
時系列推移の比較に使える可視化手法をPythonで実装する

これは 株式会社Mobility Technologies(以下MoT)データインテリジェンス部ブログの記事です。
本企画は弊社社員の個々の活動による記事であり、会社の公式見解とは異なる場合があります。
概要
こんにちは、データインテリジェンス部データアナリストの石川です。
私は普段タクシーアプリ「GO」のアナリストとして分析業務に携わっているのですが、新機能や施策などについて効果を分析しレポーティングする機会がとても多いです。特に、施策の実行前後でプロダクトKPIにどのような変化があったかなど時系列での変化に注目し分析することが重要になります。そして、分析のアウトプットとして地域や曜日など適切な軸で比較をしながら分析の結果得られた示唆を適切に伝えられる可視化レポートを作成する必要があります。そこで、本記事では複数の時系列データを比較する際に実務で有用な可視化手法を用途や注意点、Python(主に Pandas + Matplotlib)での実装例と併せて紹介します。
環境・データ
環境
本記事に記載のコードは Google Colaboratory での実行を想定しており、各種パッケージは Colaboratory 環境にプリインストールされているバージョンでの動作を確認しております。(2022/10/14時点で下記のバージョン)
・Python:3.7.14
・Pandas:1.3.5
・Matplotlib:3.2.2
データ
以降の可視化では、商品A〜Dの過去6ヶ月分の月間売上個数に見立てた下記のダミーデータを利用します
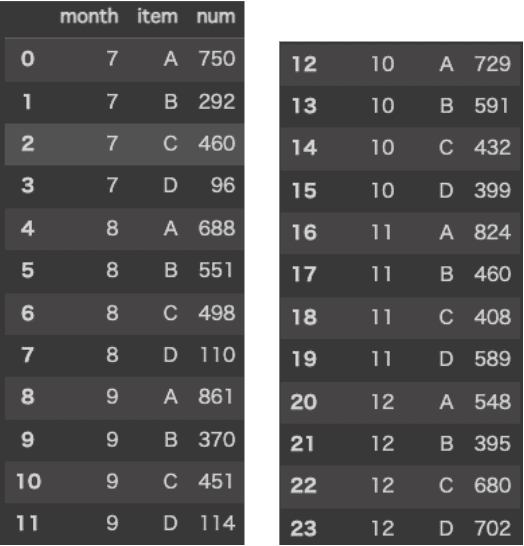
折れ線グラフ
特徴
時系列を可視化する際に最も利用されるグラフ
数値の推移、変化を比較したい場合に利用する
複数系列を重ねて可視化することで系列間の大小関係も追うことができる。
注意点
y軸は0から始める
系列が多くなると視認性が落ちる
注目すべき系列のみを色や太さなどで強調することで回避可能
実装
fig, ax = plt.subplots(1,1,figsize=(16,9))
pivot_data = data.pivot_table(index='month', columns='item', values='num')
pivot_data.plot(ax=ax)
ax.legend(bbox_to_anchor=(1, 1), loc='upper left')
[s.set_visible(False) for s in ax.spines.values()]
ax.set_ylim([0, 900])エリアチャート
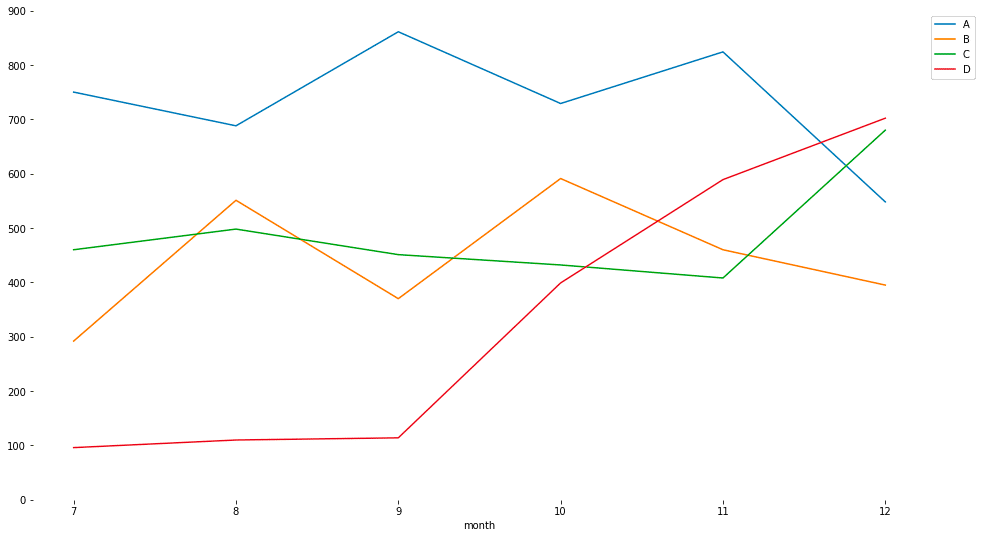
特徴
総量の推移を確認しつつ、系列の内訳も気になる場合に有用
全体の増減に影響している系列を発見するのに適している
注意点
各系列の大小比較を正確に行うのは難しい
実装
fig, ax = plt.subplots(1,1,figsize=(16,9))
pivot_data = data.pivot_table(index='month', columns='item', values='num')
pivot_data.plot(kind='area', alpha=0.8, ax=ax)
ax.legend(bbox_to_anchor=(1, 1), loc='upper left')
[s.set_visible(False) for s in ax.spines.values()]100%エリアチャート
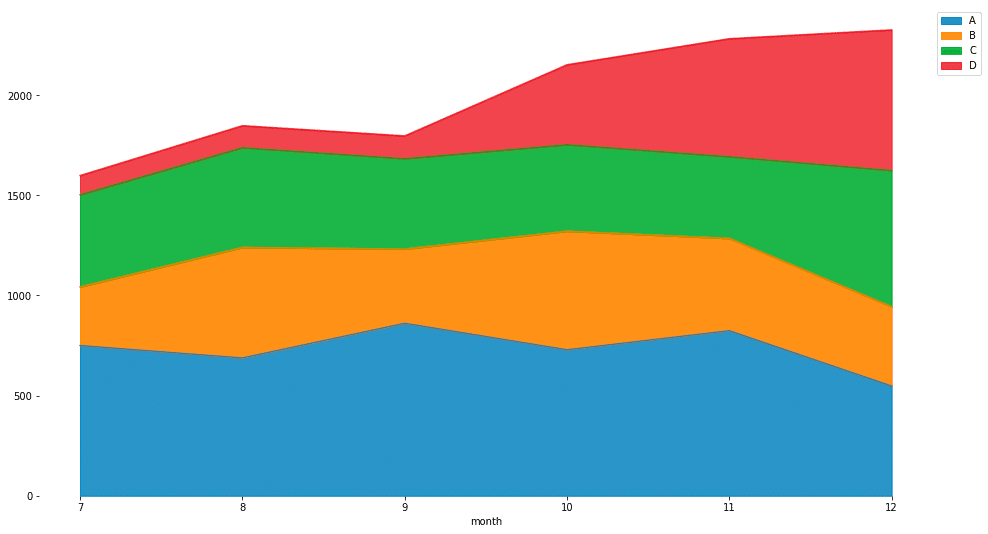
特徴
エリアチャートの縦軸を100%を最大とする比率にしたグラフ
構成比率の推移を時系列で追いたい場合に有用
注意点
各系列のボリュームに関する情報は落ちてしまう
折線グラフやエリアチャートと合わせて見ることでボリュームと比率それぞれの観点でデータを確認できる
積み上げる順序にルールは無いがボリュームが大きい系列を底に持っていく方が見栄えは良くなる
実装
# 月ごとの合計を算出
monthly_sum = data.groupby('month').sum().rename(columns={'num': 'sum'})
# 月合計に占める構成比率を算出
data_m = data.merge(monthly_sum, on='month')
data_m['rate'] = data_m['num'] / data_m['sum']
pivot_data_m = data_m.pivot_table(index='month', columns='item', values='rate')
fig, ax = plt.subplots(1,1,figsize=(16,9))
pivot_data_m.plot(kind='area', alpha=0.8, ax=ax)
ax.legend(bbox_to_anchor=(1, 1), loc='upper left')
[s.set_visible(False) for s in ax.spines.values()]スロープチャート
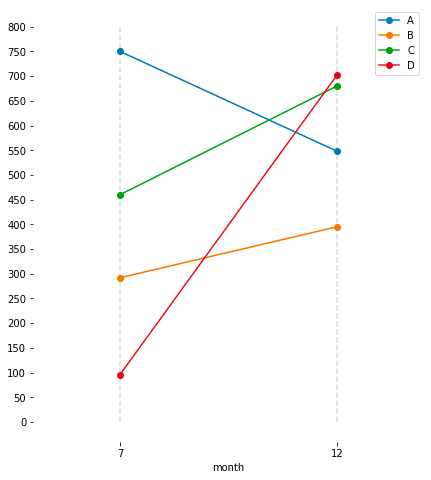
特徴
時系列の内、注目すべき2地点間のみをピックアップして変化を比較したい場合に有用
特定の地点をピックアップするだけでなく、ある地点を境界としてbefore/afterの期間で要約した上で比較するのにも使える
ランキングの入れ替わりも容易に確認することができる
注意点
時系列推移の詳細が落ちてしまうので、初手の可視化には向かない
折線などである程度傾向を分析した後に、特定の2地点間や前後での比較がメッセージとして重要であることが明らかな場合に使うと良い
実装
fig, ax = plt.subplots(1,1,figsize=(7,8))
# 7月と12月のデータのみで折れ線グラフをプロット
pivot_data = data.pivot_table(index='month', columns='item', values='num')
pivot_data.loc[[7, 12]].plot(style='o-', ax=ax)
# 基準となる垂直線を引く
ax.vlines(7, 0, 800, color='gray', alpha=0.3, linestyle='--')
ax.vlines(12, 0, 800, color='gray', alpha=0.3, linestyle='--')
[s.set_visible(False) for s in ax.spines.values()]
ax.set_xlim([5,14])
ax.set_xticks([7, 12])
ax.set_yticks(range(0, 801, 50))
ax.legend()ダンベルチャート
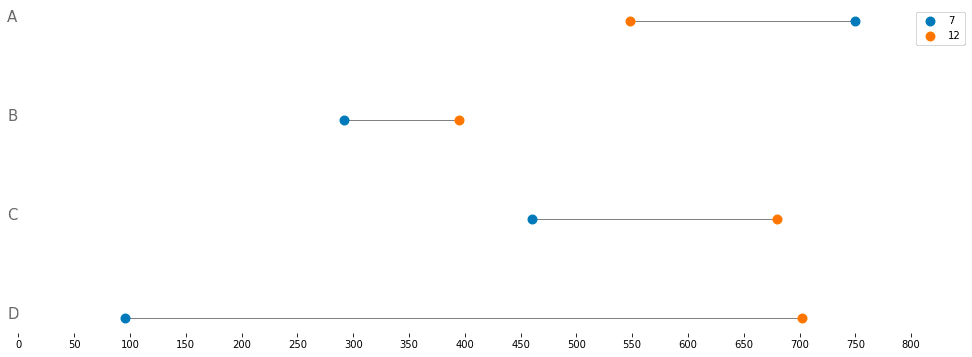
特徴
スロープチャートと同じく2地点間での変化量を確認するのに有用
差の大きさをより重視したい場合に利用すると良い
注意点
数値が増えたのか減ったのかを判断するのが難しいので、2点間を結ぶ線の色を増減どちらかによって変えたりなど視認性を上げるための工夫はあった方が良い
実装
slope_df = data.pivot_table(index='item', columns='month', values='num').loc[:,[7, 12]].reset_index()
fig, ax = plt.subplots(1,1,figsize=(16,6))
# 商品ごとに7月と12月を結ぶ水平線を引く + 商品名を縦軸として表示
for i, row in slope_df.iterrows():
ax.hlines(i, row[7], row[12], color='gray', zorder=0, linewidth=1)
ax.text(-10, i, row['item'], fontsize=15, color='dimgray')
# 散布図で点をプロット
ax.scatter(y=slope_df.index, x=slope_df[7], color='C0', label='7', s=80, zorder=1)
ax.scatter(y=slope_df.index, x=slope_df[12], color='C1', label='12', s=80, zorder=1)
[s.set_visible(False) for s in ax.spines.values()]
ax.set_yticks([])
ax.set_xticks(range(0, 801, 50))
ax.legend(bbox_to_anchor=(1, 1), loc='upper left')
ax.invert_yaxis()バンプチャート
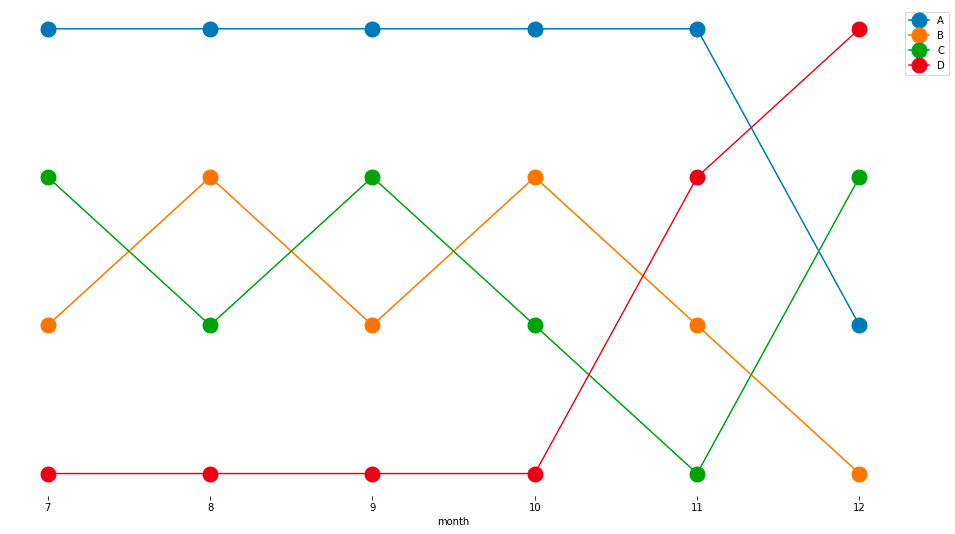
特徴
ランキングの推移に特化した可視化手法
大小の度合いには興味がなく、順序の入れ替わりをメッセージとして伝えたい場合に有用
注意点
系列が多くなると視認性が落ちる
注目すべき系列を色などで強調すると良い
実装
data_rank = data.copy(deep=True)
data_rank['rank'] = data.groupby('month')[['num']].rank(ascending=False).astype(int)
pivot_data_rank = data_rank.pivot_table(index='month', columns='item', values='rank')
fig, ax = plt.subplots(1,1,figsize=(16,9))
pivot_data_rank.plot(style='o-', markersize=15, ax=ax)
[s.set_visible(False) for s in ax.spines.values()]
ax.legend(bbox_to_anchor=(1, 1), loc='upper left')
ax.set_yticks([])
ax.invert_yaxis()エリアバンプチャート
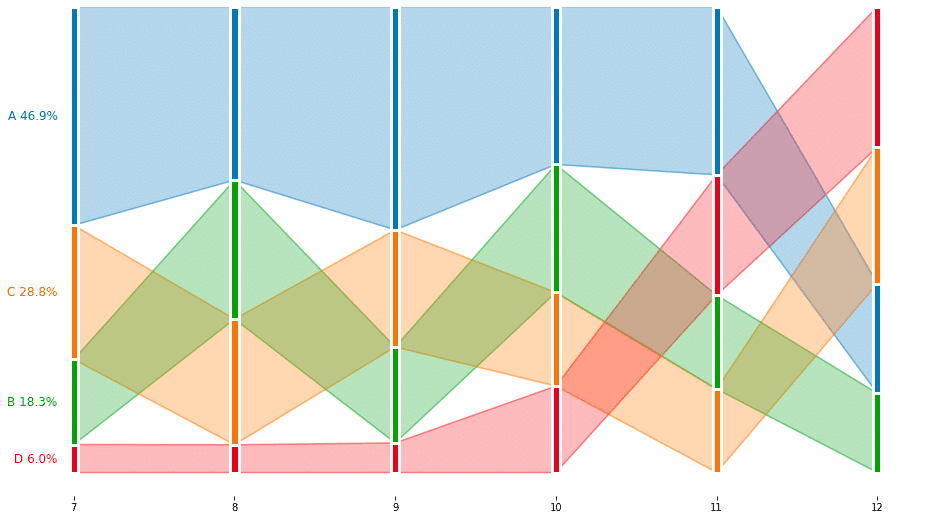
特徴
バンプチャートに構成比率の情報を加えた可視化
ランキングの入れ替わりに加えて比率の推移も伝えたい場合に有用
注意点
比率を正確に比較するのは難しい
あくまでランキングの推移を主のメッセージとして補足としておおよその比率が掴めれば良いというケースに使う。
実装
# 月ごとの合計を算出
monthly_sum = data.groupby('month').sum().rename(columns={'num': 'sum'})
# 月合計に占める構成比率を算出
data_m = data.merge(monthly_sum, on='month')
data_m['rate'] = data_m['num'] / data_m['sum']
data_m['rank'] = data.groupby('month')[['num']].rank(ascending=False).astype(int)
data_m.sort_values(by=['month', 'rank'], ascending=[True, True], inplace=True)
data_m['cumsum_rate'] = data_m.groupby('month').rate.cumsum()
data_m['cumsum_rate_lag'] = data_m.groupby('month').cumsum_rate.shift(1).fillna(0)
pivot_data_rank = data_m.pivot_table(index='month', columns='rank', values='rate')
items = list(data_m.item.unique())
months = sorted(data_m.month.unique())
def item_color(item_name):
return f'C{items.index(item_name)}'
fig, ax = plt.subplots(1,1,figsize=(16,9))
# 各月で順位で並ぶように積み上げ棒グラフを描画
bottom = [0] * len(data_m.month.unique())
for col, s in pivot_data_rank.iteritems():
ax.bar(s.index, s.values, bottom=bottom, width=0.05, edgecolor='white', linewidth=3, zorder=1)
bottom += s.values
for item in items:
color = item_color(item) # 商品ごとの色を設定
# 各月で商品の色を統一
for i, row in data_m[data_m['item'] == item].iterrows():
month = row['month']
rank = row['rank']
ax.patches[months.index(month)+len(months)*(rank-1)].set_facecolor(color)
# 商品ごとの推移を領域で塗りつぶす
target = data_m[data_m['item'] == item]
ax.plot(target['month'], target['cumsum_rate'], color=color, alpha=0.5, zorder=0)
ax.plot(target['month'], target['cumsum_rate_lag'], color=color, alpha=0.5, zorder=0)
ax.fill_between(list(target['month']),
target['cumsum_rate'],
target['cumsum_rate_lag'],
facecolor=color,
alpha=0.3)
# text要素を追加
first_value = target.iloc[0]
ax.text(first_value.month-0.1, first_value.cumsum_rate_lag+first_value.rate/2, item+f' {first_value.rate:0.1%}', ha='right', va='center', color=color, fontsize=12)
[s.set_visible(False) for s in ax.spines.values()]
ax.set_yticks([])
ax.invert_yaxis()まとめ
本記事で紹介した可視化手法を用途別にまとめると下記のようになります。
伝えたいメッセージや注目したい指標に応じて適切な手法を選ぶことがデータ可視化において重要な要素となります。
ボリュームの推移
折線グラフ、スロープチャート、ダンベルチャート、エリアチャート
総量の推移
エリアチャート
比率の推移
100%エリアチャート、エリアバンプチャート
2点間の変化量比較
スロープチャート、ダンベルチャート
ランキングの推移
バンプチャート、エリアバンプチャート、スロープチャート
おわりに
本記事を読んでMoTのアナリストや分析業務に少しでも興味を持っていただける方がいらっしゃったら嬉しいです。
また、MoTでは現在データアナリストを絶賛募集中です。
