
【初心者向け】seleniumでニュースをスクレイピング

いろいろなサイトのニュースを集めて自分用のボットを作りたいので、まずはニュースのデータ収集用のコードを作ってみました。
今回もGoogle Coraboratory で作っていきます。
【準備】ドライバーとseleniumなどをインストール
#Chromiumとseleniumをインストール
#「!」印ごとColaboratoryのコードセルに貼り付けます。
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip install selenium
#SeleniumとBeautifulSoupのライブラリをインポート
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# ブラウザをheadlessモード(バックグラウンドで動くモード)で立ち上げてwebsiteを表示、生成されたhtmlを取得し、BeautifulSoupで綺麗にする。
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
driver.implicitly_wait(10)詳しい方法はこちら
目的ページからhtmlデータをスクレイピング
今回は第一生命経済研究所のhtmlデータを取得します。
url = 'https://www.dlri.co.jp/'
driver.get(url)
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
# print(soup.prettify())soup.prettify()で得られたhtmlデータを確認できます。
driver.quit()今回はこのページのデータしか取らないので、忘れないうちにドライバーを終了させておきます。
得られたhtmlデータからBeautifulSoupを用いて目的の部分を確認する
トップページのニュースのデータを取り出したいので、検証でhtmlを確認します。(chromeなら右クリック→検証で対象部分のhtmlを表示できます)

トップニュースはlistというclassを持つdivタグに囲まれていることがわかります。
soupからdivタグのclass 'list'を持つものを抽出します。
# divタグのclass'list'を持つものを抽出
news_list = soup.find_all("div", class_="list")news_listに検索データが代入されています。
ここで、代数のtypeを確認してみましょう。
print(type(soup))
print(type(news_list))
print(len(news_list)) # divタグのclass'list'を持つグループがいくつあるか
print(type(news_list[0]))これを実行すると以下のように出力されます。
"""
<class 'bs4.BeautifulSoup'>
<class 'bs4.element.ResultSet'>
3
<class 'bs4.element.Tag'>
"""
まず、'soup'はBeautifulSoupのオブジェクトです。
'news_list' は'element.ResultSet'となっています。
divタグのclass'list'を持つ要素が複数個あったためと思われます。
news_list に含まれる要素がいくつあるかlenで調べると、3つあることがわかりました。
news_list[0] のtypeを見てみるとelement.Tagとなっています。
つまりnews_list にはclass'list'を持つdiv のTagが3つ入っていることになります。
news_listの中身を確認してみましょう。
news_list[0]を見てみます。

新着レポート部分のhtmlのようです。
順に確認していくと、このようになっていました。
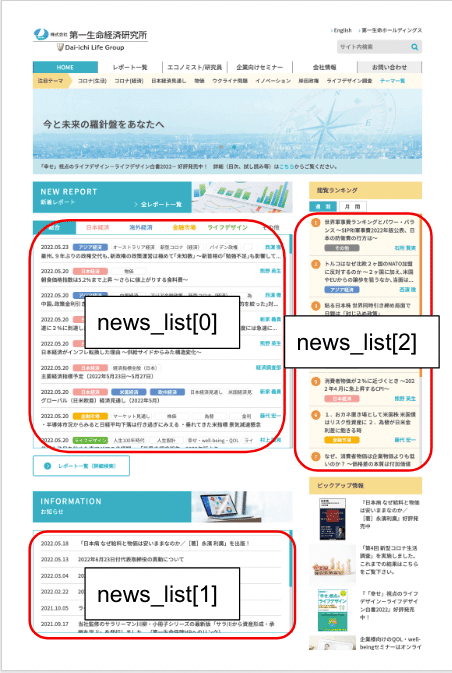
今回は新着レポートのデータを取っていきたいので、news_list[0]を使用していきます。
htmlデータからニュースの日付、タイトル、記事へのリンクを取得する
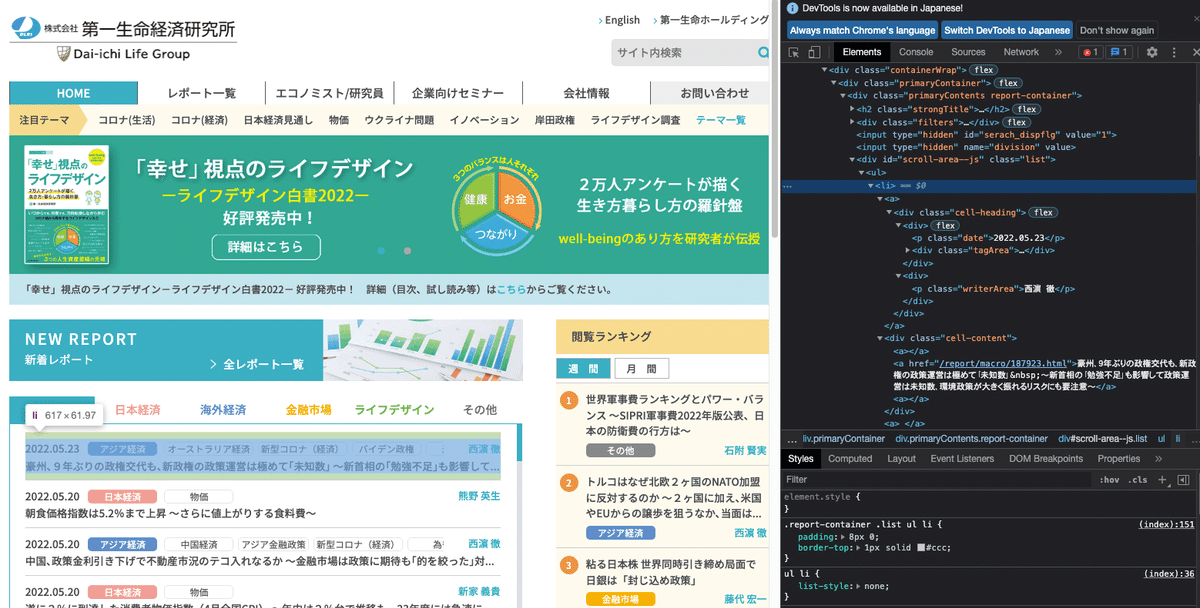
記事部分のhtmlを見てみると、タイトルはclass'cell-content'のdivタグに入っていることがわかります。
まずはタイトルのみのリストを作っていきます。
news_titles = [title.text for title in news_list[0]('div', class_='cell-content')]テキスト部分を抜き出すには*.textを使いますが、for文を内包表記してリストにします。
news_titlesの中身を見てみます。

うまくタイトルを取得できたようです。数を確認すると、全部で100記事のようです。
同様に日付も抽出してリストにします。
news_dates = [date.text for date in news_list[0]('p', class_='date')]
記事へのリンクも抽出します。
news_htmls = [news_html.get('href') for news_html in news_list[0]('a')]
'a'タグからhref部分を抽出しようとしましたが、Noneが入っています。hrefを持たない'a'タグ成分も拾ってしまっているようなので、Noneをリストから削除します。
# hrefにNanが含まれるので、Nanを削除
news_htmls_filtered = [x for x in news_htmls if x is not None]
news_htmls_filtered
これで、タイトル、日付、リンクのリストが作成できました。
得られたデータをデータフレームにまとめる
これらをデータフレームにまとめていきます。
(今回は直近20記事のみ使用)
import pandas as pd
df = pd.DataFrame(
data={'date': news_dates[:20], 'topic': news_titles[:20], 'html': news_htmls_filtered[:20]})
良さそうですが、htmlが相対パスになっているので、絶対パスに変換します。
# htmlが相対パス表記なので、絶対パスに変換
df['html'] = url + df['html'].str[1:]dfを確認してみます。

良さそうですね。
これで完成です!
最終的には、これを自動で定期的に取得し、LINE botとか作れたらいいなと考えてます。