
【スクレイピング】LLMを活用してサイトの情報を取得させる方法

はじめに
Pythonなどのプログラミングを活用して、Web上の情報を自動で取得する手法をスクレイピングと言います。
本記事では、オーソドックスなスクレイピング手法とLLMを活用した新しい手法を比較しながら、AIによるこれからのスクレイピングについて紹介していきます。
従来のスクレイピング
基本的にスクレイピングを行う際は、情報を取得したいサイトのHTML構文を解析し、一つ一つプログラムを組む必要があります。
例:楽天市場から商品情報を取得する
>> 取得したい情報のHTML文を確認して、Class名などを指定して情報を取得する
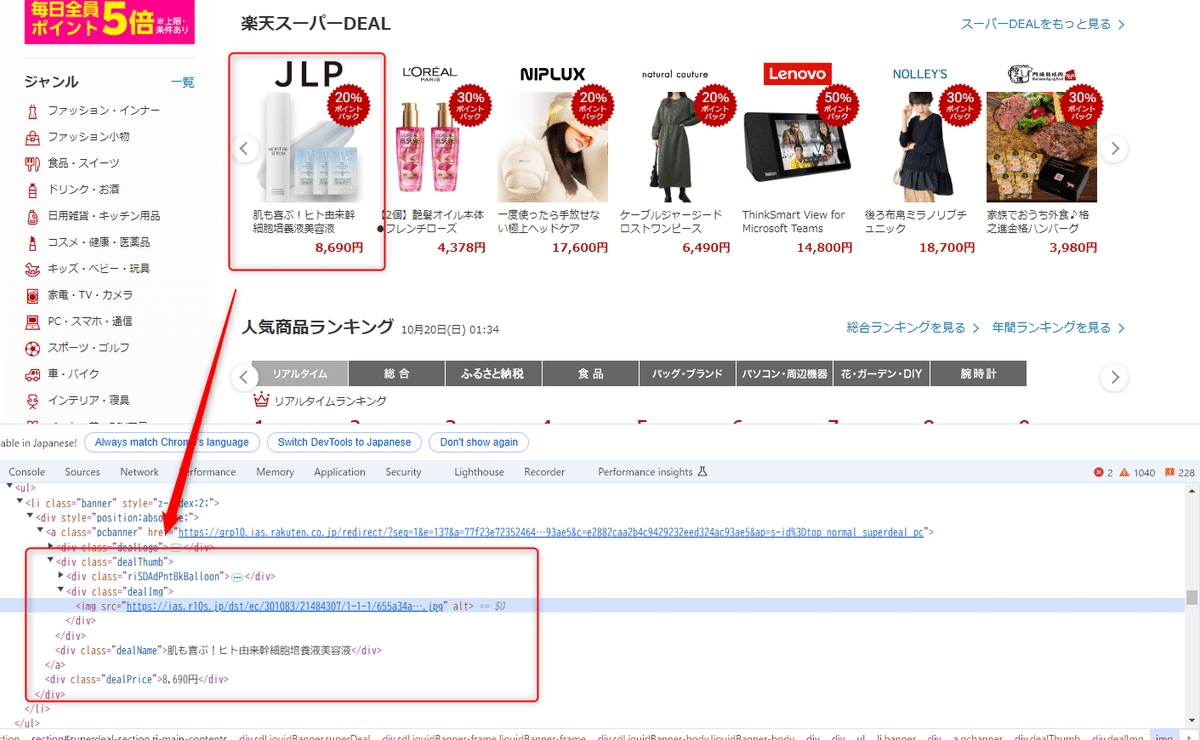
このように従来のスクレイピングでは、さまざまなタスクが必要となっていました。
・ サイトの内容をひとつひとつ確認し、コードを作成する必要がある
・ サイト内のHTML構造が更新されたら、コードも変更しなければならない
このような課題を解決するために、なるべくコードを簡略化し、一つのプログラムによって複数のサイトから情報を取得できないかと考えてみました。
LLMを活用したスクレイピング
トップページのURLを入力すると、そのサイト内を探索し、ランダムにページを解析して情報を取得するようなツールを作成しました。
デモ
実際に私のNoteのクリエイターページ(https://note.com/itsuka_someday/)を入力してみた結果です。
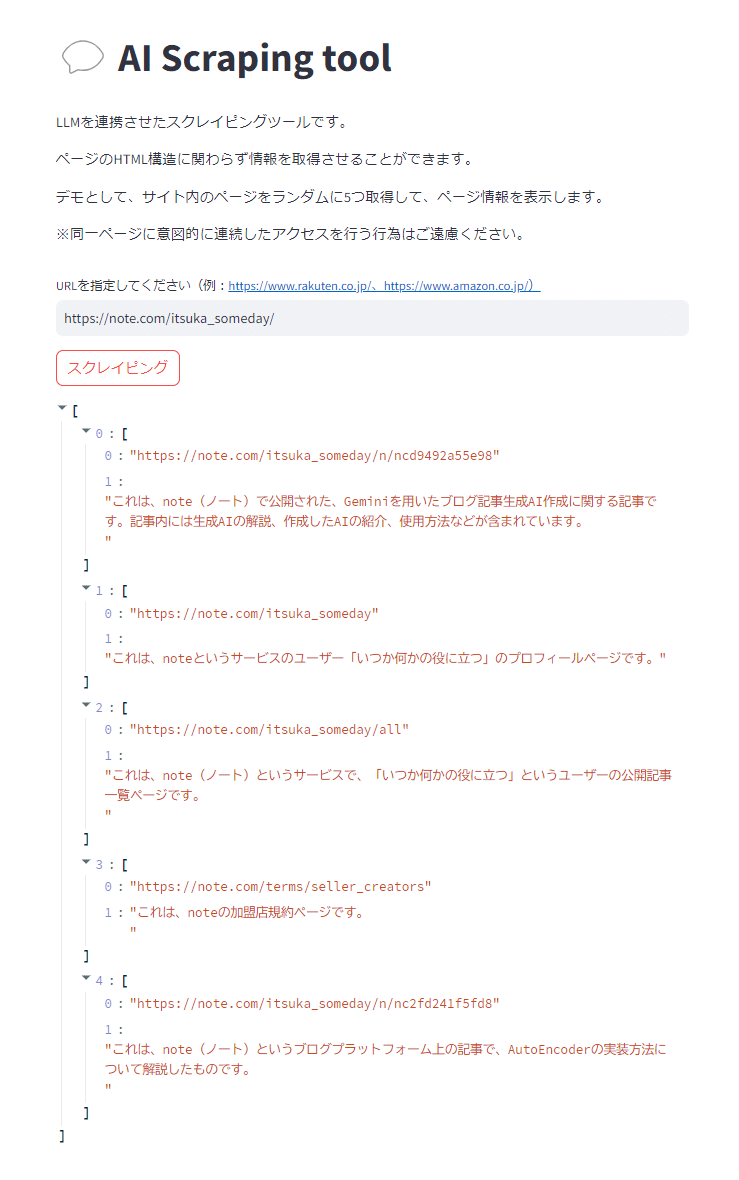
投稿した記事の説明や、他のページについての情報が取得できています。
仕組み
実際のロジックとしては、以下のライブラリを使用して実現しています。
・ Requests
・ Beautifulsoup4
・ google-generativeai
RequestsとBeautifulsoup4は、従来のスクレイピングでもよく使用されるライブラリですね。
URLを指定するとHTML文を取得することができます。
google-generativeaiは、GoogleのLLMモデルGeminiを使用するためのライブラリです。
入力されたURLからHTML文を取得し、HTML文をそのままテキストとしてGeminiに入力することで、特に複雑なロジックを組むことなく、ページの情報を解析することができています。
まとめ
今回はLLMを使用したスクレイピングツールの紹介を行いました。
このツール内では実装してませんが、LLMでHTMLを解析させた結果、目的のセレクタを特定して、処理を切り替えるようなこともできます。
今後LLMを使った汎用スクレイピング手法が主流になってくる気がしますね。
LLMのさらなる活用法について、是非コメント頂けると嬉しいです!!
以下、有料部分ではHTMLをLLMに入力する際に注意した点について、
実際のコードを見ながら解説していきます。
よろしければご覧になってみてください。
ここから先は
¥ 1,200
Amazonギフトカード5,000円分が当たる
この記事が気に入ったらチップで応援してみませんか?