
ICAIF 2024 参加報告

本記事は、Japan Digital Design Advent Calendar 2024の19日目の記事になります。
三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)にて、MUFG AI Studio(以下M-AIS)に所属し、データサイエンティストをしている山田です。
昨年に引き続き、11月14日から17日にかけてニューヨークで開催された、金融領域での国際学会「ICAIF 2024」に参加しました。
本投稿では下の目次に沿って、学会概要と興味深かった発表内容について紹介をします。記事を読んで、学会や研究内容への興味、また弊社への興味を持っていただけたら幸いです。
全体の印象
ICAIF (International Conference on AI in Finance)は、ACMの金融分野の分科会で、学術的な研究だけでなく、実務寄りの発表も多いです。
2024年で第5回目の開催となりました。メイン会場は、New York University(NYU)のTandon School of Engineeringであり、一部のワークショップでは近隣のホテルのボールルームを借りて開催されました。
メイン会場のNYUは以下のような所でした。


ICAIF2024の参加登録者は600人以上、33の地域から参加があったと報告されており、採択された論文のキーワードとしてはPredict, Portfolio, Network, Data, Languageといった単語が頻出でした。

2024年は、昨年と比べ3日から4日間と期間が延びており、ワークショップ、チュートリアル、本会議も含めて多岐にわたるトピックの発表が行われ、内容が非常に充実していました。特に、ワークショップでは、LLMのテーマが多く、金融領域へのLLM活用が非常に盛んであることが伺えました。
全体を通してのスケジュールは以下の通りでした。
11種類のWorkshop
4本のTutorial
3本のコンペ
4本のKey note speech
48本のOral presentation
51本のポスター
同時開催が多く時間的な都合上、チュートリアルは参加できませんでしたが、LLM関連のワークショップと本会議に参加し、特に興味深かったテーマとして、金融特化のマルチモーダル基盤モデルと基調講演がありました。
こちらはワークショップの発表ですが、マルチモーダル金融特化基盤モデルの構築(Q. Xie et al., 2024)についての紹介がありました。従来から報告されているベンチマークを上回っていることを示しており、実際にどの程度業務活用できるのかは興味深いものがあります。ワークショップでは機械学習の国際会議で発表された内容を紹介するという発表も多かったです。本内容は、本note記事で紹介させていただきます。
基調講演では、全体的に面白かったのですが、特にJPMorganChaseでHead of AI ResearchのManuela Veloso氏の講演でした。元々、計算機科学やロボットの研究をされている方で、途中から金融領域に入ってきたとのことです。どのようにロボットを学習させ、現実世界とインタラクションさせているかの発表についても大変興味深いものがありました。
以下では、個人的に興味深いと思った論文発表を、3本ほど紹介できたらと思います。
興味深かった発表
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
ICAIFの中で一番興味を持った内容は、ワークショップで公開されていたOpen-FinLLMs(Xie et al., 2024)です。筆頭著者のQianqian Xie氏は、昨年、金融データセットの広範囲なデータセット・ベンチマークセットを構築したことが評価され、NeurIPS Dataset and Benchmark Track 2023にてポスター発表をされていました。こちらの内容に関しては、NeurIPS 2023参加報告でも紹介させていただきました。
金融特化させたLLMとして代表的なものにBloombergGPT (Wu et al., 2023)やFinGPT (Yang et al., 2023)があります。これらのモデルは、一部タスクに対する性能が十分でなく、特定のタスク、事象に対してのみ学習が行われているといった課題がありました。一方、Open-FinLLMsでは、以下表にあるように、より広範囲なデータセットを使って金融特化マルチモーダル基盤モデルが学習されています。

一般的に、LLMの学習の流れは、事前学習(Pre-training, PT)もしくは既存の学習済みモデルに対して継続事前学習(Continual pre-training, CPT)を行います。PTもしくはCPTにてLLMに知識を学習させた後に、特定のタスクに適用できるよう指示ファインチューニング(Instruction Fine-tuning, IFT)を行います。
さらに次のステップとして、LLMが人間にとって好ましいと思う回答を引き出し、不適切な回答を生成してしまうリスクを防ぐためにアライメントが行われます。なお、上表には記載されていませんが、FinTralではアライメントが行われていますが、現状Open-FinLLMsでは行われていません。
マルチモーダル(画像)に対応するために、Open-FinLLMsでは、LLaVA-1.5 (Liu et al., 2024)と同様の方法を利用しています。すなわち、画像をエンコードするためのvision encoder (ここでは、CLIP, Radford et al., 2021)と言語モデルの埋め込み空間をアライメントさせます。これは、vision encoderとLLMの重みを凍結し、MLP projectorを学習することで達成できます。MLP projectorの学習が完了した後に、MLP projectorとLLMに対してSFTが行われ、画像のインプットに対して適切なテキストを生成できるようになります。

Open-FinLLMsはLLaMA3 8Bベースのモデルですが、金融論文やカンファレンスコール、レポート、テクニカル指標といった多様なデータセット計52B分とジェネラルなデータセットであるFineweb (18B)に対してCPTを行っています。64個のA100 (8ノード)で学習させ、1 epochに250時間かかっていることが報告されています。金融ドメイン以外のデータセットを混ぜているのは、LLMの破滅的忘却を抑えるためであり、DoReMi(Xie et al., 2023)に従い比率が決定されています。
ダウンストリームタスクに対応するためにIFTを行っており、この時のデータセットは573Kとなっています。利用しているデータセットは、PIXIUで提案された多種多様な金融データセットのものになってなります。
以下表にベースモデル (LLaMA), BloombergGPT, FinLLaMA(提案モデル)の評価結果が示されています。学習された提案モデルのパフォーマンスを見ると、ベースモデルやBloombergGPTと比べると性能が大きく向上していることが確認できます。一方で、数学のタスクは弱く、CPTやIFTだけでは依然として厳しいことも見ることができています。本課題を解決するためには、FinTralで行われていたようなツール学習が必要になってくると思われます。より詳細な内容につきましては、論文をご確認いただければと思います。
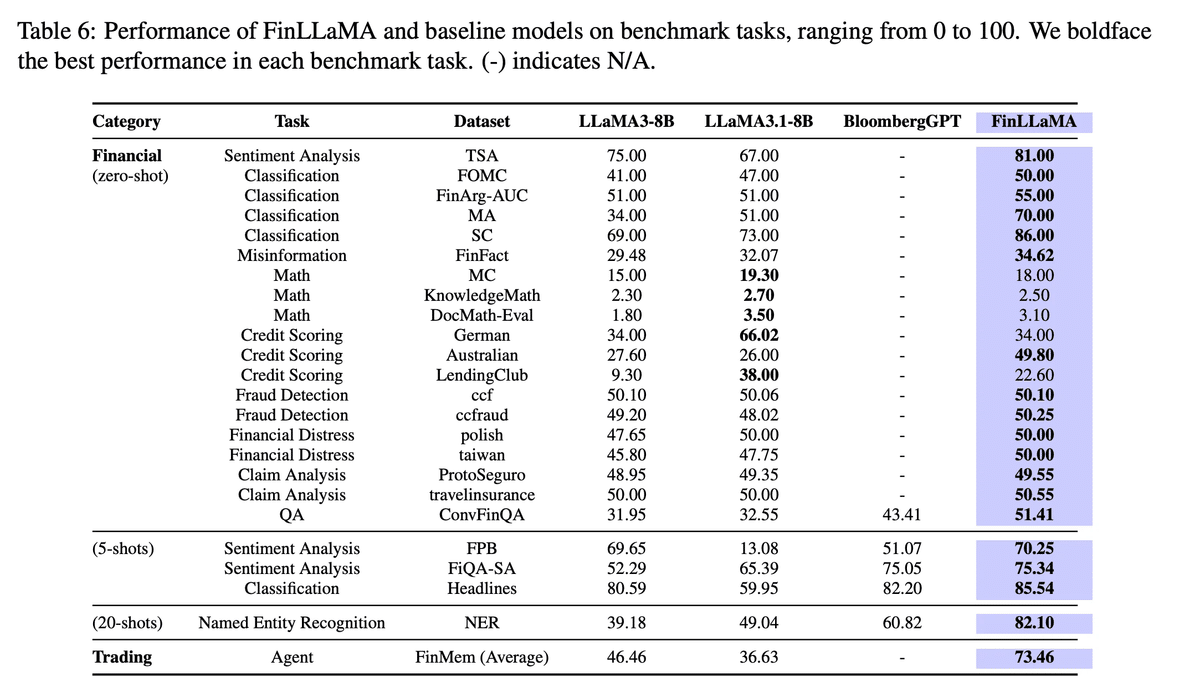
このようにオープンソースLLMの金融領域の適用はまだまだ発展途上でありますが、一部タスクでは実務で利用できるレベルに達しつつあると感じています。依然として課題は残っていますが、既存のハードウェアや研究の進化もあり、さらなるブレークスルーが起きるのではないかと期待している分野の1つでもあります。
最後に、本件を発表されたThe Fin AIは、FinConというマルチエージェントシステムに対する金融市場トレードにも関わっており、ワークショップで発表されていました。こちらはLLMを使ったトレードを行う場合に、リスクコントロールの重要性を示唆しています。本発表はNeurIPS2024に採択もされています。
Adaptive Risk-Based Control in Financial Trading
次に興味がある発表として、University of Maltaのグループが発表した論文で、こちらはオーラル発表をされています(Camilleri et al., 2024)。強化学習を使ったトレードは多くの研究グループで発表されていますが、こちらは、強化学習にリスクコントロールを組み込むことでパフォーマンスを向上させた発表になっています。
以下、強化学習の知識を前提とした数式が含まれるため、馴染みのない方は理論を抜きにして結果だけを見ていただければと思います。
本発表では、分布型強化学習(Distributional Reinforcement Learning)を使ってリスク量を推定するのに加え、Volatility-Prioritized Replay Bufferというアプローチを導入することで、強化学習トレードのパフォーマンスを安定化させています。
まず、キーとなる技術として強化学習のベルマンオペレータを分布にも対応できるようすることです。リターン分布 $${Z}$$ , 状態 $${s}$$ , 行動 $${a}$$ とすると、分布型強化学習では以下のような式でベルマンオペレータが定式化されます。
$$
Z(s,a)=R(s,a)+γZ(s',a')
$$
ここで、 $${R(s,a)}$$ は報酬、$${γ}$$ は割引率、$${s'}$$,$${a'}$$ はそれぞれ次の状態、行動になります。
分布型強化学習には、様々な方法が提案されています。通常のQ学習では、累積期待リターンそのものを近似しようとします。一方で、分布型強化学習では、Q関数を「確率分布」で推定することで、「将来報酬の分布」を返すことができるようになります。本発表では、分布型強化学習の1つであるQR-DQN (Dabney et al., 2017)を用います。QR-DQNでは、リターンの累積分布関数 $${F}$$ の逆関数$${F^{-1}}$$(分位点関数)を近似します。分位点回帰を行うことは、1-Wasserstein(earth mover's distance)を最小化する方向に分布が収束することが示されています。
分位点予測の図を考えてみます。横軸がリターンになっていて、縦軸がそのリターンの累積確率です。黒線は既存の報酬分布(累積分布関数の逆関数)を表します。青い段階的な線が近似した分布で、赤い塗りつぶし部分は1-Wasserstein誤差を表しており、この面積が最小となるようにニューラルネットのパラメータが学習をされます。

QR-DQNが金融市場トレードに適用されることがありますが、確率的な要素を組み込むのが難しいと言われています。Songら(2021)はこのような問題を解決するためにガウシアン混合によってモデル化された確率的方策と、分位数に基づく分布型のcriticを組み合わせた"Stochastic Policy with Distributional Q-Network (SQDQ)"と呼ばれるフレームワークを提案しています。Criticネットワークがリターンの分布を予測することによる行動評価をしながら、方策ネットワークはポートフォリオの重みを生成します。
ここで著者らは、リスクを調整した報酬を組み込むことで、マーケット環境がボラタイルな状況を反映できるようにしています。データセットはDJIAを利用し、強化学習の設定として以下のようにしていました。
観測空間:トータルで、661次元のベクトルとなっています。具体的には、残高、各アセットの価格、保有株式数、90のテクニカル指標に対してPCAを適用し、上位20成分を利用しています。
行動空間:DJIA30銘柄分あり、-1が保有数を減らす、+1が保有数増やす。
報酬関数:ポートフォリオのリターンを最大化させるようにしています。具体的には報酬は以下のように定義されています。
$$
r(S_t, A_t, S_{t+1})=(b_{t+1}+E_{t+1})-(b_{t}+E_{t})
$$
ここで、 $${b,E}$$はそれぞれ、残高と時刻 $${t}$$ における株式を表します。最終的なEquityは以下のように定義されています。
$$
E_t = \sum_{i=1}^{n} (h_{t,i} \cdot p_{t,i})
$$
ここで、$${n}$$ はアセット数、$${h_t}$$ はアセット$${i}$$におけるポジション数、$${p_t}$$ はアセット$${i}$$における調整済み価格になっています。
他にも流動性、ブックサイズ、コストを考慮しています。リスク管理指標としては、turbulenceを使っており、過去のリターンとのマハラノビス距離を考えることで、マーケットのボラティリティを計測しています。
提案アルゴリズム
本論文では、Twin Delayed Distributional Deep Deterministic Policy Gradient (TD4)を提案しています。ベースに用いる強化学習アルゴリズムには、Twin Delayed Deep Deterministic Policy Gradient (TD3) (Fujimoto et al., 2018)と呼ばれる代表的なアルゴリズムを用い、加えて冒頭で述べたQR-DQNを組み合わせた分布型強化学習アルゴリズムになっています。
さらに、本論文では、学習期間以前のトレードデータで類似のマーケットのボラティリティをもつ遷移に優先付けサンプリングできるようVolatility Prioritized Replay Buffer (VPRB)を提案しており、こちらのreplay bufferからサンプリングし、モデルを学習させています。具体的にVPRBのアルゴリズムを見てみると、バッファーに格納されている最大値と最小値を使ってボラティリティを0-1の範囲に標準化したのちに、その遷移を計算しています。ユークリッド距離が小さいものが高い確率値となります。
// Sampling Probability using a VPRB
// Replay Buffer as B
// C_v as current market volatility
for T in B do
T_norm = (T - B_min) / (B_max - B_min)
P(T) = 1 - (C_v - T_norm)
end forまた、最適な分位点を選択するために、各ペアの分布Conditional Value at Risk (CVaR)が最小となる関数を使っています。具体的には、以下のように定義されています。
$$
\text{CVaR}_{\alpha}(Z) = \mathbb{E} [Z \vert Z \leq \text{VaR}_{\alpha}(Z)] \\
\text{VaR}_{\alpha}(Z) = \text{CDF}^{-1}_{Z} (\alpha)
$$
ここで、Zはリターンを表すランダムな変数です。$${\text{VaR}_{\alpha}}$$は、与えられた信頼区間αでのvalue at riskで、$${\text{CDF}^{-1}}$$は累積分布関数の逆数(すなわち分位点関数)です。最小のCVaRに基づいてターゲットの分位点を選択することは、高品質なデータかつより良いアクションによってパフォーマンスの向上につながります。式で書くと以下のようになります。
$$
z_j = \min_{i \in {1,2}} \left[\text{CVaR}(Z_{\phi, target, i}(s', a'(s'))) \right]
$$
これらを組み合わせた最終的な結果として、提案手法のVPRBとTD4を組み合わせた時が最もシャープレシオが良くなっていることが確認されていました。ベースの学習期間は2009年1月から2015年12月31日で、モデルの再学習とそのバックテストには、60日ごとローリングウィンドウ方式で再学習と評価が行われています。コロナ禍の急落にはポジションを持たないようになっています。
詳細は論文の図やパフォーマンスを確認いただけたらと思います。
論文:https://dl.acm.org/doi/10.1145/3677052.3698652
分布を考慮した強化学習とリスク管理手法を組み合わせることでパフォーマンスを向上させており、このような方法は機械学習トレードを行う場合では必須ということを改めて認識することができました。
Generative-CNN for Pattern Recognition in Finance
最後に紹介させていただく発表は、チャートに対するデータ水増し手法についてです(M. Camilleri et al., 2024)。CNNを学習する際、大量のデータが必要となりますが、チャートのパターンをGANで生成させることで、CNNのパフォーマンスが向上したというものです。本発表は、問題定義・アイディアともに非常に面白いと思いました。
株価のようなチャートには特定のパターンが現れると上昇・下降トレンドといったシグナルとして扱うことができます。その中の代表的なものの一つに"Head & Shoulders"というパターンがあります。

本ローソク足の図を見ると、アップトレンドから、ネックラインを境目に左肩、頭、右肩といった山のような形が形成されています。この時に、ネックラインを下回ったときに、トレンドがブリッシュからベアリッシュ相場に逆転するといったものです。一方、逆パターンのinverse head & shouldersというものもあり、トレンドの転換に用いられたりします。
著者らは以下の点を実行しています。
ブリッシュ・リバーサルとベアリッシュ・リバーサルを表す2つのクラスのローソク足データセットを手動でスクリーンショットから作成
DCGANでのデータ水増し
CNN (Inception V3)の学習
最初にデータを集める所は、特定のトレーディングソフトウェアから、手動でスクリーンショットを行なってデータを集めたそうです。そして、得られたデータから合成データを作成することでCNNの性能向上を確認しています。実際にDCGANで生成された結果を見ると、ぼやけている画像ですが、パターンの特徴は掴んでいるようです。
例えば、DCGAN(A. Radford et al., 2015)では、MNISTの画像を学習させると、数字が生成されるようになります。本手法をHead & Shouldersに対して適用しています。

これらのデータとそのラベルをGen-CNN (Inception V3)で学習させると、トレンドを検出できる性能は、データ水増しする前よりも向上しているようです。
Head & Shouldersのようなパターンは、時間足を変えながら人間の目で見て判断してパターンを認識するという所があるので、本手法によって様々な銘柄で本パターンを抽出するには有効であるように思えます。
最後に
今回も前年に引き続き、ICAIF2024に参加し、興味深い発表を3つほどピックアップし紹介させていただきました。金融市場トレード系の発表を中心に聴講していましたが、LLM活用やプライバシーを担保したデータ合成や連合学習といった発表などもあり、実務で利用できそうな内容も多岐に渡っていました。
M-AISでは金融ビジネスの課題を解決するために、各種最先端のAI研究結果を積極的に活用しています。
もしAIの実務も研究も両立したくて、M-AISに興味を持っていただいた方はぜひ気軽に弊社まで連絡してください。
この記事に関するお問い合わせはこちらにお願いします。
Japan Digital Design 株式会社
MUFG AI Studio
Masatsugu Yamada