
DataStaxがLangflowを買収:AIへの投資強化

DataStaxがLangflowを買収
DataStaxは、Apache Cassandra NoSQLデータベースの商業化した事で知られており、包括的な生成AI事業に舵を切りました。この軌道での第一歩は、2023年にAstra DBサービスにベクトル検索機能を統合したことです。その後、Retrieval-Augmented Generation(RAG)をバックアップするGenAIアプリケーション開発を強化し、2024年4月4日にRAG中心のアプリケーションのローコード開発ツール:Langflowの開発元であるLogspace社の買収を発表しました。
DataStaxによる買収の財務的な詳細は非公開です。2022年に創業したLogspaceは、企業内での機械学習の導入を促進する機能をサポートしてます。コンサルティング企業として始まったLogspaceは、Rodrigo Nader、Gabriel Luiz、Freitas Almeidaに率いられ、製品志向のベンチャーに転換しました。2023年までに、Langflowはオープンソースのローコード/ノーコードプラットフォームとして登場しています。
DataStaxのCEO兼会長であるChet Kapoorは、この買収の戦略的重要性を強調しています。Kapoorは、「Langflowを当社のエコシステムに統合することで、開発者へのリソースを強化し、GenAIプロジェクトを実現する力を与えます」と主張しています。「Langflowの生成AIを民主化する理念は、多様なセクターでのAI開発を加速するという当社の使命と一致しています。」
DataStaxの視点からすると、この買収は、包括的な生成AIインフラを確立する戦略の一環です。Langflowの能力とDataStaxの既存の製品群を組み合わせることで、統合されたプラットフォームが提供されます。Astra DB、LangChainツールキット、およびLlamaIndexをシームレスに結びつけることで、この統合は、開発者にGenAIアプリケーション(内部および外部アプリケーション用のチャットボットを含む)を作成するためのユーザーフレンドリーなインターフェースを提供します。
買収後も、Langflowは独立したコンポーネントとして存続し、既存のユーザーには継続性と中断のないサービスを保証します。 Rodrigo NaderはDataStaxとの協力に熱意を示し、市場拡大と製品改良への投資予定を表明してます。Nader氏は、「DataStaxとのシナジーは革新の新時代を告げるものであり」と断言し、「一緒になれば、Langflowプラットフォームの影響力を拡大し、より広範囲のAI愛好家に対応する準備が整っています」と述べています。」
構築例(1):Astra DB、LangChain、およびVercelを使用してWikipediaチャットボットを構築する
WikiChatは、Wikipediaの質問に対して自然な言語で回答を得るための方法であり、以下のツールを使用して構築されています:Next.js、LangChain、Vercel、OpenAI、Cohere、およびDataStaxのAstra DB。
WikiChatは、トップ1000の人気のあるWikipediaページで構成され、その後、Wikipediaのリアルタイムの更新フィードを使用して情報のストアを更新します。 Astra DBの素晴らしい機能の1つは、これらの更新を同時に取り込み、再インデックス化し、ユーザーがクエリを行うために利用可能にする能力であり、インデックスを再構築するための遅延は一切ありません。
WikiChatのソースコードはGitHubで利用可能です。それを構築する方法の詳細については以下を読んでください。また、最近の私と同僚のAlex Leventer、LangChainのJacob Leeとのビデオもチェックしてください。
アーキテクチャ
多くのRAGアプリケーションと同様に、このアプリは2つの部分で設計されています:ナレッジベースを作成するデータ取り込みスクリプトと、会話体験を提供するWebアプリです。
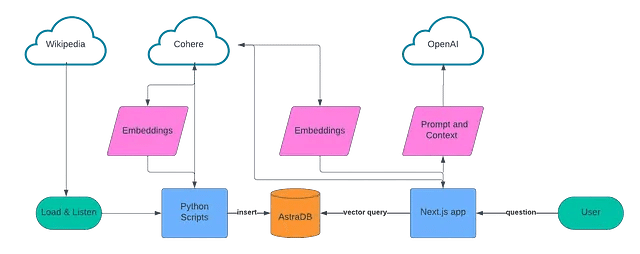
データ取り込みでは、収集するデータソースのリストを作成し、LangChainを使用してテキストデータをチャンク化し、埋め込みを作成するためにCohereを使用し、それらをすべてAstra DBに保存しました。
会話型のUXでは、Next.js、VercelのAIライブラリ、Cohere、およびOpenAIを活用しています。ユーザーが質問すると、Cohereを使用してその質問の埋め込みを作成し、ベクトル検索を使用してAstra DBをクエリし、その結果をOpenAIにフィードしてユーザーへの会話応答を作成します。
セットアップ
このアプリケーションを自分で構築するか、当社のリポジトリを実行するには、いくつかのものが必要です。
Astra DBにサインアップした後、新しいベクトルデータベースを作成する必要があります。アカウントにログインしてください。
次に、新しいサーバーレスベクトルデータベースを作成します。任意の名前を付け、お好みのプロバイダーとリージョンを選択してください。

データベースのプロビジョニングを待っている間に、プロジェクトのルートにある.env.exampleファイルを.envにコピーしてください。このファイルには、このアプリを構築する際に使用するAPIの秘密の資格情報や構成情報を保存します。
データベースが作成されたら、新しいアプリケーショントークンを作成してください。

モーダルが表示されたら、「コピー」ボタンをクリックしてその値を.envファイルのASTRA\_DB\_APPLICATION\_TOKENに貼り付けます。次に、APIエンドポイントをコピーしてください。

.envファイルのASTRA\_DB\_ENDPOINTにその値を貼り付けてください。
Cohereアカウントにログインし、API keysに移動します。開発用に使用できるトライアルAPIキーが見つかりますので、その値をコピーしてCOHERE\_API\_KEYキーの下に保存してください。
最後に、OpenAIアカウントにログインし、新しいAPIキーを作成します。そのAPIキーを.envファイルのOPENAI\_API\_KEYとして保存してください。
Paste that value into ASTRA_DB_ENDPOINT in the .env file.
データの取り込み
scriptsディレクトリには、WikiChatのデータ取り込みを処理するPythonスクリプトがあります。人気のあるWikipediaの記事の最初のバッチを読み込み、その後、Wikipediaの公開されたEvent Streamを使用して英語の記事の変更を監視します。
注意: イベントストリームには、ボット、トークページの変更、システムをテストするために送信されるcanary eventsなど、さまざまな形式の更新が含まれています。ソースに関係なく、各記事は取り込まれるまで5つのステップを経ます。
取り込み手順に進む前に、Data APIを使用してAstraに保存するデータを簡単に見てみましょう。Data APIは、JSONドキュメントを使用してデータを保存し、Collectionsにまとめます。デフォルトでは、ドキュメント内のすべてのフィールドがインデックス化され、クエリを実行できるようになっており、埋め込みベクトルも含まれます。私たちが作成したWikiChatアプリケーションでは、3つのコレクションを作成しました。
article\_embeddings - 各ドキュメントは、記事からのテキストチャンクとCohereを使用して作成された埋め込みベクトルを格納します。これは、WikiChatがチャットの質問に答えるために必要な核となる情報です。
article\_metadata - 各ドキュメントは、取り込んだ単一の記事に関するメタデータを格納します。これには、最後に取り込んだ時点で含まれていたチャンクに関する情報が含まれます。
article\_suggestions - このコレクションには、スクリプトが継続的に更新して最後に処理された5つの記事を追跡し、それぞれの最初の5つのチャンクまたは最も最近更新された5つのチャンクを含む単一のドキュメントが含まれています。
scripts/wikichat/database.pyファイルは、astrapyクライアントライブラリを初期化し、データAPIを呼び出してコレクションを作成し、それらと連携するためのクライアントサイドオブジェクトを作成する責任があります。私たちが行う必要がある唯一のデータモデリングは、各コレクションに格納したいPythonクラスを定義することです。これらはscripts/wikichat/processing/model.pyファイルで定義されています。ファイルの前半部分では、以下で議論するパイプラインを通じて記事を渡すために使用するクラスが定義されており、後半部分ではAstraに格納したいクラスが定義されています。これらのクラスはすべて標準のPython dataclassesとして定義されており、Astraに格納されているクラスもデータクラスJSONを使用しています。このライブラリは、データクラスの階層をPythonの辞書にシリアライズおよび逆シリアル化できるため、Astraに格納されているPythonの辞書として使用されます。
例えば、ChunkedArticleMetadataOnlyクラスはarticle\_metadataコレクションに格納され、次のように定義されています:
@dataclass_json
@dataclass
class ChunkedArticleMetadataOnly:
_id: str
article_metadata: ArticleMetadata
chunks_metadata: dict[str, ChunkMetadata] = field(default_factory=dict)
suggested_question_chunks: list[Chunk] = field(default_factory=list)このクラスのオブジェクトを保存したい場合(scripts/wikichat/processing/articles.py/update_article_metadata() 内で)、クラスによって追加されたto_dict()メソッドを使用します。これにより、dataclass_jsonデコレーションによって基本的なPython辞書が作成され、astrapyがJSONドキュメントとして保存できます。
METADATA_COLLECTION.find_one_and_replace(
filter={"_id": metadata._id},
replacement=metadata.to_dict(),
options={"upsert": True}
)指定されたテキストを日本語に翻訳すると、次のようになります:
同じファイルの calc\_chunk\_diff() 内でそれを読み戻すと、from\_dict() が格納されたJSONドキュメントから全体のオブジェクト階層を再構築するために使用されます。
resp = METADATA_COLLECTION.find_one(filter={"_id": new_metadata._id})
prev_metadata_doc = resp["data"]["document"]
prev_metadata = ChunkedArticleMetadataOnly.from_dict(prev_metadata_doc)アウトラインとデータアクセスが完了したら、各記事の処理方法を見てみましょう。記事はPythonを使用して構築された処理パイプラインを通過します非同期I/O。非同期処理は、Wikipediaからの更新の突発的な性質に対処するために使用され、また、スクリプトが行う必要があるさまざまなリモート呼び出しを待っている間に処理を続けるために使用されます。処理パイプラインには5つのステップがあります。
load_article()はwikipedia.orgから記事を取得し、Beautiful Soupを使用してHTMLからテキストを抽出します。
chunk_article()は記事をチャンクに分割し、それらの意味を表す埋め込みベクトルを作成するために使用されます。テキストはLangChainのRecursiveCharacterTextSplitterを使用してチャンクに分割され、チャンクのsha256ハッシュがメッセージダイジェストとして計算されます。これにより、チャンクを等しく比較できます。
calc_chunk_diff()はまずAstraをチェックして、この記事に関する以前のメタデータがあるかどうかを確認し、現在の記事を説明する「Diff」を作成します。すべての現在のチャンクのハッシュは、前回記事を見たときに知っていたハッシュと比較されます。以前に見た記事には新しい、削除された、変更されていないチャンクの組み合わせが含まれます。
vectorize_diff()はCohereを呼び出して、記事の新しいチャンクの埋め込みを計算します。「Diff」を計算した後に呼び出すことで、変更されていないテキストのベクトルを計算する必要がなくなります。
store_article_diff()は、この記事について現在知っている情報を格納するためにAstraを更新します。これには3つのステップがあります:
update_article_metadata()は、article_metadataコレクション内の記事のメタデータと、最近の更新を追跡するためのarticle_suggestionsコレクションの両方を更新します。
insert_vectored_chunks()は、すべての新しいチャンクとそれらのベクトルをarticle_embeddingsコレクションに挿入します。
delete_vectored_chunks()は、更新された記事に存在しなくなったすべてのチャンクを削除します。
構築例(2):チャットボットのユーザーエクスペリエンスの構築
Wikipediaから人気のあるデータを事前にロードし、コンテンツのリアルタイム更新を行ったので、チャットボットを構築します。
このアプリケーションでは、フルスタックのReact.jsウェブフレームワークであるNext.jsを使用することにしました。このウェブアプリケーションの2つの最も重要なコンポーネントは、ウェブベースのチャットインターフェースとユーザーの質問に答えを取得するサービスです。
チャットインターフェースは、VercelのAI npmライブラリで動作しています。このモジュールは、開発者がわずか数行のコードでChatGPTのようなエクスペリエンスを構築するのに役立ちます。私たちのアプリケーションでは、このエクスペリエンスをapp/page.tsxファイルに実装しました。このファイルは、ウェブアプリケーションのルートを表しています。以下は、特筆すべきいくつかのコードスニペットです:
"use client";
import { useChat, useCompletion } from 'ai/react';
import { Message } from 'ai';"use client";ディレクティブは、このモジュールがクライアントでのみ実行されることをNext.jsに伝えます。importステートメントは、VercelのAIライブラリをアプリ内で利用可能にします。
const { append, messages, isLoading, input, handleInputChange, handleSubmit } = useChat();このコードは、useChat Reactフックを初期化します。このフックは、チャットボットとやり取りする際にユーザーが持つ状態やほとんどのインタラクティブな体験を処理します。
const handleSend = (e) => {
handleSubmit(e, { options: { body: { useRag, llm, similarityMetric}}});
}ユーザーが質問をすると、その情報をバックエンドサービスに渡し、回答を見つける機能です。
const [suggestions, setSuggestions] = useState<PromptSuggestion[]>([]);
const { complete } = useCompletion({
onFinish: (prompt, completion) => {
const parsed = JSON.parse(completion);
const argsObj = JSON.parse(parsed?.function_call.arguments);
const questions = argsObj.questions;
const questionsArr: PromptSuggestion[] = [];
questions.forEach(q => {
questionsArr.push(q);
});
setSuggestions(questionsArr);
}
});
useEffect(() => {
complete('')
}, []);これは、私たちがインデックス化したWikipediaの最新の更新ページに基づいて提案された質問をロードするために使用する重要なフックを初期化します。 onFinish ハンドラは、サーバーからJSONペイロードを受け取り、それをUIに表示するために setSuggestions に使用します。これらの提案された質問がどのように作成されるかを確認するために、サーバーサイドで詳しく調べてみましょう。
始めるためのいくつかの提案された質問を事前に入力します。

ユーザーが最初にWikiChatをロードすると、最近更新されたWikipediaのページに基づいた提案された質問が表示されます。これらのページはアプリによって取り込まれています。しかし、最近更新されたページから提案された質問にどのように移行するのでしょうか?何が起こっているのかを見るために、/api/completion/route.tsを調べてみましょう。
import { AstraDB } from "@datastax/astra-db-ts";
import { OpenAIStream, StreamingTextResponse } from "ai";
import OpenAI from "openai";
import type { ChatCompletionCreateParams } from 'openai/resources/chat';ここでは、次のリソースをインポートしています: Astra DBクライアント、VercelのAI SDKからのいくつかのヘルパー、OpenAIクライアント、そして間もなく説明するヘルパータイプです。const {
ASTRA_DB_APPLICATION_TOKEN,
ASTRA_DB_ENDPOINT,
ASTRA_DB_SUGGESTIONS_COLLECTION,
OPENAI_API_KEY,
} = process.env;
const astraDb = new AstraDB(ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_ENDPOINT);
const openai = new OpenAI({
apiKey: OPENAI_API_KEY,
});次に、私たちは.envファイルで設定したキーに基づいてAstra DBとOpenAIクライアントを初期化します。
const suggestionsCollection = await astraDb.collection(ASTRA_DB_SUGGESTIONS_COLLECTION);
const suggestionsDoc = await suggestionsCollection.findOne(
{
_id: "recent_articles"
},
{
projection: {
"recent_articles.metadata.title" : 1,
"recent_articles.suggested_chunks.content" : 1,
},
});過去に私たちが摂取プロセスについて話し合い、最新の5つの更新されたWikipediaの記事をデータベース内のドキュメントに保存したことを覚えていますか?ここで、クライアントのfindOne関数を使用してそのドキュメントをクエリします。 projectionオプションを使用すると、クライアントに対して指定したドキュメントの属性のみを返すように指示できます。
const docMap = suggestionsDoc.recent_articles.map(article => {
return {
pageTitle: article.metadata.title,
content: article.suggested_chunks.map(chunk => chunk.content)
}
});
docContext = JSON.stringify(docMap);
提供された文書を取得したら、それを使用して「ページタイトル」と「コンテンツ」のペアの単純な配列オブジェクトを作成し、LLMへの呼び出し時にコンテキストとして渡すことになります。
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo-16k",
stream: true,
temperature: 1.5,
messages: [{
role: "user",
content: `You are an assistant who creates sample questions to ask a chatbot.
Given the context below of the most recently added data to the most popular pages
on Wikipedia come up with 4 suggested questions. Only write no more than one
question per page and keep them to less than 12 words each. Do not label which page
the question is for/from.
START CONTEXT
${docContext}
END CONTEXT
`,
}],
functions
});最新の更新されたWikipediaページのデータ(タイトルと内容)を取得したので、アプリの提案質問にどのように変換するか気になるかもしれません。疑問があれば、LLMに尋ねて解決することにしましょう!
OpenAIのチャット補完APIを呼び出す際に、渡されたデータを使用して適切な質問を構築するようLLMに求めるプロンプトを作成します。どのような種類の質問が必要か、どのくらいの長さであるべきかについての指示を提供し、より創造的な応答を得るために温度を1.5に設定します(値は0〜2の範囲内で変化することができます)。
functionsの最後のパラメータを使用して、カスタム関数を渡すことができます。私たちの場合、これを使用してOpenAIから得られる応答の「形」を定義し、それを簡単に解析してUIで提案された質問を埋めるために使用しています。
const functions: ChatCompletionCreateParams.Function[] = [{
name: 'get_suggestion_and_category',
description: 'Prints a suggested question and the category it belongs to.',
parameters: {
type: 'object',
properties: {
questions: {
type: 'array',
description: 'The suggested questions and their categories.',
items: {
type: 'object',
properties: {
category: {
type: 'string',
enum: ['history', 'science', 'sports', 'technology', 'arts', 'culture',
'geography', 'entertainment', 'politics', 'business', 'health'],
description: 'The category of the suggested question.',
},
question: {
type: 'string',
description: 'The suggested question.',
},
},
},
},
},
required: ['questions'],
},
}];このペイロードの中には、私たちが定義し、戻ってくることを期待している2つの重要な値が埋め込まれています。最初の値は category であり、これはアプリケーションのUIでアイコンを設定するために使用するいくつかの事前定義された値の1つである文字列です。2番目は question であり、これはUIでユーザーに表示する提案された質問を表す文字列です。
質問に答えるためにRAGを使用する

説明したとおり、提案された質問がどのように構築されるかを説明しました。では、ユーザーがWikiChatに質問をすると何が起こるかを見てみましょう。そのリクエストは、/app/api/chat/route.tsで定義されたバックエンドAPIルートによって処理され、LangChainのJS SDKを広範囲に使用しています。それを詳しく見て、何が起こっているのかを見てみましょう。
import { CohereEmbeddings } from "@langchain/cohere";
import { Document } from "@langchain/core/documents";
import {
RunnableBranch,
RunnableLambda,
RunnableMap,
RunnableSequence
} from "@langchain/core/runnables";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { PromptTemplate } from "langchain/prompts";
import {
AstraDBVectorStore,
AstraLibArgs,
} from "@langchain/community/vectorstores/astradb";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { StreamingTextResponse, Message } from "ai";これらのインポートは、Langchain JS SDKの関連する部分を利用できるようにします。Langchainの組み込みのCohereとOpenAIのLLMおよびAstra DBをベクトルストアとして使用していることに気づくでしょう。
const questionTemplate = `You are an AI assistant answering questions about anything
from Wikipedia the context will provide you with the most relevant data from wikipedia
including the pages title, url, and page content.
If referencing the text/context refer to it as Wikipedia.
At the end of the response add one markdown link using the format: [Title](URL) and
replace the title and url with the associated title and url of the more relavant page
from the context
This link will not be shown to the user so do not mention it.
The max links you can include is 1, do not provide any other references or annotations.
if the context is empty, answer it to the best of your ability. If you cannot find the
answer user's question in the context, reply with "I'm sorry, I'm only allowed to
answer questions related to the top 1,000 Wikipedia pages".
<context>
{context}
</context>
QUESTION: {question}
`;
const prompt = PromptTemplate.fromTemplate(questionTemplate);質問テンプレートは、LLMのプロンプトを構築するために使用するものであり、追加のコンテキストを注入して最適な回答を提供するためのものです。指示はかなり自己説明的であり、Wikipediaのソースページへのリンクをmarkdown形式で提供するように指示していることに注意してください。後でUIで回答をレンダリングする際にこれを活用します。
const {messages, llm } = await req.json();
const previousMessages = messages.slice(0, -1);
const latestMessage = messages[messages?.length - 1]?.content;
const embeddings = new CohereEmbeddings({
apiKey: COHERE_API_KEY,
inputType: "search_query",
model: "embed-english-v3.0",
});
const chatModel = new ChatOpenAI({
temperature: 0.5,
openAIApiKey: OPENAI_API_KEY,
modelName: llm ?? "gpt-4",
streaming: true,
});POST関数の内部では、チャット履歴(メッセージ)の値を受け取り、これらの値を使用してpreviousMessagesとlatestMessageを定義します。次に、LangChainで使用するためにCohereとOpenAIを初期化します。
const astraConfig: AstraLibArgs = {
token: ASTRA_DB_APPLICATION_TOKEN,
endpoint: ASTRA_DB_ENDPOINT,
collection: “article_embeddings”,
contentKey: “content”
};
const vectorStore = new AstraDBVectorStore(embeddings, astraConfig);
await vectorStore.initialize();
const retriever = vectorStore.asRetriever(10);今度は、LangChain用のAstra DBベクトルストアを構成する時です。ここでは、接続資格情報、クエリを実行するコレクション、およびDBから戻ってくる10件のドキュメントの制限を指定します。
const chain = RunnableSequence.from([
condenseChatBranch,
mapQuestionAndContext,
prompt,
chatModel,
new StringOutputParser(),
]).withConfig({ runName: "chatChain"});
const stream = await chain.stream({
chat_history: formatVercelMessages(previousMessages),
question: latestMessage,
});ここからが、LangChainの魔法が起こる場所です ✨
まず、私たちはRunnableSequenceを作成します。これには一連のRunnablesを渡します。この時点で知っておく必要があるのは、RunnableSequenceはトップから開始し、各Runnableを実行し、その出力を次のRunnableの入力として渡すということです。
シーケンスを定義した後、チャット履歴と最新の質問を使用して実行します。このシーケンスでは多くのことが行われているので、それぞれの部分を調べてみましょう。
const hasChatHistoryCheck = RunnableLambda.from(
(input: ChainInut) => input.chat_history.length > 0
);
const chatHistoryQuestionChain = RunnableSequence.from([
{
question: (input: ChainInut) => input.question,
chat_history: (input: ChainInut) => input.chat_history,
},
condenseQuestionPrompt,
chatModel,
new StringOutputParser(),
]).withConfig({ runName: "chatHistoryQuestionChain"});
const noChatHistoryQuestionChain = RunnableLambda.from(
(input: ChainInut) => input.question
).withConfig({ runName: "noChatHistoryQuestionChain"});
const condenseChatBranch = RunnableBranch.from([
[hasChatHistoryCheck, chatHistoryQuestionChain],
noChatHistoryQuestionChain,
]).withConfig({ runName: "condenseChatBranch"});シーケンス内の最初のRunnableはcondenseChatBranchです。このコードの目的は、WikiChatをスマートにし、以前に質問された内容を認識させることです。説明のために具体例を挙げましょう。
質問#1:スターウォーズの悪役は誰ですか?
回答:ダース・ベイダー
質問#2:彼の子供たちは誰ですか?
最初の質問が何だったかわからないと、2番目の質問は意味をなしません。そのため、RunnableBranchを定義します。これは、if/else文のような機能を持ちます。もしもRunnable hasChatHistoryがtrueであれば、LangchainはchatHistoryQuestionChainを実行し、そうでなければnoChatHistoryChainを実行します。
hasChatHistoryCheckは、チェーンを初期化する際に定義したchat\_history入力をチェックし、空でない値があるかどうかを確認します。
このチェックがtrueである場合、chatHistoryQuestionChain Runnableは質問とチャット履歴をLLMに提供して、より良い質問を構築します。これがどのように機能するかを見るために、condenseQuestionPromptを見てみましょう。
const condenseQuestionTemplate = `Given the following chat history and a follow up
question, If the follow up question references previous parts of the chat rephrase the
follow up question to be a standalone question if not use the follow up question as the
standalone question.
<chat_history>
{chat_history}
</chat_history>
Follow Up Question: {question}
Standalone question:`;
const condenseQuestionPrompt = PromptTemplate.fromTemplate(
condenseQuestionTemplate,
);ここでは、私たちはチャット履歴を考慮したプロンプトを定義し、具体的にLLMに指示して質問がフォローアップのものかどうかを見るようにします。前述の例を使うと、LLMは「彼の子供たちは誰ですか?」という質問を受け取り、チャット履歴を見て、質問を「ダース・ベイダーの子供たちは誰ですか?」と書き換えます。すると、より賢いチャットボットが完成します!
もしチャット履歴がない場合、noChatHistoryQuestionChainは何も行わず、ユーザーがした質問をそのまま返します。
const combineDocumentsFn = (docs: Document[]) => {
const serializedDocs = docs.map((doc) => `Title: ${doc.metadata.title}
URL: ${doc.metadata.url}
Content: ${doc.pageContent}`);
return serializedDocs.join("nn");
};
const retrieverChain = retriever.pipe(combineDocumentsFn).withConfig({ runName:
"retrieverChain"});
const mapQuestionAndContext = RunnableMap.from({
question: (input: string) => input,
context: retrieverChain
}).withConfig({ runName: "mapQuestionAndContext"});私たちのメインシーケンスの次は、mapQuestionAndContextです。これは前のステップ(ユーザーの質問)からの出力を受け取り、Astra DBから最も近いマッチングドキュメントを取得し、それらを文字列に結合します。
この文字列は次のステップに渡され、それは前もって定義したプロンプトです。その後、この完全に展開されたプロンプトをLLMに渡し、最終的にLLMからの出力をLangChain StringParserに渡します。
return new StreamingTextResponse(stream);最後に行うことは、LangchainのstreamをStreamingTextResponseとして返すことです。これにより、ユーザーはLLMの出力をリアルタイムでワイヤーを介して受け取ることができます。
まとめ
Wikipediaの最も人気のある最近更新されたページについて質問に答えるインテリジェントなチャットボットを構築するためにカバーした内容を振り返りましょう。
最も人気のあるWikipedia記事をスクレイピングして初期データセットをロードする。
リアルタイムの更新を待ち、差分のみを処理する。
LangChainを使用してテキストデータを知能的にチャンク化し、Cohereを使用して埋め込みを生成する。
アプリケーションとベクトルデータをAstra DBに保存する。
VercelのAIライブラリを使用してWebベースのチャットボットUXを構築する。
Astra DBでのベクトル検索を実行する。
OpenAIを使用して正確でコンテキストに即した応答を生成する。
現在のWikiChatのバージョンはVercelにデプロイされており、https://wikich.at でチェックできます。
参照資料: