
言語間転移を用いた日本語LLM構築に関する論文・筆者発表論文ーNLP参加報告④

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)にて、MUFG AI Studio(以下M-AIS)に所属する、井本です。
弊社では、3月11日から15日にかけて神戸で開催された、NLP2024 (言語処理学会第三十回年次大会)に参加し、個々人が参加記録を発表してきました。
また会社としては、NLP研究の発展に貢献したいという思いで、2022年の年次大会から毎年スポンサーを務めています。今年はプラチナスポンサーとして、益々規模拡大するNLP学会を、ささやかながら支えるお手伝いができたのかなと考えています。
本記事では、私が興味深く感じた発表と、私自身の研究発表内容についてご紹介します。記事を読んで、学会や研究内容への興味、また弊社への興味を持っていただけたら幸いです。
1.事前学習済み Llama2 モデルを活用した言語間転移日英モデルの作成

中小型の日本語特化LLMをいかに効率よく学習できるか?に興味があり、株式会社リコーによる大規模言語モデル(LLM)の言語間転移学習についての論文を取り上げました。
日本語LLMを作りたいけども、一から作るのには莫大なお金がかかります。また、英語等の言語に比べ、学習に使える言語資源(コーパス)が十分でない事も知られています。
そこで、日本語LLM構築の現在の主流は、利用可能な高精度の英語LLMを出発点にして、日本語コーパスを追加で学習(継続事前学習)させて、日本語対応させるものです。
ここで課題となるのが、限られた言語資源と計算コストの下で、どうやったら良い日本語モデルを作ることができるか?です。
本研究では、継続事前学習の設定について、カリキュラム学習に着目し、様々な組み合わせで実験し効果を測定しました。定番の中小型英語モデルであるLlama2-13B Chatを利用しています。
カリキュラム学習とは「学習中に意図的にデータの質や特徴を調整する学習手法」です。LLMに限ったものではなく、良く知られているのが、簡単な問題から始め徐々に難しい問題を学習させるものです。
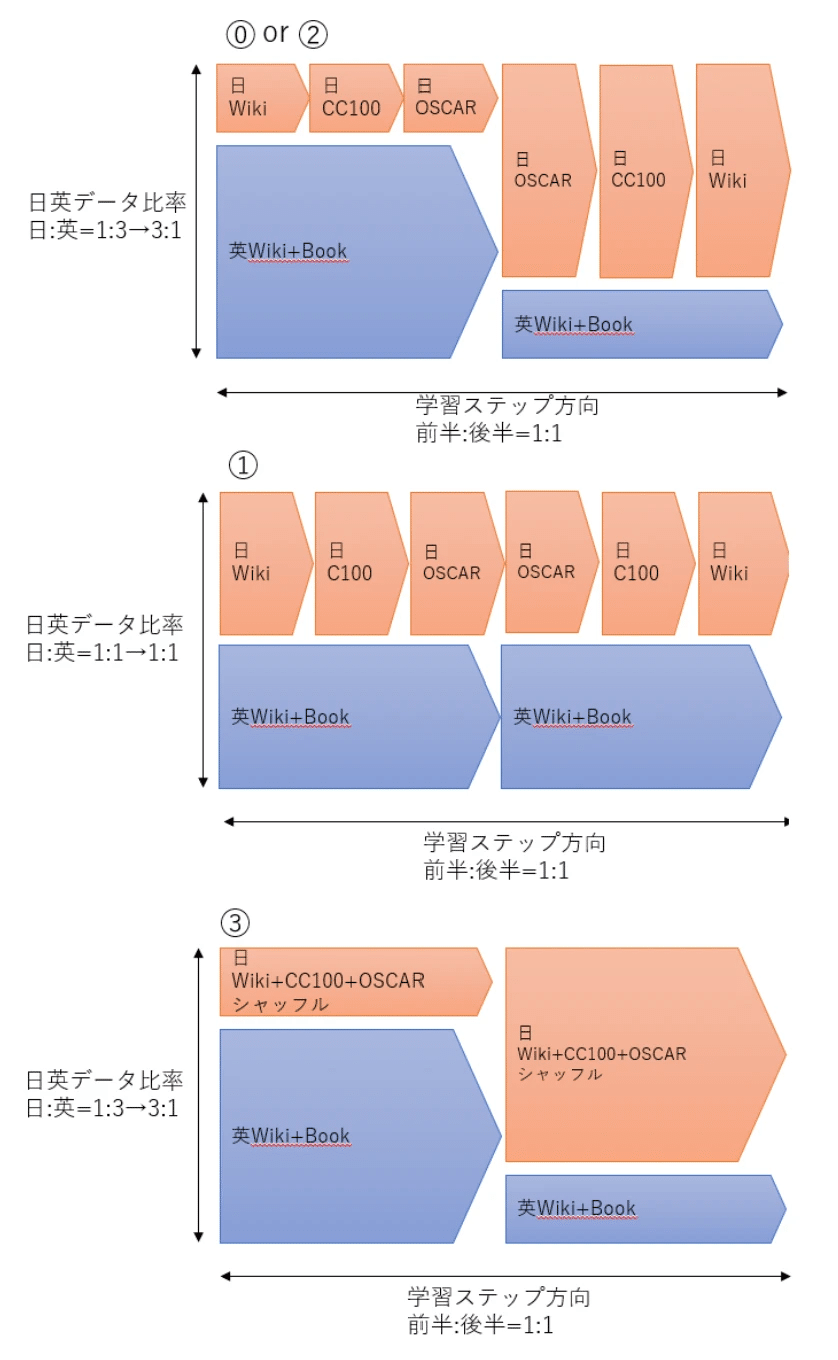
論文著者は、以下の「提案手法」の設定でカリキュラム学習すれば精度が良くなるのではないか?と考え学習を実施しました。
英語・日本語の割合調整:徐々に日本語データ多めで学習
英語モデルに徐々に日本語に慣れさせる目的
品質の調整:高品質データ(日本語データの品質が高い順に、wiki→CC100→OSCARとなる)を最初と最後に集中
CLの先行研究で高品質から始めた方が良いという報告
LLMの精度は最後周辺の学習結果に引きずられやすい
さらにAblation Studyも行い、各々の効果を観察しました。大量データの学習・分析は中々簡単にはできず、貴重な実験結果だと思います。
実験設定⓪:提案手法
実験設定①:言語間の特性を無視
実験設定②:継続学習をしない
実験設定③:カリキュラム学習を無視
下表は、各モデルの、日本語能力(日平均スコア)と英語能力(英推論スコア)を算出したものです(各スコアに用いたベンチマークなど、詳しくは原論文をご参照ください)。継続事前学習前の英語モデル(Llama2 13B Chat)と、実験⓪~③を比較対象としています。結果を見ると、どの日本語モデルも、英語モデルに比べ英語能力は落ちますが、提案手法(実験⓪)は、英語能力の劣化を抑えながら、日本語能力が一番良い事が分かります。

次に、実験設定⓪での、学習中の日本語能力の推移をまとめたものをお見せします。横軸が学習の進度を表し、縦軸が各学習時点での日本語能力を表します。青色、赤色、緑色、ピンク色が、実験設定⓪、①、②、③に対応します。
提案手法(実験設定⓪)をご覧ください。
学習当初・最後は高精度:高品質の日本語Wikiデータを学習に用いています
学習中盤:品質の低い日本語C100・OSCARを用いています
高品質の日本語Wikiデータを学習する最初と最後近辺で、精度が上昇していることが分かります。また、乱高下が大きいものの、品質が低いとこで評価指標も下がることが多いです。データの質が大事とは言われますが、具体的な数値で見れることは非常に面白く、その重要性を再認識しました。

青色(設定⓪)の上下の動き方は概ね同じで、ここではそこだけに注目ください。
2.大規模言語モデルを用いたニュース類似度の算出
次に筆者の研究発表内容を紹介します。弊社では、MUFG向けに金融市場分析を行っており、その中でニュース記事も扱っています。ニュース類似度分析は、異なる2つのニュース記事について複数基準で類似度を測り総合評価値を与えるタスクで、クラスタリング分析やニュース推薦など様々な用途に応用可能です。
ここで課題となるのは、アノテーションコストの高さです。ニュースは様々な要素があり、それぞれを評価する必要がある事、そのためアノテーターを訓練するのにもコストがかかる事が挙げられます。
本研究では、LLMを使って少数サンプルを用いるだけで、SOTAモデルと同水準の類似度を算出するモデルを提案し、精度を落とさずアノテーションコストの削減ができる事を示しました。今回は、GPT-3.5 Turboおよび、GPT-4モデルを利用しました。


ニュース類似度データセットとしては、SemEval2022 Shared Task8を利用しました。類似度の総合評価値(OVERALL)は、4種類の各類似度を評価したうえで判断されます。全ての評価値は、VS(非常に似ている)、SS (いくらか似ている)、SD (いくらか似ていない)、VD(非常に似ていない)の4段階で定量化されています。データセットは英語を中心とした10言語から構成されています(日本語はない)。

OVERALLスコアの算出を主タスクと捉えると、主タスクの点数は、GEO/ENT/NARなど「サブタスク」スコアの総合点と捉えられます。
LLMを用いれば、主タスクを直接解くこともできますが、サブタスクと主タスクを同時に解く事もできるのではないか?と考えました。そこで、前段でサブタスクのスコアを予測し、その結果を使って、OVERALLスコア予測を行う方法(サブタスク推論アプローチ)を提案しました。
論文ではまず、主タスク(OVERALLスコア予測)を、LLM (GPTモデル)のプロンプトエンジニアリングで解くことに注力し、様々な入力テキスト前処理手法や、プロンプトエンジニアリング手法の効果を検証しました。
入力テキスト前処理
Head-Tail:ニュース記事の冒頭と最後に重要な情報が含まれているという仮説
200語要約:長いので要約
Head-Tail(英語):英語以外のニュースを英語に翻訳。GPTモデルはマイナー言語に弱いという先行研究があるため
プロンプトエンジニアリング
3-shot、6-shot:ニュース記事とその正解類似度を例示として入力
CARP:根拠を中間生成することで予測精度を上げる手法
SC:自己整合性という、GPTに複数回答をさせ平均や中央値をとる手法
なお、SOTAモデル(HFL)はxlm-roberta-largeを用いたCross-Encoderベースの分類モデルで、SemEvalのラベル付きデータセットで教師あり学習したものです。

上記の結果から、Few-ShotやCARP、自己整合性がどれも精度改善に貢献していることが分かりました。しかし、SOTAには約5%精度が足りません(設定7と8を比較)。そこで、提案手法であるサブタスク推論アプローチを試しました。

設定9がさっきまでの最善設定(設定7)、設定10が提案手法の結果となります(数値が異なるのは3言語ペアに限定したため)。最適化したデータ前処理手法・プロンプトエンジニアリングに加え、サブタスク推論アプローチを組み合わせる事で、SOTAと同水準の精度を達成することができました。
まとめ
本稿では、NLP2024で筆者が興味をもった発表と筆者の発表内容を紹介しました。紙面の都合上掲載できませんが、LLMの実務レベルで気になる発表がたくさんあり、また、アカデミア・企業の方々と様々な議論ができて非常に有意義でした。学会を盛り上げるイベントもたくさんあり、運営関係者の皆様のご尽力には毎回感謝しております。
一緒に働きませんか
M-AISでは、AI技術を軸に、顧客&データ起点で金融体験をアップデートすることに挑戦してくださる仲間を募集しております。ご興味ございましたら、ぜひこちらの採用情報をご覧ください。