
Llama3に関する情報と実装事例

LLama 3に関するキーポイント
Metaは、オープンソースの大規模言語モデルの最新作であるMeta Llama 3を発表しました。このモデルには8Bおよび70Bのパラメータモデルが搭載されています。
新しいトークナイザー:Llama 3は、128Kのトークン語彙を持つトークナイザーを使用し、Llama 2と比較して15%少ないトークンを生成することで、言語をより効率的にエンコードしています。
グループ化されたクエリアテンション機能:Llama 3の全モデルで実装されており(Llama 2では最大のモデルでのみ使用)、より小さなモデルがL能力を持つようになりました。
15兆トークンで事前トレーニング:全体のうちそのうち95%が英語である。
16,000のGPUで同時にトレーニングを実施:GPUの稼働時間を管理するための新しいツールが開発されました。GPUの利用率がファインチューニングにとっての最大課題であるため、大きな期待を持たれています。
Llama2によるデータセットクリーニング:データ品質領域でのLLMの興味深い使用例として、Llama 2がチューニングのためにデータセットのクリーニングに使用されました。
新しいファインチューニングアプローチ:モデルのハルシネーションとエラー率を低減するために推論トレーシングと選好ランキングを組み合わせたアプローチで、OpenAIが採用したステップバイステップの推論と類似してます。
新しいライブラリ:TorchTune:PyTorchネイティブのライブラリで、LLMの作成、ファインチューニング、実験を行うためのメモリ効率の良いトレーニングレシピを提供します。
責任あるAI:Metaは、Llama Guard 2やCode Shieldなどの信頼性と安全性のツールを提供することで、責任あるAI開発を強調しています。
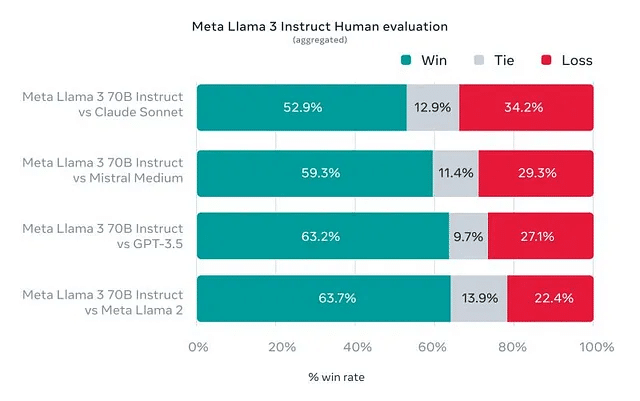
性能:Llama 3は、改善された推論能力と業界基準での最先端の性能を誇り、詳細なベンチマークはClaudeとGPT4との比較になります。
無償利用の承認条件:Llama 3を利用して開発する製品の月間利用者数が 7億人以上 を超えない場合、これらのモデルを使用するためにMetaに追加の承認を求める必要はありません。
GPT4との詳細な比較や研究論文へのリンクは提供されていませんが、近々新しい発表があることが想定されており、おそらく400Bパラメータモデルが登場する可能性があります。この400Bパラメータモデルの初期チェックポイントの結果は、GenAIにおける次の大きな動きを示唆してます。
Llama 3の特徴点
2つのモデルを提供
LLaMa 3 8B
80億のパラメータを持つモデルで、2023年3月までの知識を持っています(つまり、以降の出来事については何も知りません)。
LLaMa 3 70B
700億のパラメータを持つモデルで、2023年12月までの知識を持っています。
Llama 3のもう一つの特徴は、モデルを公式に活用することになったことで、具体的にはMeta AIという無料の仮想アシスタントをリリースし、Whatsapp、Facebook Messenger、またはInstagramなどのMetaのサービスを通じて利用できるようになります。
モデル自体に焦点を当てると、次の点で特徴があります。
80億のレベルは、Small Language Models(SLMs)と見なされるモデルで、「これはそのサイズで世界で最も優れたモデルである」と予め主張できます。コード合成と数学の大幅な改善があり、これは推論能力の点でかなりの飛躍を示しています。
このモデルはLLaMa 2 70Bと似た結果を示しており、1年も経っていないにもかかわらず、10倍小さい前世代のモデルと同じくらい優れていることを明確に示しています。
モデルアーキテクチャ
モデルアーキテクチャに関しては、Llama 2とLlama 3は実際に非常に似ています。これは、専門家の混合モデルが現在トレンドになっているにも関わらず、Llama 3モデルは伝統的な密なデコーダー専用トランスフォーマーです。ただし、トークナイザーの語彙は32kから128kのトークンに4倍拡張されています。
これにより、モデルは各可能な次のトークンに対して4倍のロジットを予測する必要がありますが、テキストのトークナイゼーションにより、Llama 2トークナイザーと比較して最大15%のトークンが減少します。つまり、Llama 2とLlama 3モデルが同じ数のトークンを生成しても、Llama 3モデルではテキストのトークナイズに同じ長さのテキストをトークナイズするためにより少ないトークンが必要なため、ユーザーはより速くより多くのテキストを見ることができます。
また、MetaチームはLlama3–8Bモデルにグループクエリアテンション(GQA)を追加しました(以前はLlama2–70Bモデルのみ使用されていました)。これら2つの変更を適用することで、MetaチームはLlama3–8Bモデルについて次のような観察をしました:
[...] Llama 2 7Bと比較してモデルのパラメータが1B多いにも関わらず、改善されたトークナイザーの効率とGQAはLlama 2 7Bと同等の推論効率を維持するのに貢献しています。
プレトレーニングデータ
Llama 3は15兆トークン以上で訓練されました!比較すると、これを中断せずに読むには平均して70,000年以上かかるでしょう。これはLlama 2の訓練に使用されたトークン数の7倍です。また、Llama 2と比較して、4倍のコードデータが使用されています。マーク・ザッカーバーグによると、これはモデルがコーディングを学ぶだけでなく、推論などの他の能力を獲得するのにも役立つとのことです。高品質のデータを確保するために、Metaはヒューリスティックフィルター、NSFWフィルター、意味重複アプローチ、およびテキスト分類器などのデータフィルタリングパイプラインを使用し、データ品質を予測します。面白いことに、テキスト品質の分類にはLlama 2モデルが使用されました。
プレトレーニングのスケーリングアップ
ブログ投稿を読んだ後、これについては完全には理解できませんでした。詳細については研究論文を楽しみにしています。ブログ投稿では、Metaは基本的に次のように説明しています。
「[...] 下流のベンチマーク評価のための詳細なスケーリング法を開発しました。これらのスケーリング法により、最適なデータミックスを選択し、トレーニングコンピュートを最適に活用するための情報を得ることができます。」
したがって、プレトレーニング中に特定の能力を特に向上させることを目指しており(たとえば数学、コーディング、推論など)、そのためにデータミックスを動的に調整することのようです。ただし、これは知識よりも推測ですが、論文で詳細を見つけることができると確信しています。もう1つの興味深い発見は、8Bモデルが(15兆トークン)というチンチラの最適値(約200Bトークン)よりもはるかに多くのトークンで訓練されると、対数線形的に改善し続けるということです。この点に関して、彼らは次のようにも述べています。
「より大きなモデルは、より少ないトレーニングコンピュートでこれらのより小さなモデルの性能に匹敵することができますが、推論中にははるかに効率的であるため、一般的にはより小さなモデルが好まれます。」
指示のファインチューニング
ブログ投稿に基づくと、Llama 3モデルの指示のファインチューニングには、Llama 2モデルと比較して、Metaははるかに多くの計算時間と努力を費やして最適化していると思います。彼らは次のように述べています。
「ポストトレーニングへのアプローチは、教師付きファインチューニング(SFT)、リジェクションサンプリング、プロキシマルポリシーオプティマイゼーション(PPO)、およびダイレクトポリシーオプティマイゼーション(DPO)の組み合わせです。SFTで使用されるプロンプトの品質と、PPOおよびDPOで使用される優先順位付けの品質は、整合されたモデルの性能に大きな影響を与えます。」
Llama 2の論文では、SFTデータの品質が非常に重要であると述べており、Llama 3モデルのためのSFTデータセットを作成する際にこれを十分に考慮したと思います。
「モデルの品質における最大の改善のいくつかは、このデータを注意深くキュレーションし、人間の注釈者による注釈に対して品質保証の複数のラウンドを実施することから得られました。」
PPOおよびDPOの使用に関して、次の声明が非常に興味深いと思いました。
「PPOおよびDPOを介した優先順位付けからの学習は、Llama 3の推論およびコーディングタスクの性能を大幅に向上させました。」
そのため、彼らはこのような技術を使用することの重要性と有用性を強調する、本当に注目すべきものを見つけたようです。
「モデルは正しい答えを出す方法を知っていますが、それを選択する方法を知らないのです。優先順位付けのトレーニングにより、モデルはそれを選択する方法を学ぶことができます。」
したがって、LLMを優先順位付けにファインチューニングすることで、モデルは推論トレースの中から実際に正しいものを選択する方法をよりよく理解するようになります。
Llama 3はシンプルなアーキテクチャ
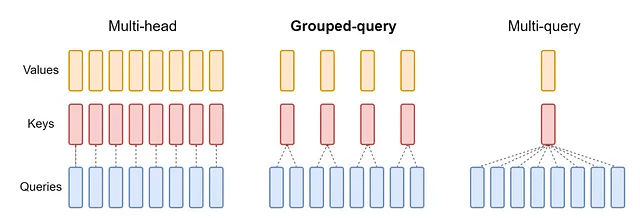
Transformerベースのモデルと同様に、Llama 3は前述のミキシング演算子を使用して言語を処理します。
ただし、LLaMa 3が標準のアテンションに導入する最大の変更は、グループ化されたクエリアテンションを両方のモデルに標準化することです(LLaMa 2ファミリーでは、最大のモデルのみがそれを持っていました)。
単純に言うと、各ヘッドが独自のキーと値のベクトルを持つ代わりに(前のイメージのように)、ここではシーケンスが単語のグループに分割され、それらの単語はすべてのヘッドで同じキーと値のベクトルを共有します。
言い換えると、入力シーケンスは単語のグループに分割され、特定のグループ内のすべての単語は、すべてのヘッドで同じキーと値のベクトルを持ちます。
これはトレードオフです。理想的なシナリオでは、各単語がそれぞれのヘッドで独自の特定のキーと値のベクトルを持ち、他の単語とより微妙な関係を特定できるようになります。ただし、これはうまく機能するようです。
モデルの語彙のトークン数も32kから128kに4倍に増やし、平均して生成されるトークン数が15%少なくなることが報告されています(コストが安く、推論が速くなります)。
1500兆トークン
それがモデルがトレーニング中に使用したトークンの数です。これは12兆ワードに相当し、前世代のLlama 2と比べてほぼ8倍に増加し、『最適』と考えられるものの75倍の大きさです。
データ量(と質)は間違いなく優れたモデルを作成する際に引く最も重要な要素であることを示しています。
Metaによると、LLaMa 2 8BとLlama 3 8Bは、トレーニングされたデータの量以外はほとんど同じです。
そして驚くべきことに、Metaによれば、彼らはまだ困惑飽和には遠く及んでいないと主張しています。素人にとっては、データを8倍に増やした後も、モデルは学習を続けたのです。
コンテキストウィンドウが小さい
モデルのコンテキストウィンドウがたったの8,000トークン(または6,000単語)。参考までに、それは現行の最先端技術であるGemini 1.5の166分の1以下です。
Metaはこれを認識しており、時間をかけてコンテキストウィンドウをさらに拡大する意向であると迅速に述べました。幸いなことに、GoogleのInfini-attentionのように、ファインチューニングによってコンテキストウィンドウを無制限に延長することができるため(ゼロからトレーニングする必要はない)、間もなくLLaMa 3モデルが大幅にアップグレードされと予測されます。
さらに、モデルはまだマルチモーダルではなく、テキストとコードのみを処理および生成できます。Metaはそれも間もなく追加することを確認しています。
さらなるニュースがもうすぐ…
今日明らかになったことはすでに素晴らしいですが、まだまだたくさんのことがあります。
マーク・ザッカーバーグ氏はインタビューで、Llama 4とLlama 5が現在開発中であり、2024年のリリースを予定していることを明らかにしました。研究論文はまだ利用可能ではありませんが、Metaによると、今後数ヶ月で研究論文とともにアップグレードを展開する予定です。
今後数ヶ月で、新しい機能、より長いコンテキストウィンドウ、追加のモデルサイズ、向上した性能を導入する予定であり、Llama 3の研究論文も共有する予定です。
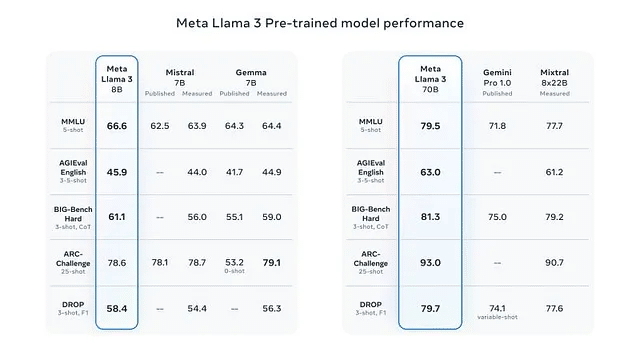
ベンチマーク結果
さて、Llama 3モデルが同じパラメータスケール上で類似モデルと比較された場合の結果を見てみましょう。個々のベンチマークについては下記に簡単な要約を付記:
MMLU: 科学、歴史、法律、数学、コンピュータサイエンスなど幅広いトピックにわたる一般知識と問題解決能力をテストします
AGIEval: 人間中心のベンチマーク(大学入学試験、法科大学院入学試験、数学競技、弁護士資格試験など)
BIG-Bench Hard: 多様な204のタスクにわたる大規模言語モデルの多段階推論能力を評価します
ARC-Challenge: 多肢選択科学試験データセット(常識的な推論能力を評価)
DROP: 難解な読解
オープンソースであるLlama 3がGemini Pro 1.0のような商用利用可能なモデルを上回っている結果が出ています。特に、70Bレベルでは、Llama 3 70Bが最も優れており、Gemini Pro 1.5 や Claude 3 Sonnet などの最も強力な独自のモデルと比較しても、最も優れているスコアを獲得しています。
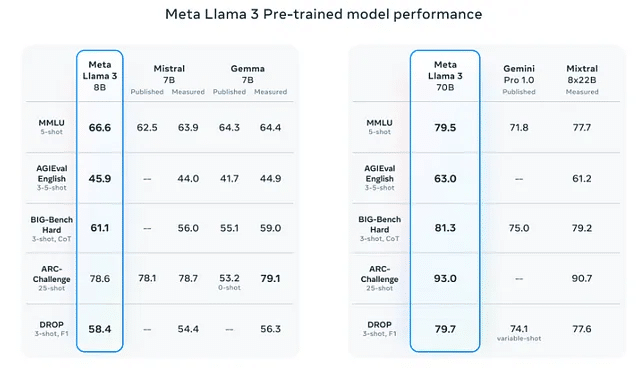
Llama3–8BとLlama3–70Bの両方が、それぞれのパラメータースケールで他の最先端のLLMを一貫して上回っていることがわかります。比較のために、GPT-4はMMLUベンチマークで86.4のスコアを達成している一方、GPT-3.5(ChatGPT)は70.0のスコアを達成しています。これは新しいLlama 3モデルがどれほど強力であるかを示しています。GPT-3.5がパラメーターの量が約2.5倍であり、GPT-4がLlama3–70Bモデルの約25倍のパラメーターを持っていることを考えると、Llama3–70BがGPT-3.5モデルを大幅に上回りながら、GPT-4モデルとあまり変わらない性能を発揮しているのは非常に印象的です。
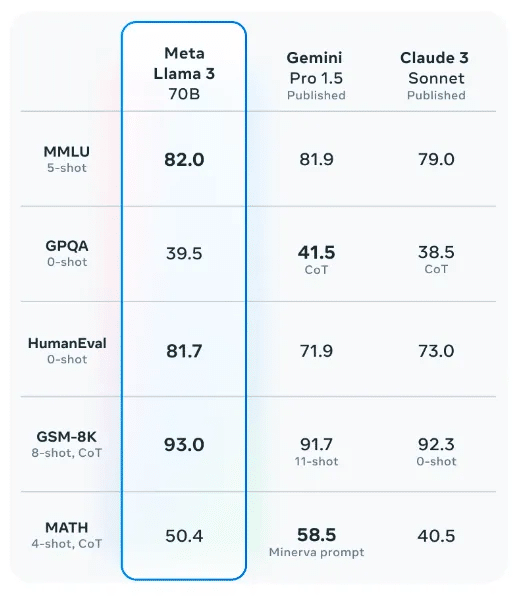
また、HumanEvalスコアが81.7であり、その性能は、71.9のGemini Pro 1.5や73.0のClaude 3 Sonnetなどの主要なクローズドモデルを上回っています。ただし、まだトップ性能のクローズドモデル、特にClaude 3 Opus(84.9)やGPT4 Turbo(85.7)にはわずかに及びません。

MetaはGPT-4レベルに到達する可能性が高い400B+モデルに取り組んでいます。少なくとも現在のトレーニングチェックポイントのベンチマークスコアは非常に有望に見えます。
Llama 3を試す方法
現在、Meta AIはごく一部の国でのみ利用可能です。
Meta AIは、現在、米国外の数十カ国で英語で展開されています。これにより、オーストラリア、カナダ、ガーナ、ジャマイカ、マラウイ、ニュージーランド、ナイジェリア、パキスタン、シンガポール、南アフリカ、ウガンダ、ザンビア、ジンバブエの人々がMeta AIにアクセスできるようになりました。そしてこれは始まりに過ぎません。
VPNを使用することもできますが、Llama 3を試すための他の無料の方法もあります:
HuggingFace Chat
HuggingFace Chatにアクセスして、ログインするかアカウントを作成してください。現在のモデル設定でMeta-Llama-3–70B-Instructモデルを選択するようにしてください。
ウェブ検索機能を有効にするオプションもあります。
Langsmithプレイグラウンド
Langsmithのプレイグラウンドダッシュボードにログインし、プロバイダーを「Fireworks」、モデルを「llama-v3-70b-instruct」に設定してください。
Replicate
最後に、Replicate上でAPIを使用してLlama-3-70b-instructモデルを試すことができます。
この言語モデルの価格は、入力トークンの数と出力トークンの生成数によって決まります。
また、近いうちに、MetaのRay-BanスマートグラスでマルチモーダルMetaAIをテストできるようになります。
実装例1:ローカルコンピュータでLlama 3とLlama3-Chatを動かす
Llama 3モデルには8Bパラメータを持つものと70Bパラメータを持つものの2つがあります。これらのモデルをFP16精度でロードするには、少なくとも16GBまたは140GBのVRAM(またはCPUのRAM)が必要です。これは多く聞こえるかもしれませんが、現代の量子化技術により、このメモリ要件を大幅に削減しながら生成されたテキストのほぼ同じ品質を維持することができます。
この記事では、Llama3–70BモデルのAWQ-量子化バージョンを使用し、これによりローカルコンピュータでLlama3–70Bモデルをロードおよび実行できます。そのために、NVIDIAがYouTubeとMediumのチャンネルをサポートするために提供してくれたNVIDIA RTX 6000 Ada GPUを使用します。RTX 6000 Ada GPUには48GBのVRAMが搭載されています。Llama3–70BのAWQ-量子化バージョンは4ビット精度を使用し、メモリ要件を約35GBのVRAMに削減します。
特定のファインチューニングおよび推論予算に対して、一般的にはパラメータの数を増やし、その精度を減らすことをお勧めします。逆のことをするよりも、最初のオプションを選択した場合、ほとんど常により良いテキスト生成結果を得ると思います。
Llama3–70Bモデルを使用する前に、必要なライブラリをインストールする必要がありました。そのために、vLLMライブラリを使用することにしました。人気のあるtransformersライブラリをよく使っていましたが、vLLMライブラリを使用すると、はるかに高速な推論が可能です。
pip install vllm==0.4.0.post1 flash-attn==2.5.7 autoawq==0.2.3 gradio==4.27.0すべてのライブラリが正常にインストールされたら、LLMをロードすることができます。ローカルコンピュータでLlama3モデルと視覚的に魅力的に対話するために、私はいくつかのコードを書きました。そのために、LLama3モデルと対話するための視覚的に魅力的なUIを簡単に作成できるgradioライブラリを使用しました。vLLMライブラリのLLMクラスには生成されたトークンをストリームするオプションがないため、私は自分でLLMクラスの軽量版をすばやく書きました。それをStreamingLLMと呼びました。テキスト生成のハイパーパラメータについては、Metaチームで定義されたデフォルト値を使用しました。
from vllm.engine.llm_engine import LLMEngine
from vllm.engine.arg_utils import EngineArgs
from vllm.usage.usage_lib import UsageContext
from vllm.utils import Counter
from vllm.outputs import RequestOutput
from vllm import SamplingParams
from typing import List, Optional
import gradio as gr
class StreamingLLM:
def __init__(
self,
model: str,
dtype: str = "auto",
quantization: Optional[str] = None,
**kwargs,
) -> None:
engine_args = EngineArgs(model=model, quantization=quantization, dtype=dtype, enforce_eager=True)
self.llm_engine = LLMEngine.from_engine_args(engine_args, usage_context=UsageContext.LLM_CLASS)
self.request_counter = Counter()
def generate(
self,
prompt: Optional[str] = None,
sampling_params: Optional[SamplingParams] = None
) -> List[RequestOutput]:
request_id = str(next(self.request_counter))
self.llm_engine.add_request(request_id, prompt, sampling_params)
while self.llm_engine.has_unfinished_requests():
step_outputs = self.llm_engine.step()
for output in step_outputs:
yield output
llm = StreamingLLM(model="casperhansen/llama-3-70b-instruct-awq", quantization="AWQ", dtype="float16")
tokenizer = llm.llm_engine.tokenizer.tokenizer
sampling_params = SamplingParams(temperature=0.6,
top_p=0.9,
max_tokens=4096,
stop_token_ids=[tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|eot_id|>")]
)その後、次のコードを実行することで、見栄えの良い方法でLlama 3モデルと対話を開始することができます。
def predict(message, history):
history_chat_format = []
for human, assistant in history:
history_chat_format.append({"role": "user", "content": human })
history_chat_format.append({"role": "assistant", "content": assistant})
history_chat_format.append({"role": "user", "content": message})
prompt = tokenizer.apply_chat_template(history_chat_format, tokenize=False)
for chunk in llm.generate(prompt, sampling_params):
yield chunk.outputs[0].text
gr.ChatInterface(predict).launch()実装例2:Llama 3をPythonを使ってローカルコンピュータ上で動かす
必要なもの
llama.cpp ライブラリとPythonを使用して、コンピュータ上でモデルを素早く実行します。これは初期テストのためのセットアップになります。テキストインターフェースのみですが、100%動作します。
依存関係
2つのライブラリのみをインストールする必要があります。
CPUのみで
新しいディレクトリを作成します(私の場合は TestLlama3 )、そのディレクトリに移動し、ターミナルウィンドウを開きます。
python -m venv venv
venvScriptsactivate #to activate the virtual environmentPythonの環境が整ったので、llama-cpp-pythonとOpenAIライブラリをインストールします。
pip install llama-cpp-python[server]==0.2.62
pip install openaiOpenAIライブラリは、llama-cppに付属の互換性のあるOpenAPIサーバーを使用するために必要です。これにより、将来のStreamlitやGradioアプリケーションに備えることができます。
Nvidia GPUを使用する場合
NVidia GPUをお持ちの場合、pipコマンドを呼び出す前にコンパイラのフラグを設定する必要があります。
$env:CMAKE_ARGS="-DLLAMA_CUBLAS=on"
pip install llama-cpp-python[server]==0.2.62
pip install openaiHugging Face から Llama-3-8B GGUF をダウンロード
これが必要な本物のモデルです:モデルの量子化(圧縮)された重みが GGUF 形式で提供されています。
いくつか試しましたが、現時点(2024年4月19日 18:00 中国時間)では、固定されたトークナイザーとチャットテンプレートを持つ唯一のものは、このリポジトリからです:
QuantFactory/Meta-Llama-3-8B-Instruct-GGUF at main
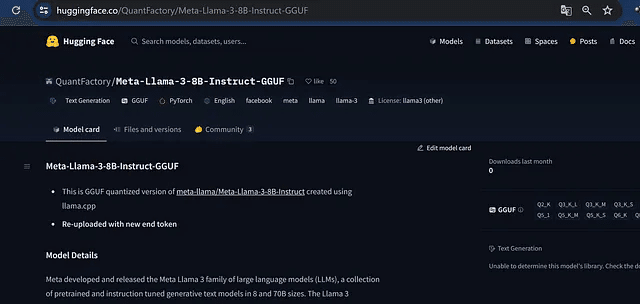
ファイルをクリックし、バージョンを選択して、Q2_K(3 Gbのみ)またはQ4_K_M(4.9 Gb)を選択してください。最初のものは正確性は低いが速いですが、2番目のものは速度と正確性のバランスが良いです。
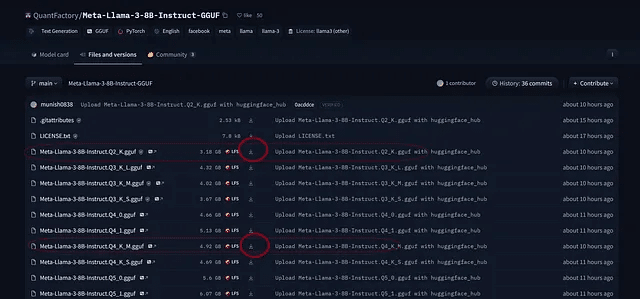
ダウンロードアイコンをクリックして、それを「model」というサブフォルダに保存してください。
メインプロジェクトディレクトリに「model」というフォルダを作成してください。そのフォルダの中にGGUFファイルをダウンロードしてください。
以上で準備完了です。
2つのターミナル戦略
これを行う最も簡単な方法は、llama-cpp-serverを1つのターミナルウィンドウで実行すること(仮想環境がアクティブになっていることを忘れずに...)、そしてAPIとやり取りするPythonファイルを別のターミナルウィンドウで実行することです(こちらも仮想環境がアクティブになっていることを忘れずに...)
したがって、メインディレクトリで別のターミナルウィンドウを開き、仮想環境をアクティブにしてください。
作業が完了すると、ここでと同じ状況になるはずです。
Pythonファイル
私たちのPythonファイル(LLama3-ChatAPIと呼んでいます)は、テキストインタフェースプログラムです。私はプロンプト入力を受け取り、APIサーバーに送受信して指示を受け取ります。
使用しているモデルと完全に相互依存しているため、便利です。以下をご覧ください:
# Chat with an intelligent assistant in your terminal
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")ここでは、標準API呼び出し用の組み込みクラスを持つOpenAIライブラリを呼び出し、clientをインスタンス化します。
次に、メッセージ履歴をフォーマットします。最初のペアでは、Pythonの辞書の最初のエントリがシステムメッセージであり、2番目がユーザープロンプトで、モデルに自己紹介を求めています。
history = [
{"role": "system", "content": "You are an intelligent assistant. You always provide well-reasoned answers that are both correct and helpful."},
{"role": "user", "content": "Hello, introduce yourself to someone opening this program for the first time. Be concise."},
]
print("033[92;1m")奇妙なprint文は、端末の色を変更するためのANSIエスケープコードです(詳細はこちらを参照してください)。
そして、whileループを開始します:基本的には、常にユーザーにプロンプトを求め、Meta-Llama-3-7B-instructモデルからの返信を生成します。quitまたはexitと言うまで。
while True:
completion = client.chat.completions.create(
model="local-model", # this field is currently unused
messages=history,
temperature=0.7,
stream=True,
)
new_message = {"role": "assistant", "content": ""}
for chunk in completion:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
new_message["content"] += chunk.choices[0].delta.content
history.append(new_message)
print("033[91;1m")
userinput = input("> ")
if userinput.lower() in ["quit", "exit"]:
print("033[0mBYE BYE!")
break
history.append({"role": "user", "content": userinput})
print("033[92;1m")最初の呼び出しはチャットの完了のためです:実際に、モデルについての質問がすでにありますよね?
こんにちは、初めてこのプログラムを開く人に自己紹介をしてください。簡潔にしてください。
私たちはStreamメソッドを使用しているので、PythonはAPI呼び出しから送信されるとすぐにレスポンスをトークンごとに入力し始めます。
注意:GPUを持っていない場合、プロンプトの長さに応じて数秒かかる場合があります(以前のすべての会話が常に新しいプロンプトの一部であることを考慮してください... さもなければ、Llama3はあなたの名前さえ忘れます!)
最後に、ユーザー入力を求めて、再度開始する準備ができました:新しいプロンプトを既存のチャット履歴(history)に追加して、Llama3がそれに取り組み始めることができるようにします。
Pythonファイルを保存して、準備完了です!
実行
最初のターミナルウィンドウで、venvをアクティブにして、次のコマンドを実行します:
#with CPU only
python -m llama_cpp.server --host 0.0.0.0 --model .modelMeta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048
#If you have a NVidia GPU
python -m llama_cpp.server --host 0.0.0.0 --model .modelMeta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048 --n_gpu_layers 28FastAPIサーバーを開始し、OpenAI標準と互換性のあるものを取得する必要があります。こんな感じのものが得られるはずです。
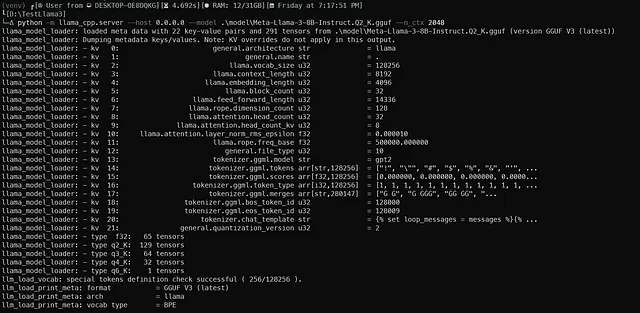
サーバーが準備完了すると、Uvicornは美しい緑色のライトメッセージで通知します。
注意: ここにはコンテキストとして2048トークンのみを置いています。実際にはLlama3にはコンテキスト用に8192トークンがありますが、これはRAMまたはVRAMを消費するため、一時的にそれを低く保っています(GPUがクラッシュしないように)*
注意2: この8Bパラメータモデルには確かに33層ありますが、そのうち28層のみをGPUに設定しました。どれだけの層をオフロードできるか、クラッシュせずに試してみてください。*
注意3: この例では、Q2バージョンのMeta-Llama-3-8B-Instruct.Q2_K.ggufを使用しました。4ビット量子化バージョンを実行するには、Q4_K_Mファイル名に置き換えてください*
もう一つのターミナルウィンドウは、驚くほど短い(しかし有用な)Pythonコード用です。venvをアクティブにして実行してください。
python .Llama3-ChatAPI.py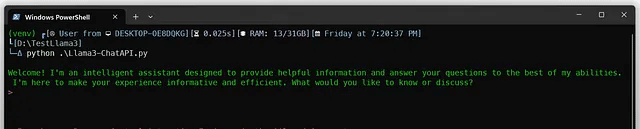
ゆっくりゆっくり、Llama-3-8Bが自己紹介を始めるでしょう
準備はできています。どんな質問でも投げて、楽しんでください。
こちらは私の質問です...
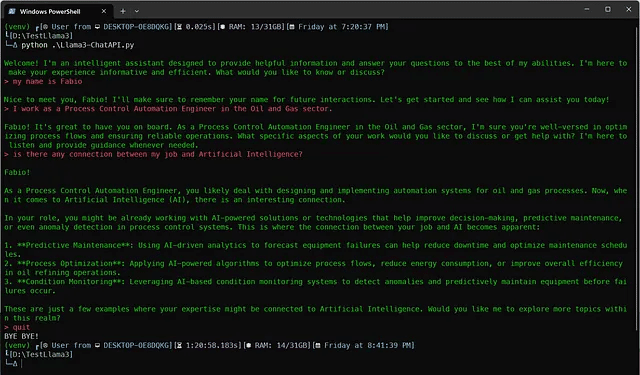
実装例3:Hugging Face Chatで無料で実行できます
もし70Bモデルバージョンを試してみたい場合は、直接HuggingFace Hub Chatで実行できます。
HuggingChat:Making the community's best AI chat models available to everyone.
huggingface.co
実装例4:Llama3とOllamaでRAGの改善を試みる
この記事では、昨日リリースされたmetaの最も先進的なオープンソースの大規模言語モデル「Llama-3」を活用した、完全なローカルインフラストラクチャを利用した高度なRAGの実装方法について見ていきます。この記事は、「Llama-3」を使用した高度なRAGのDay-1実装の手引書となります。
はじめに:
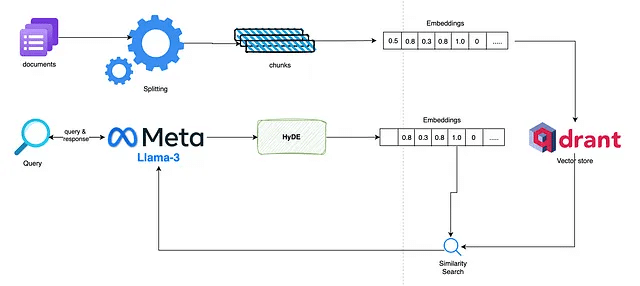
この記事では、与えられた研究論文をパイプラインの入力として使用し、ユーザーのクエリに答える高度なRAGを作成します。このパイプラインの構築に使用されるテクノロジースタックは以下の通りです。
Ollama埋め込みモデル mxbai-embed-large
Ollama量子化 Llama-3 8bモデル
ローカルホストされた Qdrant ベクトルデータベース。
このセットアップでは、費用は絶対に0であり、情報は非常に安全でプライベートであることが明らかです。
HyDEとは?
HyDE、またはHypothetical Document Embeddingsは、2022年のGaoらによる「Relevance Labelsなしでの正確なゼロショット密な検索」と題された論文で提示された革新的な作業から生まれました。この研究の主な目標は、意味的埋め込みの類似性に依存するゼロショット密な検索を向上させることでした。提示された解決策であるHyDEは、2段階の方法論を通じて操作します。
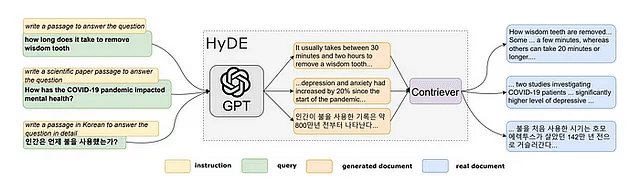
元の論文から引用されたHyDE。
初めのステップであるステップ1では、言語モデル(具体的にはGPT-3によって具体例示される)が指示に従って操作され、元のクエリに基づいた仮説の文書を生成するように促されます。このプロセスは、文書内で提示された質問に適合するように慎重に調整されており、文書が仮説であるにも関わらず関連性を確保しています。
ステップ2に移行すると、生成された仮説の文書は、「非監督対照エンコーダー」として特徴付けられるContrieverを使用して埋め込みベクトルに変換されます。このエンコーダーは、仮説の文書をベクトル表現に変換し、その後、類似性検索や取得タスクに利用されます。
HyDEは、基本的には2つの重要な要素を介して文書をベクトル埋め込みに変換することによって機能します。最初の側面では、言語モデルを用いた生成タスクが関与し、仮説の文書内でも関連性を捉えることを目指し、事実に基づかない可能性を認識しています。その後、対照エンコーダーによって管理される文書-文書の類似性タスクが埋め込みプロセスを洗練し、余分な詳細を取り除き、効率を向上させます。
特筆すべきは、HyDEはContrieverなどの既存の非監督型密なリトリーバーを凌駕しています。さらに、様々なタスクや言語にわたってファインチューニングされたリトリーバーと同等の性能を発揮しています。この方法論的アプローチは、密なリトリーバーを2つの一貫したタスクに凝縮し、意味的埋め込みに基づくリトリーバー手法の著しい進歩を示しています。
実装:
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
StorageContext,
Settings,
get_response_synthesizer)
from llama_index.core.query_engine import RetrieverQueryEngine, TransformQueryEngine
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.schema import TextNode, MetadataMode
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
import qdrant_client
import logging初期化:
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# load the local data directory and chunk the data for further processing
docs = SimpleDirectoryReader(input_dir="data", required_exts=[".pdf"]).load_data(show_progress=True)
text_parser = SentenceSplitter(chunk_size=512, chunk_overlap=100)
text_chunks = []
doc_ids = []
nodes = []埋め込みをプッシュするためのベクトルストアを作成します。
# Create a local Qdrant vector store
logger.info("initializing the vector store related objects")
client = qdrant_client.QdrantClient(host="localhost", port=6333)
vector_store = QdrantVectorStore(client=client, collection_name="research_papers")ローカル埋め込みとLLMモデル
# local vector embeddings model
logger.info("initializing the OllamaEmbedding")
embed_model = OllamaEmbedding(model_name='mxbai-embed-large', base_url='http://localhost:11434')
logger.info("initializing the global settings")
Settings.embed_model = embed_model
Settings.llm = Ollama(model="llama3", base_url='http://localhost:11434')
Settings.transformations = [text_parser]ノードを作成し、ベクトルストア、HyDEトランスフォーマーを作成し、最後にクエリを実行します。
logger.info("enumerating docs")
for doc_idx, doc in enumerate(docs):
curr_text_chunks = text_parser.split_text(doc.text)
text_chunks.extend(curr_text_chunks)
doc_ids.extend([doc_idx] * len(curr_text_chunks))
logger.info("enumerating text_chunks")
for idx, text_chunk in enumerate(text_chunks):
node = TextNode(text=text_chunk)
src_doc = docs[doc_ids[idx]]
node.metadata = src_doc.metadata
nodes.append(node)
logger.info("enumerating nodes")
for node in nodes:
node_embedding = embed_model.get_text_embedding(
node.get_content(metadata_mode=MetadataMode.ALL)
)
node.embedding = node_embedding
logger.info("initializing the storage context")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
logger.info("indexing the nodes in VectorStoreIndex")
index = VectorStoreIndex(
nodes=nodes,
storage_context=storage_context,
transformations=Settings.transformations,
)
logger.info("initializing the VectorIndexRetriever with top_k as 5")
vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
response_synthesizer = get_response_synthesizer()
logger.info("creating the RetrieverQueryEngine instance")
vector_query_engine = RetrieverQueryEngine(
retriever=vector_retriever,
response_synthesizer=response_synthesizer,
)
logger.info("creating the HyDEQueryTransform instance")
hyde = HyDEQueryTransform(include_original=True)
hyde_query_engine = TransformQueryEngine(vector_query_engine, hyde)
logger.info("retrieving the response to the query")
response = hyde_query_engine.query(
str_or_query_bundle="what are all the data sets used in the experiment and told in the paper")
print(response)
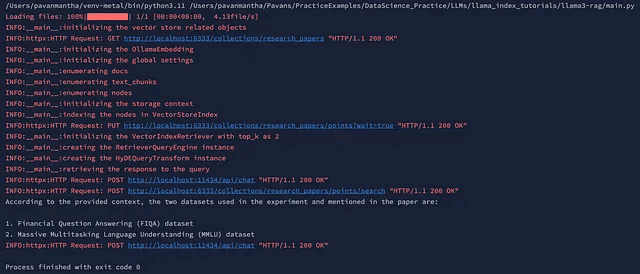
client.close()上記のコードは、INFOレベルのメッセージのためのロギングを設定し、すべてのログを出力できるようにしてから、ローカルディレクトリからPDFデータを読み込み、テキストチャンクに分割します。研究論文の埋め込みを保存するためにQdrantベクトルストアを設定し、テキストから埋め込みを生成するためのOllamaテキスト埋め込みモデルを初期化します。グローバル設定が構成され、テキストチャンクが処理され、ドキュメントIDと関連付けられます。メタデータを保持しながらチャンクからテキストノードが作成され、これらのノードのためにOllamaモデルを使用して埋め込みが生成されます。その後、スクリプトはQdrantベクトルストア内のテキスト埋め込みをインデックス化するためのストレージコンテキストを設定し、それらをインデックス化します。類似の埋め込みを取得するためにベクトルリトリーバが構成され、クエリを処理するためにクエリエンジンが初期化されます。クエリ処理を強化するためにHyDEクエリ変換が設定されます。最後に、論文の実験で言及されているデータセットに関する情報を取得するためにクエリが実行され、その応答が出力されます。
出力:
参照文献: