
Air Street Capital社のState Of AI Report 2023を読む(7):Domain Specific LLMの世界

Domain Specific LLMという言葉で代表される、特定の業界分野や専門領域の情報に特化して大規模言語モデルを構築する手法が第3のLLMとして注目されてます。
GPT-4やBardのようなインターネット全体のデータを収集対象とする大規模なLLMと異なり、例えば金融業界、保険業界、医療業界などに限定したデータだけを集約する事が目的なので、次のようなメリットが考えられます。
専門情報の集合体なので、Hallucinationをかなりのレベルまで防止できるし、修正も容易。
限定された領域の専門用語で構成されるので、構築コストやその後のチューニングのコストが比較的安く済む。
レポートでは、2つの例が示されています。
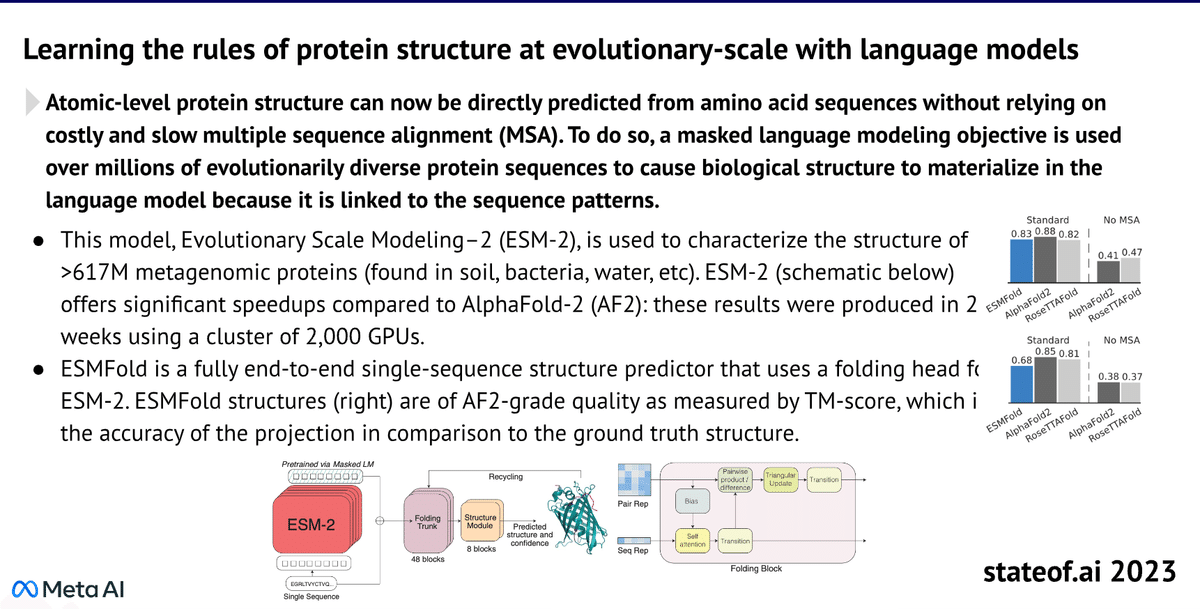
1)たんぱく質の分子レベルの構造分析
ESM-2と呼ばれるLLMは、たんぱく質の構造分析や予測の用途に特化したモデルで、15B規模のパラメタを有します。詳しくはこの論文にて説明されています。
2)医療業界専門のLLM
Googleが開発したMed-Palm 2というLLMは大量の医療ジャーナル、臨床テストデータ、等の医療情報でトレーニングを施され、医療研究、診断、教育、薬の開発、などの用途に広く用いられてます。USMLEと呼ばれる医療資格試験に対して、86.5%の正解率を打ち出し、2023年3月に初めてAIとして合格したモデルとしても話題になってます。

上記以外にも多くのドメイン特定のLLMが一般的なサービスとして提供されており、新しいビジネスとしても立ち上がりつつあります。企業内のローカルLLMと組み合わせて採用する事例も登場しています。
BloombergGPT
デコーダーのみのアーキテクチャで設計された因果関係のある言語モデル。このモデルは500億のパラメーターで動作し、金融のドメイン固有のデータを数十年分使ってゼロから訓練され、金融業界における類似のモデルの精度を大幅に上回りました。
ClimateBERT
数百万の気候関連のドメイン固有のデータで訓練されたトランスフォーマーベースの言語モデルで、さらなるファインチューニングにより、環境データのより正確な検証を可能にします。一般的な言語モデルと比較して、ClimateBERTは気候関連のタスクを最大35.7%少ないエラーで完了する論文が出ています。
KAI-GPT
銀行業界で会話型AIを提供するように訓練された大規模な言語モデル。Kasisto社によって開発されたこのモデルは、銀行の顧客にサービスを提供する際に、生成型AIモデルを透明で安全かつ正確に使用することを可能にします。
ChatLAW
中国の法的ドメインのデータセットで訓練されたオープンソースの言語モデル。ハルシネーションを減らし、推論能力を向上させるエンハンスがいくつか実装されてる、との事。
FinGPT
金融データで訓練された軽量な言語モデル。上記のBloombergGPTよりも手頃な価格の訓練オプションを提供し、パーソナライゼーションを可能にするために、RLHR(人間のフィードバックから強化学習)の機能もサポートしてます。