
ディープラーニングを使った高性能異常検知アルゴリズム

こんにちは。LiNKX株式会社のitoです。
ディープラーニングを使った異常検知を深層異常検知と言いますが、その中でも注目度が高い Gaussian-ADというアルゴリズムの概要を紹介したいと思います。より詳しく知りたい方はこちらのブログも参考にしてください。
Gaussian-ADは、ドイツのアーヘン工科大学のチームが2020年に紹介したアルゴリズムです。普通のPCで軽々と動き、学習にかかる時間はほとんどありません(普通のPCで1分とか2分のレベル。対して、通常ディープラーニングで画像の学習をさせるとGPU付きの高性能PCでも数時間から数日かかったりします)。
それなのに、精度は2020年の異常検知ベンチマーク(MTVec AD)でNo.1というすごいアルゴリズムなのです(PaperWithCode参照)。ちなみに、Gaussian-ADという名前は、このアルゴリズム比較サイトPaperWithCodeで使われているニックネームです(論文では特に名称の指定がありません)。
著者らの公式のプログラムは以下のgithubで公開されています。
下のguthubでも公開されています。私はこちらのプログラムをベースにテスト用のプログラムを作成しました。
1. Gaussian-ADができること
まず、Gaussian-ADができることについて説明します。
画像の異常検知(Anomaly Detection; AD)には、入力画像が正常か異常かを判定するDetection ADと、異常の場所を特定するSegmentation ADがあります。

ここで紹介するGaussian-ADは、前者の「Detection AD」用のアルゴリズムです。
Gaussian-ADは、通常の異常検知アルゴリズムと同様に、入力画像に対して異常度という数値を出力するので、運用時には閾値を設定し、異常度が閾値以上となった入力画像を異常と判定します。
2. 訓練データと学習
100円玉の画像で動作を確認してみました。
10枚の異なる100円玉を使って、100円玉の表(桜側)の「日本国」の文字が上になるように配置し、位置や角度を若干変えながら、合計100枚の画像を撮影しました。画像サイズは640x480ピクセルです。
この100枚を訓練データとします。

次に、これらの訓練データの画像が正常の画像であることをGaussian-ADに教えるため、学習を行いました。訓練データ100枚の学習にかかった時間は、通常のノートPCでたったの24.1秒でした。
3. 動作テスト
準備は整ったので、いろいろなテスト画像を入力して異常度を見てみます。各画像の上の「scr」という数値が、Gaussan-ADが出力した異常度です。
まずは、正常画像の異常度です。130~140くらいの値でした。訓練データには含めていない画像を入力しました。

では異常画像を試します。下の画像は、ゴミ(アルミホイル)が付着している場合です。この3つの例の異常度は全て300以上となりました。正常の範囲(130~140)に比べて十分に大きいので、例えば、閾値を200くらいに設定すれば、これらの画像は全て異常として判定することができます。

下のように、90度回転させた場合ではどうでしょうか。これも異常度は270以上となり、正常の範囲(130~140)より高い値となりました。

ちなみに、「このように回転した画像も正常として扱いたい」という場合には、回転した画像もはじめの訓練データに含めることで対応することができます。
では、裏表が違っていたらどうなるでしょうか。これは画像としてもかなりの違いになりますが、どれくらいの異常度がでるのか見てみると、900以上というとても高い数値となりました。

違うコインだったら?これも680以上というとても高い数値となりました。

とてもよいパフォーマンスですね。
4. 動作テストのまとめ
テストデータとして、正常画像10枚、すべての異常タイプに対して10枚の画像を作り、異常度をプロットしました。横軸が異常度、縦軸が画像番号です。
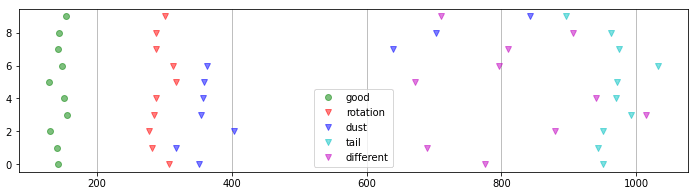
「good」(正常画像)の異常度が150付近であるのに対して、「rotation」(90度回転)、「dust」(ゴミ付着)、「tail」(裏返し)、「different」(違うコイン)のすべての異常画像の異常度が250以上となりました。
正常画像と異常画像の異常度の分布に重なりがないので、(テストデータの範囲では)ミスなしで異常検知ができることを示しています。
別な例も示しましょう。これは、異常検知ベンチマークのデータベースに含まれている「カプセル」の画像です。下の3つは正常画像です。

異常画像にはいくつかタイプがあり、例えば、「squeeze」(歪みの異常)には下のような画像があります。

全てのテスト画像に対して異常度を計算しプロットしたものが下です。

「good」(緑)が正常画像の異常度です。他の異常に対して小さい値をとっていることが分かります。
異常画像の方は、種類によって異常度の大きさがかなり異なっていました。「squeeze」(歪み;赤)は比較的大きい値をとっていますが、「faulty imprint」(印刷不良;水色)と「scratch」(ひっかき傷;赤)は低めで、正常画像の異常の分布と若干の重なりがあります。
4. Gaussian-ADの仕組み
ではGaussian-ADの仕組みについて説明します。
Gaussian-ADは、学習が完了している自然画像の分類モデルを使います。EfficientNetと呼ばれるGoogleが作った高性能分類モデルです。
このEfficientNetは多層の畳み込みディープラーニングモデルですが、下の図のように、9つのレベル(ブロック)に分割することができます。レベルとは、EfficientNetで定義された情報処理の単位で、1つのレベルには同じ種類の層が複数層含まれます。

EfficientNetに画像を入力すると、L1からL9へと情報処理が進みますが、この途中の情報を抜き出すのがGaussian-ADの特徴です。L1での情報処理結果を32次元のベクトルx1として抜き出し、同様に、L2, L3, ..., L9 までの情報処理結果を16, 24, ..., 1280次元のベクトル x2, x3, .., x9として抜き出します。これを特徴ベクトルとよびます。
一番初めのx1 は画像の局所的な特徴をとらえた(局所的な特徴で変化しやすい)ベクトル表現であり、レベルが上がるほど、大局的な特徴をとらえた表現になっていると考えらえます。
これらの特徴ベクトルが正常画像と異常画像で異なることを利用します。学習では、訓練データの正常画像の特徴ベクトルの平均値と分散(正確には共分散行列)を各レベルで求め保存します。
そして、運用時に入力された画像の特徴ベクトルが、保存してある平均値から(分散を加味して)どれくらい異なるかを各レベルで数値化し、最後にその和をとります。それが異常度となります。詳しくは、こちらのブログを参照してください。
5. さいごに
Gaussian-AD、いいですね。いろいろと使い道がありそうです。
レベル毎に異常度を出してまとめるというアイディア、「なるほど!」と思いました。
最後に、あえてGaussian-ADでは難しい異常検知を2点考えてみたいと思います。
1.正常画像のバリエーションが大きいと大変になると考えられます。対象物自体が不定形である場合以外にも、外光が変化したり、対象物への光の当たり方が様々だったり、背景が一定でない場合などで、バリエーションが大きくなるでしょう。
このような場合、訓練データにはそのバリエーションを十分にカバーする量のデータが必要になるでしょう。しかし、バリエーションがカバーできたととしても、その分布がガウス分布で近似しにくくなりパフォーマンスが落ちるという可能性も出てくるでしょう。
2.特定の部分のサイズや面積、角度などが閾値を超えたら異常とするような異常検知には向いていないでしょう。このように異常を数値で定義できる異常検知の場合は、従来のシンプルな画像処理による異常検知で実装する方がよいと思われます。
まとめると、Gaussian-ADは、「正常の製品はほぼ一定だが、異常のバリエーションが様々で数値化できないような場面で力を発揮するアルゴリズム」、と言えるのではないでしょうか。この特性にマッチするお題を見つけて実践で使ってみたいですね。
最後まで読んでいただきありがとうございました!
2021/8/26 TKo氏、YK氏から有用なコメントをいただき、内容を改善させることができました。ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?