
AWSインフラの基本と実践:初心者でもできるクラウド構築 第5回

4. ストレージソリューションの選択
AWSでは、データを保存するための「ストレージ」サービスが豊富に用意されています。アプリケーションやサービスが使うデータを、どうやって安全に保存し、効率よく使うかは非常に重要です。AWSのストレージサービスは、それぞれ特徴があり、データの種類や使い方によって適したサービスを選ぶことができます。
ここでは、AWSの代表的なストレージソリューションについて、その特徴と使いどころを紹介します。
1. Amazon Simple Storage Service (S3)
S3は、AWSで最も広く使われているストレージサービスの一つで、「オブジェクトストレージ」として知られています。S3では、画像、動画、バックアップデータ、ログデータなどを「オブジェクト」として保存できます。
バケットとは、S3でデータを格納するための基本的な単位であり、S3を利用する際の最初のステップです。バケットは、フォルダのようなもので、データ(オブジェクト)を分類し、整理して保存するために使用されます。
S3バケットには以下のような特徴があります:
グローバルで一意の名前を付ける必要があります。
データは、バケットの中に「オブジェクト」として格納され、オブジェクトにはキー(名前)とデータ本体が含まれます。
バケットはAWSの任意のリージョンに作成でき、リージョンを選択することでデータの遅延や法的要件を考慮できます。
アクセス権限(公開・非公開)はバケットごとに設定でき、IAMポリシーやバケットポリシーを使って細かく制御できます。

使いどころの例
ウェブサイトで使用する画像や動画の保存
データ分析用のログデータの保管
静的ウェブサイトのホスティング
モバイルアプリでのファイル共有やバックアップ
2. Amazon Elastic Block Store (EBS)
EBSは、EC2インスタンス(仮想サーバー)のためのブロックストレージです。ブロックストレージは、ハードディスクのように使うことができ、データベースやファイルシステムを必要とするアプリケーションに適しています。
EBSボリュームはEC2インスタンスにアタッチされ、EC2が動作している間は永続的にデータを保存します。インスタンスが停止してもデータが失われることはなく、EC2インスタンスを再起動するときにもデータはそのまま残っています。
また、EBSではバックアップ(スナップショット)を作成して、データの復元や移行が簡単に行えるのも大きな利点です。
使いどころの例
データベースのストレージ(MySQL、PostgreSQLなど)
アプリケーションのファイルシステム
EC2インスタンスで動作するソフトウェアのデータ保存
3. Amazon Elastic File System (EFS)
EFSは、複数のEC2インスタンスで共有できるファイルストレージです。ファイルストレージは、フォルダやファイルという形でデータを整理して保存できるため、データを共有したり、共同で作業するシステムに向いています。
EFSは自動的にスケーリングされ、必要に応じて容量が増減します。複数のインスタンスが同時に同じファイルにアクセスする場合にも、EFSを使うと簡単に設定でき、複雑な設定や管理の手間が省けます。

使いどころの例
複数のサーバー間で共有するファイルシステム
アプリケーションで使用するデータや設定ファイルの共有
コンテンツ管理システム(CMS)のデータ共有
4. Amazon Glacier
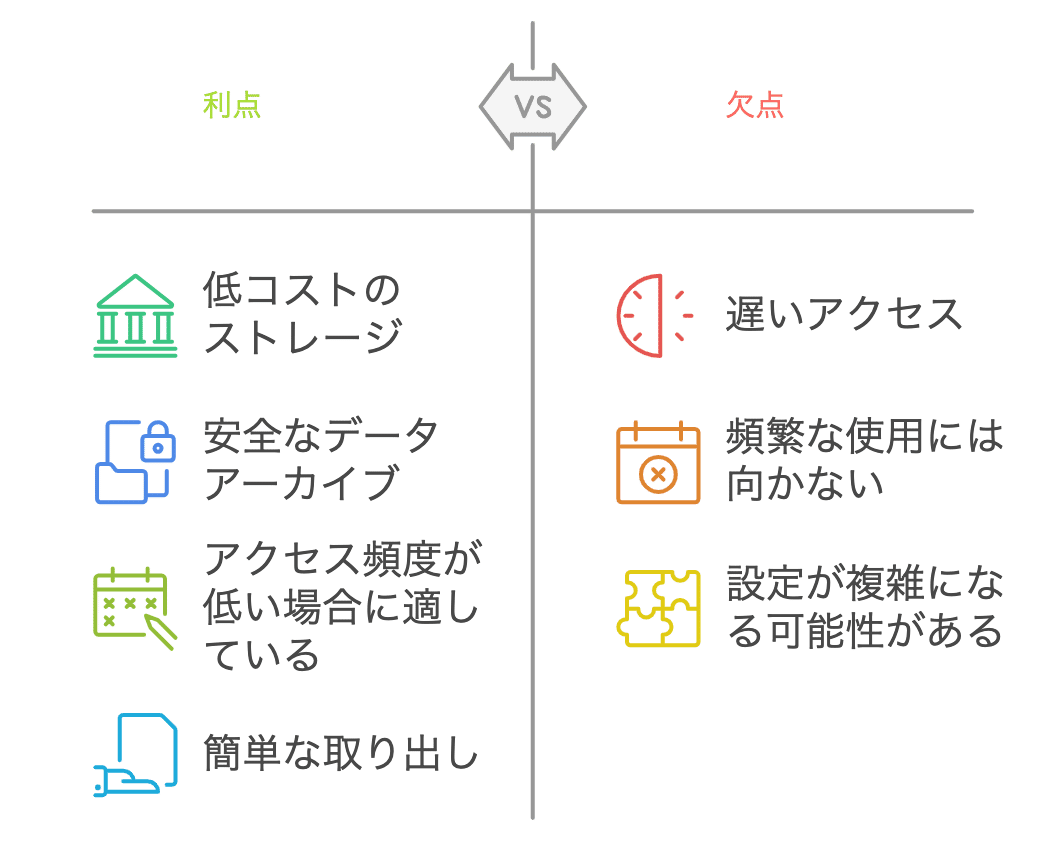
Glacierは、長期間保存するデータのためのアーカイブストレージです。アクセス頻度が低いデータを低コストで安全に保存するのに適しており、データが数ヶ月や数年に一度しか使われないような場合に便利です。
例えば、企業の古い書類や法的に長期間保存する必要があるデータ、バックアップなどを低コストで保管でき、必要なときにすぐ取り出せるようになっています。
使いどころの例
長期間保存が必要なバックアップデータ
アーカイブ用のデータ(法律や規制による保存義務のあるデータ)
アクセス頻度が非常に低い古いプロジェクトデータ
5. 実際にAWSを使ってみる:EC2の立ち上げとLambdaの作成
では実際にストレージリソースを構築してみましょう。ここでは、S3バケットを作成して、前章で作成したLambaを利用して、ファイルの作成、一覧などの表示する関数を作成してみます。
まずは、S3バケットを作成し、基本的な設定を行う手順を紹介します。
AWS Management Consoleにログイン
AWS Management Consoleにアクセスしてログインします。

S3サービスを開く
「サービス」メニューから「S3」を選択します。

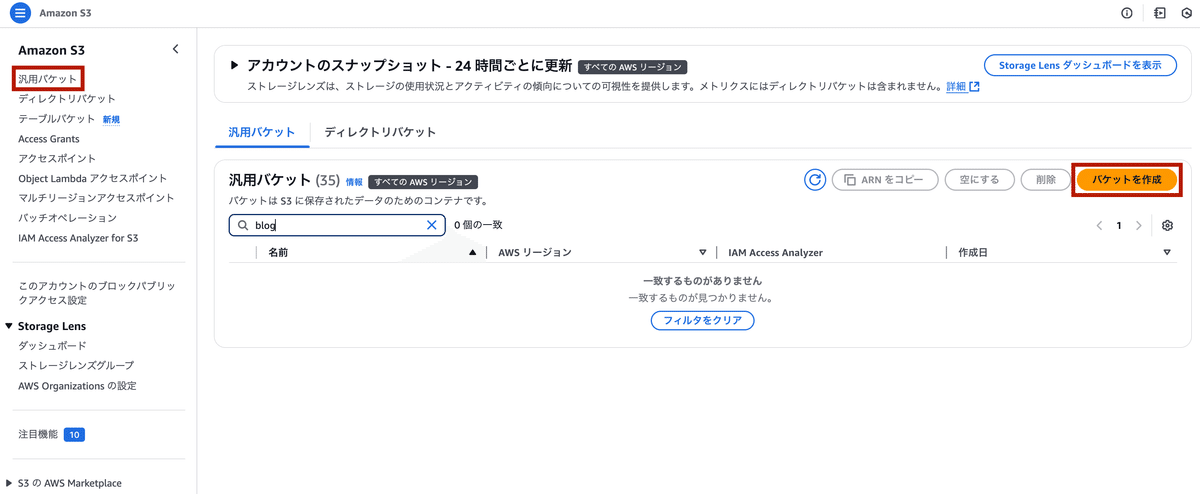
新しいバケットを作成
「バケットを作成」ボタンをクリックします。
以下の設定を行います:
リージョン:データを保存するリージョンを確認します(例:東京)。
バケット名:一意の名前を入力します(例:blog-my-s3-bucket-123)。
パブリックアクセス設定:最初はデフォルト(パブリックアクセスをすべてブロック)のままで問題ありません。
バージョニング(オプション):データの履歴を保存したい場合に有効化します。まずは無効で構いません。
デフォルトの暗号化:デフォルトはAmazon S3 マネージドキーを使用したサーバー側の暗号化 (SSE-S3)ですが、必要に応じて、AWS Key Management Service キーを使用した暗号化を選択します。
他:オブジェクトロックなども含めて必要に応じて設定します。まずはデフォルトのままで構いません。

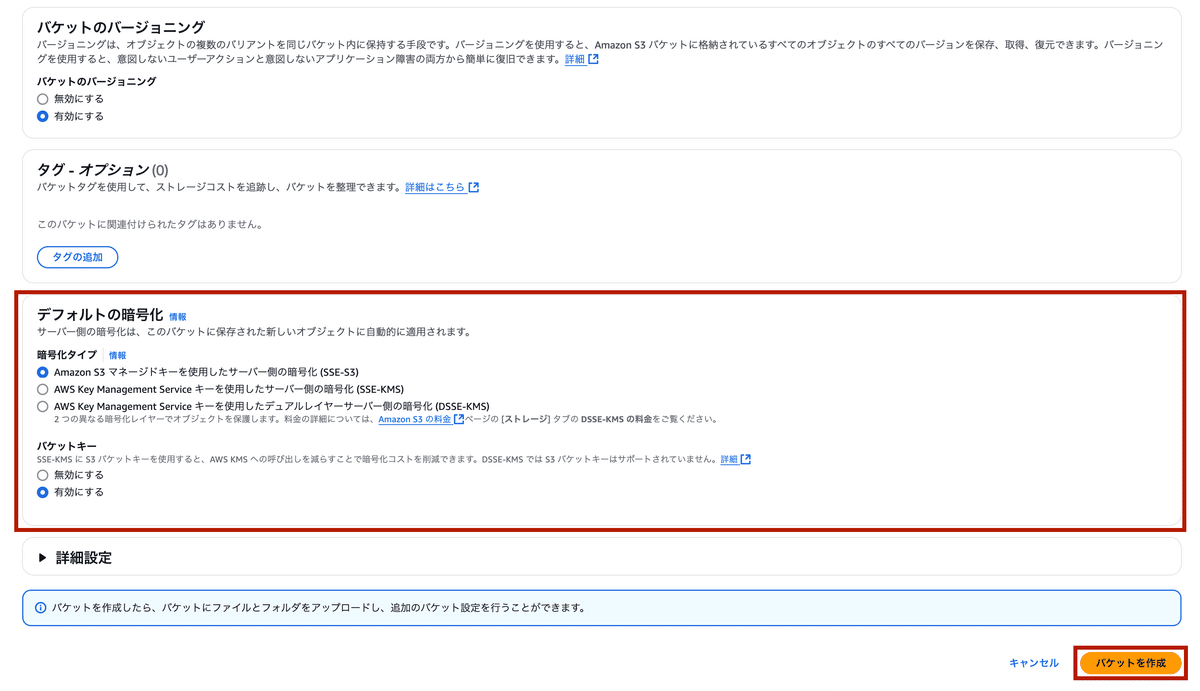
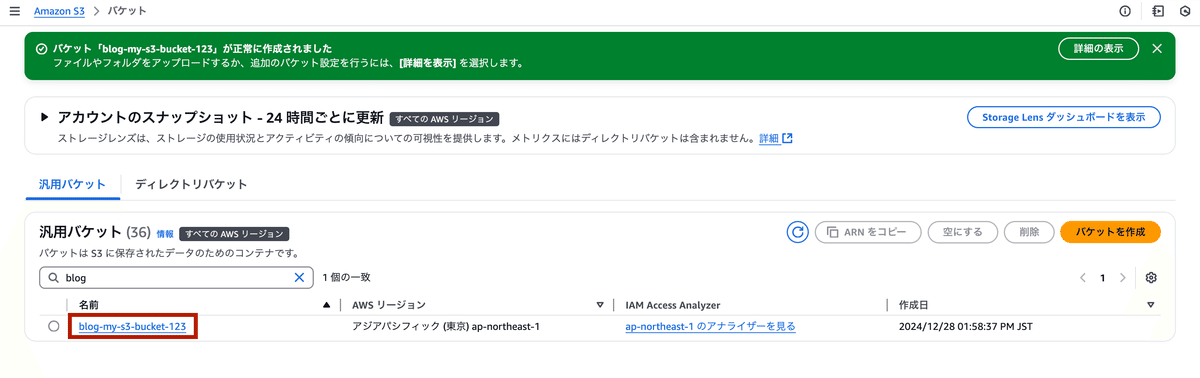
バケットの確認
作成したバケットがS3の一覧に表示されます。
作成したバケットをクリックし、データをアップロードしたり、設定を変更したりできます。

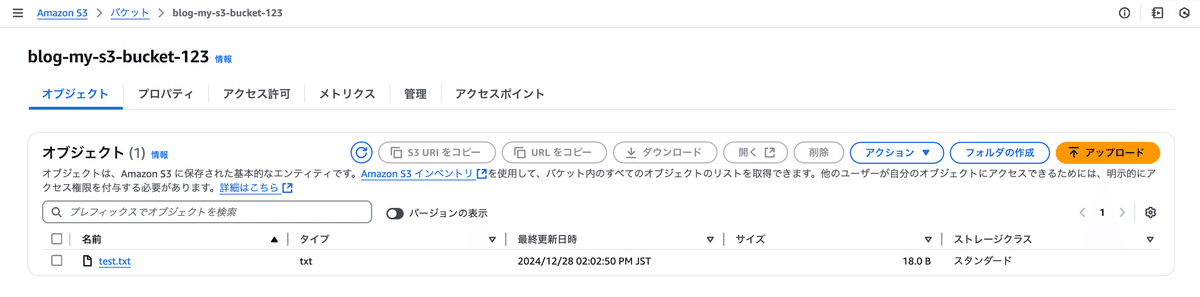

Lambda関数を作成
AWS Management Consoleにログインし、「Lambda」を選択。
前章で既に作っていたLambda関数があればそれを利用。ない場合は以下を実施。
新しい関数を作成し、ランタイムとしてPython 3.9以降を選択。
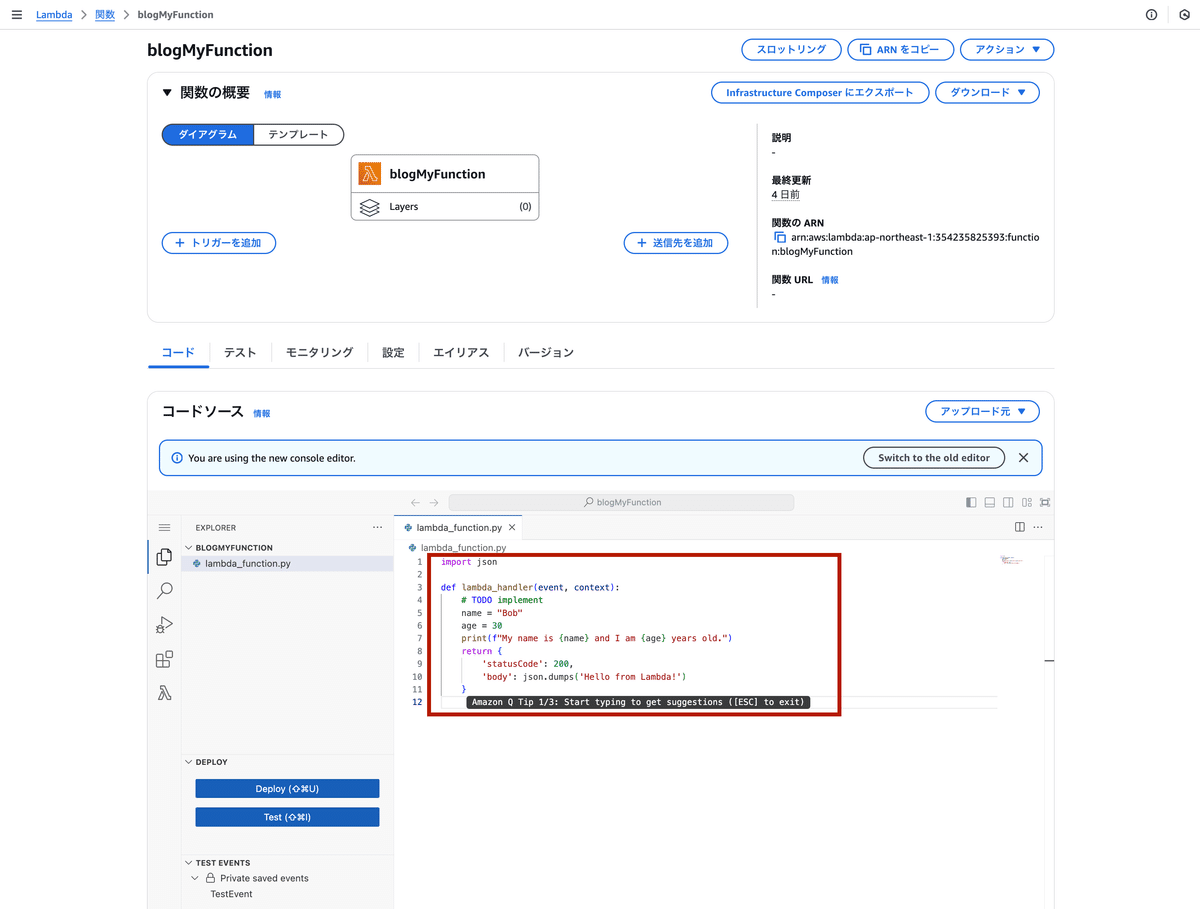
下記のコードをコピーペーストして配置。
import boto3
import logging
# ログ設定
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
# S3クライアントを作成
s3 = boto3.client('s3')
# ターゲットのS3バケット名
bucket_name = "blog-my-s3-bucket-123"
try:
# S3バケット内のオブジェクト一覧を取得
response = s3.list_objects_v2(Bucket=bucket_name)
if 'Contents' in response:
for obj in response['Contents']:
logger.info(f"Object Key: {obj['Key']} | Size: {obj['Size']} bytes")
else:
logger.info("No objects found in the bucket.")
except Exception as e:
logger.error(f"Error listing objects in bucket {bucket_name}: {str(e)}")
raise e
return {
"statusCode": 200,
"body": "S3 object listing complete. Check the logs for details."
}
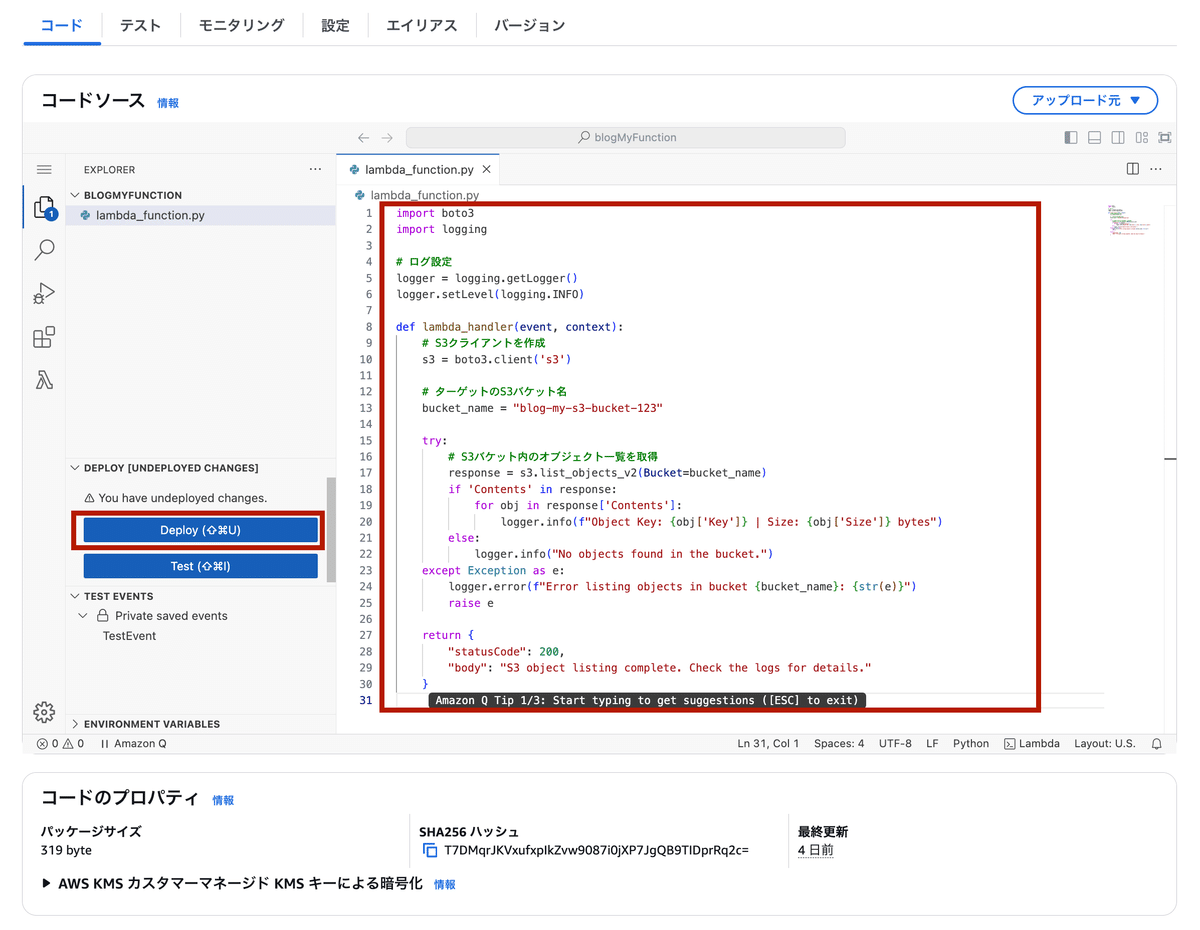

(新しく関数を作成する場合)IAMロールを設定
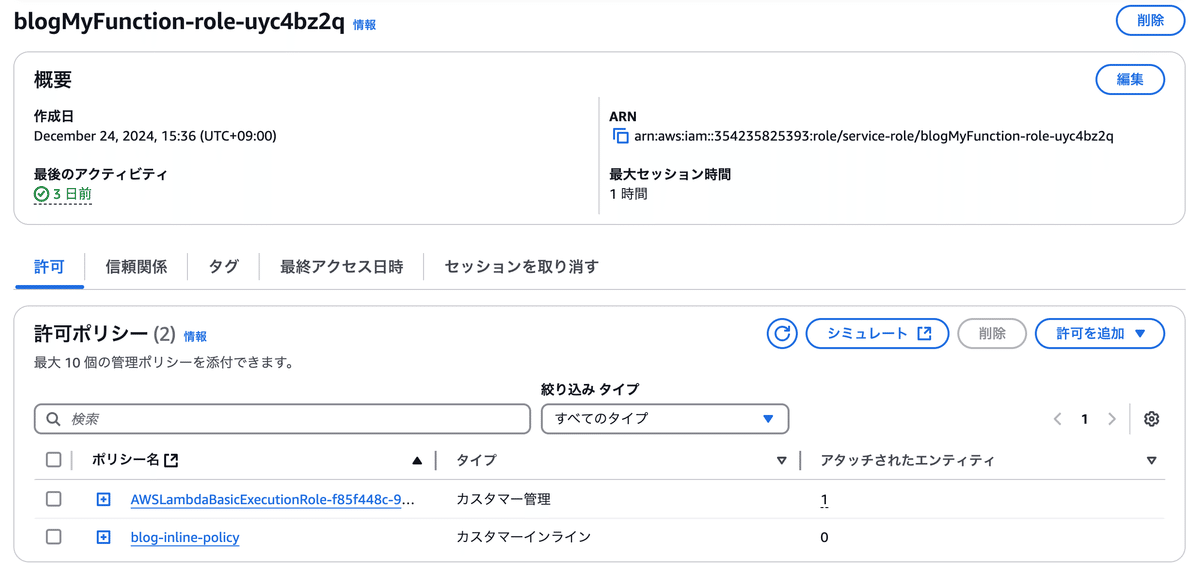
「IAM」サービスに移動し、新しいロールを作成。
「Lambda」用のロールを選択。
下記のポリシーを作成し、ロールにアタッチ。ResourceのS3バケットは各々作成したS3バケットのARNを指定。
Lambda関数にロールを関連付け
Lambdaの設定からアクセス権限から編集を行い、既存のロールの編集を行います。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::blog-my-s3-bucket-123"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::blog-my-s3-bucket-123/*"
}
]
}




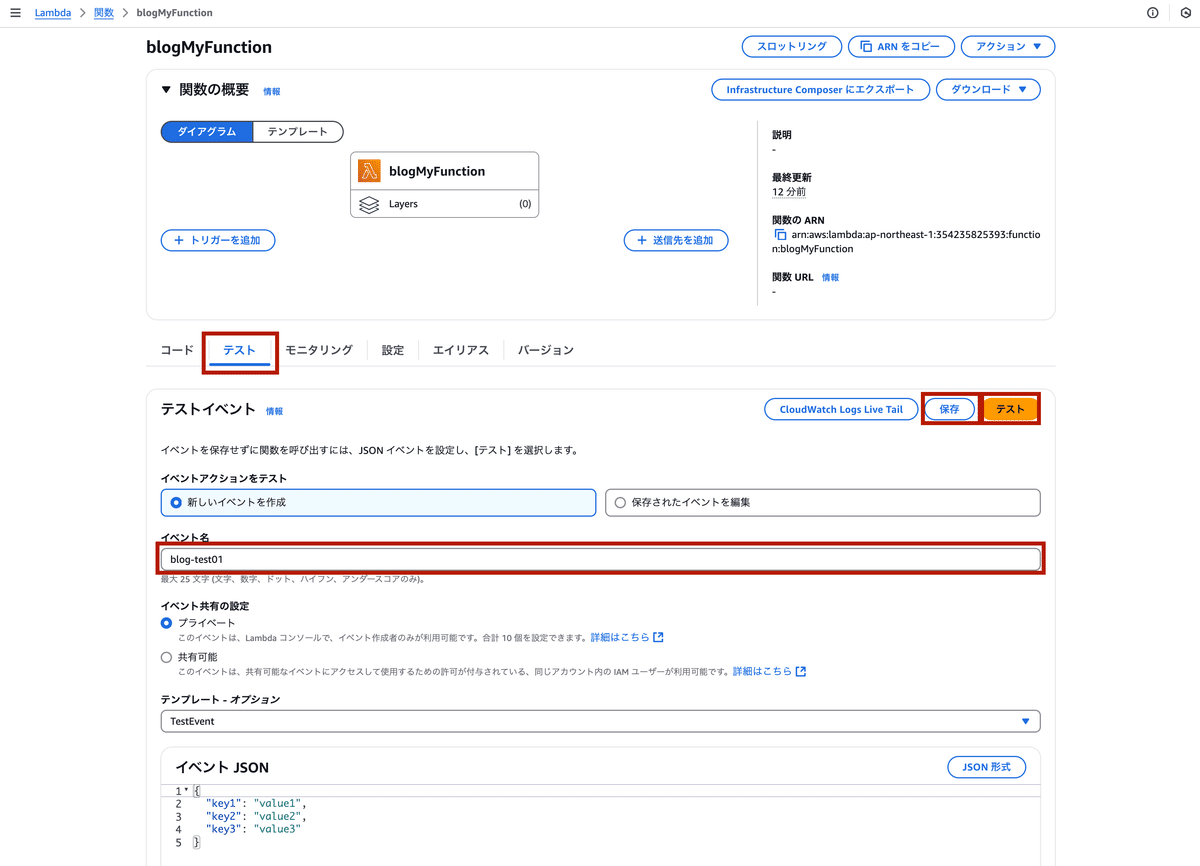
Lambda関数のテスト
「テストイベント」を作成し、コードを実行。
CloudWatchログでオブジェクト一覧が表示されることを確認。

まとめ
AWSのストレージソリューションには、用途に応じたさまざまな選択肢があります。S3はオブジェクトストレージとして柔軟に使え、EBSはEC2インスタンス用のブロックストレージとしてアプリケーションに力を発揮します。EFSはファイルを共有したいときに便利で、Glacierは長期保存向けの低コストなアーカイブストレージとして使えます。

このように、データの種類や使い方に応じて、適切なストレージサービスを選ぶことがAWSインフラの効率化につながります。次に、セキュリティの確保について解説し、データを安全に守るためのAWSのセキュリティ機能について見ていきましょう。