下流タスクにとって有益とは限らず、LLMのようにコンテキストに敏感なモデルにとってはノイズにもなり得ます (言い換えると「ネガティブな知識の転移」が起こり得ます)。
これらの課題を解決するため、本論文はLLMの学習のためのエージェントとGNNの学習のためのエージェントが協力するように強化学習を行い、ネガティブな知識の転移を防ぐような対照学習の報酬 (Contrastive Reward) を導入しました。下図が提案手法のCross-Modal Reinforced Prompting (CMRP) の概略です。ラベルが付いた言語データセットとグラフデータセットを用い、知識を転移させながら事前学習済LLMをファインチューニング、GNNを訓練するのが目標です。

言語データとグラフデータを統一的に扱うため、言語データの質問はChain-of-Thoughtなどを使って中間的な質問に分割し (例えば "Please briefly introduce the biography of Marie Curie" という質問を "Birth", "Research", "Family" などの観点で分割)、分割された質問をグラフのノードにマッピングします。そして、LLM用エージェント (L-agent) がLLM用プロンプトを、GNN用エージェント (G-agent) がGNN用プロンプトを生成します。ここでのプロンプトはグラフ形式となっており、各エージェントが適切にプロンプトに属するエッジを選択します (LSTMなどを利用してモデル化しています)。
GNN用プロンプトは元のグラフデータと統合された上で、GNNの訓練に利用されます。一方でLLM用プロンプトについては、周辺の部分グラフを言語プロンプトに変換することで、LLMのファインチューニング (Instruction Tuning) に利用されます。また、LLM用エージェントとGNN用エージェントは協力的に強化学習されます。各エージェントの報酬は、Performance Reward (PR), Reasoning Reward (RR), Semantic Reward (SR) から成るタスク報酬 (言語タスクまたはグラフタスクに関する、予測およびプロンプト生成に対する報酬) を使って定式化されたContrastive Reward (CR) となっています。
実験は3種類のグラフタスク・言語タスクの組 (ノード分類・出版物分類、リンク予測・質問回答、グラフ分類・映画分類) について行われました。結果は下表の通りです。GNNやLLMに対して提案手法のCMRPを組み合わせることで概ね予測性能が上がっていることがわかります。グラフ分類については複数の先行するプロンプト手法とも比較されています。より詳細な実験内容については論文を参照してください。



本論文は、LLM用とGNN用のエージェントを強化学習し、それぞれが生成したプロンプトをLLMとGNNの学習に利用することで知識を転移する手法を提案しました。LLMとGNN双方の利点を生かす手法の考案は研究テーマとして有意義だと思う一方で、実際に言語データとグラフデータの間で知識の転移を有効に働かせるには、データセットの用意などのハードルがありそうだと感じました。