
SELECT文の処理性能向上 5つの基本

SELECT文の処理性能を向上させるための5つの基本とは?
SQL処理性能を向上させる多くのヒントが、次のSAP社記事にまとめられています。
<SAP社記事>
パフォーマンスに関する注記(SAP ライブラリ)
この記事の「5 つのルール」のうち、ABAP固有ルールを除いた部分を私は「5つの基本」としました。また、各基本の表現は、同ルールのままとしました。
結果セットを小さく保つ
転送するデータ量を最小限にする
データ転送数を最小限にする
検索オーバーヘッドを最小限にする
データベース負荷を軽減する
前提知識
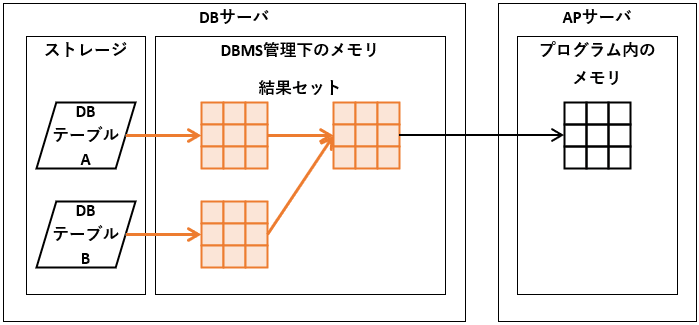
図Aは、SQLを処理するDBサーバと、プログラムが動くアプリケーション・サーバ(以下、APサーバ)の関係を表しています。なお、プログラムが発行したSQL文の流れは割愛しています。

主な要点は、次のとおり。
DBテーブルの実体は、ファイル
注:SAP HANAなどのインメモリDBの場合は、メモリ結果セット(Result Set)は、DBMS管理下のメモリ内の表
DBサーバとAPサーバの間で、ネットワーク通信が発生
注:サーバの処理性能より、同通信性能は大きく劣るプログラムは、SELECT句で指定した表をメモリに反映
注:結果セットと同じ表とは限らない
なお、私以外の「結果セット」の意味として、プログラムに返される表を指す場合もあります。ご注意ください。
以下、基本1~5について説明します。
基本1.結果セットを小さく保つ
一般的な対応:ローストア型のDBMSの場合
基本1の対象は、図1-1のとおり。

結果セットを小さく保つために最もよく使うのが、WHERE句です。DBMSは、DBテーブルからWHERE句で指定した条件に合致するデータを取り出し、結果セットを作ります。
複数のDBテーブルをJOIN句で結合する場合、DBMSは図1-2のように結合した新たな結果セットを作ります。
なお、ローストア型DBMSの場合、DBテーブルから直接作られる結果セットには、DBテーブルのすべての項目が含まれます。
一般的な対応:カラムストア型DBMSの場合
カラムストア型DBMSの代表例がSAP HANAです。カラムストア型DBMSの場合、ローストア型DBMSと同じ対応の他に、SELECT句の項目を減らすことも有効です。カラムストア型の場合、カラム(列=項目)単位で処理されるためです。
例外的な対応:正規化崩し
データモデリングの基礎技法として「正規化」があります。正規化を守ってDBテーブルを実装することで多くの利点が得られます。その正規化をでは、「導出項目を持たない」が原則です。
正規化を守ったDBテーブルを使ったSELECT文の例が、次です。そのSELECT文で単価と数量から、金額を導出しています。

このSELECT文の場合、DBMSは次の①~③のように処理します。
① DBテーブルの全データを使って結果セットを作成
② ①の結果セットに金額を追加
③ ②の結果セットからWHERE句に該当する行の金額をプログラムに返す
SQLの処理性能を大きく悪化させる一番の原因は、上記①~②であることが多いです。なぜなら、DBテーブルのデータ量が増えるにつれて、結果セットをつくる処理量および消費メモリ量も大きくなるため。
SQLだけでは処理性能を向上させることができない場合、正規化を崩してDBテーブルに導入項目を持たせます。

基本2.転送するデータ量を最小限にする
一般的な対応
基本2の対象は、図2-1のとおり。

基本2は、DBサーバとAPサーバ間のネットワーク通信量を減らすこと、と言い換えられます。基本1以外に、SAP社記事にある次の3つの方針に沿って対策を考えます。
行数の制限
SELECT文のLIMIT句(※)やDISTINCTを使用する、など。
※ABAPの「UP TO n ROWS」はNative SQLのLIMIT句に変換されます。列数の制限
SELECT句で必要な項目に限定する、など。集計機能の使用
集計結果が必要な場合は、GROUP BY句を使う。プログラムで集計しない。
例外的な対応
SELECT文でデータ加工(計算や文字列操作など)してデータ転送すると、転送するデータ量が増えます。基本2に反します。
一方、基本2を守るため、プログラムでデータ加工するとプログラム処理が複雑になります。初期の実装工数が増加する、仕様追加・変更がしにくくなる、などの弊害を生みます。
どちらがいいかは、システム環境(コンピュータの性能やプログラミング言語の仕様など)やプロジェクトの都合を踏まえて決めることになると思います。
私は、特に制約がなければ、SELECT文(やDBビュー)でデータ加工する方法を採用します。なぜなら、ノーコード開発ツールやBIツールが普及しているので。プログラムではなく、SELECT文等でデータ加工したほうが統一化が図れます。
基本3.データ転送数を最小限にする
一般的な対応
基本3の対象は、図3-1のとおり。

基本3は、プログラムがSELECT文を発行する回数を減らすことを指しています。その回数を減らすため、たとえば、次のように対応します。
同じようなSELECT文を一つにまとめる
同じようなSELECT文を発行する代表例が、①ループ文の中でのSELECT文発行、②同じSELECT文を複数個所で発行。
①の場合、ループ文の前後で一つのSELECT文で対応するようにします。
②の場合、1回目のSELECT文発行で取得した値を変数に格納し、以降その変数の値を使うようにします。SELECT文の結合(JOIN)や統合(UNION)、サブクエリを活用する
結合や統合、サブクエリを使うことで、SELECT文の発行回数を削減します。
なお、1つのSELECT文で結合等を多用すると読みにくくなる、いわゆる可読性が悪くなる可能性が高くなります。特に、サブクエリには注意が必要です。サブクエリを使う場合はWITH句を用いると可読性が良くなります。
例外的な対応
同じようなSELECT文を一つにまとめられない場合は、たとえば、次のように対応します。
ループ内で上記②を採用
まず変数に該当する値があれば、その値を使います。ない場合にSELECT文を発行し、変数に格納します。上記②をクラス化
オブジェクト指向のクラスを使えば、「変数と処理を一体化」できます。その特徴を活かし、クラスのメソッドに上記②の変数と処理を実装します。プログラムは、そのクラスをインスタンス化して使います。
【参考】クラス化の大きな利点
一般的にクラス化する大きな利点は再利用できること。複数のプログラムで同じ「変数+処理」を使えます。
また、1つのクラスを複数のインスタンスにできることも大変便利です。たとえば、得意先クラスから受注先インスタンス、出荷先インスタンスをつくって使い分けします。
クラスを使うことで、コーディング量が減り(→ 生産性向上)、バラツキも小さくなります(→ 品質向上)。積極的に活用しましょう。
基本4.検索負荷を最小限にする
一般的な対応
基本4の対象は、図4-1のとおり。

基本4を守る方法は、大きく2つに分かれます。
方法1:DBインデックスを活用する
SAP社記事も採用しています。なお、DBインデックスについては、同記事を参照してください(※)。
※一次索引、二次索引はSAP固有の用語ですが、どちらも一般的なDBインデックスです。一次索引はDBテーブルと一緒に実装されるDBインデックス、二次索引はその他のDBインデックスを指します。方法2:WHERE句の条件をカーディナリティが高い項目順に並べる
まず、FROM句のDBテーブルの項目を上記順に並べます。次にJOIN句があれば同じように並べます。こうすることで、効率よく対象データを絞り込めます。
例外的な対応:正規化崩し
正規化崩しをして、上記方法1〜2が使えるようにします。詳しいことは割愛します。
基本5.データベース負荷を軽減する
一般的な対応
基本5の対象は、図5-1のとおり。

基本5は、DBMSのSQLバッファ機能を活用することを指します。DBMSがSQLバッファを使う工夫が必要です。たとえば次があります。
複数のプログラムで、SELECT文を共通化を図る
個々のソースコードにSELECT文を書くのではなく、共通プログラムやクラスを活用します。大文字の英字を使ってSELECT文を書く
私自身は試したことはありません。複数のネット記事などで書かれていました。皆さん自身で試してみてください。
例外的な対応
基本3で説明した変数のような使い方をして、APサーバ内で完結させます。結果として、DBサーバの負荷が減ります。
ABAPの場合
ABAPプログラムは、ABAP Platform(旧SAP NetWeaver)上で動きます。ABAP Platformには専用のバッファ「テーブルバッファ」があります。これを活用することでDBサーバの負荷が減ります。詳しいことは、SAP社記事を参照してください。

【参考】ABAPの仕様拡張
SAP社記事が書かれたのは、2世代前のERPパッケージ(SAP R/3)の時です。今のERPパッケージはSAP S/4HANAです。SAP S/4HANAのDBMSは、SAP HANAのみです。SAP社はSAP HANAの能力を最大限活かす方針、いわゆる「コードプッシュダウン」(Code Pushdown)を謳っています。
それに合わせて、ABAP SQL(旧Open SQL)を標準SQL(のSQL92)にほぼ準拠させた仕様に拡張されています。今まで以上にSQLスキル、特にSELECT文に関するスキル向上が求められます。
ABAP SQLについて、主な仕様拡張を以下に挙げます。
計算式や関数、条件式(CASE式)の追加
WITH句の追加
注:SELECT文内に別のSELECT文を書く形式のサブクエリに関する仕様は今までどおり。この形式はFROM句やJOIN句で使えないので、WITH句で補完します。統合(UNION、UNION ALL)の追加
また、従来の慣習も改める必要があります。たとえば、次です。
結合(JOIN)を積極的に活用する
SAP ECCまでは、JOIN句の使用に制約がありました。具体的には、JOINできないDBテーブル(クラスタテーブルやプールテーブルなど)があったため。ABAPプログラムで結合処理せざるをえませんでした。
SAP S/4HANAでは、すべて一般的なDBテーブル(SAP用語でいえば「透過テーブル」)になったので、上記制約がなくなりました。
※欄外にもう1つ補足します。カーディナリティが大きい項目順に並べる
SAP HANAにはDBインデックスがない、と思ってよいです。そのため、基本4の方法②を採用します。
たとえば、DBテーブル BKPF の主キー項目は「会社コード、伝票番号、会計年度」の3つです。SAP ECCまでは、WHERE句の条件を主キー項目順に並べるのが正しい考え方でした。なぜなら一次索引に合致する、つまり、基本4の方法①どおりなので。
一方、SAP HANAにはDBインデックスがないため、「伝票番号、会社コード、会計年度」または「伝票番号、会計年度、会社コード」の順に並べるが「正しい考え方」になります。
上記1の補足
JOIN句の使用を避ける理由として、「JOIN処理は遅い」を挙げるSAPのコンサルタントや技術者が少なくありません。おそらく、SAP R/3が普及し始めた頃のDBサーバが非力だったことが起因していると思います。SAP ECCが発売された頃にはDBサーバの処理性能が向上したにも関わらず、「JOIN処理は遅いからABAPプログラムで対応する」という慣習だけが残ったと私は考えています。
DBインデックスについての正しく学ばないまま、慣習を重視してしまった弊害かもしれません。注意しましょう。上記2の補足
「会社コード、会計年度」と「会計年度、会社コード」のどちらかにするかは、SAP S/4HANAシステムを使う会社の数や年度の数によります。
まとめ
図Bは、図Aに基本1~5の対象を反映した状態です。SELECT文の処理性能を向上させるために、基本1~5が抜け漏れおよび重複がない状態、つまりMECEになっていることが分かります。

基本1~5について理解すれば、実践スキルを高められます。