
【実装編】AutoEncoderとは?

基本のAutoEncoderをなるべく少ないコードで実装していきます。
Tensorflowの公式チュートリアルを参考に実装を進めていきます。
必要なライブラリをインポート
# ライブラリのインストール
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers, losses
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Modelデータセットのダウンロード
# データセットのロード
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.モデルの定義
オートエンコーダーのモデルを定義していきます。
# モデルの定義
class Autoencoder(Model):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Input(shape=(28, 28, 1)),
layers.Conv2D(16, (3, 3), activation='relu', padding='same', strides=2),
layers.Conv2D(8, (3, 3), activation='relu', padding='same', strides=2)
])
self.decoder = tf.keras.Sequential([
layers.Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2D(1, kernel_size=(3, 3), activation='sigmoid', padding='same')
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Autoencoder()
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError())チュートリアルでは、エンコーダー・デコーダーでそれぞれ一層でモデルを定義していますが、構造が分かりやすいようにそれぞれ2層ずつの畳み込み層にしています。
学習後に、それぞれの層を可視化できるようになります。
# モデルの構成を可視化
autoencoder.encoder.summary()
autoencoder.decoder.summary()エンコーダー(Encoder)
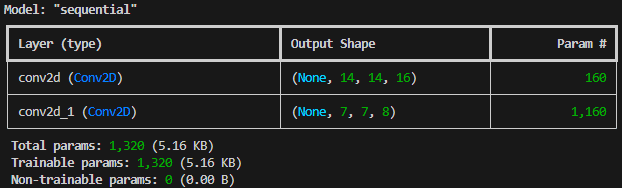
画像の通り、以下のように情報が圧縮されて行っています。
入力画像 28×28
↓
1層目 14×14
↓
2層目 7×7
デコーダー(Decoder)
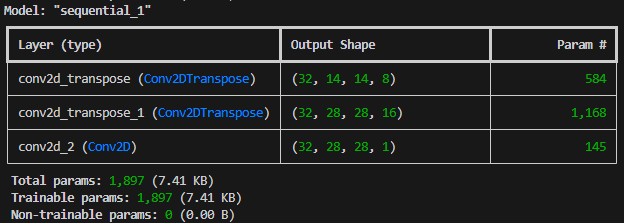
逆に、以下のように情報が復元されています。
入力 7×7
↓
1層目 14×14
↓
2層目 28×28
学習
# 学習
autoencoder.fit(x_train, x_train,
epochs=1,
shuffle=True,
validation_data=(x_test, x_test))# 学習後のエンコーダーとデコーダーを使って、情報を圧縮&復元
encoded_imgs = autoencoder.encoder(x_test).numpy()
decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()
# 元画像と復元後の画像を表示
for i in range(5):
# display original
ax = plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, 5, i + 1 + 5)
plt.imshow(decoded_imgs[i])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
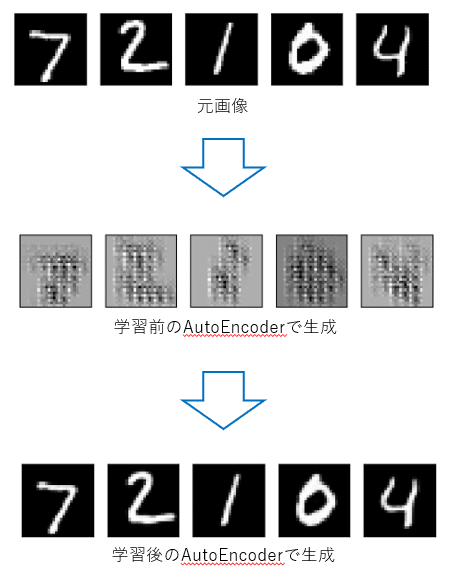
plt.show()結果画像のように、学習することで手書き文字を生成できるようになっていることが分かります。
まとめ
以上でAutoEncoderによる、次元圧縮と復元タスクを実装することができました。
データセットを変えたり、モデルの構成をカスタマイズすることで、様々な用途に活かすことができるようになります。
是非参考にしてみてください。