
ICAIF 2023 参加報告(前編)

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)にて、MUFG AI Studio(以下M-AIS)に所属し、データサイエンティストをしている井本です。
11月27日から29日にかけてニューヨークで開催された、金融領域での国際学会「ICAIF 2023」に参加しました。
本記事と次回で2回に分けて、興味深かった発表についてご紹介します。
第1回目の本投稿では下の目次に沿って、学会概要と発表紹介をします。記事を読んで、学会や研究内容への興味、また弊社への興味を持っていただけたら幸いです。
ICAIF 2023について
ICAIFは、米国のコンピュータサイエンス分野の学会であるACMの金融分野の分科会です。新しい理論・手法研究もありますが、他の国際学会に比べビジネスへの応用研究が多いです。金融機関の参加者も多く、特にJP Morgan Chase (以下JPMC)はプラチナスポンサーであり、かつ会場提供もしているため、参加者も多かったように思います。

2023年は、3日間で以下について発表があり大変充実していました。
4本のKeynote
Accepted Paperは、本会議が27本、その他(ポスター・ワークショップ)が72本
8種類のWorkshop
4本のコンペ(今年初めて開催)
2本のチュートリアル
全体の印象としては、
言わずもがなですが、金融分野においてもLLMの業務適用へのトライが進んでいると感じました。Keynoteでは、Blackrockが投資対象選定時にどのようにLLMを使っているかのプレゼンがあり、JPMC社員によるパネルでは、LLMのリーガル対応の大変さが話し合われていました。また、2本のチュートリアルはいずれもLLM関連でした。
今年に関しては、その他では大きなトレンドを生んでいるトピックはないように感じました。Paper発表はLLMが特別多いわけでもなく、GANや時系列予測、ネットワーク分析など、トピックは満遍なく多岐に渡っていました。 余談ですが、プログラムでGAN研究をGenAIと略されており、最初LLMの事だと思っていました。
LLM関連の研究・業務活用
BlackrockによるKeynote
Factors, Sustainable and Solutions部門のヘッドを務めるAndrew Ang氏が、Private EquityとESGの領域でのLLM活用事例を紹介しました。
LLMを用いた言語横断の情報抽出
Blackrockでは2000年代からテキストのセンチメント分析を開始したそうです。Bag-of-Wordベースの第一世代モデルを開発し、その後しばらくWord2Vecベースのモデル改良が続き、現在はLLMベースとのことでした。印象的だったのは「LLMを使う事で、シャープレシオが2倍になった」と仰っていたことでした。0.5が1になったのか1が2になったのか発射台は分かりませんが、Ang氏はLLMの有用性を強調していました。
Private Equityの具体的なLLM活用例として、ローカル言語で書かれた非公開企業に関する記事から、LLMに、企業スコアと要因を生成させる話がありました。また、求人数データは非公開企業のカバレッジが大きく、企業の勢いを測るのに有益だそうです。

投資テーマ探索
データドリブンな(テーマ投資の)テーマ探索も行っているそうです。
年間100万記事以上の金融ニュース
四半期に5,000社以上の決算報告書
1,000以上のテーマファンドなど
テキストデータを用いて、キーテーマを抽出し、アナリストセンチメント、バリュエーションなど複数観点の評価を経て、総合評価しています。トピックには流行り廃りがあるので月一で更新しており、金融ならではのダイナミックなビッグデータ分析で面白そうだなと思いました。
グリーン関連特許テキスト分析
SDGs関連でグリーン投資(環境問題に配慮した経済活動への投資)に関するLLM活用もありました。グリーン関係の特許を取得している会社を見つけることで、気候関連の投資機会を発見するというものでした。特許出願書類のテキスト分析ですが、出願書類にある会社名(子会社が申請したものなどもある)と対応する銘柄名を紐づけるのが時に大変だそうで、データ分析に関わるものとして非常に共感できるコメントでした。
LLM Instrcution Tuning+RAGを用いた金融センチメント分析
Adelaide大学、Columbia大学、Brown大学の著者たちによるLLMの活用事例を紹介します。
上段で紹介したBlackrockでの活用例でも分かるように、金融ドキュメントのセンチメント分析は非常に重要です。著者は以下の2点を課題として挙げました。
LLMはセンチメント分析を解くために最適化されていない
ニュース速報やTweetなど短く不完全なテキストだと、センチメントを出すには背景知識が必要になる
当該論文では、上記の1,2を各々、Instruction TuningとRAG (Retrieval Augmented Generation)で解決を試みました。
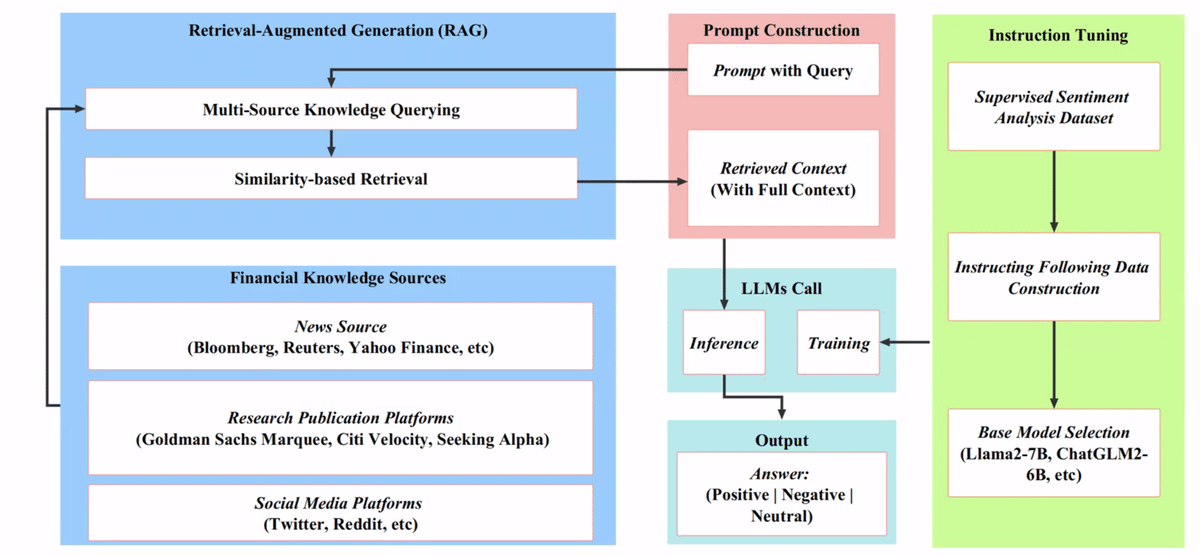
引用:https://github.com/AI4Finance-Foundation/FinGPT/tree/master/fingpt/FinGPT_RAG
Instruction Tuningは、ChatGPT登場時にSupervised Fine-Tuning(教師ありファインチューニング)と呼ばれていた学習手法です。LLMを活用したいユースケースで、想定される「入力テキストと返答(出力)テキストのペア」を学習データとして用意し、LLMに写経(学習)させます。仮に学習データにない入力テキストだとしても、LLMは事前学習で得た知識を使い、Instruction Tuningで得た返答の仕方でもって、好ましい返答を出力します。
金融センチメント分析のデータセットでは、正解ラベルは分類クラスです。適宜テキストに変換してInstruction Tuningに用い、LLMをセンチメント分析にチューニングします。
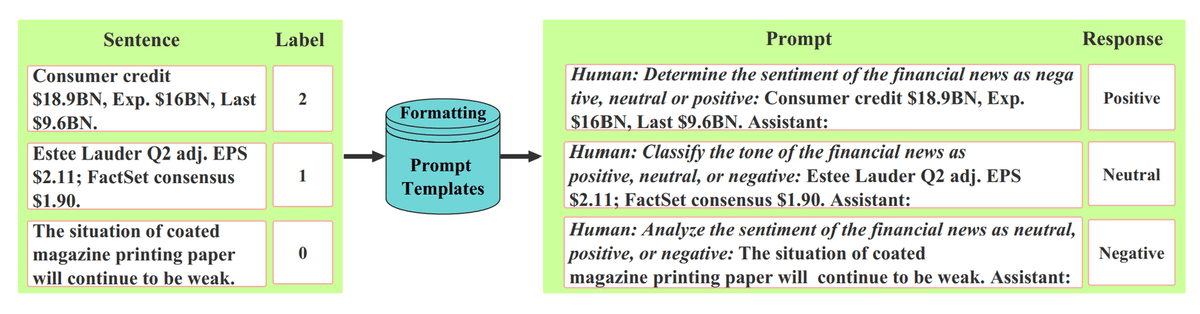
引用:https://github.com/AI4Finance-Foundation/FinGPT/tree/master/fingpt/FinGPT_RAG
課題2では、ニュース速報やTweetの背景知識の必要性に言及しました。LLMは最新のニューストピックについて事前学習できていないので、素のLLMでは、これらにいつでも正しくセンチメントを付与することはできません。RAGは、外部知識データベースから必要なテキストを抽出しLLMに参考情報として与える事で返答精度を向上させる技術です。
当該研究では、RAGのデータベースとして、最新のニューストピックへのアクセスが可能な「ニュースデータ」「リサーチレポート」「SNS」の3種類を活用します。例えばBloombergなどニュースデータでは、検索クエリに対して、サイト内検索を利用して関連ニュースを抽出しています(スクレイピング規制は気になる所です、、)。
次に、複数のデータベースから抽出したテキストの中から検索クエリと特に類似度が高いテキストを見つけます。類似度は単語の完全一致の割合で算出します(Szymkiewicz - Simpson係数)。類似度が閾値を超えるテキストだけ参考情報として、(Instruction Tuningされた)LLMに与えます。

引用:https://github.com/AI4Finance-Foundation/FinGPT/tree/master/fingpt/FinGPT_RAG
実験はFPBとTwitterデータセットで実施されました。提案手法(Ours)に対し、汎用LLM (ChatGPT 4.0, Llamaなど)や、金融特化LLMであるBloombergGPT、金融センチメントにファインチューンしたFinBERTと比較しました。

(引用:https://arxiv.org/abs/2310.04027)

(引用:https://arxiv.org/abs/2310.04027)
RAGなしで提案手法がFinBERTに勝っていたことや、RAGを使えばFinBERTに比べF1が約20%向上したことは魅力的だなと感じました。Instruction Tuningでなくて、LLMに分類ヘッド(Classification Head)を加えて分類タスクのファインチューンした場合と、どちらが高い精度なのか?は気になりました。もし、どなたか試したらご一報いただけると幸いです!
なお、FinGPT_RAG にコード公開されていますので、ご興味ある方は是非ご覧ください。
技術的に興味深かった発表
Topological Portfolio Selection and Optimization
University College London所属の著者によるBest Academic Paper Runner-up(ICAIFの論文賞の1つ)を受賞した研究となります。
Markowitzのポートフォリオ最適化は(複数株式などからなる)ポートフォリオの各銘柄の割合を最適化する問題です。その計算には各銘柄の株価リターンの共分散行列を用います。金融時系列分析が難しい理由の1つはノイズが大きい事(S/Nが小さい)です。従って共分散行列にもノイズが含まれ、ノイズ除去が精度向上のためにも必要になります。先行研究では、各銘柄をノードに相関係数をエッジに見立て、銘柄間の関係をグラフで表現し些末なエッジを削除することでノイズ除去を実現するものがありました。また、グラフ上の周辺銘柄の情報を使うと、より分散が効き高パフォーマンスのポートフォリオを作ることができます。著者たちがIFN (Information Filtering Network)と呼ぶ手法ですが、既存手法はトポロジー(グラフの形)に制限を付けなければならず、それが新たなノイズとなってしまう問題がありました。
IFNの簡単な例として、最小全域木(Minimum Spanning Tree, 以下MST)があります。重みが大きいエッジを除去してシンプルな木に変換します。下図でも分かるように、MSTは閉路(cycle)が存在しないグラフで、これがトポロジーへの制限となります。

当該論文では、その問題を緩和すべく、SR-IFN (Stationary Robust IFN)という手法が提案されました。通常のIFNでは、元リターンデータ全部を使って相関行列を算出しそれをグラフとして扱います。一方SR-IFNでは、元リターンデータから複数(下図では3なので、以下3で話を進める)回にわたりブートストラップ法(重複を許しランダムにサンプル抽出する方法)でサンプル集合を抽出します。それぞれでIFNを適用して3個のグラフを得ます。3個のグラフの中で重みの平均が低いエッジ = 重要でないとみなし除去して、最終的なグラフを得ます。
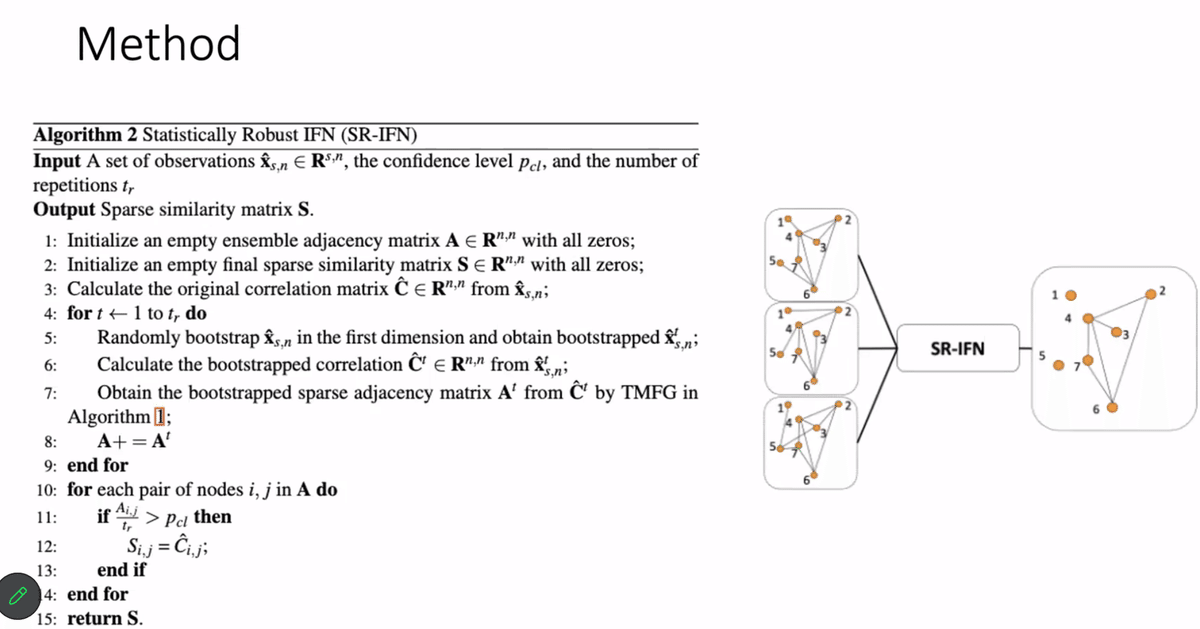
(引用:https://dl.acm.org/doi/abs/10.1145/3604237.3626875)
さて、銘柄関係を埋め込みノイズ除去したグラフを得る事ができました。このグラフからどうやって、ポートフォリオ戦略を構築するのでしょうか?当該論文は、ポートフォリオ組み入れ銘柄の選定と、各銘柄の重み決定の2段階で構築しています。
組み入れ銘柄は、他銘柄と相関の低い銘柄を組み入れたいため、(基本的には)グラフでどのノード(銘柄)ともつながらないノード(銘柄)だけとします。
銘柄の重みは、グラフ中心性(銘柄のグラフの中での重要度を定量化したもの)に反比例する形で決定します。ブートストラップ法で作った3つのグラフでそれぞれグラフ中心性を計算し平均を取ります(ですので、SR-IFNの結果どこともつながらない銘柄であっても重みを計算することができます)。
実験は、NASDAQ, FTSE, HS300(ハンセン指数)の3指数の構成銘柄で実施されました(正確には50銘柄と100銘柄に絞った2パターンの平均の結果)。2010~2016年で学習し、2017~2020年でテストした結果を載せています。行は上から「年率リターン」「年率標準偏差」「シャープレシオ」「マックスドローダウン」です。

(引用元:https://dl.acm.org/doi/abs/10.1145/3604237.3626875)
まず、シャープレシオを見ると3市場全てで、SR-IFN(PTPとL/Hの差)と中心性による銘柄の重み(PTP+CBCとPTPの差)が、どちらも精度向上に寄与していることがわかります。また、マックスドローダウンも、FTSE以外は、L/Hに比べ提案手法が提言していることが分かります。
感想としては、ネットワークの局所性から重み計算するのが面白いと感じました。当該論文では重み計算式を経験的に設計していると考えています。これを、例えば平均分散最適化のように運用成績の関係指標に紐づくように最適化出来たらより面白いと思いました。
余談ですが、記事執筆途中で、上記結果には典型的なMarkowitz最適化との比較がない事に気づきまして、どうなっているのか?非常に気になりました。こちらも、どなたか試したらご一報いただけると幸いです!
ビジネス的に興味深かった発表
VanguardによるKeynote
投資モデルとレコメンドというワークショップで、Vauguardでシニアリサーチャーを務めるThomas J. De Luca氏が、同社でのレコメンドモデル活用事例を紹介しました。
同社では、ファイナンシャルアドバイザーが顧客と面談する際に「どのような会話トピックを持ち掛けるべきか?」のレコメンドモデルを利用しています。トピックは例えば「家計支出、家、投資、税金、健康」などです。
モデルは、各顧客との会話履歴から、次の面談で顧客が興味ありそうなトピックをレコメンドします。学習データは「顧客番号(u)、会話トピック(t)、面談時に話したことがあるか?(y=1 or 0)」です。
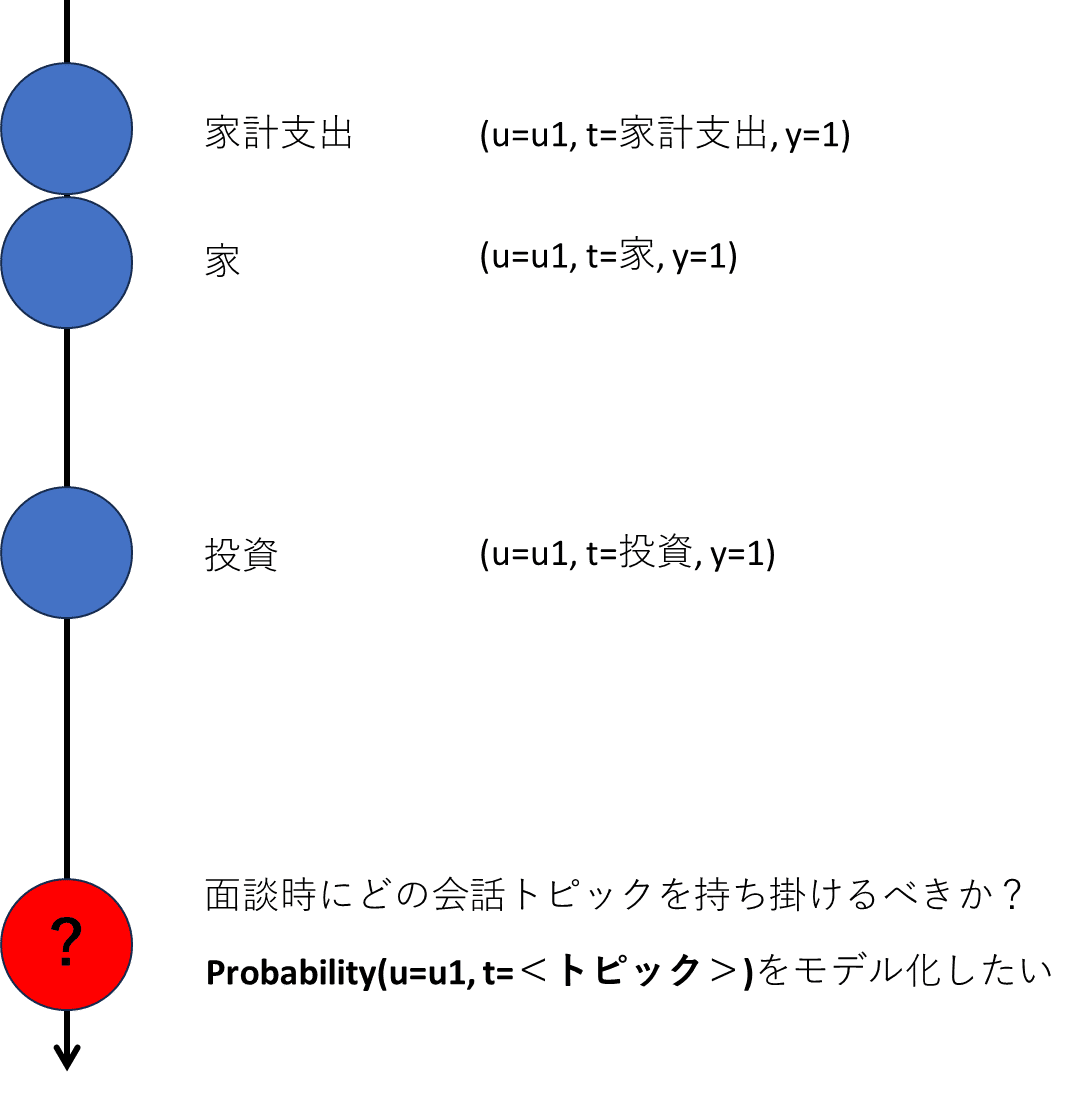
さて、学習データもそろったので、深層学習モデルを作ってしまえば一件落着でしょうか。いえ、このままでは会話履歴のない顧客へのレコメンドに困ってしまいます(コールドスタート問題と言われレコメンドシステムで一般的な問題です)。これを緩和すべくVanguardでは顧客属性情報を追加しています。こうすることで、会話履歴のない顧客でも属性情報さえあれば、似たような属性情報を持つ顧客のトピックデータから、尤もらしいトピックのレコメンドができるようになります。
最終的なモデルアーキテクチャーは下図になります。各要素をベクトルに埋め込み、それらを結合して、MLP層に入力してレコメンドスコアを算出するという、非常にシンプルなものとなっています。

弊社でも、レコメンドシステムの新規技術調査・検証活動を行っており、ご興味ある方は
をご覧頂ければと思います。
まとめ
本稿では、ICAIF2023で筆者がビジネス的・技術的に興味をもった発表を紹介しました。LLMに関しては、紙面の都合で2発表を取り上げましたが、他にも多くの実務応用研究がありました。元論文集になりますがこちら をご覧いただくと、活用例からアイデアのヒントが思いつくかもしれません(一定期間経つと削除されると聞いているのでご注意ください)。
また技術的にも参考になる研究がいくつかあり、発表者の熱量を肌で感じたので、私自身刺激を受けました。
関連記事
一緒に働きませんか
M-AISでは、AI技術を軸に、顧客&データ起点で金融体験をアップデートすることに挑戦してくださる仲間を募集しております。ご興味ございましたら、ぜひ採用情報をご覧ください。
この記事に関するお問い合わせはこちらにお願いします。