
市民プールの混雑状況画像をマルチモーダルLLMを利用してログ化してみた

本記事は面倒なことはChatGPTにやらせよう Advent Calendar 2024の17日目の記事です。
プールの混雑のトレンドを知りたい…
7月からダイエット目的で近場の市民プール(リフレッシュプラザ柏)に通い始めることに。酷暑のせいかとても混雑しており、Webサイトの混雑状況を参考に空いている時間を狙って行くものの、到着すると混んでいることもしばしば…
施設のWebサイトでは、券売機に表示されている混雑状況をライブカメラで撮影して公開しています。

そこでマルチモーダル(画像や音声を処理できる)LLMを利用して、定期的に上記の画像からテキスト化してログに出力し、混雑トレンドを把握してみることにしました。
ChatGPTは定期タスク実行には向いていない
ChatGPTやGPTsは、ブラウザから人間があれこれ指示をしないと結果を返してくれません。今回の混雑トレンドのログ化をChatGPTでやろうとすると、下記のような流れになります。
施設Webサイトのにブラウザでアクセスする
混雑状況画像をダウンロードする
ChatGPTを開き、ダウンロードした画像を添付して「添付の画像からプールの混雑状況をテキストで出力して」とプロンプトを入力する
ChatGPTの出力結果をコピーして、手元のファイルに追記する
上記を毎日、10分おきにずーーーーっとやり続ける
ChatGPTでは無理っぽいですね。
というか、ブラウザを操作する私が無理ですw
こういう単調な作業はPythonにやってもらいましょう。
今回はPythonからOpenAI APIを呼び出して、LLMを使用することにしました。
OpenAI APIとは
ChatGPTを提供しているOpenAI社が提示しているGPT-4oなどのLLMを、プログラムから利用できる仕組みをAPI (Application Programming Interface)といいます。
ChatGPT Plus (いわゆるブラウザ版) はどれだけ使っても月額費用は固定ですが、API利用の場合は従量課金になるので要注意です。大量にアクセスすると、それなりにコストが掛かります。(今回のコストについては後ほど)
また、APIを呼び出す際には「APIキー」が必要になります。APIキーはOpenAIのサイトで発行できます。
Pythonをどこで稼働させるか
今回は自宅で常時稼働しているLinuxマシン上でPythonコードを稼働させることにしました。
もし、同じようなタスクにチャレンジしてみたい、と思った方はWindowsやMac上でPythonが動作すれば同じことが実現可能です。
とはいえ、今回のような一定間隔で処理を行うケースでは、Pythonがずっと動き続けられる環境が必要となります。稼働しているマシンの電源を落としたり、ネットワークが切断されるとOpenAI APIが呼び出せなくなってしまいます。
常時稼働環境が必要なら、値段お安めのLinuxサーバをレンタルしてPythonを稼働させる、というのが良いかもしれません。
プロンプト (初版)
混雑画像に対して、下記のプロンプトを使用して、データ化してみました。
添付の画像はあるトレーニングジムの混雑状況です。
画像から時刻と、プール・トレーニング・男湯・女湯それぞれの混雑状況を抽出して出力してください。
# 混雑状況のラベリングルール
- 丸: Low
- 三角 : Moderate
- バツ: High
# 出力フォーマット (JSON形式)
{
"時刻": "{hh:mm:ss形式での時刻}",
"プール": "{プールの混雑状況を表すラベル}",
"トレーニング": "{トレーニングの混雑状況を表すラベル}",
"男湯": "{男湯の混雑状況を表すラベル}",
"女湯": "{女湯の混雑状況を表すラベル}"
}
復唱、挨拶、などは一切省略して、結果のみを出力してください。Markdownのコードブロックを示すバッククォートも省略してください。
GPT-4o-miniで正確に判定できない
まずは、上記のプロンプトを試してみました。
画像を解釈させるので、マルチモーダル対応モデルでなければなりません。2024年7月時点での選択肢は下記の2つ。
GPT-4o
GPT-4o-mini
GPT-4oは安定して正しい結果を出力できたのですが、GPT-4o-miniでは誤判定するケースが散見されました。
が、しかしです。GPT-4o-miniの料金はGPT-4oの1/16なのです。安いんですよ!
あれこれ試行錯誤して、GPT-4o-miniで安定して画像認識する方法を模索してみました。
OpenAI Playgroundでプロンプトの動作確認をする
ChatGPTで画像認識系のタスクを指示すると、Advanced Data Analysisで解きたがる(そして失敗する)ことが多かったので、OpenAI Playgroundで動作確認を行いました。
ChatGPTには便利な付加機能が沢山付いているので、普段使いにはとても便利なのですが、API開発する場合にはそれが邪魔になることがあります。
API開発を行う際には「素のLLM」として動作確認をしたいので、Playgroundを使うのがおすすめです。
GPT-4o-miniで安定して画像認識させる
まず「混雑度画像から正しくテキストが抽出できているか」というタスクを確実に遂行できるように、プロンプトを下記のようにしてみました。
添付の画像はあるトレーニングジムの混雑状況です。
画像から時刻と、プール・トレーニング・男湯・女湯それぞれの混雑状況を抽出して出力してください。
混雑状況は文字の記号(◯、△、❌️)で出力してください。
上記のプロンプトでは、いろいろな混雑状況を表した画像でも正しくテキストが抽出できていました。
以下の情報を抽出しました:
- **時刻**: 16:05
- **プール**: △
- **トレーニング**: ❌
- **男湯**: ❌
- **女湯**: ◯どうやら「画像→テキスト抽出」と「テキスト→JSON形式変換」という2つのタスクを同時に行わせていたのが、誤判定の原因でした。
そこでPythonでの処理は下記のようにタスクを2つに分解し、2回LLMを呼び出すようにしました。
画像から混雑状況を表すテキストを抽出する
混雑状況を表すテキストをJSON形式に整形する
2つめのタスクのプロンプトは下記の通りです。
下記のテキストは、とあるトレーニングジムの混雑状況です。
# 混雑状況
<<1つめのタスクのアウトプットである混雑状況テキスト>>
これをラベルに変換したあと、JSON形式に整形して出力してください。
# 混雑状況のラベリングルール
- 丸: Low
- 三角 : Moderate
- バツ: High
# 出力フォーマット (JSON形式)
{
"時刻": "{hh:mm:ss形式での時刻}",
"プール": "{プールの混雑状況を表すラベル}",
"トレーニング": "{トレーニングの混雑状況を表すラベル}",
"男湯": "{男湯の混雑状況を表すラベル}",
"女湯": "{女湯の混雑状況を表すラベル}",
}
復唱、挨拶、などは一切省略して、結果のみを出力してください。Markdownのコードブロックを示すバッククォートも省略してください。
出力結果は下記のようになりました。
{
"時刻": "16:05:00",
"プール": "Moderate",
"トレーニング": "High",
"男湯": "High",
"女湯": "Low"
}コストを下げるために画像を縮小してみる
そもそも、コストを下げるためにGPT-4o-miniを選びました。
なんせ、頻繁にOpenAI APIを利用するので、チリツモでもコストは無視できません。
もっとにコストは下げられないのだろうか、と再度点検してみました。
OpenAI Playgroundの画面には、上り(リクエスト)と下り(レスポンス)のトークン数が表示されます。
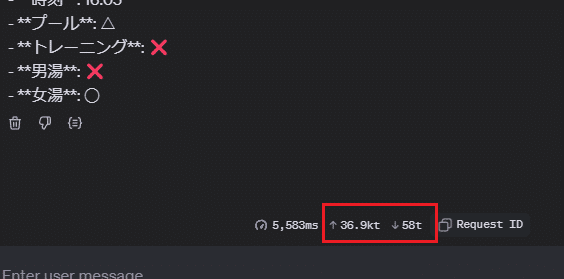
上りが36.9Kトークン?画像サイズか!
画像サイズを調べてみると1920 x 1080pxで、それなりに大きな画像でした。
試しに40%に縮小した画像で確認して認識精度は下がらなかったので、それで行くことにしました。
実施結果 (2024年9月~10月)
空いている:0.0 / やや混んでいる:0.5 / 混んでいる:1.0でスコア化して、曜日+時間帯でスコアを合計したのが下記の表です。

19:00以降ならば、どの曜日でも空いている、ということがわかりました。
Mission complete!
コスト
APIの利用コストは、Playgroundのサイトから"Dashborad->Usage"で確認することができます。
9月
9/1付近は試行錯誤もあったので、平常運転期間だと$5くらい
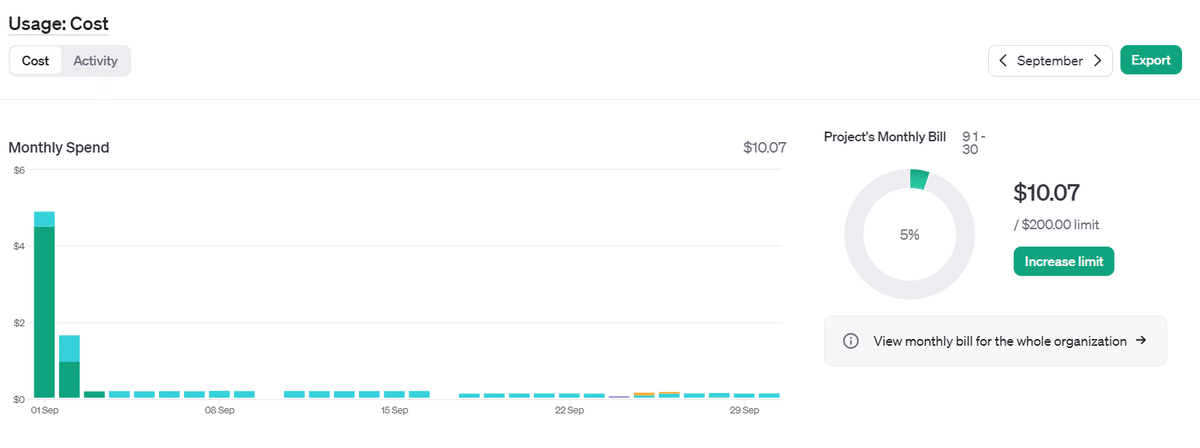
10月
10/2になんかやったっぽい(覚えてない…)が、それを引くと$3弱

トータルで $8くらいなので、150円/$換算だと、1,200円くらいでした。
軽量モデルの選定や画像サイズの縮小など、コスト削減で頑張った結果が出たので満足です。
コード
まずは依存パッケージをインストールします。(すでにPython仮想環境はつくられている前提とします)
$ pip install openai python-dotenv httpx Pillow.env というファイルを作成し、OpenAIで発行したAPIキーを下記の形式で記載します。
OPENAI_API_KEY=<YOUR_API_KEY>Pythonコードは下記の通りです。
import base64
import json
import os
from datetime import datetime
from io import BytesIO
import httpx
from dotenv import load_dotenv
from openai import OpenAI
from openai.types.chat import ChatCompletion
from PIL import Image
# - 定数定義 -
# 画像URL
URL = "https://kashiwa-refreshplaza.net/_livecam/crowded1.jpg?1725167809021"
# 使用するモデル
MODEL = "gpt-4o-mini"
# 出力するJSONLファイル
JSONL_LOG_FILE = "crawding_data.jsonl"
# 画像のリサイズ率 (画像を縮小し、OpenAI APIの使用コストを抑える)
RESCALE_RATE = 0.4
# .envファイルから環境変数を読み込む
load_dotenv()
# OpenAI APIのクライアントを作成
openai_client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
def rezise_image(image: bytes, rate: float) -> bytes:
"""画像をリサイズして返す"""
# PILのImageオブジェクトに変換
pil_image = Image.open(BytesIO(image))
# 幅と高さを取得
old_width = pil_image.width
old_height = pil_image.height
# リサイズ
resized_pil_image = pil_image.resize(
(int(old_width * rate), int(old_height * rate))
)
# バイナリデータに変換
resized_image_bytes = BytesIO()
resized_pil_image.save(resized_image_bytes, format=pil_image.format)
return resized_image_bytes.getvalue()
def get_image_fom_url(url: str) -> bytes:
"""指定されたURLから画像を取得してバイナリデータとして返す"""
with httpx.Client() as client:
response = client.get(url)
response.raise_for_status()
# 確認のために画像をファイルで保存しておく
image_filename = datetime.now().strftime("%Y%m%d_%H%M%S_image.png")
with open(image_filename, "wb") as ifp:
ifp.write(response.content)
# HTTPレスポンスのバイナリデータを取得
image_binary = response.content
# 画像をリサイズして返す
return rezise_image(image_binary, RESCALE_RATE)
def encode_image_as_base64(image: bytes) -> str:
"""バイナリデータをbase64エンコードして文字列として返す"""
return base64.b64encode(image).decode("utf-8")
def chat(user_prompt: list[dict]) -> str:
"""OpenAI Chat APIを使って対話を行う"""
response: ChatCompletion = openai_client.chat.completions.create(
messages=[{"role": "user", "content": user_prompt}], # type: ignore
model=MODEL,
temperature=0.0,
max_tokens=1000,
)
content = response.choices[0].message.content
return content # type: ignore
def get_crowding_data(image_url: str) -> dict:
"""指定された画像URLから混雑状況を取得して辞書で返す"""
# 画像を取得
image = get_image_fom_url(image_url)
# 画像をbase64エンコード
image_base64 = encode_image_as_base64(image)
# OpenAIのLLMを利用し、画像から混雑状況をテキストとして取得
image_cognitive_prompt = [
{
"type": "text",
"text": """添付の画像はあるトレーニングジムの混雑状況です。
画像から時刻と、プール・トレーニング・男湯・女湯それぞれの混雑状況を抽出して出力してください。
混雑状況は文字の記号(◯、△、❌️)で出力してください。""",
},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_base64}"},
},
]
image_cognitive_text = chat(image_cognitive_prompt)
# OpenAIのLLMを利用し、混雑状況を表現したテキストをJSON形式に整形
format_prompt = [
{
"type": "text",
"text": """下記のテキストは、とあるトレーニングジムの混雑状況です。
# 混雑状況
@@@image_cognitive_text@@@
これをラベルに変換したあと、JSON形式に整形して出力してください。
# 混雑状況のラベリングルール
- 丸: Low
- 三角 : Moderate
- バツ: High
# 出力フォーマット (JSON形式)
{
"時刻": "{hh:mm:ss形式での時刻}",
"プール": "{プールの混雑状況を表すラベル}",
"トレーニング": "{トレーニングの混雑状況を表すラベル}",
"男湯": "{男湯の混雑状況を表すラベル}",
"女湯": "{女湯の混雑状況を表すラベル}",
}
復唱、挨拶、などは一切省略して、結果のみを出力してください。Markdownのコードブロックを示すバッククォートも省略してください
""".replace(
"@@@image_cognitive_text@@@", image_cognitive_text
),
},
]
json_str = chat(format_prompt)
try:
# LLMが出力したJSON文字列が正しい形式かチェック (形式不正ならば例外が発生する)
data = json.loads(json_str)
# 辞書に日付、モデル名、リサイズ率を追加して返す
data = {
**{"日付": datetime.now().strftime("%Y-%m-%d")},
**data,
**{"model": MODEL, "rezise_rate": RESCALE_RATE},
}
return data
except json.JSONDecodeError as e:
# JSON形式が不正な場合はエラーを辞書として返す
return {"日付": datetime.now().strftime("%Y-%m-%d"), "error": str(e)}
def main():
# 指定URLの画像から混雑状況を辞書として取得
data = get_crowding_data(URL)
# 取得したデータをJSONLファイルに書き込む
with open(JSONL_LOG_FILE, "a") as f:
f.write(json.dumps(data, ensure_ascii=False) + "\n")
if __name__ == "__main__":
main()
上記のPythonコードを cron (指定した曜日や時刻にプログラムを自動的に起動する、Linuxの仕掛け)で10分サイクルで起動して、混雑画像の結果をログに出力するようにしました。
あまり頻繁にWebサイトにアクセスすると、Webサーバーに負荷をかけてしまうので、クローリングの頻度には注意が必要ですね。
まとめ
PythonからOpenAI APIを使用することで、LLMを活用したタスクを行うことができました。
OpenAIに限らず、AnthropicやGoogleなどが提供しているLLMもプログラムから利用することができます。
PythonからLLMを使って、面倒なタスクをやっつけちゃいましょう!