
LLM-Based Agentsとは何か、そして生成AIにおけるその影響度について

LLMやRAGからAIエージェントへの進歩
LLMとRAGモデルは言語生成AIの可能性を広げる代表的な技術ですが、AIエージェントの開発は、より知的で自律的で多能なシステムへの一歩として、さまざまなシナリオで人間と協力して働くモデルを提供してます。AIエージェントへの移行によって、現実世界の問題をより深く理解/学習し、現実世界の問題を解決しうるAIシステムの構築に向けた技術として注目されています。
LLMとRAGとAIエージェントの関係柄

大規模なLLMによる知識ベースと推論エンジン、さらにRAGによるローカルなデータコンテキストを利用して、さまざまな用途や目的に特化したそれぞれのエージェントがユーザの要求に対してアクションを取り、構造的な回答を提供する仕組み。
会社における各部門の持つ役割と部門間で共有される情報の管理メカニズムに非常に近いアーキテクチャを具体化したモデル。
AIエージェントが活用されたシステム例:
複雑な旅行を予約する必要があると想像してみてください:
LLM: 異なる場所を訪れるための説明や一般的な旅行のヒントを提供できます。
RAG: 目的地に関する関連するブログや記事を見つけることができます。
AIエージェント: それらすべてを行うことができます。さらに:
予算に基づいてフライトやホテルを検索する
予約を行う
すべてをカレンダーに追加する
関連情報を含めた出発前のリマインダーを送信する
AIエージェントが必要ないくつかの主要な理由
目標志向の行動: LLMsとRAGモデルは、主に彼らのトレーニングデータのパターンに基づいて人間らしいテキストを生成することに焦点を当ててるが、柔軟で知的な方法で具体的な目標を設定し追求する能力が欠けています。一方、AIエージェントは明確な目標を持ち、それらの目標を達成するために計画を立て行動を取る能力を持つように設計することができます。
メモリと状態の追跡: ほとんどの現行の言語モデルには持続的なメモリや状態追跡の能力がありません。各入力は独立して処理されます。一方、AIエージェントは内部状態を維持し、時間の経過とともに知識を蓄積し、その状態を活用して将来の意思決定や行動に影響を与えることができます。
環境との相互作用: LLMはテキスト領域でのみ動作し、物理世界との直接的な相互作用はありません。一方、AIエージェントは環境を認識し、その環境に対応する行動を取ることができます。それがデジタル世界、ロボットシステム、またはセンサーやアクチュエータを介しての物理世界であってもです。
転送と一般化: LLMsは、彼らのトレーニングデータに類似した言語タスクに優れていますが、完全に新しいドメインやタスクに知識を転送することが難しいことがよくあります。一方、学習、推論、計画の能力を持つAIエージェントは、新しい状況に対する転送と一般化の可能性があります。
継続的な学習: ほとんどの言語モデルはトレーニング後に静的に運用されます。一方、AIエージェントは新しい環境や状況との相互作用を通じて知識とスキルを継続的に学習し適応させることができます。
マルチタスク能力: LLMは通常、特定の言語タスクに特化しています。一方、AIエージェントは言語、推論、認識、制御などのさまざまなスキルを柔軟に組み合わせて複雑で多面的な問題に取り組むことができる一般的なマルチタスクシステムとして設計することができます。
AIエージェントのアーキテクチャ

AIエージェントのアーキテクチャには、それが環境内で考え、計画し、行動する力を与える必須のコンポーネントが含まれています。この洗練された設計には、通常、次のような要素が含まれます:
推論エンジン:
エージェントの中心部であり、強力な大規模言語モデル(LLM)を利用して自然言語を理解し、知識にアクセスし、複雑な問題を推論する。
知識ベース:
エージェントのメモリストアとして機能し、そのタスクに関連する事実情報、過去の経験、および好みを保持する。
ツールの統合:
APIを介してさまざまなソフトウェアアプリケーションやサービスとやり取りすることを可能にし、環境を操作および制御する能力を拡張する。
感覚入力:
テキスト、画像、またはさまざまなセンサーからデータを収集し、エージェントにその周囲を認識する能力を提供する。
ユーザーインターフェース:
人間のユーザーとのシームレスなコミュニケーションと協力を可能にする橋。( 標準のUXがあるかどうかはよくわかりませんが、おそらく近いうちに必要になると思いますが、まだ標準ではないかもしれません)
これらの要素が組み合わさって、自律的に問題を解決できる知的システムが作成されます。AIエージェントは問題を分析し、段階的な計画を立案し、自信を持って実行することができる点が人工知能の世界での変革的な力として評価されています。
AgentとRAGベースのAIシステムとの違いを例を通して説明
RAGとエージェントの違いを示す例を挙げます。入力は「ヨーロッパに旅行したい」とします。
RAGはヨーロッパ旅行に関する最新かつ信頼性のある情報を取得し、それに基づいて関連する旅行のスケジュール情報を生成します。一方、エージェントはさまざまなツールを使用し、LLMとやり取りしてタスクを完了します。これらのタスクには、ガイドの作成、チケットの予約、旅程の計画などが含まれます。
この例から、次のことがわかります:
LLMとRAGの両方が主にコンテンツに焦点を当てています。RAGは外部の知識源にアクセスし、知識レベルで操作することでLLMの能力を向上させます。
エージェントはタスクの完了に焦点を当てています。タスクを計画し、分解し、反復処理を行うことで、コンテンツを生成するだけでなく、ツールを使用して目標を達成します。これにより、エージェントはエンドツーエンドのユーザーエクスペリエンスを提供できます。

複数のエージェントの協力とコミュニケーション
エージェントの数が増えると、エージェント間の協力とコミュニケーションの難しさも増します。これは有望な研究方向を示しています。
数百、あるいは数千のエージェントから成る社会で安定した運用とタスクの実行が可能なエージェントは、将来の現実世界で重要な役割を果たす可能性が高いでしょう。
エージェントの商業的実装に関して
LLMベースのエージェントはLLM自体よりも複雑であるため、中小企業や個人がそれらをローカルで構築することは困難です。したがって、クラウドベンダーは知的エージェントをサービスとして提供することを検討する必要があります。これは Agent-as-a-Service(AaaS)とも呼ばれます。
さらに、LLMベースのエージェントが実際に実装可能かどうかは、現実世界に損害を与えないように厳格なセキュリティ評価が必要です。
LLMベースのエージェントの制限
LLMベースのエージェントは完璧ではなく、以下の欠点があります:
LLMベースのエージェントは、LLMの生成能力に大きく依存しているため、エージェントの品質もLLMが適切に最適化されているかどうかに依存します。開発プロセスで、オープンソースの小規模なLLM(3B、7B)はプロンプトを効果的に理解するのに苦労することがわかりました。したがって、競争力のあるエージェントを実装するには、GPT-4などの性能の高いLLMが推奨されます。
LLMのコンテキストウィンドウの長さは通常制限されており、エージェントがより複雑な問題を解決する能力を制限しています。
現在、エージェントが独自に探索して解決プロセス全体を完了することはかなり負担がかかり、時間がかかります。これは問題を複雑にする可能性があります。この領域での大幅な最適化が必要です。
AIエージェントの歴史
1980年代半ば以降、人工知能分野におけるエージェントに関する研究は大幅に増加しています。これに基づいて、ウールドリッジらは人工知能を、コンピュータ科学の一分野と定義し、知的な振る舞いを示すコンピュータ化されたエージェントを設計・構築することを目指しています。
基本的に、AIエージェントは哲学的なエージェントと同等ではありません。代わりに、それはAI環境内で哲学的エージェントの概念を具体化したものです。
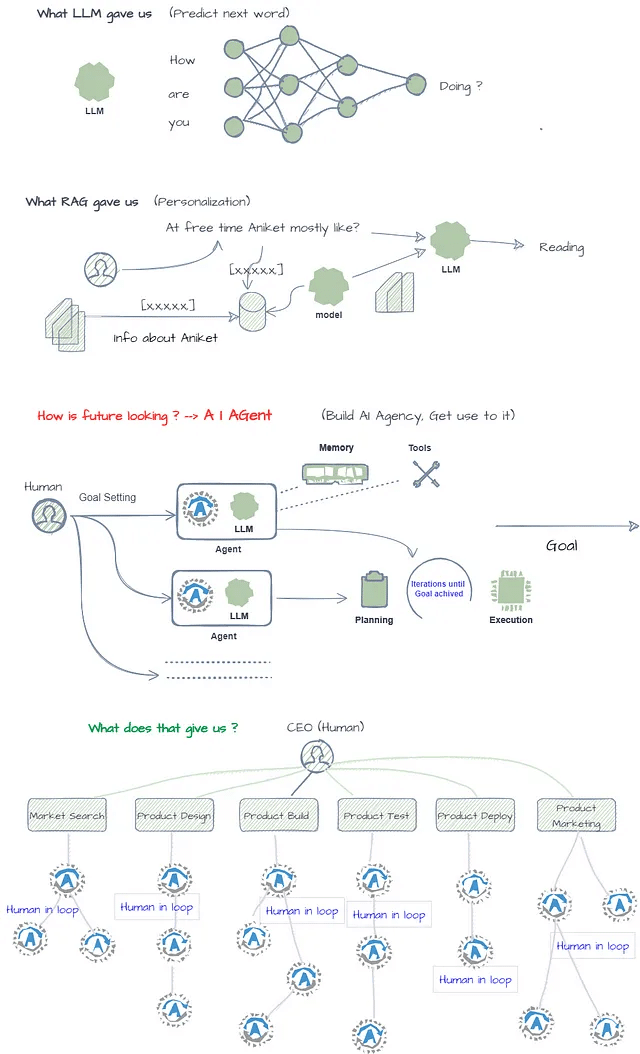
図1に示されているように、AIエージェントは、環境をセンサーを通じて知覚し、意思決定を行い、それに応じて反応する人工的な存在です。

AIエージェントの段階的な発展
AIエージェント研究の技術進化の歴史は、主に以下の段階を含んでいます。
Symbolic Agent(記号的エージェント)
人工知能研究の初期段階では、主に記号人工知能が使用されており、論理ルールと象徴的表現を使用して知識を包括し、推論プロセスを容易にする方法が主要でした。記号的エージェントのアーキテクチャは次の図に示されています。
このアプローチの典型的な例は、知識ベースの専門家システムです。このシステムは、主に知識ベース、推論エンジン、およびインタプリタで構成されています。
ただし、象徴的なエージェントは、不確実性や大規模な現実世界の問題を管理する際に課題に直面することがあります。さらに、象徴的な推論アルゴリズムの複雑さにより、限られた時間内で意味のある結果を得る効率的なアルゴリズムを見つけることが難しいです。
Reactive Agent (反応型エージェント)
象徴的なエージェントとは異なり、反応型エージェントは複雑な象徴的な推論を使用しません。彼らは主にエージェントと環境の相互作用に集中し、迅速でリアルタイムな応答を優先します。
このようなエージェントの設計では、複雑な推論や象徴的な操作よりも入出力マッピングを優先します。そのため、彼らは洗練された意思決定や計画能力を欠くことがあります。これは、反応型エージェントが通常、事前に定義されたルールセットを使用して行動をガイドするためです。次の図で示されています。

このアプローチの典型的な例は、掃除ロボットです。彼らはセンサーを使用して床のほこりや障害物を検出し、それから清掃経路を選択し、障害物を避けます。これらのエージェントは、長期的な計画の必要なしに、現在の状況に基づいて単純に意思決定を行います。
強化学習ベースのエージェント (Reinforcement learning-based agents)
この分野の主な焦点は、環境との相互作用を通じて学習し、特定のタスクで最大の累積報酬を達成するためのエージェントをどのように可能にするかです。
深層学習の台頭により、深層ニューラルネットワークと強化学習が統合されるようになりました。これにより、エージェントは高次元の入力から複雑な戦略を学習し、次の図のようにAlphaGoなどの多くの重要な成果を生み出すことができます。

出典:AlphaGoからの教訓。
ただし、強化学習には長いトレーニング時間、効率の悪いサンプリング、安定性の問題など、特に複雑な現実世界の環境で実装された場合にさまざまな課題が生じます。
転移学習とメタ学習を備えたエージェント (Agents with transfer learning and meta learning)
転移学習は新しいタスクのトレーニング負荷を軽減し、さまざまなタスク間での知識の交換と転送を促進します。さらに、メタ学習はエージェントが限られた数のサンプルから新しいタスクの最適な戦略を迅速に決定することを重視して学習方法を強調します。
ただし、ソースタスクとターゲットタスクの間に著しい不一致がある場合、転移学習の効果は期待を下回り、負の転送につながる可能性があります。さらに、メタ学習には広範な事前トレーニングと大規模なサンプルサイズが必要であり、普遍的な学習戦略の確立を複雑化します。
LLMベースのエージェント
近年、大規模言語モデル(LLM)は著しい成功を収め、人間のような知能に到達する可能性を示しています。これは、主に広範なトレーニングデータセットと多数のモデルパラメータの使用によるものです。その結果、新たな研究分野が登場し、LLMをエージェントの中核コントローラーとして使用して人間レベルの意思決定能力を実現することが可能となりました。
これが記事の主要なポイントであり、次のセクションで詳細に説明します。
LLMベースエージェントのアーキテクチャ
LLMベースのエージェントのアーキテクチャは形式によって異なります。しかし、共通性の観点から、コアモジュールにはメモリ、計画、アクションが含まれています。
例えば、Wang et al.は、 次の図に示されている統合フレームワークを提案しています。このフレームワークにはプロファイリングモジュール、メモリモジュール、計画モジュール、アクションモジュールが含まれています。

出典:Wang et al.。
プロファイリングモジュールはエージェントの役割を特定します。メモリと計画モジュールはエージェントを動的環境に配置し、過去の行動を思い出したり将来の行動を計画したりすることができます。アクションモジュールはエージェントの意思決定を特定の出力に変換します。これらの中で、プロファイリングモジュールはメモリと計画モジュールに影響を与え、これら3つのモジュールがアクションモジュールに影響を与えます。
さらに、Xi et al.は、次の図に示すように、脳、知覚、アクションから構成されるLLMベースのエージェントの一般的な概念フレームワークを提案しています。

出典:Xi et al.。
脳モジュールはコントローラーとして機能し、記憶、思考、意思決定などの基本的なタスクを処理します。
知覚モジュールは外部環境からの多様な情報を解釈し処理します。
行動モジュールはツールを使用して応答を実行し、環境とやり取りします。
論文では、ワークフローを説明する例が挙げられています。たとえば、誰かが雨が降るかどうか尋ねたとします。知覚モジュールはこのクエリをLLMが理解できる形式に変換します。その後、脳モジュールは現在の天気とオンラインの天気予報に基づいて推論を行います。最後に、行動モジュールが応答し、その人に傘を渡します。このプロセスを通じて、エージェントは一貫してフィードバックを受け取り、環境とやり取りすることができます。
LLMベースエージェントのアプリケーション例
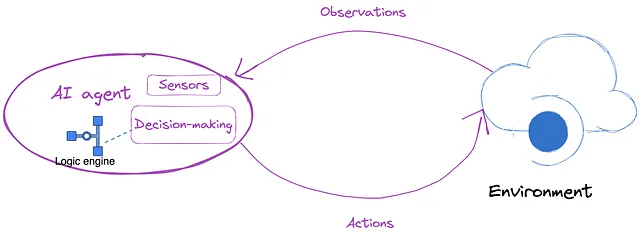
異なる応用分野に基づいて、LLMベースのエージェントの応用は、次の図に示されているように、社会科学、自然科学、および工学の3つのカテゴリに分けることができます。
出典: Wang et al. .
さらに、応用シナリオによれば、LLMベースのエージェントの応用は、次の図に示されているように、単一エージェント、複数エージェント、および人間とコンピュータの相互作用に分けることができます。

出典:Xi et al.。
単一のエージェントは多様な能力を持ち、さまざまなアプリケーションの方向で優れたタスク解決能力を示すことができます。複数のエージェントが相互作用すると、協力的または敵対的な相互作用を通じて進歩を遂げることができます。さらに、人間とエージェントの相互作用では、人間のフィードバックによってエージェントがタスクを効率的かつ安全に実行することができる一方、エージェントも人間により良いサービスを提供することができます。
LLMベースエージェントの実装(LangChain)
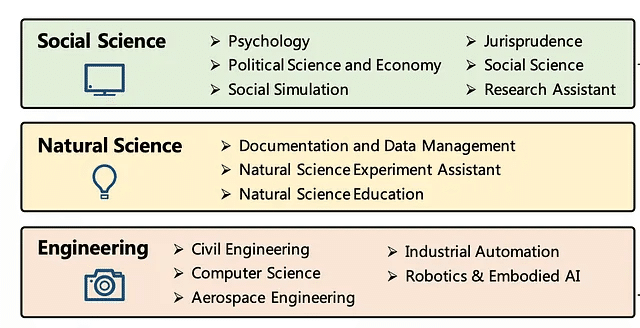
Langchainを使用してエージェントを実装します。アーキテクチャは次の図に示されています。
環境構築
Conda環境を作成し、対応するPythonライブラリをインストールします。
(base) Florian:~ Florian$ conda create -n agent python=3.11
(base) Florian:~ Florian$ conda activate agent
(agent) Florian:~ Florian$ pip install langchain
(agent) Florian:~ Florian$ pip install langchain_openai
(agent) Florian:~ Florian$ pip install duckduckgo-searchインストール後、対応するバージョンは以下の通りです:
(agent) Florian:~ Florian$ pip list | grep langchain
langchain 0.1.15
langchain-community 0.0.32
langchain-core 0.1.41
langchain-openai 0.1.2
langchain-text-splitters 0.0.1
(agent) Florian:~ Florian$ pip list | grep duck
duckduckgo_search 5.3.0ライブラリのインポート
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from langchain.agents import AgentExecutor, Tool, ZeroShotAgent
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import OpenAI
from langchain_community.utilities import DuckDuckGoSearchAPIWrapperツール
ここでは、ツールとしてDuckDuckGo検索エンジンを使用しています。もちろん、他のツールも使用できます。
search = DuckDuckGoSearchAPIWrapper()
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events",
)
]計画と行動
これがエージェントの中核です。この場合、ReActアルゴリズムを採用しています。その目的は、LLMの利用を探索し、推論トレースと特定のタスクアクションを交互に生成することです。これは以前に議論された反応型エージェントではなく、LLMで推論と行動を相乗させることができる方法であることに注意してください。

(1) 4つのプロンプト方法の比較、(a) 標準、(b) 考えの連鎖(CoT、理由のみ)、(c) 行為のみ、および(d) ReAct(理由+行為)、HotpotQAの質問を解決する。 (2) (a) 行為のみと(b) ReActプロンプトの比較、AlfWorldゲームを解決する。両方のドメインで、プロンプトでコンテキスト内の例を省略し、モデルによって生成されたタスク解決の軌跡(行為、考え)と環境(観察)のみを表示します。
出典:ReAct。
上の図に示すように、ReActの原則は、単に行動を行うだけでなく、その意思決定や推論プロセスを説明することを含んでいます。これにより、タスクが完了しただけでなく、なぜ特定の方法で行われたのかも理解できます。問題が発生した場合、原因を特定することがより簡単になります。
他のプロンプト方法の問題は、透明性の欠如です。エージェントが質問を解決した方法やプロセス中にどんな課題に直面したかを知ることができません。
以下は当社のエージェントの計画コードです。
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"],
)よく構築されたプロンプトは次のようになります。
Have a conversation with a human, answering the following questions as best you can.
You have access to the following tools:
Search: useful for when you need to answer questions about current events
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [Search]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}最初に、プロンプトは私たちが定義した[search]ツールを使用し、プロンプトの最後に3つの変数があります:
chat\_history は記憶に保存されている内容を含んでいます。
input はユーザーが入力した質問を指します。
agent\_scratchpad は以前の思考プロセスを表し、思考、行動、行動の入力、観察などを包括しています。この変数はエージェントの実行プロセス中に更新されます。
メモリ
memory = ConversationBufferMemory(memory_key="chat_history")エージェントの構築
LangChain APIを使用してエージェントを作成します。
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent, tools=tools, verbose=True, memory=memory
)テスト
agent_executor.run(input="How many people live in canada?")
# To test the memory of this agent, we can ask a followup question that
# relies on information in the previous exchange to be answered correctly.
agent_executor.run(input="what is their national anthem called?")
agent_executor.run(input="what is their capital?")全体的なコード
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from langchain.agents import AgentExecutor, Tool, ZeroShotAgent
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import OpenAI
from langchain_community.utilities import DuckDuckGoSearchAPIWrapper
search = DuckDuckGoSearchAPIWrapper()
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events",
)
]
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent, tools=tools, verbose=True, memory=memory
)
agent_executor.run(input="How many people live in canada?")
# To test the memory of this agent, we can ask a followup question that relies on information in the previous exchange to be answered correctly.
agent_executor.run(input="what is their national anthem called?")
agent_executor.run(input="what is their capital?")実施した結果は次の通りで、考え、計画、行動の過程が見えます。
> Entering new AgentExecutor chain...
Thought: I should use the Search tool to find the most recent population data for Canada.
Action: Search
Action Input: "Population of Canada"
Observation: Canada population density map (2014) Top left: The Quebec City-Windsor Corridor is the most densely inhabited and heavily industrialized region accounting for nearly 50 percent of the total population Canada ranks 37th by population among countries of the world, comprising about 0.5% of the world's total, with 40 million Canadians. Despite being the second-largest country by total area ... As of July 1, 2023, NPRs were estimated to represent 5.5% of the population of Canada. Among provinces, this proportion was highest in British Columbia (7.3%) and Ontario (6.3%) and lowest in Newfoundland and Labrador (2.4%) and Saskatchewan (2.5%). The 2.2 million NPRs now outnumber the 1.8 million Indigenous people enumerated during the 2021 ... Historical population of Canada. Statistics Canada conducts a country-wide census that collects demographic data every five years on the first and sixth year of each decade. The 2021 Canadian census enumerated a total population of 36,991,981, an increase of around 5.2 percent over the 2016 figure. It is estimated that Canada's population surpassed 40 million in 2023 and 41 million in 2024. Canada's population reaches 40 million. On June 16, 2023, Statistics Canada announced that Canada's population passed the 40 million mark according to the Canada's population clock (real-time model). Today's release of total demographic estimates and related data tables for a reference date of July 1, 2023, is the first since reaching that ... Canada's population was estimated at 40,528,396 on October 1, 2023, an increase of 430,635 people (+1.1%) from July 1. This was the highest population growth rate in any quarter since the second quarter of 1957 (+1.2%), when Canada's population grew by 198,000 people. At the time, Canada's population was 16.7 million people, and this rapid population growth resulted from the high number of ...
Thought: Based on the data, I can see that the population of Canada is estimated to be around 40 million as of October 1, 2023.
Final Answer: The estimated population of Canada as of October 1, 2023 is 40 million.
> Finished chain.
> Entering new AgentExecutor chain...
Thought: I should use the search tool to find the answer.
Action: Search
Action Input: "Canada national anthem"
Observation: O Canada, national anthem of Canada.It was proclaimed the official national anthem on July 1, 1980. "God Save the Queen" remains the royal anthem of Canada. The music, written by Calixa Lavallée (1842-91), a concert pianist and native of Verchères, Quebec, was commissioned in 1880 on the occasion of a visit to Quebec by John Douglas Sutherland Campbell, marquess of Lorne (later 9th ... Learn about the history and lyrics of Canada's national anthem 'O Canada', which has both French and English versions. The song was composed by Calixa Lavallée in 1880 and was proclaimed the official anthem in 1980. It replaced 'God Save the Queen', which is Canada's royal anthem. O Canada (French: Ô Canada) is the national anthem of Canada. The song was originally commissioned by Lieutenant Governor of Quebec Théodore Robitaille for t... National Anthem of Canada - O Canada (English only) - featuring new lyricsOther versions:Bilingual: https://www.youtube.com/watch?v=wBCuyeoSURoFrench only: h... Enjoy this virtual choir rendition of 'O Canada' arranged by George Alfred Grant-Shaefer . Make sure to subscribe for more virtual choir videos!After 100 yea...
Thought: I now know the final answer.
Final Answer: The national anthem of Canada is "O Canada".
> Finished chain.
> Entering new AgentExecutor chain...
Thought: I should use the Search tool to find the answer.
Action: Search
Action Input: "Capital of Canada"
Observation: Ottawa is the capital city of Canada.It is located in the southern portion of the province of Ontario, at the confluence of the Ottawa River and the Rideau River.Ottawa borders Gatineau, Quebec, and forms the core of the Ottawa-Gatineau census metropolitan area (CMA) and the National Capital Region (NCR). As of 2021, Ottawa had a city population of 1,017,449 and a metropolitan population of ... Ottawa, city, capital of Canada, located in southeastern Ontario.In the eastern extreme of the province, Ottawa is situated on the south bank of the Ottawa River across from Gatineau, Quebec, at the confluence of the Ottawa (Outaouais), Gatineau, and Rideau rivers.The Ottawa River (some 790 miles [1,270 km] long), the principal tributary of the St. Lawrence River, was a key factor in the city ... Skyline of Toronto. The national capital is Ottawa, Canada's fourth largest city. It lies some 250 miles (400 km) northeast of Toronto and 125 miles (200 km) west of Montreal, respectively Canada's first and second cities in terms of population and economic, cultural, and educational importance. The third largest city is Vancouver, a centre ... Learn about Canada's location, climate, terrain, natural resources, and major lakes and rivers. Find out the population distribution, ethnic groups, languages, and religions of Canada. The national capital, Ottawa, is prominently marked in the province of Ontario. Where is Canada? Canada is the largest country in North America. Canada is bordered by non-contiguous US state of Alaska in the northwest and by 12 other US states in the south. The border of Canada with the US is the longest bi-national land border in the world.
Thought: I now know the final answer.
Final Answer: The capital of Canada is Ottawa.
> Finished chain.Agentic AI についての解説
マルチエージェントAIワークフローとAGIの可能性
エージェンティックAIは、自律的な人工知能の進化の次の段階として広く考えられています。これにより、LLM(Large Language Models)がより広範な意思決定を行い、変化する要件に適応できることが期待されています。
AI FundのAndrew Ng氏は最近、Sequoia CapitalのAI AscentでエージェンティックAIワークフローとその潜在性についてプレゼンテーションを行いました。そのプレゼンテーションのビデオは以下にあります。私はそのワークフローを要約し、このアプローチの有用性と制限についての考えを述べます。
Andrewはプレゼンテーションで各ワークフローデザインパターンについての推奨される読書を含めました。私はそれらの論文へのリンクを以下に提供し
ます(すべてarXiv上にあります)。
アンドリュー・エングによるエージェンティックAIワークフローに関するプレゼンテーション(13分)
非主体的 vs 主体的LLMワークフロー
単一エージェントLLM、または非主体的(ゼロショットとも呼ばれる)は、応答を行う際に一度にトークンを一つずつ順番に生成します。アンドリューは、これを途中で修正せずに最初から最後までエッセイを書くことに例えています。現在のGPTモデルでは、単一のプロンプトを与えて応答を得るとこのような挙動が得られます。
エッセイの例に続いて、主体的(またはマルチエージェント)ワークフローは計画的で反復的なプロセスです。トピックの概要から始めて、リサーチを行い、下書きを書き、その後下書きを修正するという流れです。これは、エッセイを書く際に人間が行う方法に似ており、アウトラインを立てずに一度に全てを書いたり修正せずに済ませるのではなく、段階的に進める方法です。
主体的ワークフローデザインパターン
アンドリューのプレゼンテーションでカバーされている基本的なデザインパターンは4つあります。最初の2つ、反射とツール使用は、よく開発され信頼性があります。他の2つ、計画とマルチエージェントの協力は、成熟度が低く信頼性が低いとされています。
反射
ゼロショットLLMでは、初期の応答を取得し、モデルにそれを改善するように求めることが一般的です。これは反復的なアプローチであり、何か複雑なものを作ろうとする際にはほぼ必ず必要とされます。
これは、モデルに簡単なプログラムを書くように求め、その後コードで生じるであろうエラーを修正するように再プロンプトするプロセスに似ています。最終的には、LLMにコードを速度向上のために改善したり、スタイルや命名規則に合わせてフォーマットするように求めるかもしれません。
ゼロショットLLMでは、ユーザーが改善すべき領域を特定し、その後モデルに出力を改善するように促すことが求められます。主体的アプローチは、自己プロンプトを使用し、改善を自動化するためのフィードバックループを作成しようとします。
反射は、フィードバックループを通じた応答の反復的な改善です。
ツールの使用
LLM(Large Language Models)がウェブ検索、コードインタプリタ、コンパイラなどの外部ツールを使用することは一般的です。また、画像生成、画像キャプション、物体検出、テキスト読み上げなどの他のAIモデルも使用することがあります。
プログラムの作成時にツールを使用するエージェントベースのアプローチでは、インタプリタやコンパイラの出力を使用してコードのエラーを発見し、それを修正するために自己(反射)を促します。コードの最適化時にはプロファイラを使用することもあります。ユニットテストも外部ツールと見なすことができます。
ツールの使用は、改善が必要な領域を特定するために外部ツールを呼び出すこと、またはデータを予測可能な方法で変換することです。
プランニング
マルチエージェントのプランニングは、問題を複数のステップに分解することを含みます。これは、最終的な答えに向けて反復する複数の具体的なプロンプトを実行するか、特定のタスクに特化した複数のAIモデルの使用を計画することで行われます。
HuggingGPT paperの例として、リクエストの処理が挙げられます: “Please generate an image where a girl is reading a book, and her pose is the same as the boy in the image example.jpg, then please describe the new image with your voice.”
この例では、4つの異なるモデルが使用されます。まず、例の画像のポーズを決定するモデルが使用されます。その出力は、ポーズから画像を生成するモデルに与えられます。その画像は画像からテキストへのモデルに与えられ、画像にキャプションを付けるために使用されます。最後に、そのキャプションはテキストから音声へのモデルに与えられ、聞くことができる結果が生成されます。
プランニングは、各ステップの出力を次のステップに与えてさらに改善するためにタスクを複数のステップに分割することです。
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
マルチエージェントの協力
異なる特化とバイアスを持つ複数のエージェントを使用して、それぞれの出力を洗練させることがマルチエージェントの協力です。これの例としては、「批評エージェント」を反射デザインパターンの一部として使用することが挙げられます。批評エージェントは改善が必要な領域を見つけるように促され、その応答は主要なモデルに反復的なフィードバックを提供するために使用されます。
複数のChatGPTインスタンスを別々のブラウザタブで開き、それぞれに初期プロンプトを与えて特定の目標やバイアスを持つエージェントとして機能させ、それぞれの出力をコピー/ペーストして協力して出力を洗練させるというテクニックがあると聞いたことがあります。これはマルチエージェントの協力を手動で行う方法です。
Andrewは、ChatDevを参照しており、これは選択したLLMを使用して特化したエージェントを構成するためのオープンソースツールです。古典的なRPGの俯瞰ビューを模倣したかわいらしいドット絵のグラフィックがあります。ゲームモードでは、ソフトウェアを制作するために協力するNPCエージェントがいる町の社会環境をシミュレートしています。これは楽しい遊びになるかもしれません。
マルチエージェントの協力は、特化したエージェントを使用してお互いにプロンプトし、その出力を反復的に洗練することを含みます。
AIエージェント技術を代表するR&Dの紹介:Introducing the AI Camp: Agents Cohort | by John Borthwick | Apr, 2024 | Betaworks
2023年12月、私たちはBetaworksでの第10回キャンププログラムのテーマを発表しました:エージェント。このテーマの選択は、エージェントがAIエコシステムの重要な部分であり、ネイティブAIソフトウェアの包括的な用語になる可能性があるという私たちの信念に基づいています。この領域では多くの革新が起こっており、アプリケーション層やミドルウェアで行われています。
250以上の企業の中から、エージェントとエージェントAIについて独自の洞察を持ち、巨大な問題を解決するために異なるアプローチを取っている9つのチームを選びました。私たちが編成した イベントは、インフラストラクチャ/ツールとアプリケーション層の製品がミックスされた独特のもので、創業者はアメリカ、ヨーロッパ、カナダからいます。製品の一部は特に開発者向けに作られていますが、他の製品は企業向け、またはプロシューマー(専門家)向けです。

彼らの製品構築、GTM、およびローンチの準備を手伝うだけでなく、デザインパートナーや顧客、投資家ともに、Campは13週間、これらのチームと密接に協力してテクノロジーに関する私たちのテーゼをさらに発展させる機会です。
Betaworksでは、新興テクノロジーについて考えるための一般的なフレームワークを使用しており、それは次のような開発パターンに従う傾向があります。
第1波:既存のワークフローの複製
第2波:拡張
第3波:本当にネイティブなエクスペリエンス
今回のCamp イベントでの経験から、エージェントがAI開発の第3波を表していることが確認されました。そのため、私たちは「エージェント」がネイティブAIソフトウェアの包括的な用語になると考えています。エージェントはAIネイティブソフトウェアを表すだけでなく、将来的にはソフトウェアの大部分を占める可能性があります。言い換えれば、私たちはエージェントがソフトウェアを飲み込んでしまうと考えています。
私たちの言葉を信じる必要はありません。ぜひご自身で確認してください:Campは5月7日火曜日にNYCのBetaworksでデモデーを迎えます。これは各製品の背後にあるストーリーを聞く機会であり、ライブデモで製品を実際に見る機会です。
各チームについて詳しくは以下をご覧ください。また、Betaworksでのデモデーへの参加に興味がある場合はこちらからお知らせください。
Twin Labs
AIに繰り返しのタスクをシームレスに委任し、任意のツールを自律的に制御するようにトレーニングされたAIに委任します。
Twin Labsは、知識労働者が繰り返しのタスクをスマートなインターンに委任するのと同じくらい簡単にAIに割り当てるためのアプリやモデルを構築しています。ユーザーは「フロー」と呼ばれる、実行または自動化するタスクの自然言語の説明を作成します。Twinのカスタムアクションモデルは、それらを適切なアクションのシーケンスに変換します。最後に、これらのアクションは、任意のアプリケーション内で制御およびナビゲートできるヘッドレスブラウザを介して自律的に実行されます。Twinは、成長に追いつくのに苦労している中小企業(HR、営業、財務、運用、バックオフィス)をターゲットにし、繰り返しの作業を自動化しようとしています。彼らのビジネスモデルは使用量に基づいています。
Hugo Mercier(CEO)は以前、Dreemの創業者兼CEOでした(6000万ドル調達、150人の従業員、売却)。Joao Justi(CTO)は、Videosupportの共同創業者であり(2023年4月に買収)、MLエンジンとコア製品エンジニアリングの両方を率いていました。

Jsonify
Webページやドキュメントを自動的に有用な構造化データに変換する
Jsonifyは、スマートなAIエージェントを搭載し、ウェブサイトやドキュメントからデータを発見、監視、抽出することができます。高度なコンピュータビジョンモデルを使用してページを見て、人間と同じように構造を理解します。つまり、乱雑なウェブサイトやドキュメントを人間の介入なしに、数秒で理にかなった構造化されたJSONやCSVデータに変換できます。Jsonifyの顧客は、AIスタック/APIの上に構築したいテックスタートアップや、データのニーズがありデータパイプラインを自分で維持または構築したくない非技術系のビジネスです。製品には、実行タスクの数に基づく階層型の価格設定モデル(フリーミアムレベルを含む)があります。
創業者のPaul Hunkinは、2022年以来生成的AIエージェントに取り組んでおり、15年以上のソフトウェア開発の経験があり、3回の共同創業者/CTO(Quacks.ai、Apellix、ButlerTech)を務め、Google、NASA、Sonyとも協力しています。

Resolvd AI
Resolvdは、AIパワードエージェントを使用して、エンジニアリングチームが反復的なクラウドワークフローを自動化し、革新と高い影響を持つ作業に集中できるように支援します。
エンジニアリングチームは、マイクロサービスベースのクラウドインフラの維持にますます負担を感じ、コア製品開発と革新から注意が逸れています。Resolvdのデスクトップアプリケーションを使用すると、ユーザーは画面録画を介してクラウド関連のワークフローを簡単にキャプチャし、ステップバイステップのドキュメントを自動生成し、強力なCLI /ブラウザエンジンを介してそのワークフローを自動化できます。 Resolvdは、(a)時間のかかるクラウド関連のタスクをオフロードしたいエンジニアリングおよび製品チーム、(b)ワークフローを効率的に管理する必要があるエンジニア、および(c)ボトルネックと依存関係を減らしたいインフラストラクチャおよびITチームをターゲットとしています。 Resolvdは、フリーミアム(無償版)、シートベースのSaaSモデルで運営しています。個々のエンジニアは無料でクラウドワークフローを構築および自動化できますが、企業はその後、コラボレーション、カスタム統合、およびセキュアVPC展開などの高度な機能にアクセスするためにアップグレードできます。
創業者のAnanth Manivannanは、CapitalOneでバックエンドソフトウェアエンジニアとして3年間を過ごし、会社がモノリシックなオンプレミスサーバーから100%のマイクロサービス、クラウドベースのアーキテクチャに移行するという変革期を経験しました。これによりエンジニアリングチームの働き方が変わり、彼はこれらの新しいクラウド/インフラ関連のワークフローを支援するための自動化ツールを開発し始めました。

Floode
Floodeは、ルーチンのコミュニケーション管理を自動化する個人向けAIエグゼクティブアシスタントです。
私たちは、15分ごとにメールの受信トレイをスクロールして、99%の関係のないデータの中から重要な情報の1%を特定するために時間を無駄にしています。この問題に対処するために、Floodeは陳腐化した受信トレイを、各ユーザーのニーズに合わせた高度に個人化されたAIエグゼクティブアシスタントで置き換えます。ユーザーとのシームレスな連携を通じて、Floode AIアシスタントは情報を処理する前に、各受信メールの次のステップを決定することができます。Floodeは現在、Webアプリとして利用可能であり、年末までにモバイル版がリリースされる予定です。
Floode AIエグゼクティブアシスタントは、月額30ドルまたは年間300ドルから利用可能です。ターゲット顧客は、特にスタートアップのCEOで、数百通のメールをやりくりするために貴重な時間を失っているテック業界のエグゼクティブです。長期的には、Floodeはプロフェッショナルな目的でオンラインでコミュニケーションを取っている人々にAIエグゼクティブアシスタントを提供することを目指しています。
Sarah Allali(CEO)は、以前はAirbnbで活動し、認知科学とヒューマンコンピュータインタラクションのバックグラウンドを持っています。Nicolas Cabrignac(CTO)は、AI/MLとヒューマンコンピュータインタラクションに特化しています。2019年には、彼らはマネージャー向けの最初のGPT-3搭載AIアシスタントの1つであるMooneを共同設立しました。

Extensible AI
本番環境への展開前後において、エージェントの回帰を捉えます。
LLM、エージェントのロジック、エージェントが運用される環境はすべて変化の対象となります。これほど多くの変数が変動する中で、本番環境やステージングにおけるエージェントの信頼性を確実に測定することは難しい場合があります。企業は、展開されたエージェントが回帰しているか、あるいはパフォーマンスの期待値を満たしているかについて暗中模索しています。現在、エージェントは手動でテストされており、これによりカバレッジに大きな穴が開き、未テストの場合やテスト済みのシナリオが本番環境で狂ってしまった場合には、恥ずかしい状況や信頼を損なう状況につながることがあります。Extensibleは、商用利用可能なエージェント向けのロギングツール(完全に無料でオープンソース)およびそれに付随するプラグアンドプレイの信頼性ツールを開発しています。
Extensibleは、企業がカスタムな大規模なロギングインフラを低コストで構築できるようにする、高品質で本番環境で利用可能な完全オープンソースのツールを提供しています。彼らのターゲット顧客は、エージェントを本番環境に展開するAIエージェント企業です。
共同創業者のParthとOmkaarは、製品、機械学習、分散システムの独自のバックグラウンドを持っており、応用機械学習エージェントの領域においてそれを活かしています。Parth Sareen(CEO)は、UWaterlooでメカトロニクス工学を修了しています。以前の役職には、Autodeskの分散システムエンジニア、Apple、Tesla、Deloitteでのインターンが含まれています。Omkaar Kamath(CTO)は、Waterloo大学でマネジメントエンジニアリングを学んでいます。彼はAutodeskでのインターン中に初期バージョンの「エージェント」を構築しました(2021年、LLMエージェントが存在する以前のことです)、そしてそのコストの一部で競合他社の調査を定期的に行うためのものです。以前のインターン先には、Majik SystemsとCartaが含まれています。

Skej
あなたの新しいAIスケジュールアシスタント
毎年10億以上の会議をスケジュールすることは、生産性を損ない、自動化が難しいと広く知られている手間のかかる時間を要する作業です。そこで登場するのがSkejです。Skejは、すべてのスケジュールのやりとりやカレンダーの予約をシームレスに処理するダイナミックなAIエージェントです。
Skejを電子メール、DM、またはSlack/Teamsの会話にコピーして、スケジュール全体のプロセスを引き継ぐのを見てください。Skejは優れたエグゼクティブアシスタントの行動をシミュレートし、既存のどんなカレンダーツールにも対応しています。Skejには無料のティアと、ユーザーがプレミアム機能と高度なスケジュールツールを利用できる有料サブスクリプションがあります。
創業者(兄弟)のPaulとJustin Canettiは、MAZ Systems(PSG Equityによって取得されたノーコードアプリ開発プラットフォーム)やBounce House(Declare Healthに取得されたスケジュールプラットフォーム)を含む複数の企業を立ち上げ、拡大してきました。


Opponent
子供との深い遊びが可能な対立的なエージェント
子供の健全な成長には注意が欠かせません。親は子供が質の高い注意を受けるように時間とお金を費やします — 学校、アクティビティ、遊びの約束 — しかし、その間の周囲の時間はどうでしょうか?今日の親たちは分散し、ますますオンデマンドのデジタルメディアに頼るようになっています。Opponent Systemsは、家族生活を補完する新しい種類の注意を払うエージェントを開発しています。最初の製品は、家族の一員のようにFacetime/ビデオ通話できるデジタルドラゴンです。これには、記憶を認知マップに進化させる新しいアーキテクチャ(でっち上げたゲームから常識まで)、そしてそれらのマップを手元の遊びに適用するためのSystem 2に着想を得た能力が組み込まれています。ターゲット顧客は分かれた親、一人っ子、分散した家族です。
創業者Ian Chengは以前、MoMA、Whitney、MOCA、Serpentine、M Plus、Tate、Leeum、De Young、Venice Biennaleで発表された多エージェントシミュレーションを制作したアーティストとして活動していました。UCバークレー校で認知科学の学士号を取得しています。

High Dimensional Research (HDR)
開発者が理解し、開発し、エージェントアプリケーションやオンライン対応エージェントを展開するためのフルスタックフレームワーク。
エージェントアプリケーションの構築は難しく、最先端の状態でも信頼性に欠けることがあります。HDRは、Webエージェントを展開するための包括的なフレームワークを開発しました。このフレームワークの中心には、Collective Memory Indexがあり、これによりモデル間で情報を伝達し、どんなLLMでも信頼性のあるタスクを実行できるようになります。HDRは使用ごとにクレジットを販売しています。彼らのターゲット顧客は、あらゆるチーム規模や技術能力レベルのAI開発者であり、企業向けの追加ユーティリティも提供しています。
Tynan (Ty) Daly(CTO)は、様々な産業でのMLにおいて、標準的な、異国風の、そして独自のトランスフォーマーアーキテクチャのトレーニングと展開にキャリアを費やしてきました。Matilde Park(CPO)は、ビデオゲームやピアツーピアアプリケーションスペースを構築するチームを率いるキャリアを積んできました。Gates Torrey(CEO)は、変革的なテクノロジーや新しい資産に焦点を当て、様々な資産クラスや段階に投資するキャリアを積んできました。

Mbodi
ロボティクスにおけるインターネットスケールの学習を可能にする
ロボティクスにおける機械学習の基本的な問題はデータの不足です。Mbodiのツールは、生成AIを用いた異なるエンボディメント間のデータセット転送学習をユニークに提供しています。現在の代替手段は、数千万ドルをテレオペレーションやハードウェアに費やすか、Nvidiaのオムニバースに対して独占的な支払いをすることです。
Mbodiのターゲット顧客は、ロボットを所有する企業や研究所です。最初のターゲットは、Metaや研究所、スタートアップ、およびサービスロボット企業などのオープンソース愛好家です。Mbodiは、Nvidiaとのエコシステムのロックインや広範なテレオペレーションの代替手段として、独自の異なるエンボディメントエンドツーエンド学習フレームワークをオープンソースで提供します。同時に、彼らはロボティクス向けのマルチモーダル生成AI機能のホスティングとサービスに対してトークンごとに料金を請求します。これには、推論時のプランニング、ドリーミング(生成されたセンサーデータでのトレーニング)、過去の忘却を観察するためのダッシュボード、高性能で低遅延の推論エンドポイントなどが含まれます。
共同創業者のSebastian Peraltaは、ロボティックス、AI研究者であり、以前はGoogleのパブリックDNSでネットワークの遅延を最小限に抑える役割を果たしていました。共同創業者のXavier (Tianhao) Chiは以前、Googleのテクニカルリードとして幅広い技術と製品の経験を持っていました。

参照データ: