
量子機械学習におけるデータエンコーディングとモデル選択

2023年度研究会推薦博士論文速報
[量子ソフトウェア研究会]
矢野 碩志
(慶應義塾大学 特任助教)
■キーワード
量子計算/量子情報/機械学習
【背景】量子コンピュータ開発の進歩
【問題】量子機械学習アルゴリズム設計指針の不足
【貢献】量子機械学習アルゴリズム設計指針の提案
量子計算は,ムーアの法則に従う集積回路の性能向上の限界が指摘される中,現在注目されている次世代の計算技術の代表格である.近年ではハードウェア技術の発展により量子計算の実現が現実的なものに近づきつつあり,現在では世界的に量子コンピュータの開発が進んでいる.量子計算を用いた機械学習の大きな1つの目的は,量子計算により従来の機械学習より優れた予測性能や学習スピードを達成することである.特に近年,古典の機械学習モデルから発展した量子機械学習モデルとして,量子ニューラルネットワークや量子カーネルといったモデルが提唱された.現在はこれらのモデルをもとにした特定のドメイン専用のモデルの考案や学習方法,量子機械学習におけるデータの取り扱いなど,古典の機械学習と同様に多岐にわたるアイデアが展開されている.
本研究では,量子計算を用いた機械学習におけるデータとモデルに関する重要な課題を2つ取り上げた.1つは,データエンコーディングである.量子計算で古典データを扱う場合,まず古典データを量子コンピュータにエンコードする必要がある.このとき,どのように古典データをエンコードするかには任意性があり,優位性を示しかつ効率的であるようなデータエンコーディング手法を開発することが究極的な目標となる.もう1つは,モデル選択である.従来の機械学習と同様に,機械学習アルゴリズムの実行可能性,性能向上のためには使用する量子機械学習モデルの選定を適切に行う必要がある.
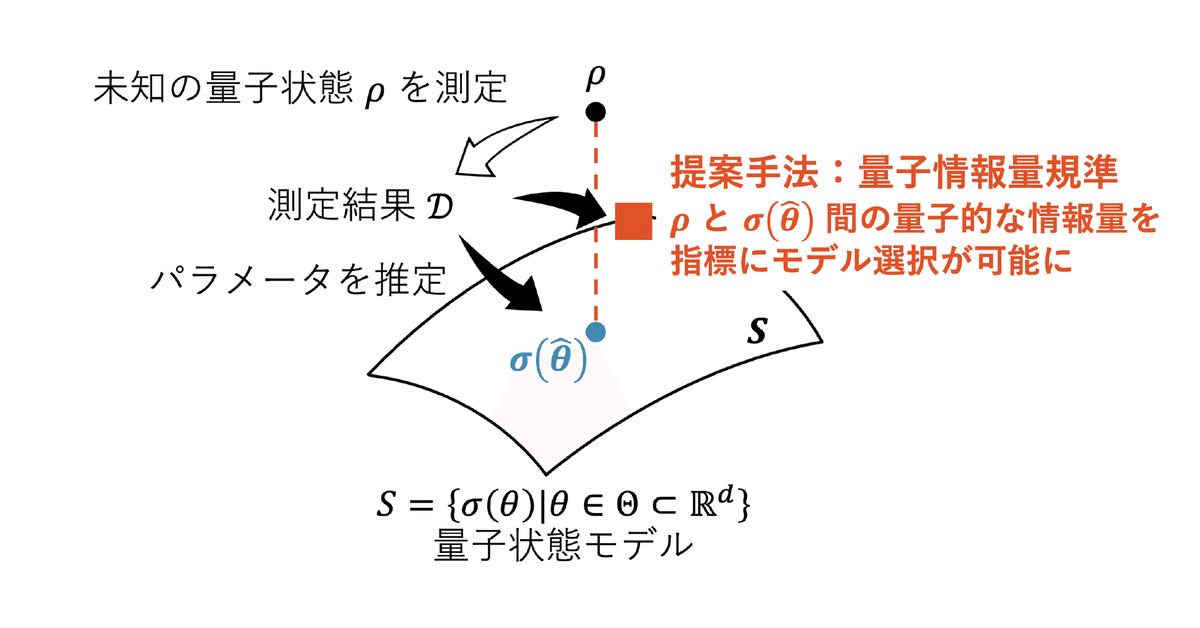
本研究の貢献の1つである,量子状態推定におけるモデル選択指標の開発についてご紹介する.量子状態推定は量子情報処理の中でも重要なタスクの1つであり,量子状態推定で開発された技術は量子機械学習にも多く応用されている.量子状態の数学的表現である密度演算子の完全な再構築は計算量的に困難であるため,量子状態推定では状態にパラメトリックなモデルを仮定しそのパラメータを推定することがしばしば行われる.しかし,対象の量子状態に関する前提知識がほとんど得られない場合,状態の構造に仮定を置くことは困難である.そこで量子状態を推定するために適切なモデルの選択をする必要が生じる.本研究では,古典統計において従来考えられてきたモデル選択指標である情報量規準のアイデアに基づき,新たに量子情報量規準を提案した.これは量子相対エントロピーによって推定された量子状態モデルを評価する指標である.量子相対エントロピー自体は測定に依存しない量であるため,提案した情報量規準は推定に用いた測定の最適性も加味した量子状態モデルの評価をできることが期待される.
本研究で扱った内容は量子優位性とは直接的なつながりはないものの,量子機械学習の実行可能性を向上させる上で必須の技術だと考えられる.本研究が量子機械学習の実用化への一助となることを期待する.
(2024年5月31日受付)
(2024年8月15日note公開)
ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー
取得年月:2024年3月
学位種別:博士(工学)
大学:慶應義塾大学
ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー
推薦文[コンピュータサイエンス領域]量子ソフトウェア研究会
統計的学習を量子コンピュータで実行するには,数理モデルが必要です.古典の場合,モデルの良し悪しを評価する指標として赤池情報量基準AICが金字塔です.本研究では,世界で初めてAICの量子版を提案しています.これは実は相当に非自明な問題ですが,最新の量子情報理論のツールを使ってこの困難を克服しています.
研究生活 博士課程での研究テーマは,量子機械学習という真新しい分野に興味を抱き調べているうちに,さまざまな課題やテーマがあることに気づき始まりました.特に,量子状態推定という基礎的なタスクにおいて日本で培われてきたアイデアである情報量規準を改めて考え直せたことは,古典と量子の統計の違いを実感するという点で良い経験になりました.また博士課程での研究を通じて,古典機械学習と量子機械学習の研究の違いを痛感しました.それは,機械学習は実際にデータに対して学習をしてみて初めて性能が分かるという経験的な要素も強い分野である一方,古典の場合と異なり量子機械学習は現状(量子デバイスの性能を考慮すると)実際にアルゴリズムを実行するには大きな制約があるということです.このような状況はスパコンが登場する前の古典機械学習と状況が似ており,現在は研究を停滞させないために歴史を顧みて色々試行錯誤を行う,重要で特別な時期だと感じています.