
AutoGenの現時点での課題を整理

AutoGen isn’t Practical for Real-world Applications, Yet
Why AutoGen is Impractical with the Current Generation of LLMs
https://pub.aimind.so/autogen-isnt-practical-for-real-world-applications-yet-5b8c6dc97641
はじめに
顧客が使用するアプリケーションにAutoGenを使用するのを避けています。これは、いくつかのAutoGenテストバージョンを作成した後に決めたことです。AutoGenが悪いツールだと言っているわけではありません。使用するのは楽しく、研究、学習、および楽しいプロジェクトには素晴らしいツールです。しかし、現在のLLM(大規模言語モデル)とAutoGenや類似のツールを使用することについては懸念があります。
以下は、これらの問題を説明するための実験です。
プロジェクト
AutoGenを使用して複雑な質問に答えるシステムを構築しました。これらの質問は、法律、金融、研究など多くの分野で一般的です。従来の方法が常に最良の解決策であるとは限りませんが、新しいアプローチがうまく機能するかもしれません。
複雑な質問に答えることは、異なる情報源から情報を集めて質問に答えることを意味します。
新しい方法は4つの部分から構成されています。
プランニング部分: 複雑な質問をより簡単な関連質問に分解し、問題を整理します。
ウェブ検索ツール: このツールはBingを使用して、簡単な質問に基づいてインターネットを検索します。検索結果の上位ページを訪問し、情報を要約し、すべての要約を組み合わせて元の質問に答えるのに役立てます。
統合部分: ウェブ検索から得られた情報が質問に答えるのに役立つかどうかを確認します。役立つ場合は、報告部分に進みます。役立たない場合は、プランニング部分にどの情報がまだ必要かを伝えます。
報告部分: 最終的な答えを提供します。答えは詳細で、参照が添えられています。
マネージャ部分: システムのすべての部分間で情報を共有します。

MuSiQue データセットからの複雑な質問を使用して、エージェントワークフローの性能を確認しました。これらの質問は回答が困難になるように設計されています。

下記の通り、1つの質問は複数を複数の質問に分解することにより、答えを導き出す必要があり、その質問のステップの構造は図にある通り、グラフ構造的に構成される。
(Q1) ナミビアの初代大統領の後任は誰ですか?⇒ヒフィケプニェ・ポハンバ
(Q1-1) ナミビアの初代大統領は誰ですか?⇒サム・ヌジョマ
(Q1-2) サム・ヌジョマの後任は誰ですか?⇒ヒフィケプニェ・ポハンバ
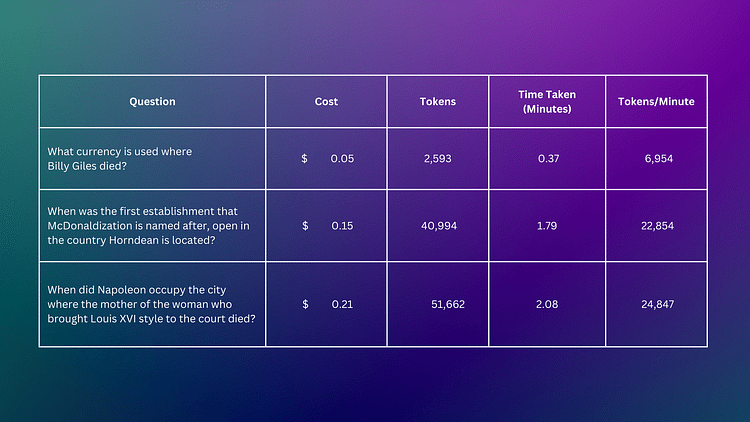
(Q2) ビリー・ジャイルズが亡くなった場所で使われている通貨は何ですか?⇒ポンド
(Q2-1) ビリー・ジャイルズが亡くなった場所はどこですか?⇒ベルファスト
(Q2-2) ベルファストはイギリスのどの地域にありますか?⇒北アイルランド
(Q2-3) 北アイルランドの通貨単位は何ですか?⇒ポンド
(Q3) マクドナルディゼーションの名前の由来となった最初の店舗が、ホーンディーンのある国で開店したのはいつですか?⇒1974年
(Q3-1) マクドナルディゼーションの名前の由来は何ですか?⇒マクドナルド
(Q3-2) ホーンディーンはどの州にありますか?⇒イングランド
(Q3-3) イングランドで最初のマクドナルドが開店したのはいつですか?⇒1974年
(Q4) ルイ16世のスタイルを宮廷に持ち込んだ女性の母親が亡くなった都市をナポレオンが占領したのはいつですか?⇒1805年
(Q4-1) ルイ16世のスタイルを宮廷に持ち込んだのは誰ですか?⇒マリー・アントワネット
(Q4-2) マリー・アントワネットの母親は誰ですか?⇒マリア・テレジア
(Q4-3) マリア・テレジアが亡くなった都市はどこですか?⇒ウィーン
(Q4-4) ナポレオンがウィーンを占領したのはいつですか?⇒1805年
(Q5) プラゼレスの国が統治していたアルバの大陸に住むドイツ人は何人ですか?⇒500万人
(Q5-1) アルバはどの大陸にありますか?⇒南アメリカ
(Q5-2) プラゼレスの国はどこですか?⇒ポルトガル
(Q5-3) ポルトガルが統治していた南アメリカの植民地はどこですか?⇒ブラジル
(Q5-4) ブラジルに住むドイツ人は何人ですか?⇒500万人
(Q6) フィリップスブルクのある地域にマラコフを占領した人々が来たのはいつですか?⇒1625年
(Q6-1) フィリップスブルクはどこの首都ですか?⇒セントマーチン
(Q6-2) セントマーチンはどの地形的特徴に位置していますか?⇒カリブ海
(Q6-3) マラコフを占領したのは誰ですか?⇒フランス人
(Q6-4) フランス人がカリブ海に来たのはいつですか?⇒1625年
OpenAIのgpt-3.5-turbo-0125およびgpt-4-0125-previewをテストしました。これらをGPT 3.5-turboおよびGPT 4-turboと呼びます。
さて、AutoGenの制限について議論しましょう。
1. LLMは推論に苦労する
複雑なタスクには、現在のLLMが持つ推論能力以上のスキルが必要です。私のテストでは、3つ以上のステップが必要な質問や非線形パターンの質問に対して、タスクの信頼性が低下することが示されました。GPT 4-turboはGPT 3.5-turboよりも良い結果を出しましたが、両者とも非線形の質問構造に問題がありました。
次に、多段階の質問に関するテスト結果を見てみましょう。

GPT 3.5-turboとGPT4-0125-previewの推論の比較では、新しいGPT4モデルがビリー・ジャイルズが亡くなった場所で使用される通貨を特定する際に少し詳細にわたっています。両モデルとも質問をよく分解し、正しく英国ポンドを特定しました。違いは、GPT 4-turboがBillie Gilesが誰であるかをより詳しく調べ始めることで、文脈をより深く考慮していることを示唆している点です。
GPT 3.5-turboのエージェントトレースとGPT 4-turboのエージェントトレースを参照してください。

GPT 3.5-turboは広範で不明確な戦略を試み、歴史的な出来事や人物を結びつけるのに苦労しました。しかし、GPT 4-turboはより整理された方法を使用し、まず主要な人物や出来事を見つけてから、ウィーンとナポレオンがそこにいた年(1805年と1809年)を特定しました。
覚えておいてください、GPT 4-turboが答えを見つけたとしても、常にそうするわけではありません。試したときにうまくいかないこともありました。
GPT 3.5-turboのトレースとGPT 4-turboのトレースを参照してください。

GPT 3.5-turboは一般的な回答をしましたが、正確な開業日を特定しませんでした。一方、GPT 4-turboは質問をより簡単なサブ質問に分解し、正確な答えである1974年10月を導き出しました。
詳細なプロセスについては、GPT 3.5-turboとGPT 4-turboを参照してください。

GPT 3.5-turboは一般的な検索戦略を試みましたが、より具体的かつ直接的である必要がありました。GPT 4-turboは「Prazeres」に関する初期の誤解を修正し、南アメリカのポルトガル植民地としてのブラジルに焦点を当てました。これにより、文脈をよりよく理解していることが示されました。しかし、GPT-4 turboはフィードバックを使用して正しい答えを導き出すことはできませんでした。
両モデルとも、特定の人口統計データを取得するのに苦労し、複雑で多層的な質問に対処するのが難しいことを示しました。GPT 4-turboは質問の言い換えがうまくできましたが、データを正しく取得する点ではGPT 3.5-turboと同じ問題に直面しました。
答えが正しい場合、GPT 4-turboは要求された参照を正確に提供しましたが、GPT 3.5-turboはこれができませんでした。また、特にフィードバックを使用する必要がある場合、両モデルとも一貫性がないことが確認されました。
GPT 3.5-turboのエージェントトレースとGPT 4-turboのエージェントトレースを参照してください。
2. 複数のエージェントを使用することの費用
現時点では、ワークフローで複数のエージェントを使用することは費用がかかり、実際の状況で正当化するのは難しいです。AutoGenでうまく動作するのはGPT-4モデルのみですが、これは多くの実際の用途には高すぎます。
AutoGenワークフローの高コストは、モデルとフレームワークがコンテキストを処理する方法によるものです。AutoGenは、ワークフロー内のすべてのエージェントに会話の全コンテキストを共有します。これにより、エージェント同士の効果的なコミュニケーションが可能になります。しかし、特にエージェントが非線形の多段階の質問のような難しいタスクを解決しなければならない場合、コストは急速に上昇します。
質問が複雑になるほど、コストも高くなります。これはワークフローのステップ数が増えるだけでなく、フォローアップの質問が必要になる可能性が高いためです。
3. レート制限に達する可能性
AutoGenを任意のプロジェクトに使用する場合、レート制限に達する可能性があります。執筆時点で、OpenAIには5つの有料レベルのレート制限があります。

OpenAIのレート制限(2024年2月11日時点)
GPT4-Turboは無料で利用できません。
レート制限は、大規模なアプリケーションを実行する際に問題になることがあります。予測可能なタスクには通常管理が容易ですが、自律的な(LLM)エージェントワークフローを使用するアプリでは困難です。これらのエージェントは、思考能力が限られているため、時々タスクを繰り返すことがあります。これは予測が難しいですが、複雑なタスクではより一般的に見られます。AutoGenでは、ワークフローが停止する前に繰り返す回数を制限できます。これにより、アプリがOpenAIサーバーに過負荷をかけるのを防げますが、タスクを完了するのに十分なサイクルを許可する必要があります。
何千人ものユーザーにサービスを提供する場合、レート制限に達する可能性があります。一部のユーザーは大量のトークンを使用するクエリを持ち、パフォーマンスの問題を引き起こします。大規模に運営している場合、レート制限に達するのに多くのユーザーは必要ありません!

AutoGenはこの問題に対する解決策を提供します。ワークフロー用に複数のOpenAIモデルエンドポイントを登録できます。1つが失敗した場合、ワークフローは自動的に次の利用可能なモデルに切り替わります。
4. オープンソースLLMを使用する際の課題
AutoGenの課題の1つは、オープンソースLLMとの互換性があまり良くないことです。多くのLLMアプリケーションフレームワークと同様に、AutoGenはOpenAIを中心に設計されています。しかし、多くの実際のケースではオープンソースモデルが必要です。これらのモデルをAutoGenに統合するのは困難でした。統合できたとしても、マルチエージェントワークフローではパフォーマンスが良くありませんでした。これは、オープンソースモデルの性能がそのようなワークフローに適していないことが主な理由ですが、AutoGenはこれらのモデルを扱いやすくするべきです。
主な問題は、AutoGenがOpenAIモデルとの連携を前提に設計されていることです。オープンソースモデルを使用することは可能ですが、基本的なエージェントクラスに大きな変更を加えずにカスタムプロンプトを統合する方法が明確ではありません。
LLM間で標準的なプロンプト形式は存在しないため、プロンプトをカスタマイズできることが、オープンソースLLMをAutoGenで効果的に使用するための鍵です。
コミュニティがより優れたモデルを開発するにつれて、オープンソースとの互換性はますます重要になります。2023年のOpenAI問題の後、企業はサードパーティに依存するのではなく、自社のモデルを管理したいと考えています。モデルがマルチエージェントワークでうまく機能すれば、オープンソースの方がコストを抑えることができます。
結論
AutoGenの使用を楽しんでおり、いくつかのアプリを構築しました。しかし、まだプロダクション環境で使用するには至っていません。トークン使用量とコストを制御するためのメモリ管理を改善したいと考えています。また、オープンソースモデルとの統合が簡単になることを期待しています。メモリ管理に関しては、mem-GPTが最近AutoGenエージェントを作成しており、これは有望かもしれません。Mem-GPTはそのコンテキストを知的に管理できるからです。私にとっての主な制限はLLMです。ワークフローが信頼できるものになるためには、推論能力の向上が必要です。