
DBテーブルを使った条件分岐削減

注:以下、単に「条件分岐削減」、または単に「削減」と略します。
はじめに
アルゴリズムを学び始める場合、アルゴリズムの基本構造(順次構造、選択構造、反復構造)や、フローチャートの作成などの基礎を学ぶことが多いです。特に、できるだけ多くの演習問題を解き、実践で活用することでアルゴリズムに関するスキルが向上します。
しかし、DBの活用頻度が高いITシステム(ビジネス系システムなど)のプログラムを設計・実装する場合、そのアルゴリズムの基礎に従うだけでは足りません。少なくとも、DBテーブルを活用して条件分岐を減らすこと、つまり条件分岐削減が必要です。条件分岐削減により、「複雑度が下がる」、「(非機能要件の)仕様変更対応性が高くなる」などの利点が得られるためです。
本記事では、条件分岐削減について、まず具体的なイメージを掴むために、複数の例を紹介します。その後、条件分岐削減を活用する利点や必要なスキル、留意点などをまとめます。
実践で役立てば幸いです。
前提
アルゴリズムの前提
本記事で使うアルゴリズの前提は次のとおりです。
アルゴリズムをフローチャートを使って表現する。
条件分岐と関連処理のみ表記する。前後の処理(データの入出力、例外対応、など)は割愛する。
※削減前後を分かりやすくするため。処理名の終わりに「~検索」が、SELECT文により直接データを取得する処理を表す。理由は、DBテーブルを活用していることを明示するため。
※実践ではオブジェクト指向のクラスやAPIなどを活用したほうが
よい場面が多い。SELECT文内で計算式を使わず、フローチャートの処理で表現する。理由は、フローチャートの削減前後で計算式(または値設定)の違いを比較しやすくするため。
DBテーブルの前提
本記事で使うDBテーブルの前提は次のとおりです。
表形式で表現する。
1行目を項目名とする。項目名に下線をつける。
主キー項目の右に「Key」をつける。
仕様の採用元
例1および4~10は、次の参考書籍から抜粋および加工しました。
<参考書籍>
『この1冊でよくわかるソフトウェアテストの教科書 増補改訂第2版
- 品質を決定づけるテスト工程の基本と実践』
(布施昌弘、他/著、SBクリエイティブ/出版)
例1:初歩的な削減
初歩的な対応として、主キー項目(1つ)の値と他項目(1つ)の値が「1:1 の関係」となる場合の条件分岐削減例を紹介します。
仕様

注:参考書籍 Chapter 03『ホワイトボックステストとブラックボックステスト』の
練習問題1より抜粋・加工
削減前のフローチャート
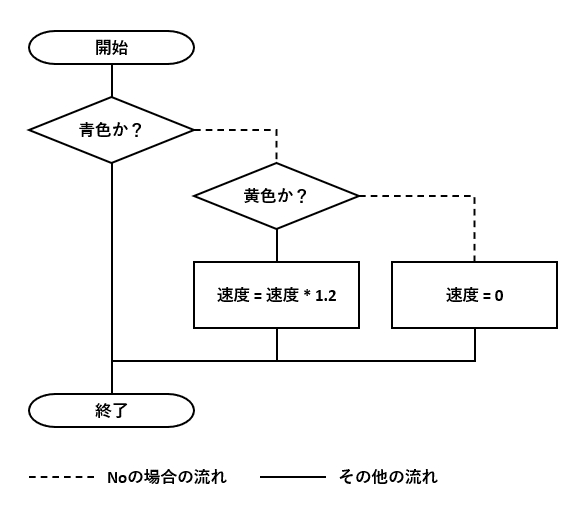
削減後のフローチャート
例1の仕様を元に速度変更率テーブルを作成します。交通信号の色を主キーとし、速度を変更する率を紐づけます。
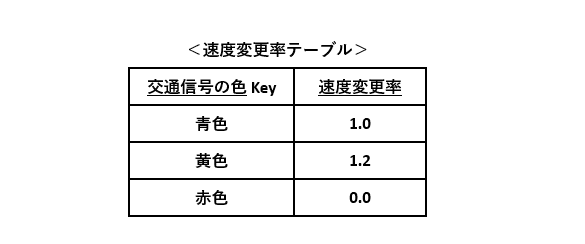
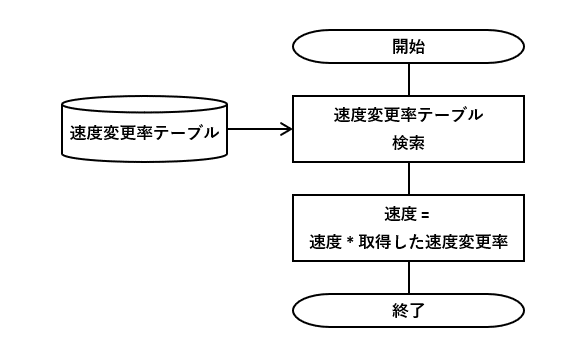
このDBテーブルを使って、図1-1のフローチャートの条件分岐を削減します。
例2:論理演算子 OR の削減 その1
ここでは、主キー項目(1つ)の値と他項目(1つ)の値が論理演算子 ORを使って「n:1 の関係」となる場合の条件分岐削減例を紹介します。
仕様

削減前のフローチャート
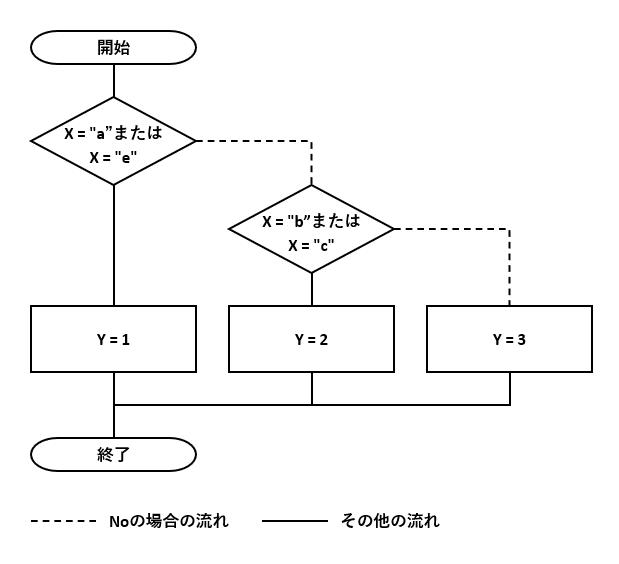
削減後のフローチャート
例2の仕様を元に、X-Y対応テーブルを作成します。区分Xを主キーとし、区分Xの値と区分Yの値を紐づけます。
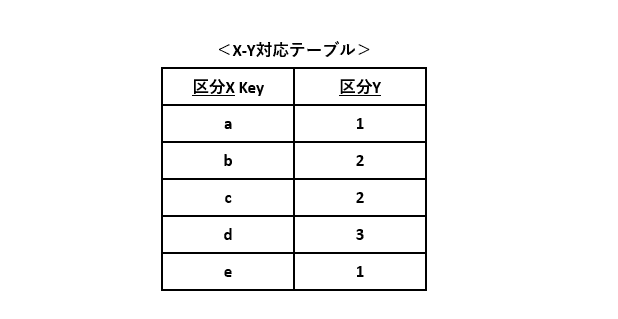
このDBテーブルを使って、図2-1のフローチャートの条件分岐を削減します。図1-3のフローチャートと同じようになりました。
例3:論理演算子 OR の削減 その2
例2の仕様では、主キー項目(1つ)の値がすべて指定されていました。例3では、「その他の値」という指定があった場合の条件分岐削減例を紹介します。
仕様
例2の仕様のうち、①区分Xの値の範囲を「英数字1桁」、②「"d”ならば」を「その他の値ならば」に変更しています。

削減前のフローチャート
(図2-1と同じ)
削減後のフローチャート
例2と同じX-Y対応テーブルを作成します。ただし、「その他の値」に対応する区分Xの値を"#"とします。
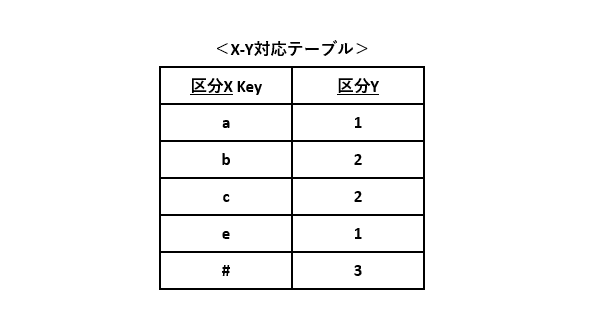
削減後のフローチャートは図2-3と同じなので割愛します。ただし、検索に使うSELECT文は図3-4のようになります。

X-Y対応テーブルに入力値に該当する値があればその行(=”a"~"c"、”e"のいずれかの行)だけが返され、なければ"#"の行(=その他にあたる行)だけが返されるSELECT文です。このようなSELECT文になることを踏まえて、DBテーブルの設計および登録するデータの設計をするのがコツです。
例4:範囲指定
ここでは、条件として上下限の範囲を使う場合の条件分岐削減例を紹介します。項目が増える以外は、例1と基本的な考え方は同じです。
仕様

注:参考書籍 Chapter 04『同値分割テストと境界値テスト』の練習問題2より抜粋・加工
削減前のフローチャート
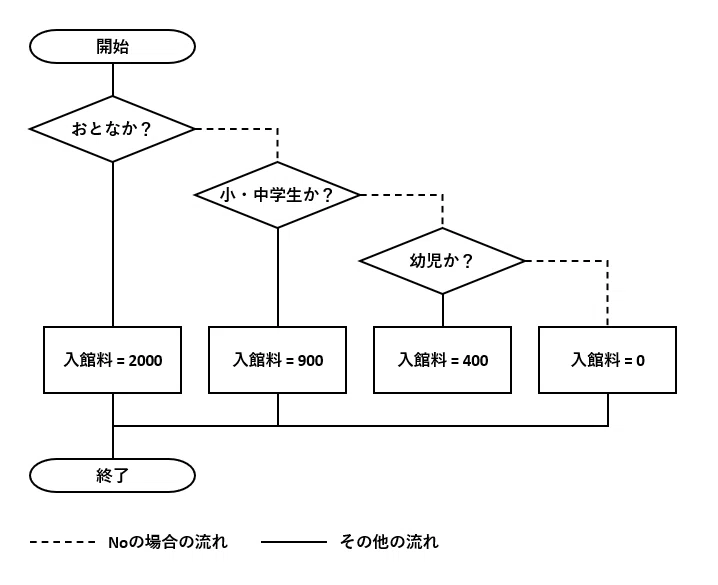
削減後のフローチャート
例4の仕様を元に料金テーブルを作成します。年齢の上限・下限を主キーとし、その上下限に該当する料金を紐づけます。
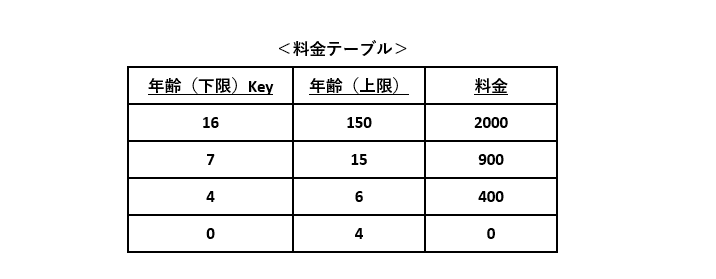
このDBテーブルを使って、図4-1のフローチャートの条件分岐を削減します。
例5:料金改定の考慮
昨今は、物価高に伴う商品価格の改定が目立っています。このように価格に関するデータについて、価格改定への対応が欠かせません。これは、お客様から言われなくても「当たり前に気づく」必要があります(※)。
※価格以外にもありますが、説明を割愛します。
例4は価格に関することですが、価格改定への対応が含まれていません。したがって「仕様どおり」に実装するのは不適切です。価格改定に対応する仕様も組み込んで対応します。
仕様(例4の改訂版)

削減前のフローチャート
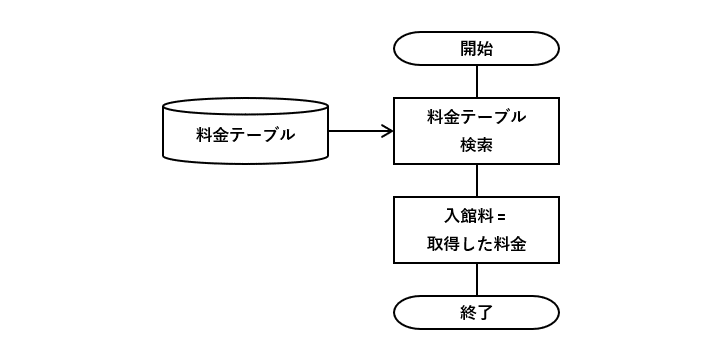
結論からいえば、削減前のフローチャートを作成できません。なぜなら、お客がいつ、いくらで料金改定するのか事前に決められない、つまり「要求定義が不可能」なため。
削減後のフローチャート
例5の仕様を元に料金テーブルに適用開始日を追加し、上映日と比較して料金を求められるように見直します。
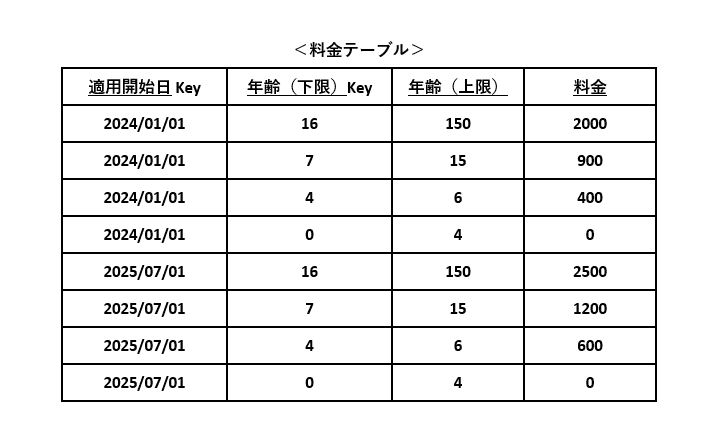
削減後のフローチャートは図4-3と同じなので割愛します。ただし、検索に使うSELECT文は図5-4のようになります。

このSELECT文の作成について、基本的な考え方は例3のSELECT文の場合と同じです。ただし、料金改定の頻度が常識的な範囲に留まり、検索処理性能が大きく変わらない前提です。その前提が崩れるような場合は、DBテーブルの見直しも必要となります。
注:例6以降について、価格等の改定について考慮しません。
仕様にも追加しました。
例6:等号・不等号の使い分け
例4~5の場合で使った不等号は、等号付き(”≦”、”≦")のみでした。そのため、「未満」や「より大きい」などへの対応が面倒な場合があります。そこで、さらに工夫した例を紹介します。
仕様

見出し『隠れた境界値』の例題より抜粋・加工
削減前のフローチャート
削減後のフローチャート
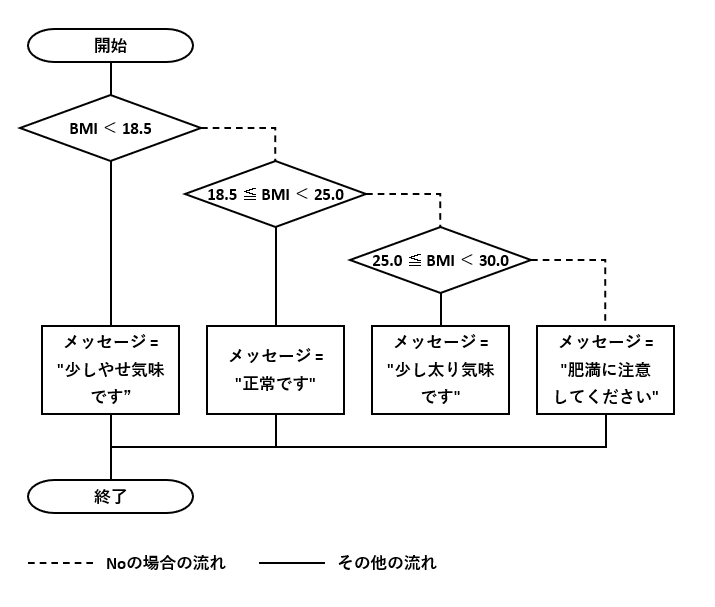
例6の仕様を元にBMI判定テーブルを作成します。上下限の値が異なる行が不等号”<"、同じ行が等号”="を表します。等号を表す行と次の行を組み合わせて不等号”≦”と同じになります。
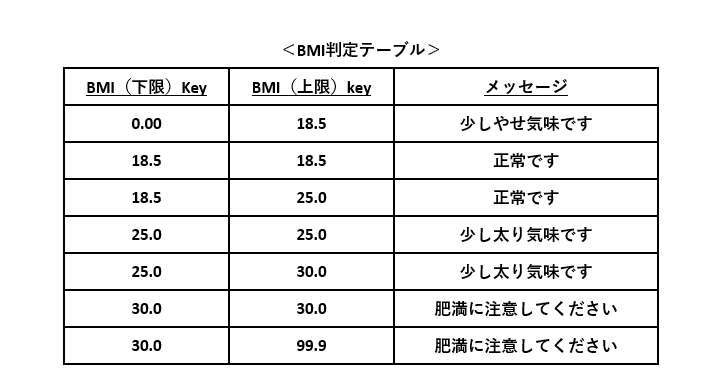
このDBテーブルを使って、図6-1のフローチャートの条件分岐を削減します。
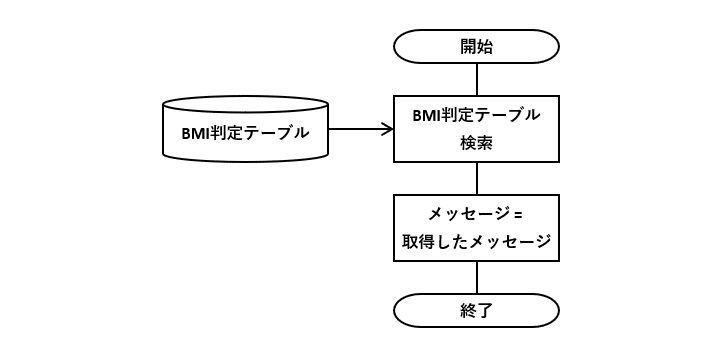
検索に使うSELECT文の例は図6-4のようになります。不等号”<"と等号”="の行を考慮したWHERE句にすることで、仕様を満たせます。

これなら、もし仕様変更により『BMI ≦ 18.5 の場合に「少しやせ気味です」とする』となっても、同テーブルの登録内容を図6-5のように変更すれば済みます。フローチャート(、そしてプログラム)の変更を避けられます。

例7:識別の活用
ここでは、主キー項目(3つ)の値と他項目(1つ)の値が「1:1 の関係」となる場合の条件分岐削減例を紹介します。それだけだと面白くないので、「識別」を活用した例にしました。詳細については後述します。
仕様

注:参考書籍 Chapter 05『デシジョンテーブルテスト』の練習問題1より抜粋・加工
削減前のフローチャート
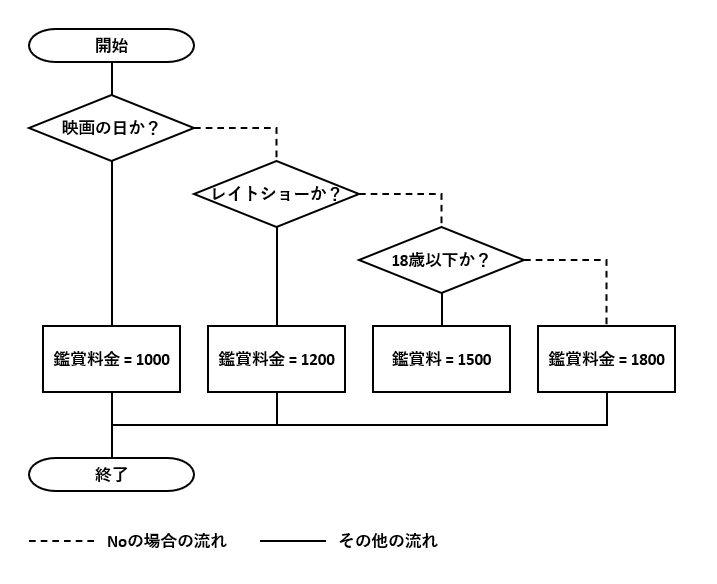
削減後のフローチャート
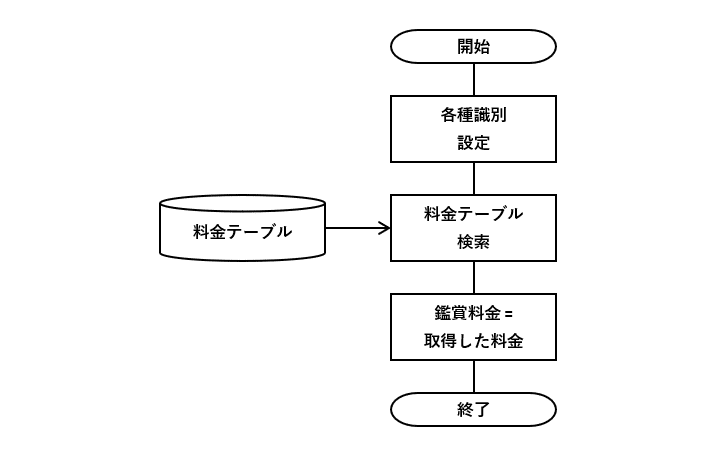
例6の仕様を元に料金テーブルを作成します。各月の日にち(1~31日)や上映時間などを使わず、月初(=1日)かどうかの識別や、レイトショーかどうかの識別などを活用した形式にしました。なぜなら、3つの識別を活用することで、データの組み合わせ数を大幅に減らせるため。それらの識別の組み合わせと料金を紐づけます。
なお、識別の値の意味は、”0”が非該当、”1”が該当を表します。
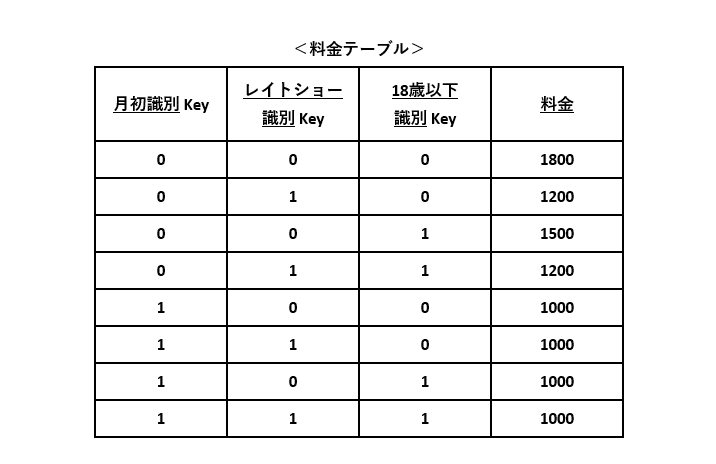
このDBテーブルを使って、図7-1のフローチャートの条件分岐を削減します。なお、3つの識別を設定する処理を追加しています。
補足1)識別の活用がなぜ大事か?
識別を使わなければ、「日にち」(1~31日の31種類)、「上映時」(0~24時の25種類)、「年齢」(0~100歳以上)のすべての組み合わせをDBテーブルに登録しなければなりません。組み合わせ数が約8万以上になり、データ準備の手間が多すぎます。ミスなくデータを準備できる可能性は著しく下がります。
しかも、例5のように料金改定まで考慮すると、組み合わせ数はさらに増加します。そのため、非機能要件の「運用性」が大きく悪化し、お客様の負担が増します。お客様からの強いクレームは発生するのは容易に予想できます。
非機能要件を満たす(あるいは理想状態に少しでも近づける)ためには、識別の活用も視野に入れることが大事です。
補足2:識別を設定する場所
図6-3では、フローチャート内に処理「各種識別設定」を追加しました。実際には、オブジェクト指向のクラスやAPIなどで対応するのが望ましいと思います。
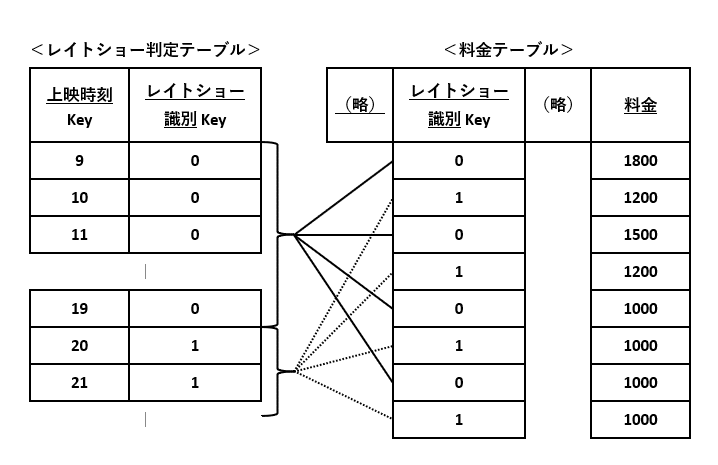
ただ、どうしてもSQLや準ずる方法で対応せざるをえない場合もあります。たとえば、BI(Business Intelligenceの略)ツールや、SAP S/4HANAから追加された実装方法 CDS(Core Data Servicesの略)などを使う場合です。そのような場合は、図7-4のように、複数のDBテーブルを組み合わせて実装する方法が考えられます。
例8:区分と範囲の組み合わせ
ここでは、区分と金額範囲を組み合わせた「1:1 の関係」となる場合の条件分岐削減例を紹介します。ただし、主キー項目の設定を工夫しました。
仕様

見出し『3値以上の答えを持つ条件の採用』の例題より抜粋・加工
削減前のフローチャート
削減後のフローチャート
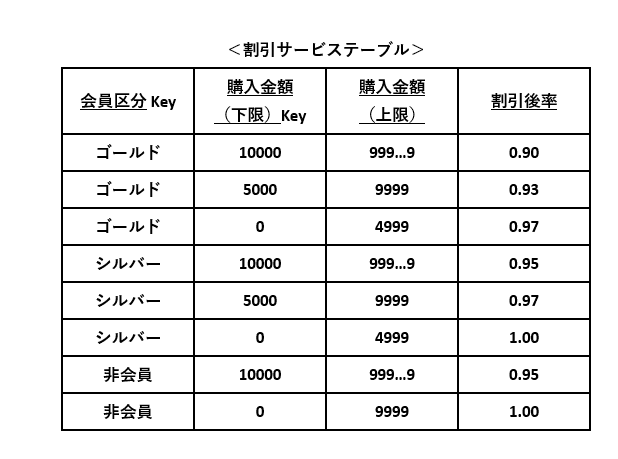
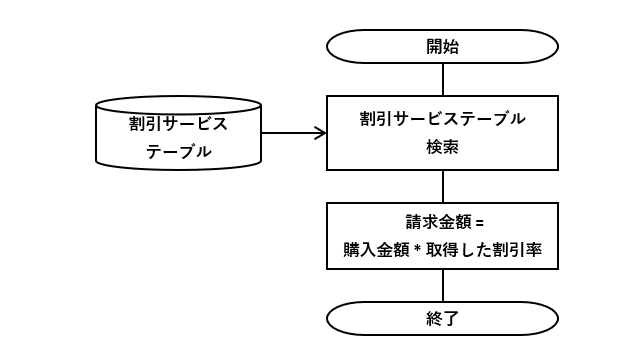
例7の仕様を元に割引サービステーブルを作成します。会員区分と購入金額の上限・下限を主キーとし、それらの組み合わせに該当する割引後率(=1 - 割引率)を紐づけます。
なお、少しでも処理性能を向上するために割引後率を採用しました。また、会員区分と購入金額(下限)が決まれば一意になるため、同(上限)は主キー項目の対象外としました。
このDBテーブルを使って、図8-1のフローチャートの条件分岐を削減します。
例9:条件の一部または全部を満たす判定
前書きは割愛します。まずは仕様をご一読ください。
仕様

上記仕様から、一部の条件(腹囲および2~3項目)を満たすことが求められることが分かります。しかも、5つの項目とも異なるので、例8までのように1つのSELECT文で対応するのは困難です。それを踏まえた工夫が必要です。
削減前のフローチャート
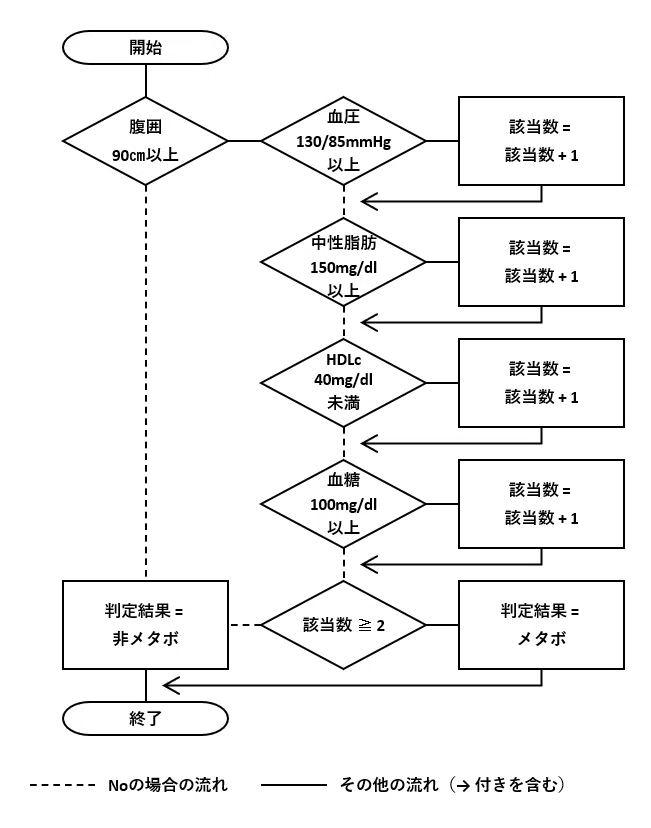
削減後のフローチャート
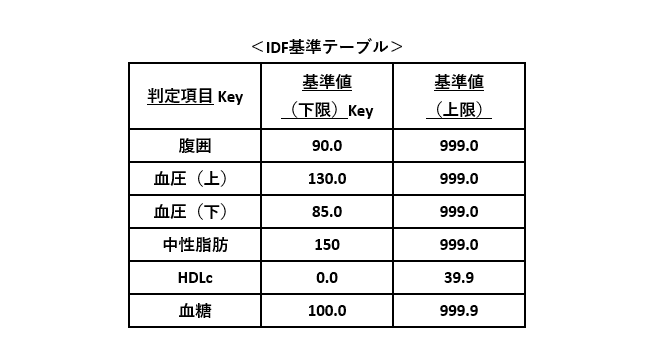
例9の仕様を元にIDF基準テーブルを作成します。判定項目別に基準を満たす範囲を登録し、該当行の有無で基準を満たすかどうかを判定する前提としました。判定項目と基準値(下限)が決まれば一意になるため、同(上限)は主キー項目の対象外としました。
なお、仕様②より例6のような工夫は不要なため、1つのDBテーブルで対応できるように考えました。
このDBテーブルを使って、図9-1のフローチャートの条件分岐を削減します。条件分岐の「取得した腹囲 ≧ 1」で必須条件を満たすかどうか、「かつ取得したその他 ≧ 2」で4項目中2項目以上を満たすかどうかを判別します。
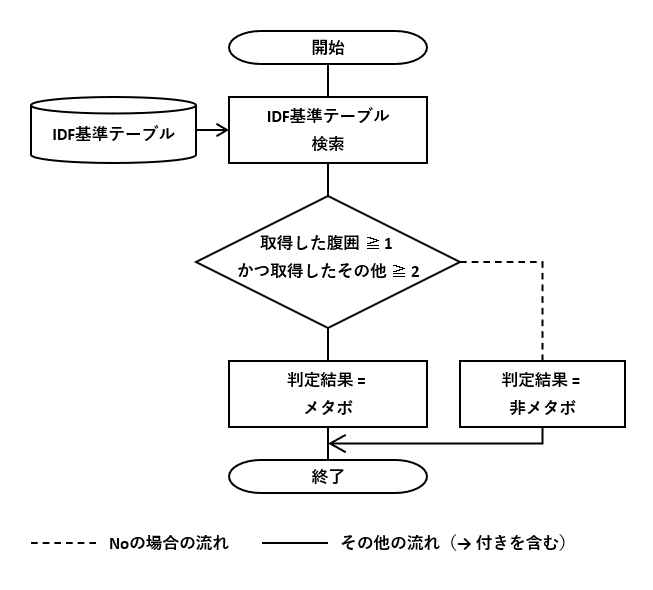
検索に使うSELECT文は図9-4のようになります。複雑そうに見えますが、判別項目別に基準を満たすかどうかを「件数」で返すSELECT文を、UNIONで統合しただけです。必須項目の腹囲と、その他を区別する工夫はしました。

なお、血圧に関するSELECT文が複雑になったのは、血圧(上)と血圧(下)の行を分けたためです。両方を満たせば行数が2になるため、その場合だけ1に変換するCASE式にしました。
IDF基準テーブルのように無理矢理1つのDBテーブルで対応しようとすると、SELECT文も複雑になりやすいです。実践では、そのことも踏まえがDBテーブル設計が求められます。
例10:状態遷移
ここでは、状態遷移の条件分岐削減例を紹介します。
仕様

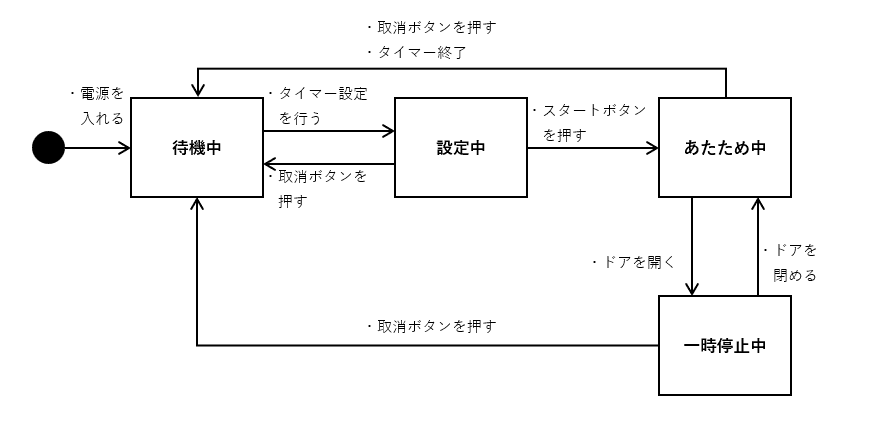
注:参考書籍 Chapter 06『状態遷移テスト』の練習問題2より抜粋・加工
削減前のフローチャート
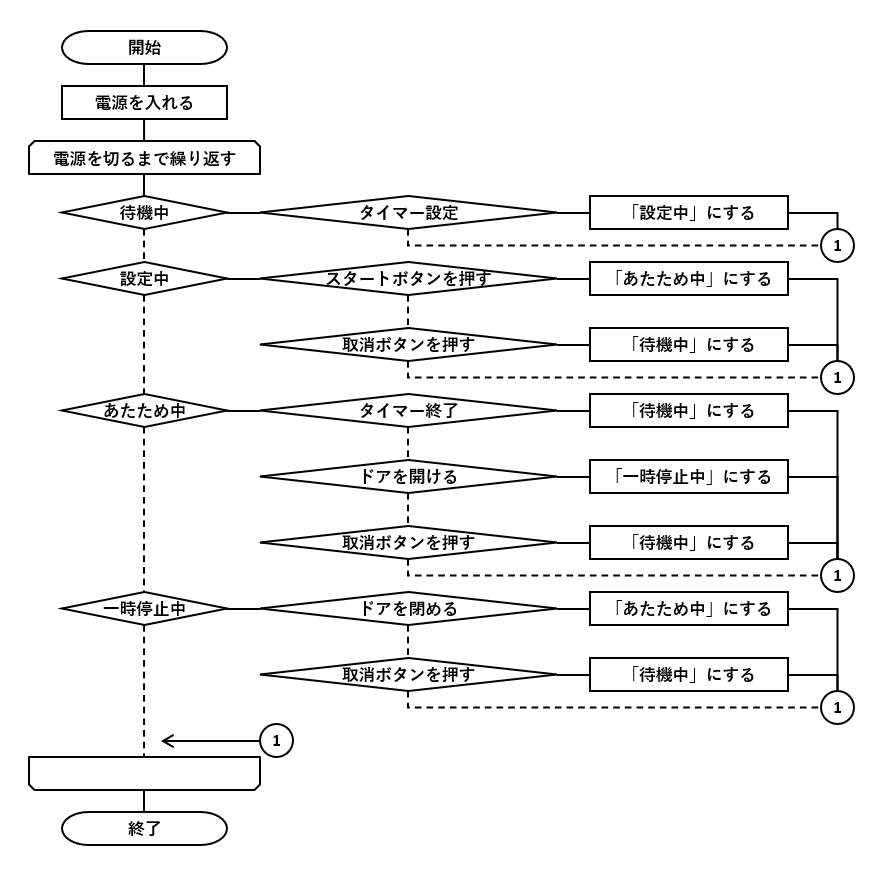
削減後のフローチャート
例10の仕様を元に状態遷移テーブルを作成します。現在の状態(=変更前の状態)と操作の組み合わせと、その組み合わせに対する変更後の状態を登録します。それらの組み合わせ以外、つまりDBテーブルに登録がない場合は、状態を変更しません。

このDBテーブルを使って、図10-2のフローチャートの条件分岐を削減します。フローチャートに変更前の状態と操作の組み合わせをなくせたので、条件分岐が大幅に減りました。
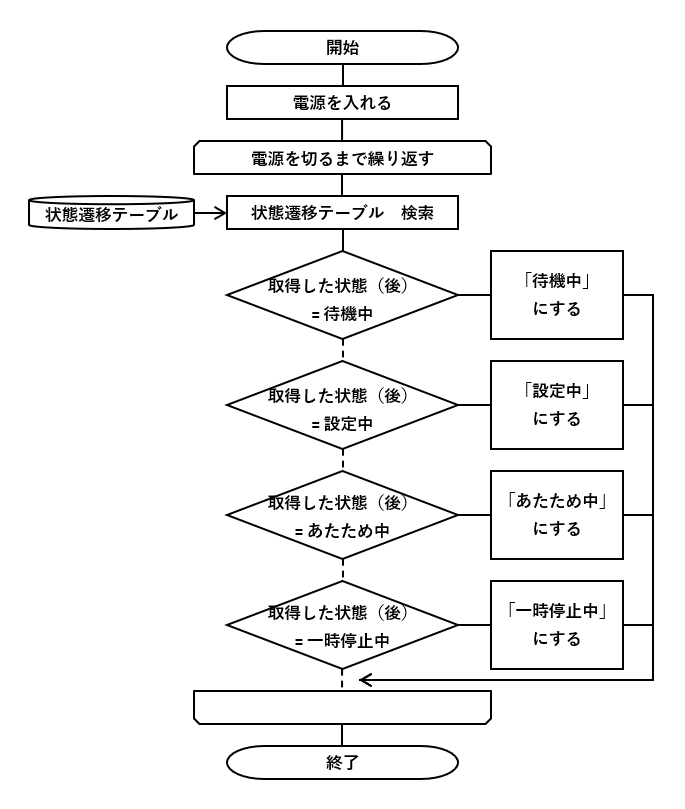
例1~10から言えること
条件分岐削減の主な利点
DBテーブルを使って条件分岐を削減する主な利点を5つ挙げます。
複雑度が下がる
条件分岐が多いほど複雑になります。特に、図1-1のように条件分岐のネスト、いわゆる入れ子構造があると複雑さが増します。一般的に簡素につくるのが望ましいので、できるだけ条件分岐(特に入れ子構造)を減らすアルゴリズムが実践では求められます。DBテーブルを活用することで条件分岐が減り、複雑度も下がります。非機能要件の仕様変更対応性が高くなる
たとえば、例1の速度変更率を1.2から1.3に変更する場合、DBテーブルの値を変更すれば済みます。このように仕様変更対応性が高くなります。要件定義の一部を遅らせられる
仕様変更対応性が高いことから、たとえば、例1の速度変更率の値を「要件定義工程の段階で確定する」必要がなくなります。要件定義工程での値は「仮置き」として進められます。難易度が下がる
複雑度が下がれば、難易度も下がります。不慣れな技術者でも対応できる可能性が高まります。要員調達・調整がしやすくなる、技術者の経験を増やせる、などの利点も得られます。リスク・マネジメントの面で有利になりやすい
上記1~4により、リスク・マネジメントの面でも有利になります。たとえば、①仕様変更対応性により納期遅延リスクが小さくなる、②要員調達・調整の容易性により納期遅延やコスト超過のリスクも小さくなる、など。
条件分岐削減を使うのが望ましい工程
最も望ましい場面は、システム要件定義工程です。主な理由は、①上記利点3にあるように要件定義の一部を遅らせられるため、②DBテーブルの登録・更新機能および運用などの設計も必要になるため、の2つです。
また、DBテーブルがあれば、昨今普及が進むノーコード・ローコード開発(以下、NL開発)の対応もしやすくなります。システム要件定義工程でNL開発を使えば、プロトタイピング手法を活用してシステム要件の精度を上げられるし、うまくいけば実際に使う機能に仕上げられます。
システム要件定義工程が無理なら、基本設計工程の前半か、遅くても基本設計工程中が必要な場面です。
詳細設計工程やそれ以降の工程では遅すぎます。手戻りが大きくなるので。
条件分岐削減に必要なスキル
私は自分の経験から、次の3つのスキルは少なくとも必須だと考えています。なお、プログラミング・スキルについては任意です。
表形式で表せることに気づけるスキル
このスキルがあることは必須です。DBテーブル設計やSELECT文に詳しくなくても構いません。表形式で対応できそうだと気づければ、DBテーブル設計やSELECT文に詳しい技術者に相談すればよいだけなので。気づかなければ、ChatGPTに質問することも不可能です。SELECT文をすぐに思い浮かべられるスキル
少なくとも例1~8で紹介したSELECT文の例ぐらいはすぐに思い浮かべられるスキルが必須です。いずれの例も難しいSELECT文ではありません。それでも、一般的な演習問題をこなしただけでは、図3-4のSELECT文の例のような工夫には気づけないと可能性が高いです。そのことを踏まえてスキルを磨くことが求められます。
できれば、図9-4のようなSELECT文の例にも気づけるスキルがあるのが望ましいです。私の経験からいえば、多くの事例から学ぶのが良いと思います。一般的な書籍や演習問題では見たことがないので。基本的なフローチャート作成スキル
このスキルがあれば、例1~10の削減前のフローチャートを、手書きで紙やホワイトボードなどにスラスラと描けます。精度よりスピードです。素早く描ければ、短時間で何度も見直せるので。
条件分岐削減についての留意点
まず基本的なフローチャート作成スキルを身につける
上記必要なスキルの3で書いたように、削減前のフローチャートをスラスラ描けるスキルを習得することが大事です。このスキルを習得するために、新人研修や初歩的な演習などで学び、実践を繰り返すことが多いと思います。条件分岐削減スキルは、その後に学ぶのが望ましいです。
一般的なデータモデリングの知識・スキルだけでは足りない
たとえば、情報処理技術者試験の一つ「データベーススペシャリスト試験」の試験勉強をして満点が取れる実力があったとしても、一部の条件分岐削減しか対応できません。なぜなら、一般的なデータモデリングは全社のデータやシステムが扱うデータなどを整理してデータモデルをつくる手法(正規化やERD、など)を重視しているので。例1~10の仕様などからつくる過程でそれらの手法以外の方法も必要です。DBビュー(または準ずる実装技術)の場合も同じ
DBビューは「SELECT文の部品」です。そのため、DBビューを作成する場合も上記必要なスキルの2が必要になります。
または、DBビューはBIシステムなどでも使われる実装技術です。BIシステムではプログラミング言語を使わずに、DBテーブルとSELECT文の組み合わせで対応することがほとんどです。DBビューを設計する際も、DBテーブルとSELECT文も踏まえる必要があります。条件分岐削減スキルと重なる部分が大きいです。
なお、DBビューに準ずる実装技術として、例7の補足で触れたCDSが該当します。CDSを設計する場合も、DBテーブルとSELECT文も踏まえる必要があります。CDSの実装技術を学んだだけでは設計できません。このことも留意してください。