
【工事中】3つのデータモデルとエンティティ

本記事の前提
私は、本記事の内容を、データモデリングに関する一般的な知識やスキル(※)がある方が読む前提でまとめました。「ERD」や「正規化」、「多重度」などの一般的な用語については説明しません。
※IPAのデータベーススペシャリスト試験などで求められる知識やスキル
を指します。
3つのデータモデル
3つのデータモデルとは?
ここでいう「3つのデータモデル」は、次を指します。
概念データモデル
概念エンティティ(後述)と、それらの間の関係を表したデータモデル。 主に概念ERD(後述)を使って表現する。論理データモデル
概念データモデルを正規化やスーパータイプ化などして整理し直したデータモデル。主に論理ERD(後述)を使って表現する。
注:一般的には、単に「ERD」という表現は論理ERDを指す場合が多い
ようです。物理データモデル
論理データモデルをITシステムが使えるように変換・加工したデータモデル。ただし、システム都合のデータモデルを追加する場合が通常。
以上は、私が説明しやすい定義です。IPAの情報処理技術者試験やDMBOKなどの定義とは違う部分もありますが、ご了承ください。(以下、同じ)
【参考】DMBOKの定義
DMBOK 2.0では、3つのデータモデルを次のように説明しています(※)。
概念データモデル
概念データモデルには、関連する概念の集合体としてデータ要件の概要が取り込まれる。ここには、特定の領域や業務機能に関する基本的で重要なビジネスエンティティのみが含まれる。各エンティティの説明とエンティティ間のリレーションシップが含まれる。論理データモデル
論理データモデルは、詳細なデータ要件が表現されたものであり、通常、アプリケーション要件のような特定の使用シナリオに適応する。論理データモデルも技術や具体的な実装上の制約から独立している。論理データモデルは概念データモデルの拡張として始まることが多い。物理データモデル
物理データモデル(PDM)は詳細な技術的ソリューションを表す。このモデルは論理データモデルを出発点として作成されることが多く、そこからハードウェア、ソフトウェア、ネットワークツールを組合わせた環境に適応するように設計される。物理データモデルは特定のテクノロジ向けに構築される。(略)
※DMBOK 2.0の抜粋元
第5章「データモデリングとデータモデル」
→「1.3.5 データモデルの詳細レベル」
【参考】SAP社の定義
SAP社は、次の記事にある「データ抽象化の 3 つのレベル」で、3つのデータモデルを説明しています。
記事「データモデリングとは? | 定義、重要性、& タイプ | SAP Insights」
エンティティの定義
DMBOKにおける「エンティティ」の定義
DMBOK 2.0では、エンティティを以下のように定義しています(※)。
データモデリングを離れて一般的にエンティティとは、他のものから分離されて自立している存在と定義される。データモデリングの世界でエンティティとは、ある組織が情報を収集する対象のことである。エンティティは、組織が使う名詞と呼ばれることもある。エンティティは、誰が、何を、いつ、どこで、なぜ、どのように、といった基本的な疑問詞やその組み合わせに対する解答と考えることができる。表7は一般的に使用されるエンティティの分類定義(Hoberman、2009)と例を示している。

エンティティという一般用語は、違う名称で呼ばれることがある。最も一般的なものはエンティティタイプであり、表現対象のタイプを意味する。「ジェーンは従業員というタイプである」と言った場合、ジェーンがエンティティであり、従業員はエンティティタイプである。しかし今日では、従業員がエンティティであり、ジェーンはエンティティインスタンスとする言い方が広く普及している。
※DMBOK 2.0の抜粋元
第5章「データモデリングとデータモデル」
→「1.3.3.1 エンティティ」
私が使っている「エンティティ」の定義
私が普段使っている「エンティティ」は、DMBOKの定義とほぼ同じです。主に違う点は、次です。
概念データモデルで使うエンティティを「概念エンティティ」と呼ぶ。
論理データモデルで使うエンティティを「論理エンティティ」と呼ぶ。
物理データモデルの場合は、「エンティティ」を使わずに実装方法名を使う。たとえば、「DBテーブル」、「DBビュー」、「API」など。ただし、開発ツールなどで「エンティティ」を使う場合は、それに従う。
上表のエンティティカテゴリーを拡張して、6W3Hを使う。
詳しくは、以降で説明します。
概念エンティティ
概念エンティティとは?
私は、概念データモデルで使うエンティティを「概念エンティティ」と呼んでいます。「システムのユーザー(特に業務ユーザー)が使うデータの管理単位」と説明することが多いです。そのほうが便利なので。
概念エンティティの単位は、ユーザーが使う単語などが該当します。たとえば、表7の例に上がっている単語の単位です。
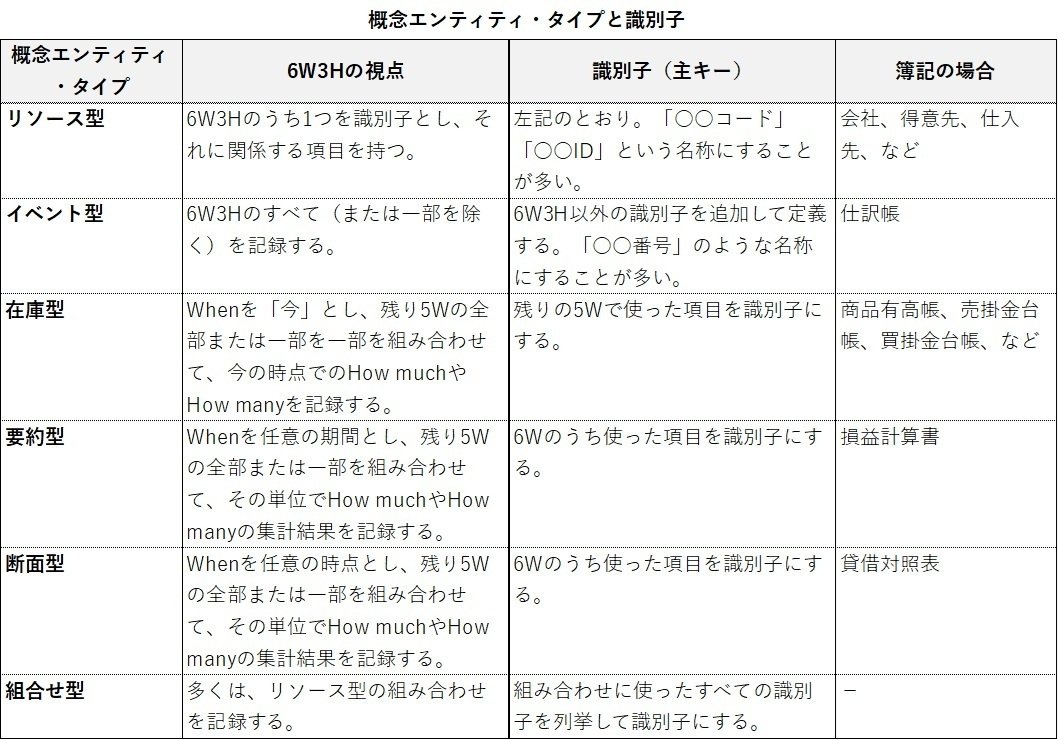
概念エンティティ・タイプと識別子
私は、概念エンティティを下表のような6つの型(タイプ)に分け、「概念エンティティ・タイプ」と呼んでいます(※)。分け方のコツは、6W3Hの使い方です。このような使い方をすれば、個々の概念エンティティを整理しやすくなります。
※「組合せ型」を除く5つの概念エンティティ・タイプの名前や基本的な
考え方は、椿正明氏の次の書籍にある「エンティティ・タイプ類型」を
採用しました。
書籍『名人椿正明が教えるデータモデリングの技
- データ中心システム開発原論』(椿正明/著、翔泳社/出版)
概念エンティティ・タイプにより、識別子もある程度決まります。データモデリングの初心者でも識別子を決めやすくなります。
識別子の多くは、物理データモデルの「主キー」になる重要な項目です。
物理データモデルの「主キー」はシステム開発が進めば進むほど変えにくい項目なので、上流工程(~基本設計)で確定しておくことが欠かせません。それほど、重要な項目が「識別子」です。概念エンティティ・タイプおよび概念エンティティを使うことで、経験や勘に頼る部分が減り品質を上げやすくなります。
もちろん、識別子の決め方にも例外はあります。たとえば、特定の契約に
基づいた在庫です。この場合は、イベント型と在庫型の組み合わせが必要になります。
概念エンティティと採番規則
ここでいう「採番規則」は、概念エンティティの識別子の値を具体的に決める規則です。「コード定義」などのように呼ぶこともあります。採番規則が違えば、概念エンティティも分けます。理由は、採番規則が違えば、データの管理単位も異なるためです。
たとえば、お客様からの注文の受け方が、Web経由と営業員経由で採番規則が異なる場合は、次の2つのような概念エンティティに分けます。
なお、角括弧[]は概念エンティティを表します。(以下同じ)
[受注(Web)]、[受注(営業員)]
ただ、これだと不便な場合もあるので、スーパータイプとして[受注]も
併用するのが現実的だと思います。
概念エンティティ・タイプと「マスタと取引」の区分との関係
概念エンティティ・タイプ、あるいは似たような区分は、私の経験では、一般的ではないようです。「マスタ」と「取引」(または「トランザクション」)の区分を使うことのほうがほとんどでした。後者の区分は分かりやすく、多くの場合は次の対応でも問題ありません。
リソース型 ⇔ マスタ型
その他の型 ⇔ 取引型(またはトランザクション型)
ただし、次の2点に注意してください。
マスタ型、取引型の区分は、識別子の定義に使えない。別の方法が必要。
イベント型だが、マスタ型として使う場合もある。
上記2の代表例が「基本契約」です。基本契約は、具体的な注文などの個別契約を締結する際の「共通的な約束事や条件など」をまとめたものです。基本契約は、「契約」の一つなので、概念エンティティ・タイプは「イベント型」です。そのため、識別子も「基本契約番号」のような項目になります。しかし、使い方は「マスタ型」と同じです。
概念ERD
概念ERDとは?
概念ERDは、概念エンティティを使って描いたERDを指します。使い方の多くは一般的なERDと同じです。
概念ERDを読む際の留意点 その1
まず、具体例を使って説明します。
在庫販売の出荷業務の場合、次の2つの概念エンティティと、リレーションシップが考えられます。
なお、概念エンティティの右にある括弧()は多重度(カーディナリティ)を表します。(以下、同じ)
[受注](m):[在庫出荷](n)
ビジネスの状態は時間と共に変わります。たとえば、下表のような状態が考えられます。

このように表形式でまとめておくと、業務要件の抜け漏れも防ぎやすくなります。私は、このような表を「状態別概念ER表」と呼んでいます。
【コラム】状態別概念ER表を使う場合の大事なコツ
そのコツとは、上表でいえば、該当しない多重度があった場合、考えられる状態例に「該当なし」のように記述すること、です。該当しない多重度の行がないと、「該当なし」なのか「検討不足(や考慮漏れ、など)」なのかが区別できません。後者のような状態を避けるためにも、このコツは忘れないようにしましょう。
【コラム】SAP ERPの多重度
受注と在庫出荷について、「m:n」のような業務要件は私も経験がありません。
しかし、SAP ERPソフトウェアでは標準機能が「m:n」に対応しています。
お客様の業務要件がないにも関わらず、「使ってしまった場合にどうするか?」という要件を検討せざるをえませんでした。
概念ERDを読む際の留意点 その2
こちらも具体例を使って説明します。
在庫販売の請求業務の場合、次の2つの概念エンティティと、リレーションシップが考えられます。
[在庫出荷](1):[請求](1)
注意が必要なのは、請求内容の変更や、請求取消などの対応です。請求は会計仕訳と「1:1」で紐づけるのが基本です。会計仕訳を変更/取消する場合は、その仕訳を相殺する会計仕訳を登録し、変更時はさらに新たな会計仕訳を登録します。したがって、請求も同じ考え方で処理する必要があります。
そのため、システム実装を考慮すると、上記リレーションシップは次のように変わります。
[在庫出荷](1):[請求](n)
したがって、業務要件としてのリレーションシップと、システム要件としてのリレーションシップが異なります。「分割請求がある」ような誤解をしないよう、留意してください。
概念ERDを作る際の留意点
一般的なERDの作り方については、さまざまな参考書がたくさんあるので、そちらを参考にしてください。
私からは、1つだけ留意点をあげます。それは、下図左の[品目]と下位の概念エンティティのように、複数の概念エンティティをスーパータイプとサブタイプの関係にまとめた場合の留意点です。
下図の場合、概念エンティティ[受注]とのリレーションシップは、[品目]に対する一部のサブタイプのみ対象となります。
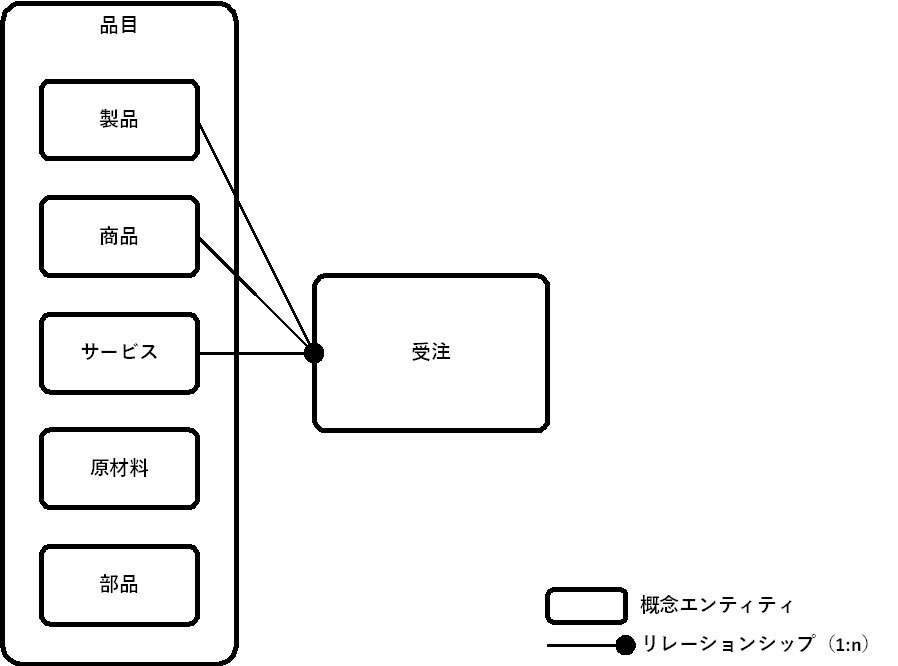
スーパータイプとサブタイプを使うことは、データモデルの共通化・簡素化には有用です。しかし、共通化・簡素化を重視しすぎて下図のような概念ERDにしてしまうと、上図の情報が失われてしまいます。これは、論理ERDの場合も同じです。そのようなことにならないよう注意してください。

論理エンティティと論理ERD
論理エンティティとは?
私は、論理データモデルで使うエンティティを「論理エンティティ」と呼んでいます。
論理ERDとは?
論理ERDは、論理エンティティを使って描いたERDを指します。一般的なERDは論理ERDを指す場合が多いと思います。
ただし、下図の基本型A~Cのように、概念エンティティとの関係も示す場合もあります。
論理エンティティと概念エンティティとの関係
私の経験でいえば、下図の3つの基本型に分かれます。さらに、基本型Bと同Cを組み合わせた場合もあります(注:複雑になるので、説明は割愛します)。
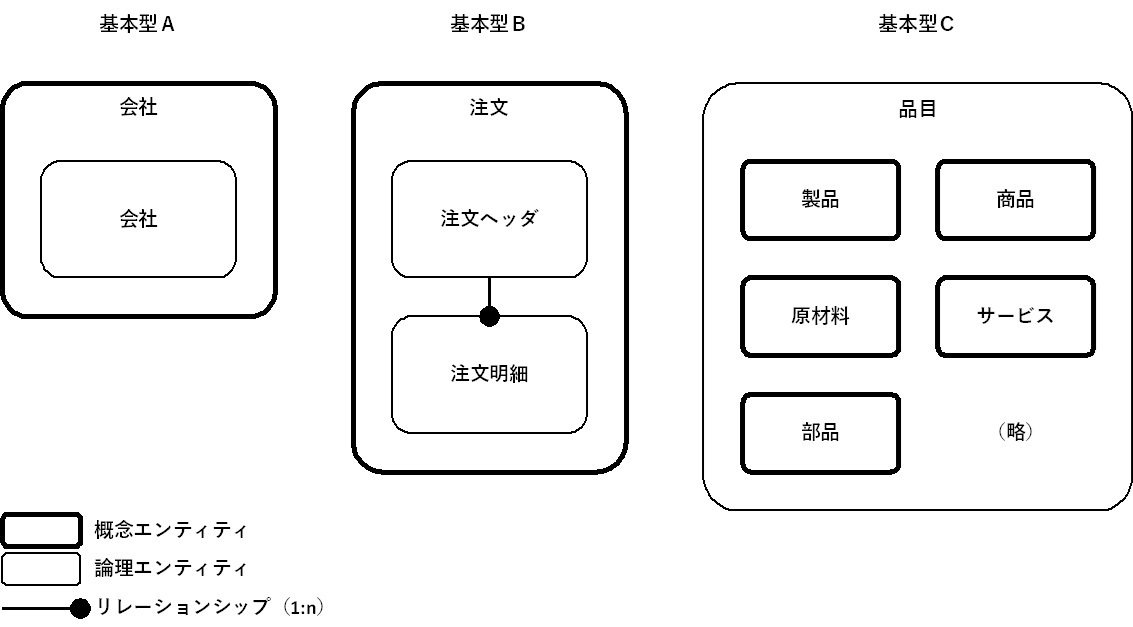
基本型Aは、概念エンティティがそのまま論理エンティティになる型です。主に、概念エンティティ・タイプがイベント型以外の概念エンティティが該当することが多いです。
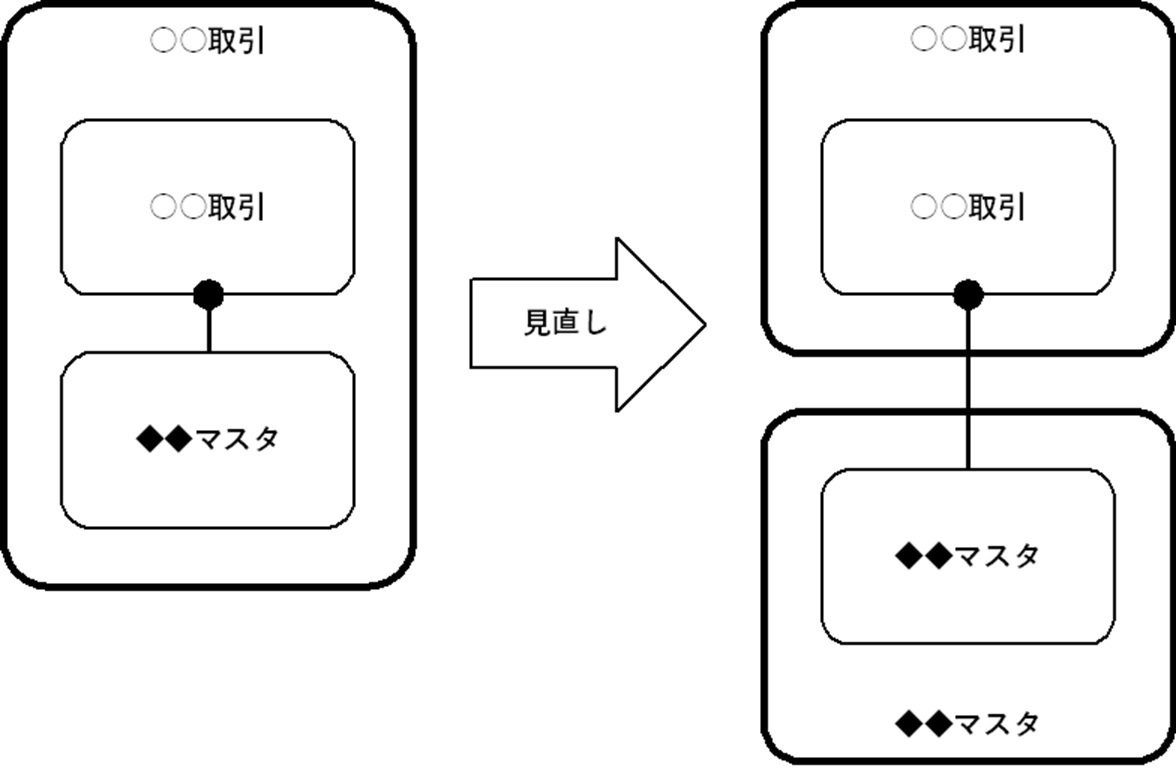
基本型Bは、第1~3正規化の結果、いわゆる「ヘッダ + 明細」のように複数の論理エンティティに分かれる場合になった型です。主に、概念エンティティ・タイプがイベント型の概念エンティティが該当することが多いです。
なお、正規化の結果、下図左のようになった場合は、下図右のように概念エンティティを見直します。
基本型Cは、論理エンティティがスーパータイプ、複数の概念エンティティがサブタイプになっている型です。
概念ERDにおいて、スーパータイプの概念エンティティを作成済みの場合も、基本型Cになります。
物理データモデル
物理データモデルについては、具体的な実装方法によって考え方が変わります。今後書く記事で具体的にまとめていきます。
全体補足
私のデータモデリング・スキルと「2:8の法則」
すべての要件に対応できるスキルの量を「10」とした場合、私は、2割のスキル量で8割の要件に対応できればよい、と考えています。つまり、「2:8の法則」に従った考え方です。その2割のスキルに集中すればいいので、効率的にスキルを習得できます。残り2割の要件については専門家と協力して対応するのが理想です。
この考え方は、データモデリング・スキルも同じです。この記事でまとめたことは、「2割のスキル」の一部です。形式知だけですが、少しでも多くのことを記事でまとめていくことを目指します。
なお、IPAのデータベーススペシャリスト試験の午後Ⅰおよび午後Ⅱのアプリケーション関連の問題は「2割のスキル」で解けます(※)。過去問に挑戦すると、自分のスキル習得度合いが実感できると思います。
※普段使わない用語については、実際に使うスキルと紐づける必要が
あります。
「正規化崩し」と「非正規化」
理想的には正規化したデータモデルのまま物理データモデルにするのが望ましいです。しかし、現時点でのコンピュータでは要求を満たす処理性能が得られないことが少なくありません。そのため、非正規化したデータモデルが必要になります。
私は、できるだけ正規化したデータモデルを崩し、つまり「正規化崩し」をするようにし、いきなり非正規化したデータモデルを考えないようにしています。
3つのデータモデルを順序よく作ったほうがよいのか?
正直言って、私はいきなり物理データモデルを考え出すことが多いです。理由は、「基礎を身につけたうえで慣れた」から。概念データモデルや論理データモデルについては、他の方への説明や自己確認などの場面で使うぐらいです。
ただ、そのような進め方は不適切だとも思っています。理想的には誰でも適切な物理データモデルを作れるようになってほしいので。そのためには、より多くの方が3つのデータモデルを順序よく作る進め方が普及することを期待しています。