
KDD 2024参加報告

本記事は、Japan Digital Design Advent Calendar 2024の8日目の記事になります。
三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)に所属する永友遥です。
弊社のアドベントカレンダーに昨年に引き続きましての参加になります。前回は推薦をテーマとして扱ったkaggleの過去に開催されたコンペの上位解法を紹介しました。こちらもご興味あればぜひご覧ください。
今年はデータマイニングの国際学会であるKDDに聴講で参加してきましたのでその紹介をさせていただければと思います。
KDD 2024について
KDDとはデータマイニングをテーマとした国際学会です。(KDD 2024 - ACM KDD 2024 )
30回目となる今年はスペイン・バルセロナで2024年8月25日から29日にかけて開催されました。発表された論文やワークショップの内容はLLMやグラフ、推薦などのトピックが多く、金融系ドメインに特化したセッションもありJDDの業務との親和性もありました。
また本会議とは別に毎年KDDではデータ分析コンペが開催されておりAmazon、Meta、OAGの3種類のコンペが開催されました。それぞれのコンペ内で複数のタスクがあり、例えばAmazonはオンラインショッピングデータに関するデータを題材として5種類のタスクが課せられました。直接参加してはいませんが近年はLLMの活用を前提としたコンペとなっているようです。
AIcrowd | Amazon KDD Cup 2024: Multi-Task Online Shopping Challenge for LLMs | Challenges
AIcrowd | Meta Comprehensive RAG Benchmark: KDD Cup 2024 | Challenges
参加者: 2284名
論文数
研究トラック(Research Track): 411本
データサイエンスに関する新しいモデルやアルゴリズムを扱った論文
ADSトラック(Applied Data Science Track): 151本
実用的アプリケーション向けのソリューションを扱った論文
ワークショップ: 30本
チュートリアル: 34本

チュートリアル
1日目にRAG(Retrieval Augmented Generation)のチュートリアルに参加してきました。RAGはLLMの活用法としてかなり注目されて研究されていますが私自身現在の業務ではLLMをあまり使いこなせてなかったので世間のトレンドに遅れをとらないようキャッチアップをするためにこのチュートリアルに参加しました。
RAGのアーキテクチャや学習方法、実ビジネスへの応用例などのセクションに分けて紹介されていて初心者でもRAGの技術周りの概要が網羅的に理解できるような講演でした。リンク先には発表で使用されたスライドがありますのでご興味のある方は参考にしてみてください。
RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
論文紹介
ここでは本会議において金融系と推薦系で印象に残った論文を2つ紹介します。
①LASCA: A Large-Scale Stable Customer Segmentation Approach to Credit Risk Assessment
どんな研究か?
クレジットリスク評価における顧客セグメンテーション(信用スコアに基づいて特定のリスクレベルへ分類・格付けすること、またはその分割点を決めるビニングのこと)には以下の課題があります。
スコア変動によりリスクレベルが頻繁に変化する不安定性
数億ユーザーに対する安定性評価をしようとするとリスクレベル毎のユーザー数の分布が目標としている分布に近いかどうかや単調性が維持されているかなどを過去データをもとに計算する必要がありました
安定性の評価が複雑で明確に定義されておらずブラックボックス化
本研究では進化的アルゴリズムによる統計的アプローチとML的アプローチの2段階で従来研究より安定したセグメント同士の分割点を探索する手法を提案しています。
先行研究との優位性
既存手法は単一の指標(単調性など)に対して最適化するもので合ったのに対して本手法は安定性の評価をStability regretとして定義し単調性以外にユーザー分布やリテンション率を総合的に評価しています。
既存手法は大規模データセットにおいては計算負荷の高さからダウンサンプリングを行う必要があり、その場合最適解が得られにくい課題があったのに対して本手法は数億件のデータにも適用可能で実際にAlipayのシステムに実装されています。
技術や手法のキモはどこにあるか
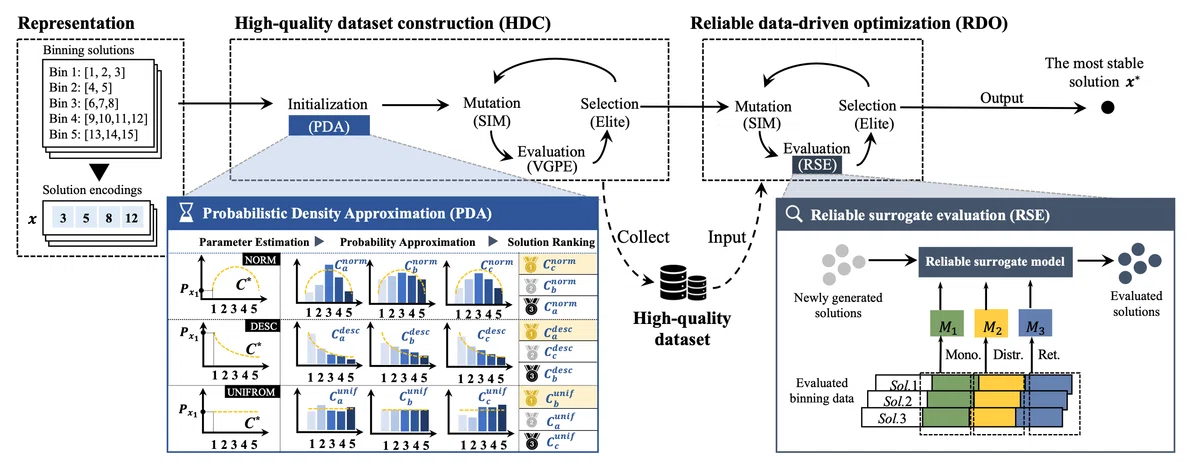
本手法は2つのフェーズから構成されています。
High-quality dataset construction(HDC)
確率密度近似(PDA)による初期化で収束速度を向上し、進化的アルゴリズムで分割点を最適化します。
Reliable data-driven optimization(RDO)
HDCで最適化したデータセットをさらにサロゲートモデル(代理モデル)を用いて最適化します。
1. HDC: High-quality dataset construction
PDA(Probabilistic Density Approximation)
pre-bin(データをざっくり分割したグループ)の累積確率を計算し、最初のビンに対してターゲット分布(正規分布, 指数分布, 一様分布)の形状を決定する境界値の範囲を定め、理想的な累積確率分布を計算します。
実際の累積分布を理想的なターゲット分布の累積分布に近づけるよう分割点を確率的に決定します。
上記の初期解に対し理想的な累積分布との乖離をKLダイバージェンスで計算しスコアが低い解を選択します。
進化的アルゴリズム
突然変異: ビニング解の要素(リスクレベルの区切り点)をランダムに変化させることで、新しい候補解を生成します。
評価: それぞれの解を以下の3つの指標の合計で算出されるStability Regretで評価します。
Distribution Regret
各リスクレベルの実際のユーザー分布が目標とする分布の差を評価します。目標分布に近いほどペナルティが小さくなります。
Monotonicity Regret
リスクレベルが上がった時に連動して単調にリスク指標(デフォルト率など)が上がるかどうかを評価します。単調性を維持するほどペナルティが小さくなります。
Retention Rate Regret
ユーザーが時系列方向に同じリスクレベルに留まるかの保持率と目標値との差を評価します。目標の保持率より高いほどペナルティが小さくなります。
選択: Stability Regretが小さい解を残し、また突然変異へ戻りループさせより安定的な解を探索します。
2. RDO: Reliable data-driven optimization
サロゲートモデルの構築
HDCで収集したビニング解データセットを分割し、3つのタスク(ユーザー分布, 単調性, リテンション率)を予測するサロゲートモデルをLightGBMなどで構築します。
進化的アルゴリズム
上記の各モデルの予測値からStability Regretを算出しHDC同様進化的アルゴリズムでより安定な解を探索します。
どうやって有効だと判断したのか
検証用データセット
ユーザーの行動履歴や属性、取引履歴に基づく信用スコアの3種類を用いて比較を行なっています。
安定性の比較
既存手法に比べて提案手法(LASCA)はStability Regretを改善しています。

計算効率の比較
RDOは、サロゲート評価を使用することで最適化プロセスを25倍高速化しています。
ODO: 実データ全てを対象にStability Regretを計算する従来の評価手法

業務に活かせそうか
クレジットスコアを元に安定性を保つようなリスクレベルへ分類するために統計的な手法とML的な手法に進化的アルゴリズムを組み合わせて2段階で安定したビニングを行っているのが特徴的でした。オンライン融資の与信モデルのスコアを元に融資の諾否を決めるようなビジネスモデルではリスクレベルを分類して融資の諾否を決めるので本研究の手法を用いることでより安定性のあるセグメントを得ることができるかもしれません。
②Controllable Multi-Behavior Recommendation for In-Game Skins with Large Sequential Model
どんな研究か?
オンラインゲームのキャラクタースキンはユーザーのゲーム体験をパーソナライズする重要な要素であり、サービスの収益に大きな影響を与えています。従来の行動履歴を用いた推薦モデルは異なる行動間の時系列の関係性を十分に捉えきれていなかったり、学習時とは異なるシナリオに適応できないといった課題を挙げています。
本研究ではユーザーのさまざまな行動履歴(クリックやスキンの使用、購入など)をもとに異なるシナリオ(スキン購入、スキン試用、ウィッシュリスト追加)に単一モデルで推薦を行うことができる手法を提案しています。

先行研究との優位性
既存手法はユーザーの単一の行動に基づいて推薦を行うために複数の行動の相互関係を考慮しにくいですが本手法は多様な行動の相互関係に対応することが可能です。
またシナリオ(予測したいタスクのことで本論文だとクリック、購入、試用が挙げられています)毎にモデルを構築する必要がなく、Stimulus Prompt Mechanismによって単一のモデルで複数の行動予測に対応させることができます。
技術や手法のキモはどこにあるか

本研究では、以下の技術を組み合わせたCMBR(Controllable Multi-Behavior Recommendation)モデルを提案しています。
1.刺激プロンプト機構(Stimulus Prompt Mechanism)
ユーザーの履歴シーケンスにシナリオ(予測したいタスクのことで本論文だとクリック、購入、試用が挙げられています)固有のプロンプトを挿入します。このプロンプトにより、モデルは特定のシナリオにおいてどの行動タイプを重視すべきかを理解し、ユーザーの次の行動を誘導します。これにより、異なるシナリオにおいてユーザーの異なる意図をうまく捉えることができ、シナリオ特有の行動予測が可能になります。
具体的には、以下のようにシナリオごとの特定のトークン(例: [stimulus_buy] )をユーザー行動履歴内の最後のシナリオのトークン直前に挿入します。
スキン購入シナリオ:[stimulus_buy] → 以降のスキン購入行動を予測するよう誘導
スキン試用シナリオ:[stimulus_use] → 以降のスキン試用行動を予測するよう誘導

# 購入シナリオ時のインプットイメージ
[2003211_use], [stimulus_buy], [2001452_buy], [2004562_click]2.逐次生成モデル(Sequence Generation Model)
大規模逐次モデル(LSM)の事前学習能力を活用。
GPTのようなTransformerデコーダーベースのアーキテクチャをベースとしています。
ユーザー行動シーケンスの次の行動を予測するタスクを通じて事前学習を行います。
ユーザーの行動履歴を自然言語のように扱い、時系列関係を自己回帰的に学習します。
モデル
以下の3種類のレイヤーから構成されています。
埋め込み層
Dual-Level Interaction Attention
アイテムレベルとスキンレベルの2種類のattentionを統合します。
ユーザーの多様な行動間の依存関係を学習します。
予測層
次に起こり得る行動(例: 購入)を予測します。
3.CTCVRモデリング(Click-Through Conversion Rate Modeling)
ユーザーがクリックし、最終的に購入するCTR(クリック率)とCVR(購入率)を掛け合わせた確率(CTCVR)を予測します。
推論時は予測CTCVRが最も高いスキンが推薦されます。
どうやって有効だと判断したのか
検証用データセット
数百種類のキャラクタースキンをもつゲームのユーザーの行動履歴
オフライン実験
既存手法に比べて購入予測精度(HR@10)は最大10倍以上向上しています。

オンラインA/Bテスト
収益指標(ARPU)が数%向上しています。

業務に活かせそうか
通常の時系列データを扱うような推薦タスクは行動履歴に対してクリックや購入のラベルが1対1対応するようなものが多いですが、本研究ではキャラクスタースキンのクリックや購入といった異なる目的に応じてアイテム(キャラクスタースキンと行動のペア)を推薦をすることが可能になっています。シーケンシャルデータをTransformerエンコーダーベースのモデルで学習するような手法はありましたがLLMのようにデコーダーベースの事前学習を用いていることから、より大きなモデルを適用すると精度が向上しそうな気がしています。本論文でも展望として行動履歴のみをインプットとしていますが今後はキャラクタースキンの画像やテキストなども含めたマルチモーダルモデルや他ゲームのデータも活用したクロスドメイン推薦も提案されています。
金融ドメインでも金融商品のレコメンドといった形で推薦タスクのニーズはありますのでLLMを用いたレコメンドモデル構築のアイデアとして面白い論文でした。
最後に
ここまでお読みいただきありがとうございました。
2年連続となる今回は国際会議KDDの参加報告でした。自身初めての海外かつ国際会議への参加だったので色々不安な面もありましたが日本から参加している方々も多く、最先端のトピックの発表を聞くことで刺激を受けることができ改めて参加できて良かったと思っています。

Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちら
M-AIS
Haruka Nagatomo