
文埋め込み・二段階要約・語義の箱埋め込みーNLP2024参加報告②

三菱UFJフィナンシャル・グループの戦略子会社であるJapan Digital Design(JDD)でデータサイエンティストをしている田邊です。
3月11日~15日にかけて神戸で開催されたNLP2024 (言語処理学会第三十回年次大会)に参加してきました。本記事では、個人的に興味深かった3つの発表を紹介させていただきます。
1.平均プーリングによる文埋め込みの再検討:平均は点群の要約として十分か?

文ベクトルとしてBERT出力の平均ベクトルを利用することは、GloVeの平均ベクトルよりも精度が悪い場合があると言われることがありますが、実際に平均プーリングは適切なのかを検証した研究です。
学会参加者からも反響があった内容であり、経験的に感じたことをデータで証明しており、とても面白いと感じました。
サマリ
平均プーリングによって、単語間(点群)の空間的な広がりが消えてしまうことがあるかを確認
※「意味の異なる点群なのに平均が近くなる」問題が実際に起こっているかを確認
結果、最先端のモデルでは発生していないが、他のモデルでは発生していることがわかった

内容
「意味の異なる点群なのに平均が近くなる」問題が実際に起こっているかは、以下の類似度を利用して調べています。
平均の類似度(L2、cosine)
点群の類似度(WMD、WRD)
意味の類似度(人手評価)
※各文ペアに対する上記類似度スコアは、各類似度同士を比較できるように相対順位に基づき 0.0~1.0 の範囲で算出しなおしたものを利用します。
※点群の類似度は、Word Mover’s Distance (WMD)と呼ばれる最適輸送を理論背景として計算される距離を採用しています。
類似度を利用し、「人手評価の類似度≒点群の類似度≪平均の類似度」がどの程度存在するかを確認することで、「意味の異なる点群なのに平均が近くなる」ものを確認しています。
問題が起こっているかは、STS Benchmarkの訓練データを使用し、以下の4つのモデル(word2vec、Sent2Vec、BERT、Sentence-BERT)で確認しています。

結果、最先端のモデルでは発生していないですが、他のモデルでは発生していることが確認できます。
なぜこれが起こるかはfuture workということで、とても楽しみです。

また、実は点群ではなく平均で要約する方が良い場合が半分程度も存在する、という言及もありました。こちらもfuture workとして挙げられており、とても興味があります。
(参考資料)
「言語処理学会 ANLP YouTube Channel」にて、点群距離の背景にある理論や最適輸送について、分かりやすく噛み砕いて説明している動画です。
2.大規模言語モデルを用いた二段階要約におけるhallucinationの分析

実務で要約を利用する際に、活用できる点がないか気になり興味を持ちました。
特に長文の要約では、要約根拠も利用者が確認できると嬉しいです。それらの取り組みやその際のハルシネーションについてとても勉強になりました。
サマリ
要約時の根拠が分かるように要約を生成し二段階要約した場合、ハルシネーションはどうなるか?を検証
全体的に二段階要約によってハルシネーションは増加
多数のLLMでの検証により、既存研究では見えていなかった知見を発表
内容
要約には大きく分けて以下の2種類があり、それぞれメリット・デメリットがあります。
①abstractive summary(抽象型要約)
一般的にイメージする要約。
メリット:自然な表現。冗長性が低い。文字数の自由度が高い。
デメリット:ハルシネーションが起こりやすい。解釈可能性が低い。
②extractive summarization(抽出型要約)
元の文章を利用し抽出して、文章を短く表現すること。
メリット:ハルシネーションが起こりにくい。元の文章が利用されるため解釈可能性が高い。
デメリット:自然ではない表現。冗長性が高い。文字数の自由度が低い。
先行研究では、両者のメリットを生かす目的で二段階要約(抽出→抽象)を行う研究がありますが、ハルシネーションに関しての研究はまだまだ少ないそうです。そのため、本研究では、多様なLLMを活用し、長文に対しての二段階要約を行った際のハルシネーションを検証しています。
ハルシネーションの評価としては、要約に書かれた内容が入力文書(要約前の文章)に包含されているかで評価しており、評価は以下の比較的新しい2023年に発表された評価モデルを利用し、自動評価で行っています。
AlignScore(カリフォルニア大学サンディエゴ校)、RoBERTa-largeを追加学習したモデルで評価する方法
TrueTeacher(Google)、T5を追加学習したモデルで評価する方法
G-Eval(Microsoft)、評価用プロンプトを利用してGPTで評価する方法
検証の結果、全体的に二段階要約によって、抽象型要約のみの場合と比較してハルシネーションが増加することがわかりました。ただし、周辺文脈を抽出し前後数文も含めてモデルに入力することで、ハルシネーションを抑制できるという発見について追加検証を行っています。

要約の根拠を利用者に示せると嬉しいですが、抽出を挟むことでハルシネーションが増加してしまうという結果はLLMを利用した要約の難しさを感じました。
(参考資料)
NLP2024の発表ではないですが、似たテーマで、「どのLLMが最も長文要約性能が高いのか評価した実験結果」という論文解説記事があり、以下抜粋を載せています。
実はLLMによる要約は、短編小説、詩、脚本など、物語の分野で研究が進んできました。その中で、LLMが長い文脈を一貫性を持って要約することができることなどが確認されてきました。しかし、それ以上の詳細な評価は今回が初めてだと言います。
まだまだ分からないことが多い分野だという点と、紹介論文のような包括的な検証を行っていただきとても有難いと改めて感じました。
3.語義の箱埋め込み学習とその応用

「箱埋め込み」という概念に初めて触れましたが、箱埋め込みを利用することで語義間の上位下位関係を直観的に理解・定式化できる点や、新語義の上位語義推定など、新たな学びが多くこういったものがあることに感動しました。
また、新語義の判定や新語義の上位語義が推定できる点は、銀行の専門単語などについても理解できるかなど興味がありました。
まだまだ理解不足なため、今後勉強していきたいと思います。
サマリ
語義曖昧性解消(Word Sense Disambiguation、WSD)の問題に対し、語義の箱埋め込みを学習する手法を提案
低頻度語義にも強いMetricWSDを応用し、語義の箱埋め込みを学習することで新語義や新語義の上位語義の推定にも対応できるモデルを提案
3つのタスク(WSD、新語義判定、新語義の上位語義推定)で評価し、データセットによってはベースラインを上回る精度となった
内容
WSDの従来のモデルの課題に、低頻度語義に対する精度が低いことや、新しい語義には対応できない点があります。それらを解消するために紹介論文では以下2つの関連研究を参考にして、MetricWSDを語義の箱埋め込みを学習するように拡張することで、3つのタスク(WSD、新語義の判定、新語義の上位語義の推定)に対応できるモデルを提案しています。
Few-shot Learningと呼ばれる数例だけで学習できる手法を利用したモデル(Prototypical Networks)をベースとし、MetricWSDモデルを提案
低頻度語義に対するWSDの性能が低い点を解消
単語の上位下位関係(タクソノミ)を箱埋め込みを用いて行う手法を提案
モデル概要図は以下です。
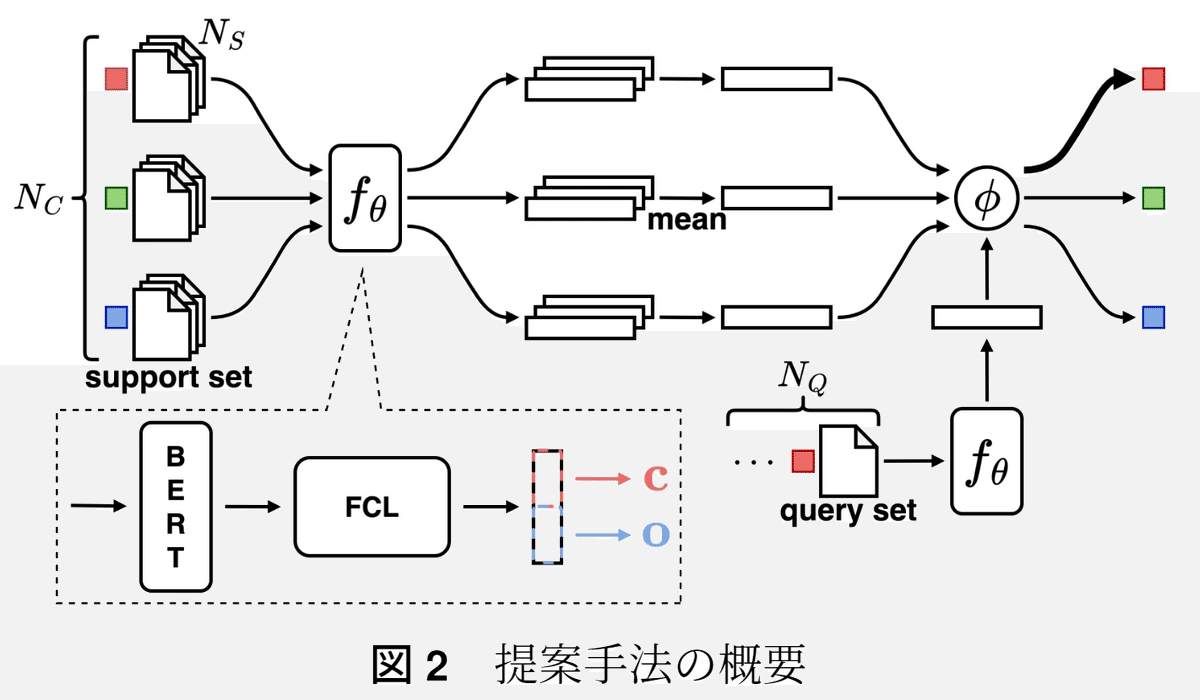
紹介論文の特徴としては、損失関数の計算に箱埋め込みを利用することで単語の上位下位関係(タクソノミ)を考慮できる点です。
損失関数(式(2))では、クエリ表現の箱埋め込みb𝑥と各プロトタイプ表現の箱埋め込みb𝑦のペア (b𝑥 , b𝑦 ) を利用し、クエリ表現b𝑥が各プロトタイプ表現b𝑦を包含する確率を元に損失関数を計算しています。


式(1)は、箱埋め込みの包含関係を表現しており、アイテム 𝑥 の箱埋め込み b𝑥、アイテム 𝑦 の箱埋め込み b𝑦、とした場合の、アイテム 𝑥 がアイテム 𝑦 を包含する確率を表します。Vol は箱の体積を計算する関数です。
紹介論文のモデルはエピソード別(正例と負例の選び方別)に2つのモデル(ProtoBox Sr、ProtoBox Sn)を作成しています。
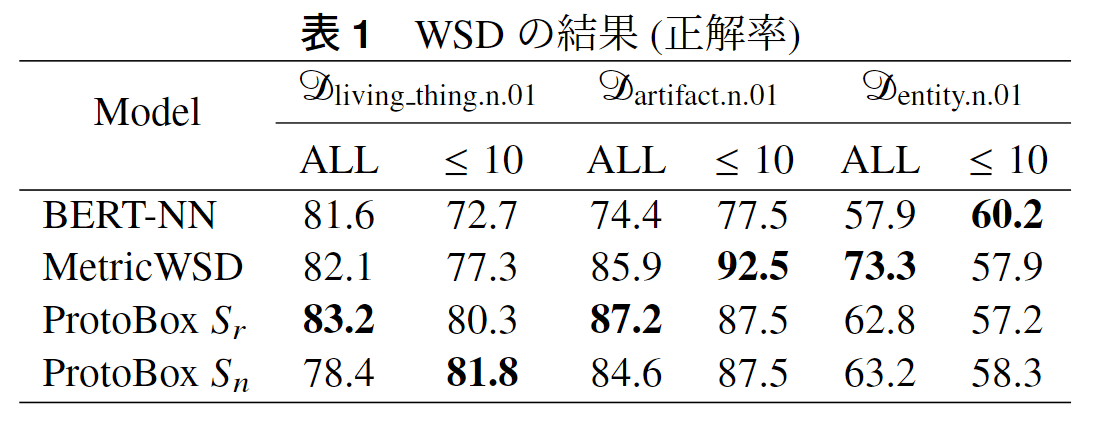
各タスクにおけるモデル精度はデータセットによって異なっており、今後もエピソード作成の工夫などをfuture workとして挙げられていますが、紹介論文の特徴である上位語義推定では小規模なデータセットにおいてベースラインを上回っており、有効性を感じました。
(引用:https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/A10-5.pdf)


(引用:https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/A10-5.pdf)
(参考資料)
語義曖昧性解消について、「NLPコロキウム YouTube Channel」での参考動画です。
箱埋め込みについても、以下の記事は非常に参考になります。
→ 円などでは無く箱にするメリットは、単語の重なりや広がりをより簡単に計算・表現できる点の様です。
感想・まとめ
今回言語処理学会に初めて参加しましたが、学会で発表されている方々の研究はとても勉強になり、刺激を受けました。質疑応答も積極的に行われており、5日間の参加を通してとてもオープンでプロフェッショナルなマインドを皆さまから感じました。
また、各会の運営やslackの構成など、運営の方々のきめ細かな配慮を感じ、感動しました。懇親会初心者ツアーという企画もあり、実際に私も参加させていただき、関係者の皆さまにも大変感謝しています。
NLP2024の論文は一般にも公開されているので、参加できなかった方も是非ご覧いただけたらと思います。なお、過去の言語処理学会の資料も検索すると参照できます。
関連記事
JDDより、共にNLP2024に参加したメンバーの記事です。ぜひ、こちらもご覧ください。
一緒に働きませんか
Japan Digital DesignのMUFG AI Studio(以下M-AIS)では、AI技術を軸に、顧客&データ起点で金融体験をアップデートすることに挑戦してくださる仲間を募集しております。
ご興味ございましたら、ぜひこちらの採用情報をご覧ください。
Japan Digital Design 株式会社
M-AIS
田邊