
実践!Databricks Feature Storeで始めるデータ管理とモデル運用

はじめまして、三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)に所属する、小林です。
普段はMUFGに向けたAI施策のPoCやモデルの本番実装等を担当しています。
弊社では分析基盤環境としてDatabricksを利用しており、PoC時のアドホックな分析での利用にとどまらず、AIモデルの実運用自体もDatabricks上で行っております。
本記事では、AIモデルを本番実装する上で便利な機能であるDatabricksのFeature Storeの使用方法および利用する際のユースケースについて紹介したいと思います。
DatabricksのFeature Storeとは
DatabricksのFeature Storeは、特徴量管理とモデル運用を効率化するための便利なサービスです。以下にその便利さを具体的に記載します。
便利な点
特徴量の中央管理: Feature Storeを利用することで、どのモデルがどの特徴量を利用しているかの追跡(リネージ)が容易になります。これにより、特徴量の再利用性が高まり、データの一貫性を保ちやすくなります。
データのリネージ: 特徴量の起源となるDelta Tableを追跡できるため、データの信頼性が向上します。これは、データの作成元を容易に特定できることを意味し、データの品質管理に貢献します。
データの簡易更新(Upsert): Feature Storeでは、新しいレコードの追加や既存レコードの更新が簡単にできます。これにより、常に最新のデータを特徴量として使用することができ、モデルの精度を高めることが可能です。
柔軟な予測フロー: 予測を行う際に特徴量を明示的に指定する必要がなく、自動的に学習時に利用した特徴量が選択されます。これにより、モデル実装の手間が軽減され、迅速な予測が可能になります。
モデル実装の品質向上: 上記の全ての機能が、モデル実装時の品質向上に寄与します。データの整合性と品質が保たれ、開発プロセスがスムーズになります。
実装方法
DatabricksのFeature Storeには大きく「Unity Catalog用のFeature Store」および「WorkSpace Feature Store」の2種類存在しますが、今回は「WorkSpace Feature Store」で実装いたします。
Unity Catalogについてはこちらをご参照ください。
事前準備
今回Feature Storeの実装を行うにあたり、以下を設定し実装を行います。
使用するデータセットは、scikit-learnで提供されているbreast cancerデータセットです。このデータセットは、乳がん患者から採取した細胞の特徴(例:半径や滑らかさ)を基に、がんが悪性か良性かを判断するための情報を含んでいます
Feature Storeを利用するには、データセットに主キーが必要です。そこで、擬似的にインデックスをキーとして使用します
実運用を考慮した場合、特徴量テーブルには時系列でレコードが蓄積されることが多いと予想されるため、基準日カラムもデータセットに追加します
Feature StoreのFeature Lookup機能を利用するために、上記のbreast cancerデータセット以外にも、擬似的にインデックスをキーとする特徴量テーブルを追加で用意します
使用するクラスターはバージョン13.3のLTS MLです
dataset = load_breast_cancer()
data = pd.DataFrame(dataset.data, columns=dataset.feature_names)
data['target'] = pd.DataFrame(dataset.target, columns=['class'])
# indexをキーに設定する
data = data.reset_index().rename(columns={'index':"id"})
# 基準日を示すカラムを追加する(月次データを想定して月末日を設定)
data['ref_date'] = datetime.date(2024,2,29)
# カラム名にスペースがある場合、それをアンダースコアに置換
# columnのrename(FeatureStoreのカラム名に” ”は利用できないため)
data.columns = data.columns.str.replace(' ', '_')
# spark DataFrame へ変換
dataDF = spark.createDataFrame(data)
# idカラムはdataと同一で1~10のランダムな値を持つカラムをもたせたDataFrame
# Feature Look UP 機能を試すためにref_dateは持たせない
rand_dataDF = dataDF.select('id').withColumn("uniform_rand",F.floor(F.rand(seed=1234)* 10)+1)特徴量テーブル作成
最初にFeature Storeテーブルの作成を行います。テーブルを作成する前に、データベースが必要になりますので、事前に作成しておきます。
# データベース名
database_name = "fs_test"
# データベースが存在するかどうかを確認
dbExists = spark.sql(f"SHOW DATABASES LIKE '{database_name}'").collect()
# データベースが存在しない場合、新しいデータベースを作成
if len(dbExists) == 0:
spark.sql(f"CREATE DATABASE {database_name}")
print(f"Database '{database_name}' created.")
else:
print(f"Database '{database_name}' already exists.")Feature Storeテーブルを作成する際に必要なのは、主キーの設定とスキーマの定義です。乳がんデータ用のDataFrame(以下dataDF)については、「id」と「ref_date」(インデックス、基準日)を主キーとして設定します。一方、ランダムな値を含むカラムのDataFrame(以下rand_dataDF)には、「id」を主キーとして設定します。
スキーマ定義に関しては、簡略化のためにSparkDataFrameのスキーマ定義をそのまま利用します。
fs = FeatureStoreClient()
# feature storeのTBL定義を作成
feature_table = fs.create_table(
name='fs_test.cancer_dataset',
primary_keys=['id','ref_date'],
schema=dataDF.schema,
description='sklearn cancer dataset'
)
feature_table_1 = fs.create_table(
name='fs_test.random_dataset_for_cancer',
primary_keys=['id'],
schema=rand_dataDF.schema,
description='random dataset for sklean cancer dataset'
)
# feature storeへデータを登録
fs.write_table(name='fs_test.cancer_dataset',
df = dataDF,
mode = 'overwrite')
fs.write_table(name='fs_test.random_dataset_for_cancer',
df = rand_dataDF,
mode = 'overwrite')特徴量テーブルの更新
先ほどのfs.write_tableでは、初期データの登録にmode='overwrite'を使用し、すべてのデータを上書き保存しました。しかし、特徴量テーブルを運用していく過程で、同じキーのレコードを更新したい場合や新規レコードを追加したい場面が想定されます。
そのような時に便利なオプションがmode='merge'です。このオプションを使用すると、同一キーのレコードがすでに存在する場合は更新(update)、存在しなければレコードを追加(insert)する、いわゆるupsert処理を行います。
mode='merge'はFeature Storeの便利な特徴の一つであり、特徴量テーブルの運用を簡易にすることが可能です。
id=1のレコードのmean_radiusカラムを更新しつつ、id=999のレコードを新規に追加する場合の例を以下に記載いたします。
# id = 1 のレコードを更新し、新規で id = 999のレコードを追加する
# 変更前のレコードを確認
tmpDF = spark.read.table('fs_test.cancer_dataset').where(F.col('id').isin([1,999]))
tmpDF.display()
# id = 1 のレコードに対してmean_radiusを999に設定
updateDF = tmpDF.where(F.col('id')==1).withColumn('mean_radius',F.lit(999))
# 新規でid=999のレコードを生成(id,ref_date,target以外はnullとする)
# 新しいレコードを含むDataFrameを作成
fields = {field.name: None for field in tmpDF.schema.fields}
# 必要なフィールドに値を設定
fields['id'] = 999
fields['ref_date'] = datetime.date(2024, 2, 29)
fields['target'] = 0
# 上記のfields辞書を使用してRowオブジェクトを作成
new_record = Row(**fields)
# 新しいDataFrameを作成
addDF = spark.createDataFrame([new_record], schema=tmpDF.schema)
# 更新用のDFを用意
upsertDF = updateDF.unionByName(addDF)
# recordの更新(mode = 'merge')
fs.write_table(name='fs_test.cancer_dataset',
df = upsertDF,
mode = 'merge')
# 変更後のレコードを確認
tmpDF = spark.read.table('fs_test.cancer_dataset').where(F.col('id').isin([1,999]))
tmpDF.display()更新前のTBL
id = 1のmean_radius=20.57
id = 999 は存在しない

更新後のTBL
id = 1のmean_radius=999
id = 999 が新規作成

学習編
特徴量の取得方法
続いて、Feature Storeを利用した学習プロセスにおいて、非常に便利なFeature Lookupについて説明します。
取得したいテーブル(table_name)、カラム(feature_names)、そして検索時のキー(lookup_key)を指定することで、対応するキーが登録されているSparkDataFrameを渡すだけで、簡単にデータを取得できる便利な機能です。
feature_lookupsを使用して取得したDataFrameは、学習用データのDataFrame(training_index_df)と外部結合する形でレコードを取得します。
以下の例では、fs_test.cancer_datasetテーブルからキー['key', 'ref_date']を使用してtraining_index_dfと外部結合し、データを取得する方法を示します。
features = [col for col in data.columns if col not in ['id','ref_date','target']]
feature_lookups = [
# fs_test.cancer_dataset のキーは['id','ref_date']
FeatureLookup(
table_name = 'fs_test.cancer_dataset',
feature_names = features,
lookup_key = ['id','ref_date']
),
# fs_test.random_dataset_for_cancerのキーは ['id']
FeatureLookup(
table_name = 'fs_test.random_dataset_for_cancer',
feature_names = 'uniform_rand',
lookup_key = ['id']
),
]
# 学習用データのキー+ラベルを取得する
training_index_df = spark.read.table('fs_test.cancer_dataset').select(['id','ref_date','target'])
training_set = fs.create_training_set(
# trainデータの「キー+ラベル」のsparkDataFrame
df=training_index_df,
# trainデータのDataFrameに対して外部結合で特徴量を取得する
feature_lookups = feature_lookups,
label = 'target',
# feature_lookupsで取得してきたカラムのうち、学習時に利用しないカラムを指定する
exclude_columns = ['id','ref_date']
)
training_df = training_set.load_df().toPandas()モデルレジストリへの保存
実際に上記で取得したtraining_df DataFrameを利用した学習コードを以下に示します。ここでは、LightGBMを用いて2値分類タスクを解き、その結果を保存するコードです。
特筆すべき点として、fs.log_modelを使用して学習済みのモデルをモデルレジストリに登録しています。登録する際には、前段階で生成したtraining_setを渡す必要があります。
with mlflow.start_run(experiment_id = 'experiment_id'):
log_model_name = 'fs_test_lgb'
mlflow.sklearn.autolog(log_input_examples=True, silent=True)
X = training_df.drop(['target'], axis=1)
y = training_df['target']
# データセットを8:2の割合で訓練データセットとテストデータセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# LightGBMのパラメータ
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0,
'random_seed': 42
}
# トレーニングセットとテストセットのためのLightGBMデータセットを作成
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
model = lgb.train(params, train_data, num_boost_round=1000, valid_sets=[train_data, test_data], verbose_eval=10, early_stopping_rounds=100)
# 特徴重要度の取得
feature_importances = model.feature_importance(importance_type='gain')
feature_names = X_train.columns
feature_importance_df = pd.DataFrame({'Feature Name': feature_names, 'Importance': feature_importances})
# 特徴重要度をログに記録
mlflow.log_param('feature_importances', feature_importance_df.to_dict('records'))
# モデルとデータをFeature Storeに登録
fs.log_model(
model,
log_model_name,
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=log_model_name
)また、fs.log_modelを利用してモデルを登録することにより、Feature Store上で特徴量ごとにどのモデルが使用しているかを追跡(リネージ)することが可能になります。
この機能は、複数のモデルを運用している場合に特に有効です。特徴量テーブル単位で、どのモデルがどの特徴量を利用しているかを一覧で確認できます。これにより、特徴量テーブルの保守性を向上させることができます。

予測編
score_batch機能を利用した予測出力
続いて、予測処理について説明します。FeatureStoreにはscore_batchという機能があります。この機能を利用することで、学習時に使用したテーブル(TBL)から特徴量を自動的に取得し、予測を行うことができます。
サンプルコードは以下の通りです。
# 予測用sparkDataFrameを用意(id,ref_date)
predict_index = pd.DataFrame(data=[(10)],columns=['id'])
predict_index = spark.createDataFrame(predict_index)
predict_index = predict_index.withColumn('ref_date',F.lit(datetime.date(2024,2,29)))
# DataFrameの確認
predict_index.display()
# model registoryの指定(今回はモデルverで指定)
model_uri = f'models:/{log_model_name}/11'
# 予測処理実施
predictions = fs.score_batch(
model_uri,
predict_index
)
# 結果確認
predictions.display()予測を行うにあたり、まずはキーとなるカラムを含むSparkDataFrameを準備します。今回の例では、キーとなるカラムは「id」と「ref_date」です。さらに、使用するモデルのURIも指定します。このURIは、モデルレジストリに登録されたモデルを指し、前述した学習時にfs.log_modelで保存したモデルです(今回は、モデルのバージョンを指定してURIを生成します)。
これらの準備が整った上で、fs.score_batch機能を使用して予測処理を実行します。
予測結果として返されるSparkDataFrameには、「キーで指定したカラム(ここではpredict_index)」、「特徴量」、「予測値」が含まれます。
予測用に作成したsparkDataFrame

予測処理後のsparkDataFrame

~

番外編
データリネージについて
前段で紹介できませんでしたが、Feature Storeにはデータリネージ機能が搭載されています。この機能は、Feature Storeを作成する際の入力となるテーブルのリネージ(つまり、データの起源を追跡する機能)を可能にします。
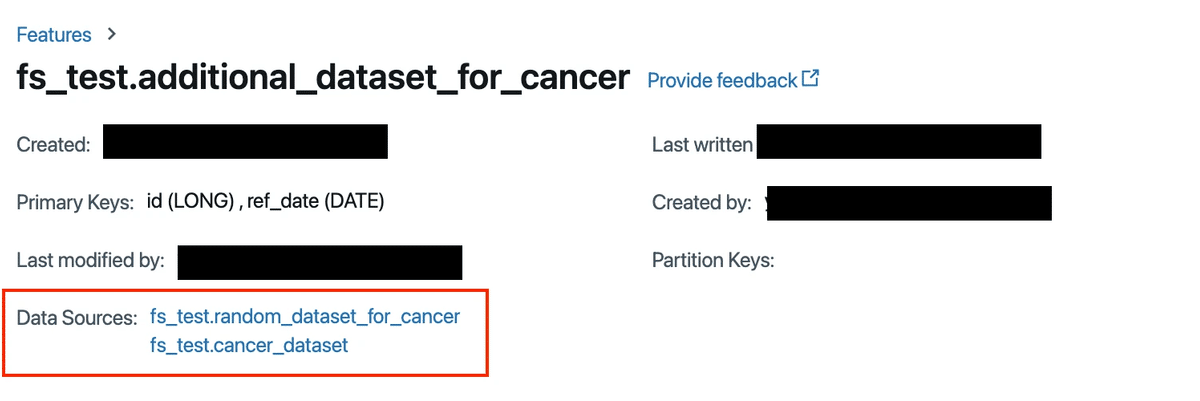
例として、先に作成したfs_test.cancer_datasetとfs_test.random_dataset_for_cancerを組み合わせて、新たなデータセットfs_test.additional_dataset_for_cancerを作成します。
canserDF = spark.read.table("fs_test.cancer_dataset").select(
"id", "ref_date", "mean_radius"
)
randomDF = spark.read.table("fs_test.random_dataset_for_cancer")
addDF = (
canserDF.join(randomDF, "id", "left")
.withColumn(
"multi_mean_readius_random", F.col("mean_radius") * F.col("uniform_rand")
)
.select("id", "ref_date", "multi_mean_readius_random")
)
fs = FeatureStoreClient()
# feature storeのTBL定義を作成
feature_table = fs.create_table(
name="fs_test.additional_dataset_for_cancer",
primary_keys=["id", "ref_date"],
schema=addDF.schema,
description="multi mean_readius,uniform_rand",
)
# feature storeへの登録
fs.write_table(name="fs_test.additional_dataset_for_cancer", df=addDF, mode="overwrite")作成したテーブルに関してはFeatureStoreのGUI画面で以下のようにデータソースを見ることが出来ます。
シチュエーション別実装方法
これまでの説明では、すべての特徴量がFeature Storeに登録されているという前提で進めてきました。しかし、実際にモデルを運用する際には、次のようなシチュエーションでモデルの使用が必要になることも想定されます。これらの状況に適応する実装例をご紹介します。
Feature Store外の特徴量を利用して学習や予測を行いたい場合
学習時にはFeature Storeから特徴量を取得し、予測時には一部のカラムをFeature Store外から利用したい場合
学習時も予測時も、一部の特徴量をFeature Store外から利用したい場合
アンサンブルモデルの運用におけるscore_batch機能の活用方法
Feature Store外の特徴量を利用して学習/予測したい場合
「学習時にはFeature Storeから特徴量を取得し、予測時には一部のカラムをFeature Store外から利用したい場合」について説明します。これを実現するには、予測時のキーとなるSparkDataFrameを作成する際に、学習時にFeature Storeで取得したカラムと同じ名前のカラムを用意することが重要です。これにより、予測時にそのカラムを利用することが可能になります。つまり、予測時のキーとなるSparkDataFrameとFeature Storeに同名のカラムが存在する場合、予測時のキーとなるSparkDataFrameにあるカラムが優先して利用されます。
# 予測用sparkDataFrameを用意(id,ref_date)
predict_index = pd.DataFrame(data=[(10)],columns=['id'])
predict_index = spark.createDataFrame(predict_index)
predict_index = predict_index.withColumn('ref_date',F.lit(datetime.date(2024,2,29)))
# 予測用にカラムを追加する(mean_radiusに999999を入れる)
predict_index = predict_index.withColumn('mean_radius',F.lit(999999))
# DataFrameの確認
predict_index.display()
# model registoryの指定(今回はモデルverで指定)
model_uri = f'models:/{log_model_name}/11'
# 予測処理実施
predictions = fs.score_batch(
model_uri,
predict_index
)
# 結果確認
predictions.display()予測結果
mean_radiusが999999で予測処理が実行された事が返り値のSparkDataFrameから分かります。

〜

「学習時も予測時も、一部の特徴量をFeature Store外から利用したい場合」に関して説明します。この場合、まず学習時に使用するfs.create_training_setで指定するSparkDataFrame(training_index_df)に、Feature Store外のカラムを追加することで実現できます。以下の例では、random_colというカラムを追加しています。
features = [col for col in data.columns if col not in ["id", "ref_date", "target"]]
feature_lookups = [
# fs_test.cancer_dataset のキーは['id','ref_date']
FeatureLookup(
table_name="fs_test.cancer_dataset",
feature_names=features,
lookup_key=["id", "ref_date"],
),
# fs_test.random_dataset_for_cancerのキーは ['id']
FeatureLookup(
table_name="fs_test.random_dataset_for_cancer",
feature_names="uniform_rand",
lookup_key=["id"],
),
]
# 学習用データのキー+ラベルを取得する
training_index_df = spark.read.table("fs_test.cancer_dataset").select(
["id", "ref_date", "target"]
)
# FeatureStore外のカラムをsparkDataFrameへ追加する
training_index_df = training_index_df.withColumn("random_col", (F.rand(seed=1234)))
training_set = fs.create_training_set(
# trainデータの「キー+ラベル+random_col」のsparkDataFrame
df=training_index_df,
# trainデータのDataFrameに対して外部結合で特徴量を取得する
feature_lookups=feature_lookups,
label="target",
# feature_lookupsで取得してきたカラムのうち、学習時に利用しないカラムを指定する
exclude_columns=["id", "ref_date"],
)
training_df = training_set.load_df().toPandas()この状態で、先ほどと同様に学習し、fs.log_modelを使用してモデルをモデルレジストリに登録します(コードは同じなのでここでは省略します)。
次に、Feature Store外のカラムを利用して学習したモデルでscore_batchを使用する例を以下に示します。学習時と同じように、予測で使用するSparkDataFrameにFeature Store外のカラム(random_col)を追加することにより、予測を出力できます。
# 予測用sparkDataFrameを用意(id,ref_date)
predict_index = pd.DataFrame(data=[(10)],columns=['id'])
predict_index = spark.createDataFrame(predict_index)
predict_index = predict_index.withColumn('ref_date',F.lit(datetime.date(2024,2,29)))
# 予測用にカラムを追加する(mean_radiusに999999を入れる)
predict_index = predict_index.withColumn('random_col',F.lit(999999))
# DataFrameの確認
predict_index.display()
# model registoryの指定(今回はモデルverで指定)
model_uri = f'models:/{log_model_name}/14'
# 予測処理実施
predictions = fs.score_batch(
model_uri,
predict_index
)
# 結果確認
predictions.display()予測結果

~

アンサンブルモデルの運用におけるscore_batch機能の活用方法
先ほどまでの例をご覧の通り、Feature Storeを利用してモデルを登録するfs.log_modelを用いた場合、モデルレジストリに新しいバージョンでモデルが登録されます。そのため、仮に5-fold CVで5つのモデルを作成し、その予測値の平均を運用で利用する場合、モデルレジストリに5つのモデルを登録する必要があり、運用が煩雑になる恐れがあります。
このような場合の解決策として、Ensembleクラスを用意し、そこにモデルを集約してモデルレジストリに登録する方法があります。例として、他のnotebookで作成した5つのモデル(5-fold CVを想定)を1つのEnsembleクラスに集約し、Feature Storeのfs.log_model機能を利用してモデルレジストリに登録することで、1つのモデルとして運用することが可能となります。
初めにEnsembleクラスを用意いたします。
import mlflow.pyfunc
import numpy as np
class Ensemble(mlflow.pyfunc.PythonModel):
def __init__(self, LGBMS):
"""
LGBMS: List of LightGBM models
"""
self.LGBMS = LGBMS
# def predict(self, context, model_input):
def predict(self, model_input):
"""
model_input: a pandas DataFrame of input features
"""
# 各モデルの予測を格納するリスト
predictions = []
# 各モデルに対して予測を行い、予測リストに追加
for model in self.LGBMS:
pred = model.predict(model_input)
predictions.append(pred)
# 予測の平均値を計算
avg_predictions = np.mean(predictions, axis=0)
return avg_predictions続きまして既に学習済みである5-foldCVで作成したモデルをmlflowから取得し、listへ格納いたします。
ensamble_models = []
run_id = 'run_id'
for n in range(5):
# model_0 ~ model_4でモデルレジストリへ保存したモデルを呼び出す
model_uri = f"runs:/{run_id}/model_{n}"
ensamble_models.append(mlflow.pyfunc.load_model(model_uri))modelレジストリへ特徴量情報を登録するためfeature_lookupsを定義いたします。
features = spark.read.table('fs_test.cancer_dataset').columns
features = [col for col in features if col not in ['id','ref_date','target']]
fs = FeatureStoreClient()
feature_lookups = [
# fs_test.cancer_dataset のキーは['id','ref_date']
FeatureLookup(
table_name = 'fs_test.cancer_dataset',
feature_names = features,
lookup_key = ['id','ref_date']
),
# fs_test.random_dataset_for_cancerのキーは ['id']
FeatureLookup(
table_name = 'fs_test.random_dataset_for_cancer',
feature_names = 'uniform_rand',
lookup_key = ['id']
),
]最後に学習です。ここでは先程listに格納した5つのモデルを1つのEnsembleクラスにまとめた上でfs.log_modelを利用する事で1つのモデルとしてモデルレジストリへ登録することが可能です。
with mlflow.start_run(experiment_id = 'experiment_id'):
mlflow.sklearn.autolog(log_input_examples=True, silent=True)
log_model_name = 'ensemble_model'
fs = FeatureStoreClient()
# 学習用データのキー+ラベルを取得する
training_index_df = spark.read.table('fs_test.cancer_dataset').select(['id','ref_date','target'])
# training set生成
training_set = fs.create_training_set(
df=training_index_df,
feature_lookups = feature_lookups,
label = 'target',
# feature_lookupsで取得してきたカラムのうち、学習時に利用しないカラムを指定する
exclude_columns = ['id','ref_date']
)
# Ensemble classの生成
model = Ensemble(ensamble_models)
# モデルとデータをFeature Storeに登録
fs.log_model(
model,
log_model_name,
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=log_model_name
)さらに、上記方法で登録したモデルレジストリを利用することでscore_batch機能を利用でき、予測時のコードを簡略化することが可能となります。
predict_index = pd.DataFrame(data=[(10)],columns=['id'])
predict_index = spark.createDataFrame(predict_index)
predict_index = predict_index.withColumn('ref_date',F.lit(datetime.date(2024,2,29)))
model_uri = f'models:/ensemble_model/1'
predictions = fs.score_batch(
model_uri,
predict_index
)
predictions.display()この説明は、Feature Storeを活用することでモデル実装を行う際のサンプルコードについてのものでした。Feature Storeを利用することによって、データ管理やモデル性能の向上につながります。
より詳細な情報や最新の機能については、公式のリファレンスを参照していただくことをお勧めします。
参考
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちらにお願いします。
Japan Digital Design 株式会社
M-AIS
Yuto Kobayashi