
KDD 2023 参加報告③(LLM Day編)

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)にてVP of Data Scienceを務める平山です。
ロサンゼルスのロングビーチで開催されたデータマイニングの国際学会「KDD 2023」に参加してきました。
本記事は、KDD 2023参加報告の第3回として、Large Language Model Dayにて大規模言語モデル(LLM)開発の一線で活躍している研究者によって共有されたLLMに関する知見を紹介したいと思います。
第1回では「KDD 2023 参加報告①(JPMC編)」と題し銀行業界のAI研究をリードするJPMC AI Researchの取り組みを、第2回では「KDD 2023 参加報告②(Finance Day編)」と題しFinance Dayで発表された金融・経済分野の研究を、それぞれ紹介させて頂きました。
今回採り上げるLLM Dayは、Google DeepMind、Open AI、Meta、Microsoft、Zhipu AIといったLLM開発の中心にいる企業の研究者・開発者が勢揃いし、LLM技術の何がわかっており、将来どんな進化が期待できるか、信頼性をどう担保していくかなどについて講演が行われました。
このように企業の垣根を超えて第一線のメンバーが揃うのもKDDのような国際学会ならではの魅力と言えるのではないでしょうか。
本稿では、LLMによってもたらされた機械学習技術開発における変化を概観するのに最適なOpen AIのWei氏の講演について詳しく紹介し、他の講演についてはトピックを簡単に紹介いたします。
紹介する講演のスライドは、LLM DayのWEBページからアクセス可能ですので、併せてそちらもご参照ください。
New paradigms in the large language model renaissance
Open AIのWei氏の講演では、LLM研究によって発見された3つの特徴、スケール則、創発(発現)性、推論能力、の紹介と、それらによって起きた従来の機械学習モデル開発と異なるLLM開発のパラダイム変化が示されています。個人的な感想ですが、従来の機械学習モデル開発においては、ローカルに独自データを大量に保有することが必要とされ競争優位をもたらすと考えられてきましたが、大規模言語モデル開発においては、その価値は大きく変化すると考えさせられる講演だったと思います。
まずは、スケール則(Scaling Laws for Neural Language Models, Jared Kaplan, et al. 2020)によるパラダイム変化です。言語モデルとは、ある文章の単語列が途中まで与えられた時にそれに続く単語を予測するモデルです。スケール則は、言語モデルの予測の正確さが言語モデルの規模(学習に必要なコンピューターのリソースの大きさ)が大きくなるほど向上し、モデルの正確さと規模の間に特定の関係が存在することを示すものです。講演ではこの法則性を示す実験結果が紹介されています。

(発表スライドより。図のオリジナルはGPT-4 Technical Report )
スケール則は、言語モデルの大規模化を加速させ、多くのコンピューターのリソースを持つ、いわゆるビッグテック企業による開発競争を加速させました。Chat GPTの登場により世界が受けた衝撃は、その結果もたらされたものと言えるでしょう。
そしてモデル開発の現場では、1人または少人数による開発から、多くの人が協力し合う大規模チームを必要とするものへとパラダイム変化が起きている、とWei氏は述べていました。実際に、先日発表されたGoogleの言語モデルGeminiの論文では、900名以上のチームメンバーが論文著者として名を連ねています。
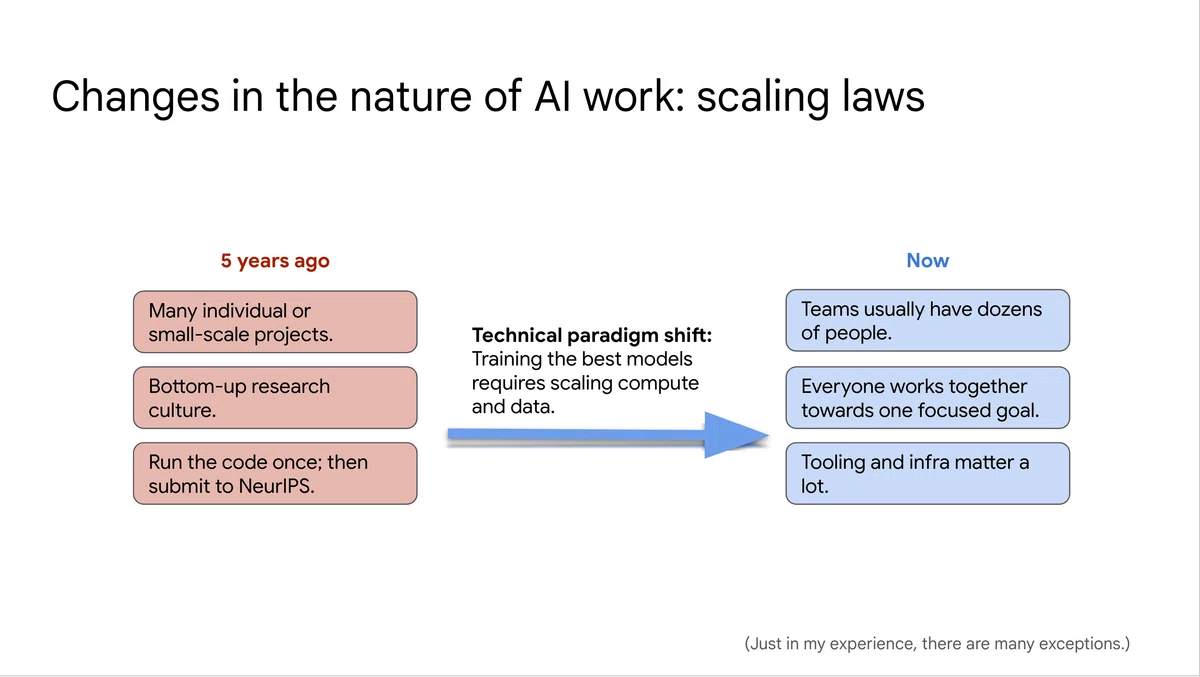
(発表スライドより)
続いては、創発性(Emergence)の発見についてです。
創発性とは、小さなサイズの個々の要素が集まり一定の規模を超えたときに突如として質的な変化が発現(Emergence)する現象・性質のことです。
言語モデルは、与えられた単語列からそれに続く単語を予測するモデルですが、予測された単語を入力の単語列に追加し再帰的に予測を繰り返すことで文章を生成することができます(実際に整合性のある文章を安定的に生成するためには技術的な工夫が必要です)。この時の、得たい文章を生成するために最初に与える単語列(文章)のことをプロンプト(prompt)と呼んでいます。このプロンプトを工夫することで大規模言語モデルから様々なタスクの回答(確率的に最適と考えられる文字列)を得られることが知られてきています。
なかでも、いくつかの例を与えることで言語モデルの学習データには含まれていないはずの問いに対しても正しい回答が生成できるfew-shot promptingは驚くべき性質ですが、この性質は言語モデルの規模に対して創発的に発現します。few-shot promptingの回答精度はモデル規模が一定の大きさを超えたときに突如として飛躍的に向上するとの実験結果が講演では紹介されました。
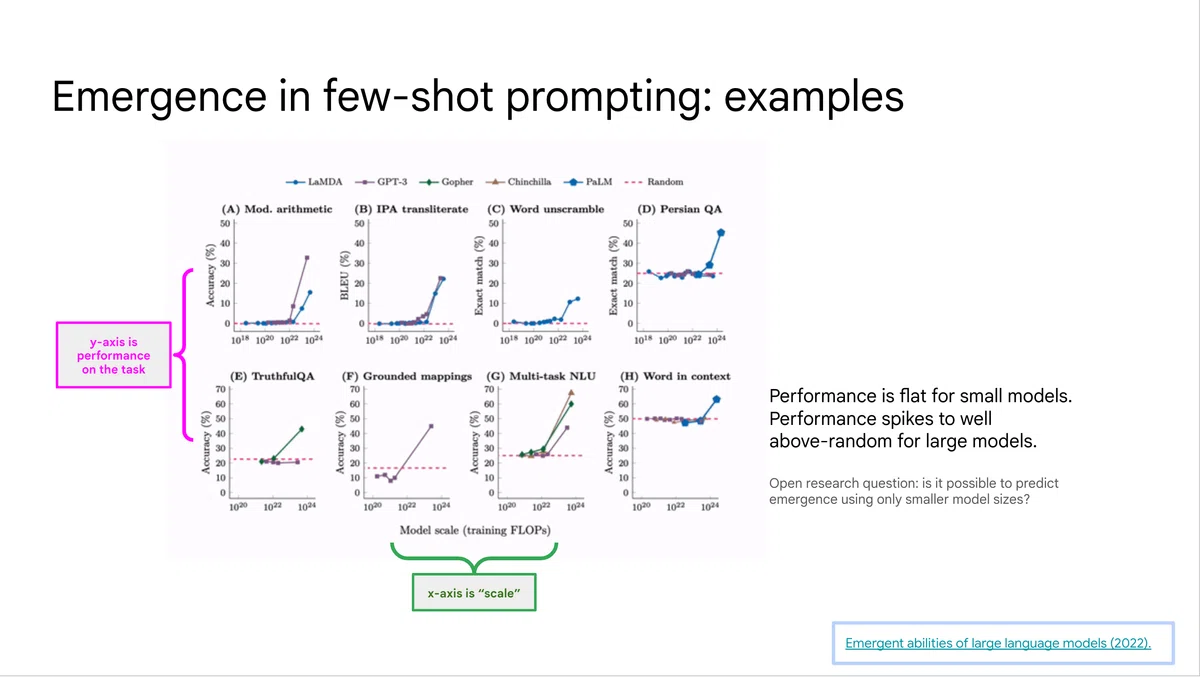
(発表スライドより抜粋。詳細はEmergent Abilities of Large Language Models参照)
また、言語モデルの創発性の発見について下記の3つの意味があると紹介されています。
予測困難
より小さなモデルによる実験結果の外挿では性能が予測できない。言語モデルを使用した下流タスクにおける性能はスケール則が当てはまらないケースがある。非意図的
言語モデルの設計者や開発者によって事前に意図して組み込まれた機能ではない。多機能性
よりモデルの規模を大きくすれば、さらに多くの創発的な能力が発現するかもしれない。結果として1つのモデルで多くのタスクを実行できる汎用性の高いモデルが実現できるかもしれない。(望ましくない能力が発現する可能性もある)
そしてAI開発においては、未知の能力が創発的に発見されることに伴い、モデル性能を計るためのベンチマークも新たに追加され続けることが求められ、さらに1つのモデルで複数のタスクがこなせるようになったため単一の指標だけではモデルの優劣は判断できなくなっている、との変化が示されました。創発性は、より巨大なモデルを作る新たなモチベーションを与え、より汎用的なAIの実現への期待を大きく膨らませている、と感じました。

(発表スライドより)
最後のトピックは、推論能力についてです。
タスクに応じた大量の学習データを必要とする(機械学習による)人工知能に対して、人間は「考え方」を学ぶことで、少量の例示、あるいは全く事例のない未経験の事であっても、答えを推論して導くことができます。
これまで、このような推論能力は、人間の知能と人工知能との大きな差の1つとして認識されてきました。ところが、Google ResearchのBrainチームによって発見されたChain-of-Thought(CoT) Prompting(Jason Wei, et al. 2022)により、LLMでは推論能力が実現されていると考えられるようになりました。
例えば、単純な問いと答えの例示によるプロンプトは下記のようなものです。
Q:ロジャーは5個のテニスボールを持っている。加えて2缶のテニスボールを購入し、1缶にはそれぞれ3個のテニスボールが入っている。ロジャーは全部で幾つのテニスボールを保有しているか?
A:答えは11個。
Q:ある食堂に23個のリンゴがある。そのうち20個をランチを作るために使い、6個を新たに購入した。りんごは今何個あるか?
残念ながら、このプロンプトの最後の問いに対してLLMは正解を答えられなかったようです。従来の機械学習のアプローチは、このような問いと答えのペアを大量に与えることで何らかの法則性を学習して一定の確率で正解を答えられるようにするというものでした。
一方で、CoT Promptingのアプローチでは、次のようなプロンプトをLLMに与えます。
Q:ロジャーは5個のテニスボールを持っている。加えて2缶のテニスボールを購入し、1缶にはそれぞれ3個のテニスボールが入っている。ロジャーは全部で幾つのテニスボールを保有しているか?
A:ロジャーは最初に5個持っている。3個ずつ入った2缶には6個テニスボールがある。5 + 6 = 11。よって、答えは11個。
Q:ある食堂に23個のリンゴがある。そのうち20個をランチを作るために使い、6個を新たに購入した。りんごは今何個あるか?
最初との違いは、答えを導出するための考え方も含めて例示している点です。
このようなプロンプトを与えることで、LLMは次のように考え方を示した上で正解を答えることができます。
食堂に最初23個のリンゴがある。20個をランチに使った。よって残りは23 - 20 = 3。6個リンゴを購入したので、3 + 6 = 9。よって答えは9個。
このように考え方を示すことで、大量の正解データを必要とせずに答えを導くことができているこの性質は、従来の機械学習モデルの学習と全く違う性質のように見えます。
CoT Promptingで明らかになったLLMの推論機能を引き出すためのコツは、Least-to-Most Prompting(Denny Zhou, et al. 2022)などさらなるプロンプトの工夫(プロンプトエンジニアリング)へと発展し、LLMがより難しい問題をステップ・バイ・ステップで解くことができる推論能力も持っていそうだ、ということも明らかになってきています。
一方で、このCoT Promptingによる推論性能に関しても創発的であることが報告されています。残念ながら、今のところ汎用的なAIの実現にはモデルの大規模化が避けては通れないようです。

(発表スライドより。詳細はChallenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them)
プロンプトによってLLMの推論機能を発揮させてタスクを解決できることが明らかになったことで、次のようなパラダイムシフトが起きているとWei氏は示しています。
まず、これまでのように単純に答えが合っているかという性能と違って、考え方が合っているかどうかという性能は、評価やデバッグが非常に難しいが、それに挑戦しなければならない。
次に、これまでは解きたいタスクに合わせてデータを集めてモデルを学習させていたが、これからは自然言語で記述されたプロンプトによってタスクを解いていく事になる。
それに伴い、これまでのハイパーパラメータチューニングに代わって、プロンプトエンジニアリングがAI開発の黒魔術(秘伝のノウハウ)になる。
黒魔術という表現を使っているところに、思わず注目してしまいます。
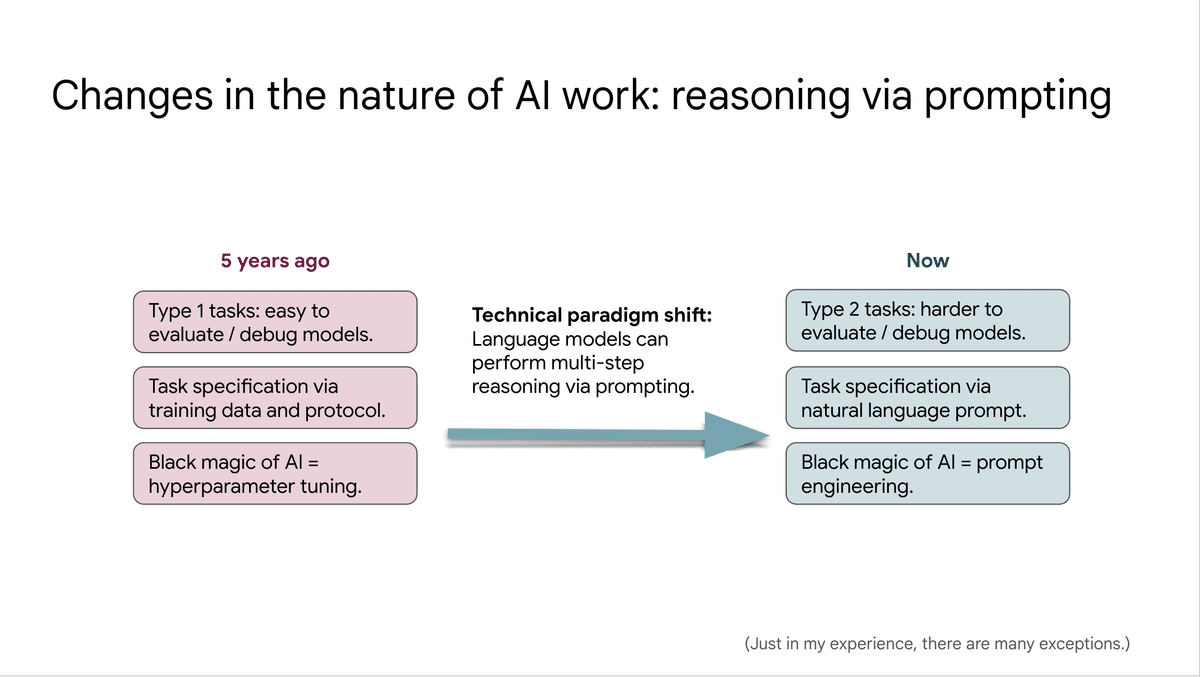
(発表スライドより)
最後に、Wei氏は今後可能性が見込まれる研究分野についてもいくつか示していました。
LLMの強みと限界を総合的に理解する
ハルシネーションの低減や校正、事実との紐付けなど正確性の向上
マルチモーダル性能の獲得(画像や音声との融合)
実世界とインタラクションして人間のように道具を使用する
人間の意図に従うように制御する
Teach Language Models to Reason
Denny Zhou(Google DeepMind), 発表スライド
Google DeepMindのZhou氏は推論チームを立上げたリーダーであり、Wei氏の講演でも取り上げられていたエポックメイキングなChain-of-Thought Promptingの研究を主導した1人です。講演では自身が関わった下記の研究成果について共有されました。
Chain-of-thought prompting (Jason Wei, et al. 2022)
考え方をプロンプトで与える事で、LLMが推論し、回答の精度が向上するSelf-Consistency (Xuezhi Wang, et al. 2022)
複数の考え方による答えを集約することで、正答を得られる確率が向上するLeast-to-most prompting (Denny Zhou, et al. 2022)
より簡単なステップに分解して順序立てて考え方を示す事で、複雑な構造の問いに対する回答精度が向上するInstruction finetuning (Hyung Won Chung, et al. 2022)
指示形式のデータによるファインチューニングにより、初見のタスクに対する性能が向上するLLMs self-debug (Xinyun Chen, et al. 2023)
LLM自身が生成したソースコードをセルフデバッグする方法を提案LLMs as tool makers (Tianle Cai, et al. 2023)
ツール(Pythonコード)を生成するLLMとそのツールを使用するLLMを組み合わせることで、継続的に異なるタスクに対応するツールを作成するフレームワークを提案
LLMそれ自身のみで、ソースコードをデバッグしたり、新しい課題に対応するツールを開発したりする仕組みは、まさにLLMが知能を持った主体として人間に変わって作業ができる未来が現実になりつつあることを感じます。
講演の最後では、Zhou氏の2人の子供が、まさにLeast-to-most promptingのようなやり取りで姉が弟に算数の解き方を教えていたエピソードが紹介されました。Zhou氏の研究の源となった発想が、人間に対しては当たり前に行なっているアプローチをLLMに適用すること、と語られていたのが印象的です。
また、「LLMの作り方はわかっているが、なぜ機能するのかはわかっていない」とも述べられていました。
Llama 2: Open Foundation and Fine-Tuned Chat Models
Vedanuj Goswami(Meta FAIR), 発表スライド
Goswami氏はMetaが公開しているLLMであるLlama 2の開発メンバーの1人です。講演では、Llama 2の開発プロセスである、事前学習、反復的なファインチューニング、安全性評価をどのように行なっているか、また、その過程で得られた知見について、紹介されました。

そして、今後の挑戦として下記が挙げられており、今後のLLM研究の方向性が示されていました。
より多くのデータ収集、多言語化、マルチモーダル化
何千台規模のGPUエンジニアリング
学習と推論におけるハード、ソフト両面での効率的なアーキテクチャ開発
継続的な学習と知識のアップデート
事実に基づく正確さの向上、出典の明示
ハルシネーションの抑制、不確実性の可視化
有害性、攻撃性、偏見などの排除
学習データを超えて世界の知識への適合
From GLM-130B to ChatGLM
Zhipu AIは中国の清華大学から2019年に生まれたLLM開発のスタートアップ企業で、Zhang氏はそのCEOです。Zhipu AIは、英語と中国語によるバイリンガルの独自アーキテクチャを持ったLLMであるGLM-130Bを開発し、オープンソース化しています。講演では、GLM-130Bのアーキテクチャや開発ノウハウについて紹介された後、GLM-130Bをベースに開発された製品群が紹介されました。中国語タスクのベンチマーク(C-Eval)においては、GPT-4を上回る性能を実現したと報告されており、英語以外の言語のLLM開発に希望を与える内容となっていました。

(発表スライドより)

(発表スライドより)
From Documents to Dialogues: How LLMs are Shaping the Future of Work
Jaime Teevan(Microsoft), 発表スライド
MicrosoftのTeevan氏の講演では、LLMをサービスとして世界へ展開する際の技術トピックについて取り上げられました。
印象的だったのは、多言語対応における英語への翻訳の有効性に関する報告で、日本語は英語に翻訳することによるパフォーマンス低下が実験対象の言語の中で最も悪い結果となっていたことでした。Zhipu AIが中国語LLMで成果を出しているように、日本語LLMも成果を上げられる可能性があるように思えました。

(発表スライドより)
他にも、ユーザーの独自データに基づく応答を実現するためのRAG、差分プライバシーによる学習、チャットログという新しいデータソースの分析と活用法、などのトピックが語られていました。
また、世界展開するにあたり、エネルギー消費の効率化も課題として取り上げられていました。単純にLLMを開発するフェーズとは異なり、LLMをサービスとして、しかもMicrosoftのように全世界の多くのユーザーへデリバリーするフェーズならではの広く総合的な視野での課題認識は、AIを実務で活用しようとする組織において大変参考になるものと思います。
個人的な所感
LLMの規模による創発性や推論性能は、これまで行われていた機械学習モデル開発の常識やそれを担っていたデータサイエンティストの役割を大きく変えるインパクトを持っていると感じました。
まず、モデルの巨大化が必須となることで、膨大な数のパラメータを個別タスクに合わせて事後的に再計算して最適化することはほとんどの組織で現実的ではなくなるように思えます。逆に、少数サンプルによる例示や、考え方の教示など、推論性能を活用したプロンプトエンジニアリングによって個別タスクを解決する方法が現実解として主流になるように思えます。これは、同時に、大量のデータを保有する優位性を失わせることに繋がる可能性があります。
また、AI活用の文脈においては、データ分析とAIエンジニアリングの機能の分化がより進み、AIエンジニアリングの比重が増していくように思えました。
また、LLMの推論性能やツールを作り改良する研究成果からは、人間のような汎用的に近い知能が実現しつつあるように思えてきます。
LLM Dayの講演を聞いて、LLMのさらなる巨大化によって汎用的な人工知能の実現を目指す動きが加速しているように感じました。私たちは、言語を使って思考しているが故に、言語を適切に扱えていると、その背景に適切な知性が存在すると考えてしまいます。LLMの延長で実現する知能は創発性でもたらされる本当の知能なのか、単にそれっぽい言葉を紡ぐだけの存在なのか、個人的には今後の基礎的研究の進展にも期待したいと思います。
いずれにせよ、今後、LLMによって実現する機能は、多くの企業とそこで働く人々に大きな影響を与えるでしょうし、AI研究の動向を把握しておくことがこれまで以上に経営においても大切になると考えられます。
関連記事
一緒に働きませんか
M-AISでは、AI技術を軸に、顧客&データ起点で金融体験をアップデートすることに挑戦してくださる仲間を募集しております。ご興味ございましたら、ぜひこちらの採用情報をご覧ください。
Japan Digital Design 株式会社
M-AIS
VP of Data Science
Motokiyo Hirayama