
ナレッジグラフ(Neo4j) を活用してLangChainアプリケーションを強化

ナレッジグラフ関係の技術記事が多くなってきてますが、この記事は、Neo4jとLangChainを組み合わせて実際にRAGを作ってみた、という内容でステップ毎に紹介してくれています。ナレッジグラフをRAG向けのデータストアとして使うと、構造型のデータと非構造型のデータをミックスしてRAGに提供できる、っという点が強みです。一緒にできるってことは運用管理が楽になる、ということです。ベクトルデータも作る必要はありますが、これもナレッジグラフの中に入れちゃいます。
企業向けのRAGの開発にグラフデータベースとRAGの組み合わせはこれからもっと広がっていくのでは、と期待してます。
Using a Knowledge Graph to implement a DevOps RAG application
Clip source: devops_rag.ipynb - Colaboratory
RAGアプリケーションは現在、非常に注目されており、多くの企業が社内文書のチャットボットなどを開発しています。これらのほとんどは、構造化されていないテキストがソースであり、何らかの方法でチャンク化され、組み込まれています。しかし、情報がすべて構造化されていないテキストだ、というわけではありません。
例えば、マイクロサービスアーキテクチャや進行中のタスクに関する質問に答えられるチャットボットを作ったとします。タスクはほとんどが構造化されていないテキストとして定義されているので、通常のRAGワークフローと変わらないですが、マイクロサービスアーキテクチャに関する情報をどのように準備し、チャットボットが最新の情報を取得できるようにするかは、異なる問題です。
一つの選択肢は、アーキテクチャの日次スナップショットを作成し、LLMが理解できるテキストに変換することです。しかし、より優れた方法として、ナレッジグラフを推奨します。ナレッジグラフは、構造化された情報と構造化されていない情報の両方を単一のデータベースに格納できるためです。

ナレッジグラフでは、ノードとリレーションシップを使用してデータを記述します。通常、ノードは人、組織、場所などのエンティティや概念を表すために使用されます。マイクロサービスグラフの例では、ノードは人、チーム、マイクロサービス、タスク、になります。一方、リレーションシップは、これらのエンティティ間の接続を定義するために使用されます。例えば、マイクロサービス間の依存関係やタスクの所有者などです。
ノードとリレーションシップの両方には、キーと値のペアとして格納されるプロパティ値があります。

マイクロサービスのノードには、その名前と技術を記述する2つのノードプロパティがあります。一方、タスクノードはもっと複雑です。これらには名前、状態、説明、そして埋め込みプロパティがあります。テキストの埋め込み値をノードプロパティとして格納することで、タスクをベクトルデータベースに格納しているかのように、タスクの説明のベクトル類似性検索を行うことができます。したがって、ナレッジグラフは、RAGアプリケーションを強化するために構造化された情報と非構造化情報の両方を格納および取得することを可能にします。
このブログ投稿では、LangChainを使用してDevOpsチームをサポートするナレッジグラフに基づくRAGアプリケーションを実装するシナリオを紹介します。コードはGitHubで利用可能です。
Neo4j 環境の設定
このブログ投稿の例に沿って進めるためには、Neo4j 5.11以上をセットアップする必要があります。最も簡単な方法は、Neo4jデータベースのクラウドインスタンスを提供するNeo4j Auraで無料インスタンスを開始することです。また、Neo4j Desktopアプリケーションをダウンロードしてローカルデータベースインスタンスを作成することにより、ローカルインスタンスのNeo4jデータベースをセットアップすることもできます。
from langchain.graphs import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username ="neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)データセット
ナレッジグラフは、複数のデータソースからの情報をつなげるのに非常に優れています。DevOps RAGアプリケーションを開発する際には、クラウドサービスやタスク管理ツールなどから情報を取得することができます。

この種のマイクロサービスおよびタスク情報は公開されていないため、私は合成データセットを作成する必要がありました。そのため、ChatGPTの助けを借りました。これは100ノードのみの小規模なデータセットですが、このチュートリアルには十分です。以下のコードはサンプルグラフをNeo4jにインポートします。
import requests
import_url = "https://gist.githubusercontent.com/tomasonjo/08dc8ba0e19d592c4c3cde40dd6abcc3/raw/e90b0c9386bf8be15b199e8ac8f83fc265a2ac57/microservices.json"
import_query = requests.get(import_url).json()['query']
graph.query(
import_query
)
[ ]Neo4j ベクトルインデックス
まず、名前と説明による関連タスクを見つけるためにベクトルインデックス検索を実装します。もしベクトル類似性検索が初めてなら、簡単なおさらいをしましょう。重要なアイデアは、各タスクの説明と名前に基づいてテキスト埋め込み値を計算することです。その後、クエリ時に、コサイン距離のような類似性メトリックを使用して、ユーザー入力に最も類似したタスクを見つけます。
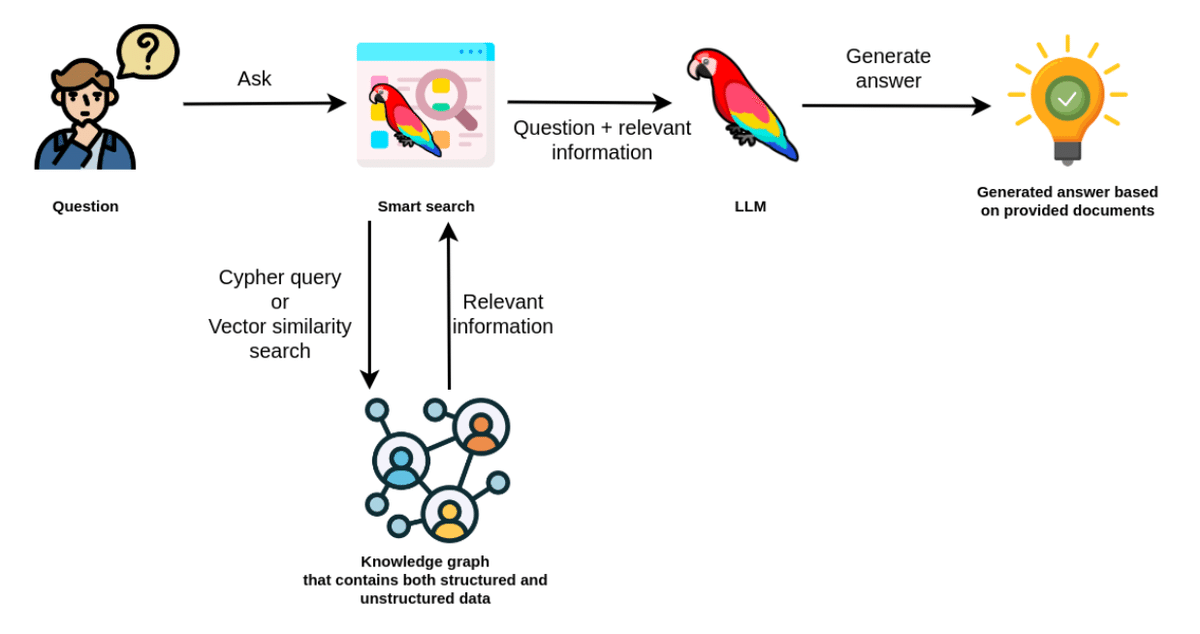
ベクトルインデックスから取得した情報は、LLMにコンテキストとして使用され、正確でかつ最新の回答を生成することができます。
タスクは既に私たちのナレッジグラフにあります。しかし、埋め込み値を計算し、ベクトルインデックスを作成する必要があります。これは from_existing_graph メソッドを使用して実現することができます。
import os
from langchain.vectorstores.neo4j_vector import Neo4jVector
from langchain.embeddings.openai import OpenAIEmbeddings
os.environ['OPENAI_API_KEY'] = "sk-"
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
index_name='tasks',
node_label="Task",
text_node_properties=['name', 'description', 'status'],
embedding_node_property='embedding',
)この例では、from_existing_graphメソッドに対して以下のグラフ固有のパラメータを使用しました。
index_name: ベクトルインデックスの名前
node_label: 関連ノードのノードラベル
text_node_properties: 埋め込みを計算し、ベクトルインデックスから取得するために使用されるプロパティ
embedding_node_property: 埋め込み値を格納するプロパティ
ベクトルインデックスが初期化された今、LangChainで他のベクトルインデックスと同様に使用することができます。
response = vector_index.similarity_search(
"How will RecommendationService be updated?"
)
print(response[0].page_content)name: RecommendationFeature
description: Add a new feature to RecommendationService to provide more personalized and accurate product recommendations to the users, leveraging user behavior and preference data.
status: in progresstext_node_propertiesパラメータで定義されたプロパティを持つマップや辞書のような文字列のレスポンスを構築することがわかります。
これで、ベクトルインデックスをRetrievalQAモジュールにラッピングすることで、簡単にチャットボットのレスポンスを作成できるようになりました。
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
vector_qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(), chain_type="stuff", retriever=vector_index.as_retriever())vector_qa.run(
"How will recommendation service be updated?"
)一般に、ベクトルインデックスの一つの制限は、Cypherのような構造化クエリ言語で行うような情報の集約能力を提供しないことです。例えば、以下の例を考えてみましょう:
vector_qa.run(
"How many open tickets there are?"
)レスポンスは妥当に思え、LLMは断定的な表現で結果が正しい、と思われます。しかし、問題はレスポンスがベクトルインデックスから取得されたドキュメントの数、つまりデフォルトで4つに直接関連していることです。実際に起こるのは、ベクトルインデックスが4つのオープンチケットを取得し、LLMは疑うことなくそれらがすべてのオープンチケットであると信じています。しかし、実際は異なり、Cypherステートメントを使用してそれを検証することができます。
graph.query(
"MATCH (t:Task {status:'open'}) RETURN count(*)"
)[{'count(*)': 5}]私たちのグラフDBでは、5つのオープンタスクがあります。ベクトル類似性検索は非構造化テキスト内の関連情報を選別するのに優れていますが、構造化された情報を分析し集約する能力に欠けています。Neo4jを使用すると、この問題はグラフデータベース用の構造化クエリ言語であるCypherを利用することで簡単に解決できます。
グラフCypher検索
Cypherは、グラフデータベースと対話するための構造化クエリ言語であり、パターンやリレーションシップのマッチングを視覚的に行う方法を提供します。次の構文で表記されます:
(:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"})このパターンは、PersonというラベルとTomazという名前プロパティを持つノードが、SloveniaのCountryノードに対してLIVES_IN関係を持つことを記述しています。LangChainの素晴らしい点は、GraphCypherQAChainを提供していることで、これはCypherクエリを生成してくれるので、Neo4jのようなグラフデータベースから情報を取得するためにCypher構文を学ぶ必要がありません。以下のコードはグラフスキーマをリフレッシュし、Cypherチェーンをインスタンス化します。
from langchain.chains import GraphCypherQAChain
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm = ChatOpenAI(temperature=0, model_name='gpt-4'),
qa_llm = ChatOpenAI(temperature=0), graph=graph, verbose=True,
)Cypherステートメントを生成することは複雑な作業です。したがって、Cypherステートメントを生成する際には、gpt-4のような最先端のLLMを使用することが推奨されますが、データベースコンテキストを使用して回答を生成する作業はgpt-3.5-turboに任せることができます。
これで、何枚のチケットがオープンしているかという同じ質問をすることができます。
cypher_chain.run(
"How many open tickets there are?"
)> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (t:Task {status: 'open'}) RETURN COUNT(t)
Full Context:
[{'COUNT(t)': 5}]
> Finished chain.
There are currently 5 open tickets.また、次の例のように、さまざまなグルーピングキーを使用してデータを集約するようチェーンに依頼することもできます。
cypher_chain.run(
"Which team has the most open tasks?"
)> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (t:Task)-[:ASSIGNED_TO]->(team:Team)
WHERE t.status = 'open'
RETURN team.name, COUNT(t) AS OpenTasks
ORDER BY OpenTasks DESC
LIMIT 1
Full Context:
[{'team.name': 'TeamA', 'OpenTasks': 3}]
> Finished chain.
TeamA has the most open tasks with a total of 3.これらの集約はグラフベースの操作ではないと言うかもしれませんが、それは正しいです。もちろん、マイクロサービスの依存関係グラフをトラバースするような、よりグラフベースの操作を実行することもできます。
cypher_chain.run(
"Which services depend on Database directly?"
)> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (m:Microservice)-[:DEPENDS_ON]->(n:Microservice {name: 'Database'}) RETURN m.name
Full Context:
[{'m.name': 'InventoryService'}, {'m.name': 'CatalogService'}, {'m.name': 'UserService'}, {'m.name': 'OrderService'}, {'m.name': 'AuthService'}, {'m.name': 'PaymentService'}]
> Finished chain.
The services that depend on the Database directly are the InventoryService, CatalogService, UserService, OrderService, AuthService, and PaymentService.もちろん、次のような質問をすることで、可変長のパストラバーサルを生成するようチェーンに依頼することもできます:
cypher_chain.run(
"Which services depend on Database indirectly?"
)> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (m:Microservice)-[:DEPENDS_ON*2..]->(n:Microservice {name: 'Database'}) RETURN m.name
Full Context:
[{'m.name': 'OrderService'}, {'m.name': 'PaymentService'}, {'m.name': 'OrderService'}, {'m.name': 'ShippingService'}, {'m.name': 'OrderService'}, {'m.name': 'UserService'}, {'m.name': 'OrderService'}]
> Finished chain.
The services that depend on the Database indirectly are the OrderService, PaymentService, ShippingService, and UserService.言及されたサービスの一部は、直接依存する質問と同じです。これは無効なCypherステートメントではなく、依存関係グラフの構造によるものです。
ナレッジグラフエージェント
ナレッジグラフの構造化された部分と非構造化された部分に対して別々のツールを実装したので、これら2つのツールを使用してナレッジグラフを探索できるエージェントを追加できます。
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
tools = [
Tool(
name="Tasks",
func=vector_qa.run,
description="""Useful when you need to answer questions about descriptions of tasks.
Not useful for counting the number of tasks.
Use full question as input.
""",
),
Tool(
name="Graph",
func=cypher_chain.run,
description="""Useful when you need to answer questions about microservices,
their dependencies or assigned people. Also useful for any sort of
aggregation like counting the number of tasks, etc.
Use full question as input.
""",
),
]
mrkl = initialize_agent(
tools, ChatOpenAI(temperature=0, model_name='gpt-4'), agent=AgentType.OPENAI_FUNCTIONS, verbose=True
)エージェントがどれほどうまく機能するか試してみましょう。
response = mrkl.run("Which team is assigned to maintain PaymentService?")
print(response)> Entering new AgentExecutor chain...
Invoking: `Graph` with `Which team is assigned to maintain PaymentService?`
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (m:Microservice {name: 'PaymentService'})-[:MAINTAINED_BY]->(t:Team) RETURN t.name
Full Context:
[{'t.name': 'TeamD'}]
> Finished chain.
TeamD is assigned to maintain PaymentService.TeamD is assigned to maintain the PaymentService.
Finished chain.
TeamD is assigned to maintain the PaymentService.それでは、タスクツールを呼び出してみましょう。
response = mrkl.run("Which tasks have optimization in their description?")
print(response)> Entering new AgentExecutor chain...
Invoking: `Tasks` with `Which tasks have optimization in their description?`
The tasks that have optimization in their description are:
1. Optimize: Enhance AuthService’s performance and security by optimizing the authentication mechanisms and implementing additional security measures to safeguard user information.
2. Optimize: Optimize PaymentService by refining the transaction processing logic, reducing the service’s latency, and improving its reliability and efficiency in handling transactions.The tasks that have optimization in their description are:
1. Enhance AuthService’s performance and security by optimizing the authentication mechanisms and implementing additional security measures to safeguard user information.
2. Optimize PaymentService by refining the transaction processing logic, reducing the service’s latency, and improving its reliability and efficiency in handling transactions.
> Finished chain.
The tasks that have optimization in their description are:
1. Enhance AuthService’s performance and security by optimizing the authentication mechanisms and implementing additional security measures to safeguard user information.
2. Optimize PaymentService by refining the transaction processing logic, reducing the service’s latency, and improving its reliability and efficiency in handling transactions.一つ確かなことは、私はエージェントプロンプトエンジニアリングスキルを向上させる必要があるということです。ツールの説明には確実に改善の余地があります。さらに、エージェントプロンプトをカスタマイズすることもできます。
結論
ナレッジグラフは、構造化されたデータと非構造化データの両方をRAGアプリケーションに組み込む必要がある場合に非常に適しています。このブログ投稿で示されたアプローチを使用することで、複数のタイプのデータベースを維持し同期する必要のあるポリグロットアーキテクチャを避けることができます。LangChainでのグラフベース検索についてもっと学ぶことができます。