Python pandasの覚書

・表形式のデータとDataFrame
次のような表を、pythonプログラムで使用するには Pandasでつくるデータフレームが便利である。基本的な使い方をメモしておく。
$$
\begin{array}{|l|c|c|} \hline
\text{} & \text{国語} & \text{数学} \\ \hline
\text{A} & \text{65} & \text{60} \\ \hline
\text{B} & \text{80} & \text{85} \\ \hline
\text{C} & \text{95} & \text{75} \\ \hline
\end{array}
$$
データフレームは、インデックス(行)、カラム(列)につけられたキーをマトリクスにした中にデータを収める構造となっている。
DataFrame は、
columns( 'pandas.core.indexes.base.Index' )、
index ( 'pandas.core.indexes.base.Index' )、
values ( numpyの2次元配列 )
で構成されている
上の表の例では、
A,B,C が インデックスのキーで、
国語、数学 が カラムのキーとなっている。
収めるデータは、数値、文字列、または混在、欠損(NaNとなる)があっ
ても問題なし。dictionayの2次元版みたいなものかな。さらに、要素は、
配列の要素番号の扱いと同じようにしても参照できる。
・データフレームの作成
2次元配列のデータから作成(行データ)
import pandas as pd
''' 行データからデータフレームを作る
dataは、2次元配列の1行が1人のデータ。
1行のデータは左から詰められ、不足するときはNaN。多すぎるときはエラーとなる。
df --->> <class 'pandas.core.frame.DataFrame'>
国語 数学
A 65 60
B 80 85
C 95 75
'''
col = ["国語", "数学"] # カラム名の作成
idx = ["A", "B", "C"] # インデックス名の作成
data = [ # データ
[65, 60], # 国語、数学
[80, 85],
[95, 75]
]
df = pd.DataFrame(data, columns=col, index=idx) # DataFrameの作成Dictionaryのデータから作成(列データ)
''' 列データからデータフレームを作る
dataは、(Dictionary) columns 名と key 名は、一致しているものが取り込まれる。
キー名が一致しないものは NaN となる。インデックスの数と要素の数が、過不足のときはエラーとなる。
'''
col = ["国語", "数学"] # カラム名の作成
idx = ["A", "B", "C"] # インデックス名の作成
data = { # データ
"国語" : [65, 80, 95],
"数学" : [60, 85, 75]
}
df = pd.DataFrame(data, columns=col, index=idx) # DataFrameの作成
・CSVファイルとして保存
# 保存
df.to_csv("output_pd2.csv") # UTF-8
'''
文字コードを,"shift_jis"とする場合
OSによって、使用されている文字コードが異なるので注意
動作環境
OS:debian
開発環境:VSCODE
df.to_csv("output_pd2.csv", encoding="shift_jis")
保存されたファイル
,国語,数学
A,65,60
B,80,85
C,95,75
'''・CSVファイルの読み込み
# 読み込み
df = pd.read_csv('output_pd2.csv', index_col=0)
'''
index_col=0 を省略すると、インデックス名もデータの中に入る
Unnamed: 0 国語 数学
0 A 65 60
1 B 80 85
2 C 95 75
なお、タブ区切りのファイルの読み込みは delimiter='\t', header=0 をつける
df = pd.read_csv("output_pd3.tsv", delimiter='\t', header=0)
データフレームの出力例(インデックスの設定ができなかった)
国語 数学
0 A 65 60
1 B 80 85
2 C 95 75
'''・データフレームからデータを抽出
データフレームよりデータを抽出したとき、その方法によって、
<class 'pandas.core.frame.DataFrame'> 2次元
<class 'pandas.core.series.Series'> 1次元
<class 'numpy.int64'> 数値など
のオブジェクトとなるので、注意が必要。
* 1行または1列だけのデータを、DataFrameで参照したいときは
df.loc[ [ 'A' ] ] のようにする(下記のソースを参照)
# 読み込み
df = pd.read_csv('output_pd2tokei.csv', index_col=0)
'''
ファイル名 --> path/ファイル名.csv
index_col=0 --> csvファイルの1行目をカラム名とする
'''
# ---------------------------------------------------------------------
# データフレーム
df # <class 'pandas.core.frame.DataFrame'> .shape (5,3)
'''
国語 数学 クラス
A 65 60 1A
B 80 85 NaN
C 95 75 1C
D 65 75 1A
E 65 60 1B
DataFrame は、columns、index、values で構成されている
'''
# ---------------------------------------------------------------------
# キー(列)
df.columns # <class 'pandas.core.indexes.base.Index'> .shape (3,)
'''
Index(['国語', '数学', 'クラス'], dtype='object')
'''
# ---------------------------------------------------------------------
# キー(行)
df.index # <class 'pandas.core.indexes.base.Index'> .shape (5,)
'''
Index(['A', 'B', 'C', 'D', 'E'], dtype='object')
'''
# ---------------------------------------------------------------------
# データフレームの値 2次元のnumpy.ndarray
df.values # <class 'numpy.ndarray'> .shape (5,3)
'''
array([[65, 60, '1A'],
[80, 85, nan],
[95, 75, '1C'],
[65, 75, '1A'],
[65, 60, '1B']], dtype=object)
'''
# ---------------------------------------------------------------------
# values のデータ型
df.dtypes # <class 'pandas.core.series.Series'> .shape (3,)
'''
国語 int64
数学 int64
クラス object
dtype: object
'''
# ---------------------------------------------------------------------
# キーを使わず取り出す
# 2列目の数学を、データフレームとして取り出す(2次元)
df.iloc[:,[1]] # <class 'pandas.core.frame.DataFrame'>
'''
数学
A 60
B 85
C 75
D 75
E 60
'''
# 2列目の数学を、Seriesとして取り出す(1次元)
df.iloc[:,1] # <class 'pandas.core.series.Series'>
'''
A 60
B 85
C 75
D 75
E 60
Name: 数学, dtype: int64
--->> Seriesの参照
dd=df.iloc[:,1]
dd[0] <-- 0行の 60 を参照(警告がでる。 dd.iloc[0] と記述してね。)
dd['A'] <-- これは警告なしで参照できる
DataFrameではエラーとなるので注意
'''
# ---------------------------------------------------------------------
# キーを使って取り出す
# 2列目の数学を、データフレームとして取り出す(2次元)
df.loc[:,['数学']] # <class 'pandas.core.frame.DataFrame'>
'''
数学
A 60
B 85
C 75
D 75
E 60
'''
# 2列目の数学を、Seriesとして取り出す(1次元)
df.loc[:,'数学'] # <class 'pandas.core.series.Series'>
'''
A 60
B 85
C 75
D 75
E 60
Name: 数学, dtype: int64
=====
1列全てを取り出すときは、df['数学'] でOK
1行分は、df['A'] で取り出せない --> df.loc['A'] または df.loc['A',:]
'''
# ---------------------------------------------------------------------
# AとBの数学と国語をDataFrameとして取り出す
df.loc['A':'B',['数学','国語'] ]
'''
数学 国語
A 60 65
B 85 80
'''・データフレームからデータを代入で抽出するときの注意
pandasは、設定や挙動が options にまとめられている。
= (代入演算子)を使ってデータを抽出したときは、
参照渡しとなっている。(デフォルト)
完全なコピーを作成するときは、
options の設定を変更する(pd.options.mode.copy_on_write=True)か、
copy() メソッドを利用すること。
import pandas as pd
df = pd.read_csv('output_pd2tokei.csv', index_col=0)
'''
国語 数学 クラス
A 65 60 1A
B 80 85 NaN
C 95 75 1C
D 65 75 1A
E 65 60 1B
'''
pd.options.mode.copy_on_write = False # デフォルト。True にすると copy。
print(pd.options.mode.copy_on_write)
d=df['国語']
d.iloc[0]=100
print(df.iloc[0,0],d.iloc[0]) # 100 100
'''
pandas の options
.options.mode.copy_on_write は、デフォルトで False
d は df の view(参照渡し) になっているので
d の値を変更 --> df の値も変化
print(df.iloc[0,0],d.iloc[0]) --> 100 100
d の値を変更 --> df の値が変化しないようにするには、(d と df は独立の変数としたい)
pd.options.mode.copy_on_write = True
d=df['国語']
d.iloc[0]=100
print(df.iloc[0,0],d.iloc[0]) --> 65 100
または、copy()メソッドを利用する
d=df['国語'].copy()
補足
Jupyterを利用しているとき、 pd.options.mode.copy_on_write=True の設定を行うと、
カーネルの再起動がされるまで有効。デフォルトのFalseに戻すには、
pd.options.mode.copy_on_write=False を実行すること。
'''・データフレームの統計
# ---------------------------------------------------------------------
# 統計
df.describe(include='all') # 全ての情報 include='all'
'''
国語 数学 クラス
count 3.0 3.000000 2
unique NaN NaN 2
top NaN NaN 1A
freq NaN NaN 1
mean 80.0 73.333333 NaN
std 15.0 12.583057 NaN
min 65.0 60.000000 NaN
25% 72.5 67.500000 NaN
50% 80.0 75.000000 NaN
75% 87.5 80.000000 NaN
max 95.0 85.000000 NaN
'''
df.describe() # 数値の情報が出力される
'''
国語 数学
count 3.0 3.000000
mean 80.0 73.333333
std 15.0 12.583057
min 65.0 60.000000
25% 72.5 67.500000
50% 80.0 75.000000
75% 87.5 80.000000
max 95.0 85.000000
'''
df.describe(exclude='number') # 数値以外の情報が出力される
'''
クラス
count 2
unique 2
top 1A
freq 1
'''
df.astype(object).describe() # objectとしての統計
'''
国語 数学 クラス
count 3 3.0 2
unique 3 3.0 2
top 65 60.0 1A
freq 1 1.0 1
'''
# その他の例
df.describe(include=int) # int型データのみ
df.astype({'国語': int, '数学': str}).describe() # 型を変換して
# 個々の統計
df['国語'].count() # 個数 国語の個数: 5
df['国語'].max() # 最大値 国語の最大値: 95
df['国語'].min() # 最小値 国語の最小値: 65
df['国語'].mean() # 平均 国語の平均: 74.0
df['国語'].median() # 中央値 国語の中央値: 65.0
df['国語'].std() # 標準偏差 国語の標準偏差: 13.416407864998739
df['国語'].nunique() # 国語のユニークな値の数: 3
df['国語'].value_counts() # 度数分布(結果は Series 型)
'''
国語
65 3
80 1
95 1
Name: count, dtype: int64
'''
df['数学'].mode() # 最頻値 (結果は Series 型)
'''
0 60
1 75
Name: 数学, dtype: int64
'''・データに欠損値があるかを確認し、埋める
# ---------------------------------------------------------------------
# 欠損値の個数
df.isnull().sum() # 列
'''
国語 0
数学 0
クラス 1
dtype: int64
'''
df.isnull().sum(axis=1) # 行
'''
A 0
B 1
C 0
D 0
E 0
dtype: int64
'''
df.isnull()
'''
国語 数学 クラス
A False False False
B False False True
C False False False
D False False False
E False False False
.isnull() は、上のような真偽の DataFrame となる
'''
# ---------------------------------------------------------------------
# 欠損値を埋める .fillna(値)
df["クラス"] = df["クラス"].fillna('1E') # クラス列にある全ての欠損値が'1E'となる
'''
個別に設定するときは、.isnull()と条件を組み合わせること
'''・相関係数、クロス集計、ピボットテーブル
import pandas as pd
# 読み込み
df = pd.read_csv('output_pd2tokei.csv', index_col=0)
'''
国語 数学 クラス
A 65 60 1A
B 80 85 NaN
C 95 75 1C
D 65 75 1A
E 65 60 1B
'''
# ---------------------------------------------------------------------
# 相関係数
df.loc[:,['国語','数学']].corr()
'''
国語 数学
国語 1.000000 0.567282
数学 0.567282 1.000000
'''
# クロス集計
pd.crosstab(df['クラス'], df['国語'])
'''
国語 65 95
クラス
1A 2 0
1B 1 0
1C 0 1
'''
pd.crosstab(df['クラス'], df['国語'], margins=True, normalize='index') # 列ごとの正規化 normalize='columns'
'''
国語 65 95
クラス
1A 1.00 0.00
1B 1.00 0.00
1C 0.00 1.00
All 0.75 0.25
'''
# ピボットテーブル
df.pivot_table(index='クラス',columns=None, values=['国語','数学'],aggfunc='count') #sum
'''
国語 数学
クラス
1A 2 2
1B 1 1
1C 1 1
'''・ピボットテーブルとグラフの作成
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
# ピボットテーブルの作成
pivot=df.pivot_table(index='クラス',columns=None, values=['国語','数学'],aggfunc='count')
# グラフの表示設定
sns.set(style='darkgrid',font='IPAexGothic') # seaborn の設定
plt.rcParams['figure.figsize'] = (10, 5)
plt.rcParams['font.size'] = 12
# print(plt.rcParams['font.family']) # ['IPAexGothic']
plt.ylabel("人")
# グラフ作成
pivot.plot.bar(title="クラス別国語、数学の受験者数") # bar pie
plt.show()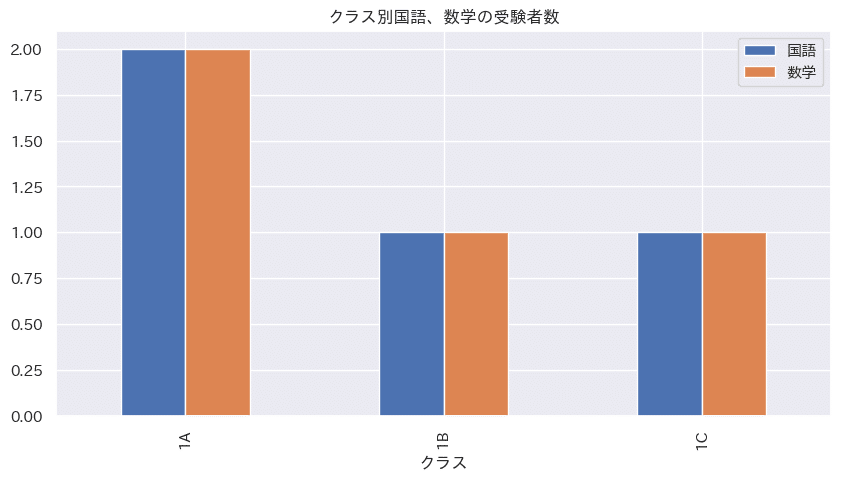
・データフレームの結合
結合は、mergeメソッドが便利。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
display(df1,df2)
'''
key value
0 A 1
1 B 2
2 C 3
3 D 4
key value
0 B 5
1 D 6
2 E 7
3 F 8
'''
# 内部結合 両方(df1,df2)のキーの共通するもの
merged_inner = pd.merge(df1, df2, on='key')
merged_inner.columns=['key','df1','df2']
display(merged_inner)
'''
key df1 df2
0 B 2 5
1 D 4 6
'''
# 外部結合 両方(df1,df2)の全てのキーに該当するもの 存在しないものはNaN
merged_outer = pd.merge(df1, df2, on='key', how='outer')
merged_outer.columns=['key','df1','df2']
display(merged_outer)
'''
key df1 df2
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0
5 F NaN 8.0
'''
# 左結合 左(df1)のすべてのキーに該当するもの 存在しないものはNaN
left_merged = pd.merge(df1, df2, on='key', how='left')
left_merged.columns=['key','df1','df2']
display(left_merged)
'''
key df1 df2
0 A 1 NaN
1 B 2 5.0
2 C 3 NaN
3 D 4 6.0
'''
# 右結合 右(df2)のすべてのキーに該当するもの 存在しないものはNaN
right_merged = pd.merge(df1, df2, on='key', how='right')
right_merged.columns=['key','df1','df2']
display(right_merged)
'''
key df1 df2
0 B 2.0 5
1 D 4.0 6
2 E NaN 7
3 F NaN 8
'''