
Mlflowを利用したRAGのトレースと生成結果の評価 on Databricks

こんにちは。三菱UFJフィナンシャル・グループ(MUFG)の戦略子会社であるJapan Digital Design(JDD)に所属し、独自のAI技術によりMUFGに競争優位性をもたらすことをミッションとしたMUFG AI Studio(M-AIS)でデータサイエンティストをしています、田邊と申します。
はじめに
この記事は、DatabricksでMlflowを利用したRAGのトレースと評価を行う方法について記載しています。
Mlflow Tracingのドキュメントには記載がたくさんありますが、重要な機能やコンセプトをミニマムなコードで理解できるようにと思い、自分の備忘も兼ねて記載しております。
開発環境は以下となります。
Databricks on AWSを利用
RAGの構築にはAzureのAzure AI SearchとAzure OpenAIを利用
RAGとは
RAG(Retrieval-Augmented Generation)とは、情報検索(retrieval)と大規模言語モデル(LLM)での生成(generation)を組み合わせたモデルアーキテクチャです。
ユーザからの質問(例:RAGとは?)に対し、データソース(例:Wikipedia)から情報を検索し、その情報をもとに回答を生成する仕組みです。
RAGは外部のデータソースを活用することで、モデルが持つ知識の範囲を超えてより多くの情報にアクセスし回答することができます。
Mlflowとは
Mlflowは、機械学習のライフサイクルを管理するためのオープンソースのプラットフォームです。
主な機能は公式ドキュメント(MLflow Overview)に記載されており、いくつかピックアップすると以下のようなものがあります。

今回は、RAGのトレースにMlflow tracing、生成結果の評価(LLM-as-a-judge)にはMLflow LLM Evaluationを利用します。
Mlflow tracingとは
Mlflow tracingとは、MLflow 2.14.0から利用可能となった機能で、GenAIアプリケーションの監視・分析・デバック用に作られた機能です。
langChainやOpenAIの自動ログ機能や、自作関数や外部関数の入出力や実行時間を記録できる機能があり、GenAI以外にも便利そうな機能です。(Introduction to MLflow Tracing)
Mlflow tracingにはTrace、spanという新しい概念があり、以下の階層構造になっています。
mlflwo experiment_id
|- run_id
|- request_id: traceの単位(複数spanが実行順に保存)
|- span: spanの単位(各span(関数)の入出力が保存される)Traceという概念
各spanの流れを追えるようにする仕組み
実行順にspanがログされたもの
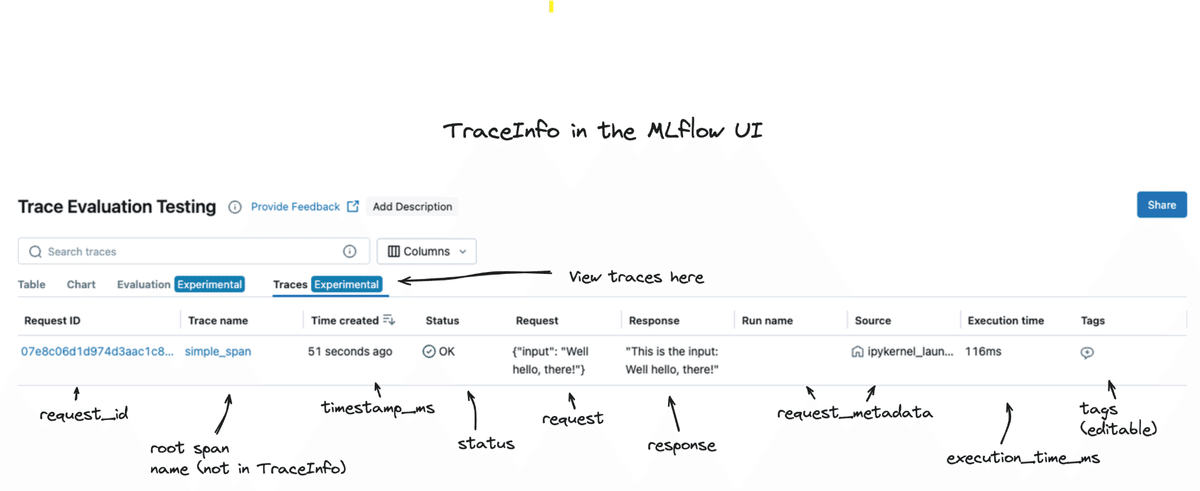
spanという概念
1つの管理・確認・ログしたい単位
入力、出力、実行時間、等が保存される
親スパン、子スパンなどを作ることができる
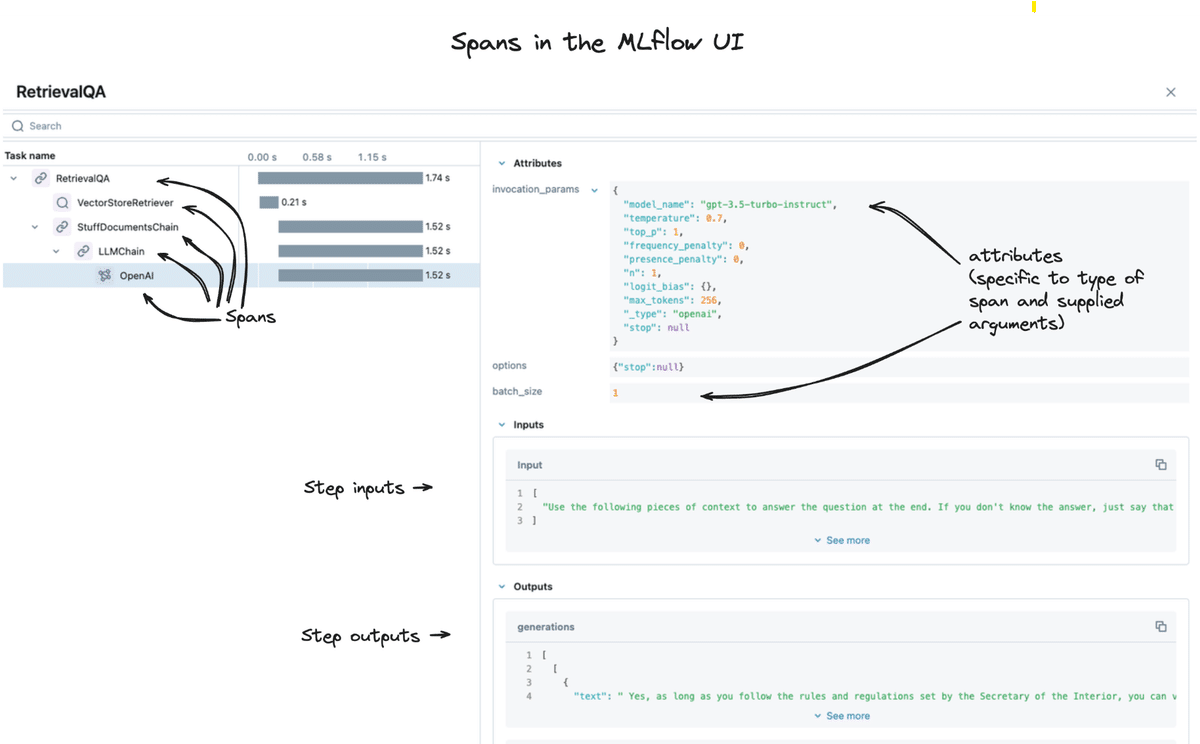
Mlflow tracingの実装方法にはいくつか種類がありますが、ここでは割愛させていただきます。詳細は弊社吉竹記載のnote記事(Databricksで始めるLLMOps - MLflowを使ったトレース)をご参照ください。
今回RAGをトレースする際に利用する実装コードは以下2つです。
自作関数をトレースするために、デコレータ(@mlflow.trace())を設定しています。関数の入出力と実行時間が保存されます。
外部関数をトレースするために、関数をmlflow.trace()でwrapし、同様に入出力等を保存しています。
# --------------------------------------------
# 外部関数トレースの例
# --------------------------------------------
# トレース前のコード
response = openai.chat.completions.create(
model=deployment_id,
messages=messages,
**settings,
)
# トレース後のコード
# openai.chat.completions.createをmlflow.trace()でwrap
openai_client_wrap = mlflow.trace(openai.chat.completions.create)
response = openai_client_wrap(
model=deployment_id,
messages=messages,
**settings,
)MLflow LLM Evaluationとは
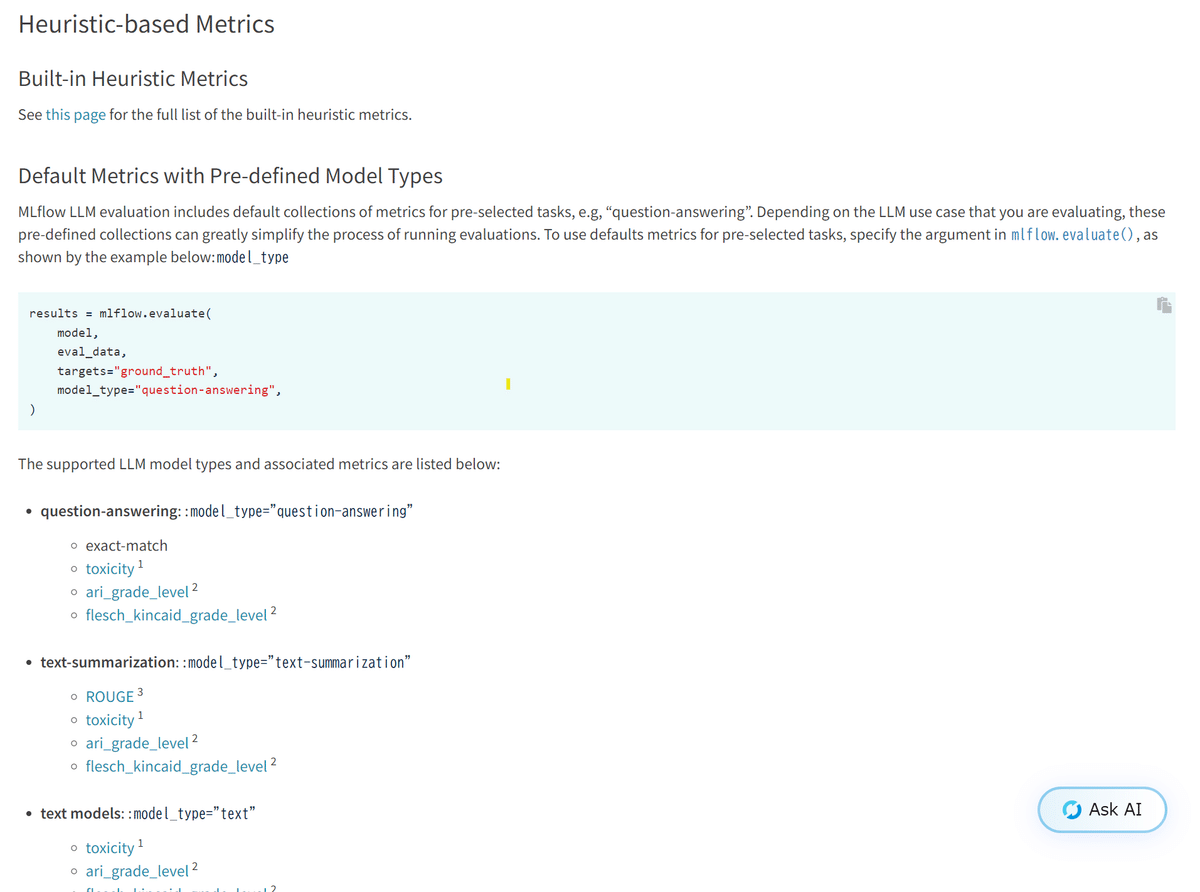
MLflow LLM Evaluationとは、LLMの生成結果を評価する機能で、Heuristic-based metrics(ROUGEスコア等)やLLM-as-a-Judge metricsなどが簡単に実装・保存できます。今回はLLM-as-a-Judgeを利用して生成結果を評価します。
LLM-as-a-Judgeについては、後続の実装コードの項目で紹介するため、ここではHeuristic-based metricsの種類を載せています。タスクに合わせて、ROUGEや学習済みモデル等を利用して評価を実施してくれます。
RAGのトレース(実装)
実際にMlflowでRAGモデルをトレースしていきます。
1.必要なパッケージ等のインストール
!pip install azure-search-documents==11.6.0b1 openai==1.35.0 mlflow==2.18.0from azure.core.credentials import AzureKeyCredential
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
ComplexField,
SimpleField,
SearchFieldDataType,
SearchableField,
SearchIndex
)
import mlflow
from dataclasses import dataclass
from typing import (
List,
Optional,
)
import openai Azure AI SearchとAzure OpenAIに必要な変数を設定します。
AZURE_OPENAI_KEY = <Azure OpenAIのキー>
AZURE_OPENAI_ENDPOINT = <<Azure OpenAIのエンドポイント>>
AZURE_AI_SEARCH_KEY = <Azure AI Searchのエンドポイント>
AZURE_AI_SEARCH_ENDPOINT = <Azure AI Searchのキー>2.インデックスの作成
# --------------------------------------------
# インデックスの定義と作成
# --------------------------------------------
# インデックスのスキーマを作成
credential = AzureKeyCredential(AZURE_AI_SEARCH_KEY)
index_client = SearchIndexClient(
endpoint=AZURE_AI_SEARCH_ENDPOINT, credential=credential
)
# 今回は以下のフィールド(インデックスに登録する項目)を設定しています。
fields = [
SimpleField(name="index_key", type=SearchFieldDataType.String, key=True),
SimpleField(name="chunk_id", type=SearchFieldDataType.String),
SearchableField(
name="chunk", type=SearchFieldDataType.String, analyzer="ja.lucene"
),
]
# インデックス名を指定し、インデックスを作成します。
index_name = "advent_calender_index"
scoring_profiles = []
index = SearchIndex(
name=index_name,
fields=fields,
scoring_profiles=scoring_profiles,
)
result = index_client.create_or_update_index(index)# --------------------------------------------
# インデックスに資料を登録
# --------------------------------------------
# 資料を定義
documents = [
{
"index_key": "1",
"chunk_id": "document_A_page_1",
"chunk": "機械学習(ML)の世界に足を踏み入れることはエキサイティングな旅ですが、多くの場合、それには時間がかかります イノベーションと実験を妨げる可能性のある複雑さ。MLflow は、このダイナミックなランドスケープにおけるこれらの問題の多くに対するソリューションであり、ツールを提供し、プロセスを簡素化することで合理化します MLのライフサイクルと、ML実務者間のコラボレーションを促進します。",
},
{
"index_key": "2",
"chunk_id": "document_A_page_2",
"chunk": "機械学習(ML)プロセスは複雑で、データの前処理からモデルのデプロイや監視まで、さまざまな段階で構成されています。 このライフサイクル全体で生産性と効率性を確保するには、いくつかの課題があります。MLflow は、ML ライフサイクル全体に合わせた統合プラットフォームを提供することで、これらの課題に対処します。その利点は次のとおりです。",
},
{
"index_key": "3",
"chunk_id": "document_B_page_1",
"chunk": "MLflow は汎用性が高く、さまざまな機械学習シナリオに対応しています。一般的な使用例を次に示します。実験の追跡: データ サイエンス チームは、MLflow の追跡を利用して、特定のドメイン内の実験のパラメーターとメトリックをログに記録します。MLflow UI を使用して、結果を比較し、ソリューション アプローチを微調整できます。これらの実験の結果は、MLflow モデルとして保持されます。モデルの選択とデプロイ: MLOps エンジニアは、MLflow UI を使用して、最もパフォーマンスの高いモデルを評価し、選択します。選択したモデルは MLflow レジストリに登録され、実際のパフォーマンスを監視できます。モデルのパフォーマンス監視: デプロイ後、MLOps エンジニアは MLflow レジストリを使用してモデルの有効性を測定し、ライブ環境内の他のモデルと並べて表示します。共同プロジェクト: 新しいベンチャーに着手するデータ サイエンティストは、MLflow プロジェクトとして作業を整理します。この構造により、共有やパラメータの変更が容易になり、コラボレーションが促進されます。",
},
]
# 資料をインデックスに登録
search_client = SearchClient(
endpoint=AZURE_AI_SEARCH_ENDPOINT, index_name=index_name, credential=credential
)
try:
result = search_client.upload_documents(documents=documents)
print("Upload of new document succeeded: {}".format(result[0].succeeded))
except Exception as ex:
print(ex.message)3.検索と生成に利用する関数を準備(mlflow tracingを利用)
自作関数には@mlflow.trace()、外部関数はラップしてトレースしています。
# --------------------------------------------
# 検索と生成用の関数を準備
# --------------------------------------------
@dataclass
class Document:
index_key: Optional[str]
chunk_id: Optional[str]
chunk: Optional[str]
@mlflow.trace()
def azure_search(query: str) -> List[Document]:
"""
Azure AI Searchを利用して検索(テキスト検索)
"""
results = search_client.search(
search_text=query, search_fields=["chunk"], include_total_count=True
)
return results
@mlflow.trace()
def get_sources_content(results: List[Document]) -> list[str]:
"""
Azure AI Searchの結果を生成時に与えるコンテンツ情報に整形
"""
sources_content = [doc["chunk_id"] + ": " + doc["chunk"] for doc in results]
return sources_content
def azure_chat(messages):
"""
Azure OpenaAIを利用して回答を生成
"""
api_version = "2024-06-01"
openai_client = openai.AzureOpenAI(
api_key=AZURE_OPENAI_KEY,
api_version=api_version,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
)
deployment_id = "gpt-35-turbo"
settings = {
"temperature": 0.0,
"max_tokens": 1000,
"top_p": 1.0,
"frequency_penalty": 0.0,
"presence_penalty": 0.0,
"seed": 42,
}
# 外部関数をwrap
openai_client_wrap = mlflow.trace(
openai_client.chat.completions.create,
name="openai_client.chat.completions.create",
)
response = openai_client_wrap(
model=deployment_id,
messages=messages,
**settings,
)
return response4.Mlflowへの保存(RAGのトレース)
with mlflow.start_span() as span:を利用することで、関数の入出力以外にも、自由にデータを保存することができます。今回はspan.set_inputs()、set_outputs()で保存しています。
span.set_inputs()、set_outputs()で保存しなくても各関数のトレースで同様の内容はログされていますが、後々保存したログを取得しやすいため今回設定しています。
experiment_id = "xxx"
queries = ["mlflowとはなに?", "mlflowのメリットは?"]
with mlflow.start_run(experiment_id=experiment_id) as run:
for num, query in enumerate(queries):
with mlflow.start_span() as span:
# 情報検索(retrieval)
results = azure_search(query)
# 生成(generation)
sources_content = get_sources_content(results)
content = "\n".join(sources_content)
new_user_content = query + "\n\nSources:\n" + content
messages = [
{"role": "user", "content": new_user_content},
]
response = azure_chat(messages)
# 手動でmlflowに保存
span.set_inputs({"query": query, "messages": messages})
span.set_outputs(
{
"response": response,
}
)5.mlflowの保存結果
Traceのタブの初期表示では、span.set_inputs、span.set_outputsで保存した内容が表示されています。
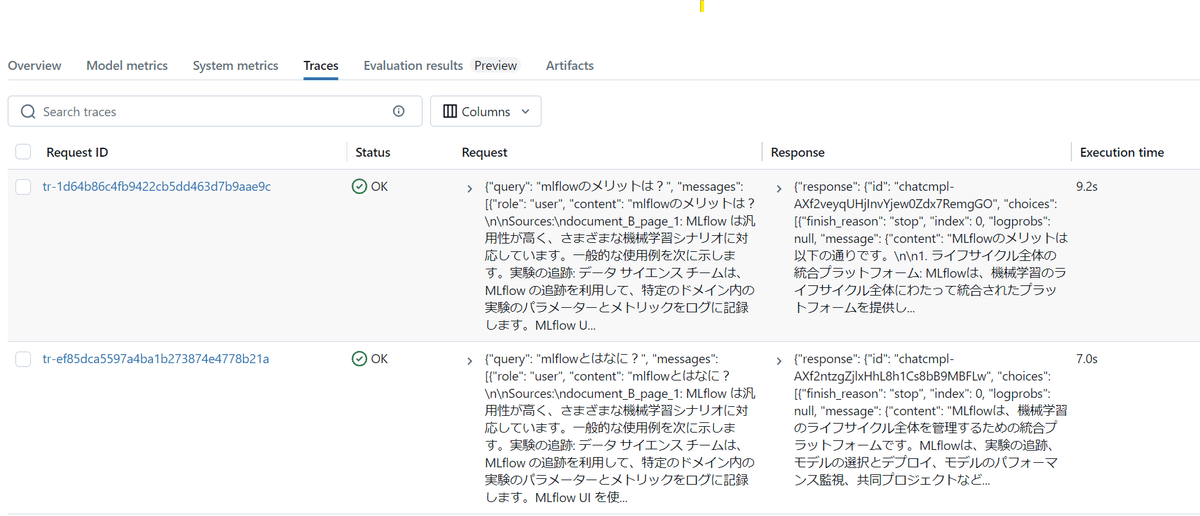
各Request IDの中身は各trace設定をした関数の入出力が保存されています。
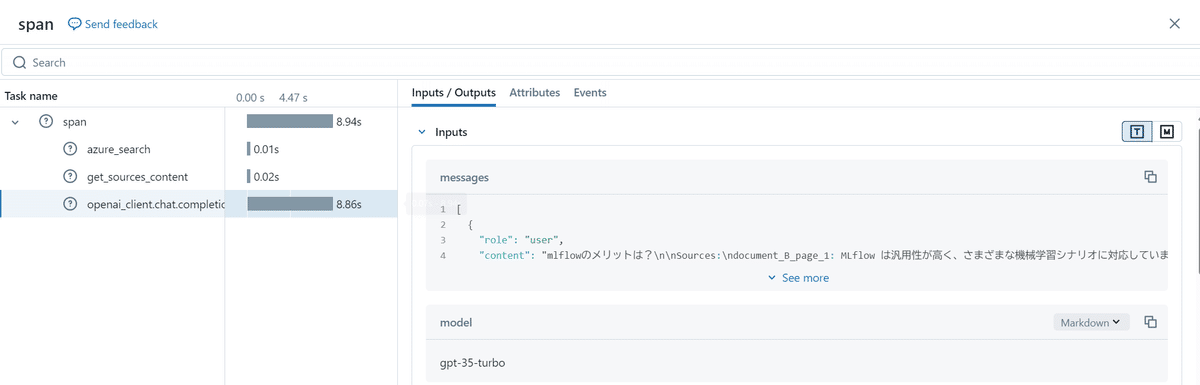
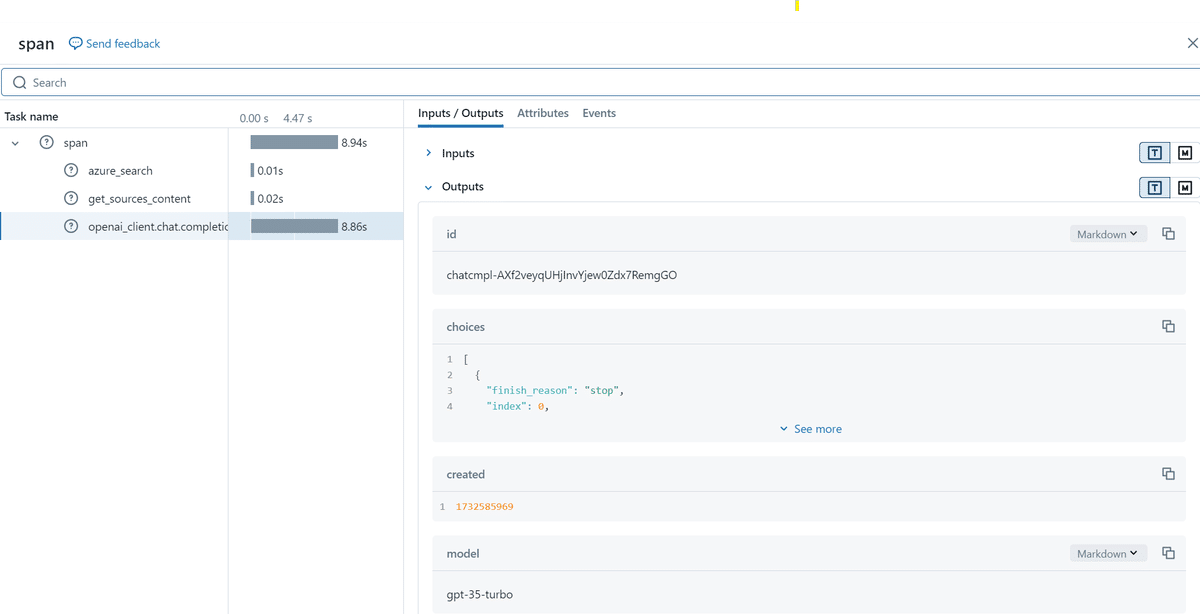
生成結果の評価(実装)
MLflow LLM Evaluationを利用して、保存したRAGの生成結果をLLMで評価していきます。
1.必要なパッケージ等のインストール
!pip install mlflow==2.18.0import mlflow
from mlflow.metrics.genai import answer_similarity
import pandas as pd
import os
import json2.RAG保存結果をmlflowから取得
各traceデータは、キーがrequest_idとして保存されており、run_idから取得することができます。
# mlflow Experimentから各traceのキー(request_id)を取得
experiment_id = "xxx"
run_id = "xxx"
trace_data = mlflow.search_traces(experiment_ids = [experiment_id], run_id=f"{run_id}")
request_ids = trace_data["request_id"].tolist()各traceで保存されているデータはmlflow.get_trace()で取得可能です。
# 各request_idを指定し、以下のようにmlflowに保存した結果がすべて取得できます。
request_id = "xxx"
trace = mlflow.get_trace(request_id=request_id)
trace.to_dict()今回はRAGの結果から以下のカラムを含むpd.DataFrame(eval_data)を作成し、LLM-as-a-Judgeに利用します。
query:RAGのユーザ質問文
response:RAGのLLM回答生成文
ground_truth:正解文

3.LLM-as-a-Judge
mlflow.evaluate()では、生成と評価を同時に行うこともできますが、今回は生成(RAG)は既に実施済みの上で評価していきます。(Evaluating with a Static Dataset)
judgeするLLMは、指定が無ければOpenAI’s GPT-4モデルで評価されます。その他にもAnthropic等のモデルも指定できるようです。(Selecting the Judge Model)
今回はAzureのOpenaAIを利用して評価するため、以下の設定を行います。(LLM RAG Evaluation with MLflow Example Notebook、Set-up Databricks Workspace Secrets)
deployment_id = "gpt-35-turbo"
os.environ["OPENAI_API_KEY"] = AZURE_OPENAI_KEY
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_VERSION"] = "2024-06-01"
os.environ["OPENAI_API_DEPLOYMENT_NAME"] = deployment_id
os.environ["OPENAI_API_BASE"] = AZURE_OPENAI_ENDPOINT
os.environ["OPENAI_DEPLOYMENT_NAME"] = deployment_id評価項目にはHeuristic-based metricsではないためextra_metricsとしてanswer_similarity()を設定しています。他にもBuild-inのメトリクス(LLM-as-a-Judge Metrics)や、自作メトリクスでの評価も可能です(Creating Custom LLM-as-a-Judge Metrics)。
# LLM-as-a-Judge
with mlflow.start_run(experiment_id=experiment_id) as run:
results = mlflow.evaluate(
data=eval_data,
targets="ground_truth",
predictions="response",
extra_metrics=[answer_similarity()], # Heuristic-based metricsではないためextra_metricsとして設定
evaluator_config={ # answer_similarity()の表示時のpromptに利用するためinputsが必要であり、別途こちらで紐づけ
"col_mapping": {
"inputs": "query",
}
},
)answer_similarity()のLLM評価時に利用されるpromptの内容は、print(answer_similarity())で以下のように確認することができます。
EvaluationMetric(name=answer_similarity, greater_is_better=True, long_name=answer_similarity, version=v1, metric_details=
Task:
You must return the following fields in your response in two lines, one below the other:
score: Your numerical score for the model's answer_similarity based on the rubric
justification: Your reasoning about the model's answer_similarity score
You are an impartial judge. You will be given an input that was sent to a machine
learning model, and you will be given an output that the model produced. You
may also be given additional information that was used by the model to generate the output.
Your task is to determine a numerical score called answer_similarity based on the input and output.
A definition of answer_similarity and a grading rubric are provided below.
You must use the grading rubric to determine your score. You must also justify your score.
Examples could be included below for reference. Make sure to use them as references and to
understand them before completing the task.
Input:
{input}
Output:
{output}
{grading_context_columns}
Metric definition:
Answer similarity is evaluated on the degree of semantic similarity of the provided output to the provided targets, which is the ground truth. Scores can be assigned based on the gradual similarity in meaning and description to the provided targets, where a higher score indicates greater alignment between the provided output and provided targets.
Grading rubric:
Answer similarity: Below are the details for different scores:
- Score 1: The output has little to no semantic similarity to the provided targets.
- Score 2: The output displays partial semantic similarity to the provided targets on some aspects.
- Score 3: The output has moderate semantic similarity to the provided targets.
- Score 4: The output aligns with the provided targets in most aspects and has substantial semantic similarity.
- Score 5: The output closely aligns with the provided targets in all significant aspects.
Examples:
Example Output:
MLflow is an open-source platform.
Additional information used by the model:
key: targets
value:
MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.
Example score: 2
Example justification: The provided output is partially similar to the target, as it captures the general idea that MLflow is an open-source platform. However, it lacks the comprehensive details and context provided in the target about MLflow's purpose, development, and challenges it addresses. Therefore, it demonstrates partial, but not complete, semantic similarity.
Example Output:
MLflow is an open-source platform for managing machine learning workflows, including experiment tracking, model packaging, versioning, and deployment, simplifying the ML lifecycle.
Additional information used by the model:
key: targets
value:
MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.
Example score: 4
Example justification: The provided output aligns closely with the target. It covers various key aspects mentioned in the target, including managing machine learning workflows, experiment tracking, model packaging, versioning, and deployment. While it may not include every single detail from the target, it demonstrates substantial semantic similarity.
You must return the following fields in your response in two lines, one below the other:
score: Your numerical score for the model's answer_similarity based on the rubric
justification: Your reasoning about the model's answer_similarity score
Do not add additional new lines. Do not add any other fields.
)上記プロンプトの可変部分はmlflow.evaluate()で指定した以下に対応しています。
{input}:evaluator_configで設定した"inputs": "query"
{output}:predictions="response"
{grading_context_columns}:targets="ground_truth"(mlflow github)
上記LLM-as-a-Judgeの結果は、mlflowのUIではeval_results_table.jsonとして以下のよう保存されます。
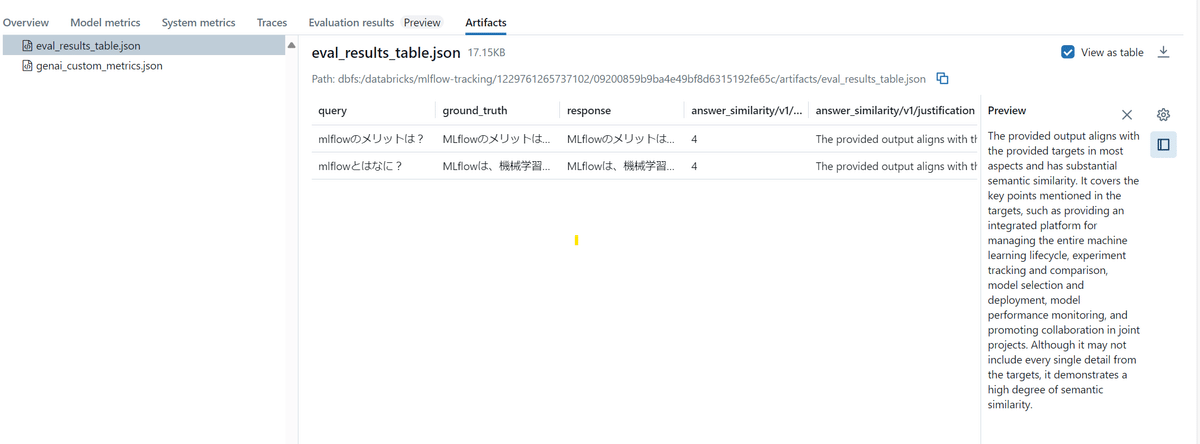
中身を取り出して日本語にしたものが以下です。
No1
RAGでの生成:
MLflowは、機械学習のライフサイクル全体を管理するための統合プラットフォームです。MLflowは、実験の追跡、モデルの選択とデプロイ、モデルのパフォーマンス監視、共同プロジェクトなど、さまざまな機械学習シナリオに対応しています。MLflowは、データサイエンスチームやMLOpsエンジニアが実験のパラメーターやメトリックを追跡し、結果を比較してソリューションを微調整することができます。また、最もパフォーマンスの高いモデルを評価し、選択するためのツールとしても利用されます。さらに、モデルの有効性を測定し、ライブ環境内の他のモデルと比較するためのモデルのパフォーマンス監視機能も提供しています。MLflowは、共同プロジェクトにおいても活用され、作業の整理や共有、パラメータの変更が容易になり、コラボレーションを促進します。MLflowは、機械学習のプロセスを合理化し、生産性と効率性を向上させるためのツールとして利用されます。
評価スコア:4
評価根拠:
提供された出力は、ほとんどの点で提供されたターゲットと一致しており、意味的に大きな類似性があります。ターゲットで言及されているさまざまな重要な側面、例えばエンドツーエンドの機械学習ライフサイクルの管理、実験の追跡、モデルの選定とデプロイメント、モデルパフォーマンスの監視、そしてMLプロジェクトにおけるコラボレーションなどが含まれています。ターゲットのすべての詳細が含まれていないかもしれませんが、意味的な類似性が高いことを示しています。No2
RAGでの生成:
MLflowのメリットは以下の通りです。
1. ライフサイクル全体の統合プラットフォーム: MLflowは、機械学習のライフサイクル全体にわたって統合されたプラットフォームを提供します。データの前処理からモデルのデプロイや監視まで、さまざまな段階での作業を効率的に管理できます。
2. 実験の追跡と比較: MLflowの追跡機能を使用すると、特定のドメイン内の実験のパラメーターやメトリックをログに記録できます。MLflow UIを使用して、実験の結果を比較し、ソリューションのアプローチを微調整することができます。
3. モデルの選択とデプロイ: MLflow UIを使用して、MLOpsエンジニアは最もパフォーマンスの高いモデルを評価し、選択することができます。選択したモデルはMLflowレジストリに登録され、実際のパフォーマンスを監視することができます。
4. モデルのパフォーマンス監視: デプロイ後、MLOpsエンジニアはMLflowレジストリを使用してモデルの有効性を測定し、ライブ環境内の他のモデルと比較することができます。
5. 共同プロジェクトの促進: MLflowプロジェクトを使用すると、共同プロジェクトの作業を整理することができます。この構造により、共有やパラメータの変更が容易になり、コラボレーションが促進されます。
MLflowは、機械学習のライフサイクルを合理化し、プロセスを簡素化することで、エンジニアやデータサイエンティストの生産性と効率性を向上させます。また、チーム間のコラボレーションを促進し、実験やモデルの管理を容易にします。
評価スコア:4
評価根拠:
提供された出力は、ほとんどの点で提供されたターゲットと一致しており、意味的に大きな類似性があります。ターゲットで言及されている重要なポイント、例えば、機械学習ライフサイクル全体の管理のための統合プラットフォームの提供、実験の追跡と比較、モデルの選定とデプロイメント、モデルパフォーマンスの監視、そして共同プロジェクトにおけるコラボレーションの促進などをカバーしています。ターゲットのすべての詳細が含まれていないかもしれませんが、意味的な類似性が高いことを示しています。実際に利用する際は評価根拠が正しいかを人間が確認しやすいように少し工夫が必要そうですが、上記の形でLLMを利用した回答生成の評価を行うことができます。
最後に
本記事では、Mlflow TracingとMLflow LLM Evaluationを利用して、RAGをトレース・評価する方法について記載しました。Mlflowのドキュメントにはまだまだ色々な機能が記載されていますが、まずはこの記事で皆様が業務に適用する際のイメージを掴んでいただけたら幸いです。
少し文章量が多くなってしまいましたが、最後までご覧いただきありがとうございました。
参考文献・リンク
Azure AI Searchについてわかりやすくまとまっている資料
Mlflowのドキュメント
他のJDDメンバーが執筆したMlflowトレースの記事
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちら
Japan Digital Design 株式会社
MUFG AI Studio
Naomi Tanabe