HTMLのElementを引き出してコードで扱う

はじめに
TypeScriptと言うかJavascriptの基本とも言うべきHTMLタグの扱いの基礎があやふやだったので、ここで忘備録を兼ねて整理。
サンプルHTMLの内容
コードの前に、ここで扱うサンプルHTMLの構造を記載しておく
<p>■ テーブル</p>
あいうえお
<table>
<thead>
<tr>
<th align="left">赤身</th>
<th align="center">白身</th>
<th align="right">軍艦</th>
</tr>
</thead>
<tbody><tr>
<td align="left">マグロ</td>
<td align="center">ヒラメ</td>
<td align="right">ウニ</td>
</tr>
<tr>
<td align="left">カツオ</td>
<td align="center">タイ</td>
<td align="right">イクラ</td>
</tr>
<tr>
<td align="left">トロ</td>
<td align="center">カンパチ</td>
<td align="right">ネギトロ</td>
</tr>
</tbody></table>
<ul>
<li>リスト有り1</li>
<li>リスト有り2</li>
</ul>ブラウザで表示すると以下となる。

Elementの引き出し
これは基本でId指定では以下で記述する。クラス名やタグ名での引き出しメソッドもあるが、ここでは一番使うであろうメソッドのみ記載。
const element = document.getElementById('引き出す要素のID');Elementの子要素取得 その1
一番イメージしやすい方法としてchildNodesでループする。
const element = document.getElementById('引き出す要素のID');
if (element) {
element.childNodes.forEach((child) => {
{
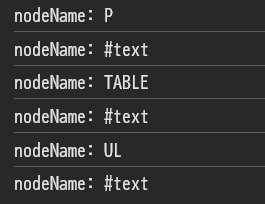
console.log('nodeName: ' + child.nodeName);
}
});
}consoleは以下の通り。ここで#textは文字列値を表し、1番目の#textは「あいうえお」に該当する。2,3番目の#textはHTMLでは空のように見えるが改行コードがあるので、それが対象となっている。
Elementの子要素取得 その2
変則方法として、引き出したElementの最初の子を取り出して、nextSiblingで次の子に移る方法。
let element = document.getElementById('引き出す要素のID')?.firstChild;
while (element) {
console.log('nodeName: ' + element.nodeName);
element = element.nextSibling;
}結果はchildNodesでループする場合と同じになる。メソッドの正しい使い方としては子の取得ではなく同階層にいるElementを取得する方法として使用すると思われる。
取得した子をHTMLのElementとして扱う
上のどちらの方法も変数の型がChildNodeになっており、HTMLタグとして扱うことはできない。そのため属性を取得することやHTMLそのものを取り出すことがそのままではできない。
そのためElementインスタンスかどうかチェックすることで、HTMLタグの情報が扱えるようになる。
if (child instanceof Element) {
console.log(child.setAttribute('class', 'test'));
console.log(child.outerHTML);
}結果は以下のようにclassが追加できる。

まとめ
JavaからTypeScriptに入った身としては文化の違いで戸惑うところが多いが、今回のinstanceofでチェックすればそのままチェック後の型で扱うことできる点は大きなカルチャーショックだった。
TypeScriptとしては当たり前なのだろうが、Javaなどの言語のようにキャストしなくて良いというのは非常にメリットが大きいと感じた。
このような文化の違いは今後も小ネタとして記載していって理解度を深めたい。