
Databricksを勉強してみる 第五回

前回はDatabricksの「データの取り込み」から「データの処理」までの内容について簡単に説明しました。
今回はいよいよ最終回!DatabricksでのETL作成方式とAWSでデータレイクを構築することに対する比較について説明します。
16. DatabricksでのETL作成方式
ETLの概要
ETL(Extract, Transform, Load) は、データ統合の基本的なプロセスであり、以下の3つのステップで構成されます。
抽出(Extract):データソースからデータを取得
変換(Transform):データのクレンジングや加工、ビジネスロジックの適用
ロード(Load):データウェアハウスやデータレイクにデータを格納

以前の章で説明したメダリオンアーキテクチャではブロンズレイヤーからシルバーレイヤー、シルバーレイヤーからゴールドレイヤーへのデータ処理で利用します。 Databricksでは、スケーラブルで効率的なETLプロセスを実現するためのさまざまな方法が提供されています。

ETLを実現する方式の種類
1. ノートブックベースのETL
特徴:
柔軟性が高い:カスタムロジックや複雑な変換処理を実装可能
インタラクティブな開発:データの可視化やデバッグが容易
チームでのコラボレーション:ノートブックを共有し、共同開発が可能
サンプルコード:
# データの抽出
df_raw = spark.read.format("csv").option("header", "true").load("/mnt/raw/data.csv")
# データの変換
from pyspark.sql.functions import col, trim
df_transformed = df_raw.select(
trim(col("name")).alias("name"),
col("age").cast("int"),
col("email")
).filter(col("age") >= 18)
# データのロード
df_transformed.write.format("delta").mode("overwrite").save("/mnt/processed/users")
2. Delta Live Tablesを使ったETL
特徴:
宣言的アプローチ:データパイプラインを宣言的に定義し、依存関係を自動管理
データ品質の向上:自動テストやデータ検証機能を提供
スケーラビリティ:大規模データにも対応
サンプルコード:
import dlt
from pyspark.sql.functions import col, trim
@dlt.table
def raw_data():
return spark.read.format("csv").option("header", "true").load("/mnt/raw/data.csv")
@dlt.table
def transformed_data():
return (
dlt.read("raw_data")
.select(
trim(col("name")).alias("name"),
col("age").cast("int"),
col("email")
)
.filter(col("age") >= 18)
)
3. ワークフローとジョブによるETLの自動化
特徴:
スケジューリング:定期的なジョブ実行をスケジュール可能
依存関係の設定:ジョブ間の依存関係を管理し、複雑なワークフローを構築
通知とモニタリング:ジョブのステータスを監視し、エラー時に通知を受け取る

設定例:
ジョブの作成:ノートブックやDelta Live Tablesパイプラインをジョブとして登録
スケジュール設定:Cron表記や簡易設定で実行頻度を指定
依存関係:ジョブの成功・失敗に応じた次のアクションを設定
Pythonコード例
import os
from databricks.sdk import WorkspaceClient
# Databricksクライアントの初期化
client = WorkspaceClient()
# ノートブックのパスを指定
notebook_path = "/Workspace/Users/<your-username>/etl_notebook"
# クラスターの設定(ジョブ実行用の汎用クラスターを指定)
existing_cluster_id = "<your-cluster-id>"
# ベースパラメータ(ノートブックに渡すパラメータ)
base_parameters = {
"input_path": "/mnt/data/input/",
"output_path": "/mnt/data/output/",
"process_date": "2024-01-01"
}
# ジョブタスクの設定
task_1 = {
"task_key": "etl_task",
"notebook_task": {
"notebook_path": notebook_path,
"base_parameters": base_parameters
},
"existing_cluster_id": existing_cluster_id
}
# ジョブの依存関係を持つ別のタスク(例:Task 1の成功後に実行されるTask 2)
task_2 = {
"task_key": "dependent_task",
"notebook_task": {
"notebook_path": notebook_path,
"base_parameters": base_parameters
},
"existing_cluster_id": existing_cluster_id,
"depends_on": [
{"task_key": "etl_task"}
]
}
# スケジュール設定(毎日午前2時に実行されるジョブ)
schedule = {
"quartz_cron_expression": "0 2 * * *",
"timezone_id": "UTC"
}
# ジョブ作成の設定
job_settings = {
"name": "ETL Job with Dependencies",
"tasks": [task_1, task_2],
"schedule": schedule,
"email_notifications": {
"on_failure": ["your-email@example.com"]
}
}
# ジョブの作成
created_job = client.jobs.create(**job_settings)
# 作成されたジョブのIDを表示
print(f"Job created successfully with Job ID: {created_job.job_id}")
ジョブ設定のポイント:
パラメータの利用:dbutils.widgetsを使ってノートブックにパラメータを渡し、再利用性を高める
エラーハンドリング:ジョブ内でエラー処理を実装し、失敗時の対策を講じる
Pythonコード例
from pyspark.sql.functions import col
# dbutils.widgetsを使用して、ノートブックのパラメータを設定・取得
dbutils.widgets.text("input_path", "/mnt/data/input/")
dbutils.widgets.text("output_path", "/mnt/data/output/")
dbutils.widgets.text("process_date", "2024-01-01")
# パラメータの取得
input_path = dbutils.widgets.get("input_path")
output_path = dbutils.widgets.get("output_path")
process_date = dbutils.widgets.get("process_date")
# パラメータを表示して確認
print(f"Input Path: {input_path}")
print(f"Output Path: {output_path}")
print(f"Process Date: {process_date}")
try:
# データの読み込み
print(f"Reading data from {input_path}")
df = spark.read.format("csv").option("header", "true").load(input_path)
# データのフィルタリング(例:process_dateに基づいてデータをフィルタ)
print(f"Filtering data for process_date: {process_date}")
filtered_df = df.filter(col("date") == process_date)
# 加工したデータの保存
print(f"Writing filtered data to {output_path}")
filtered_df.write.mode("overwrite").format("parquet").save(output_path)
print(f"ETL job completed successfully for {process_date}")
except Exception as e:
# エラーハンドリング:エラーが発生した場合はログを記録し、ジョブを失敗させる
error_message = f"ETL job failed: {str(e)}"
print(error_message)
dbutils.notebook.exit(error_message)
この章では、DatabricksでETLを作成・実行するための主な方法を紹介しました。各方法にはそれぞれ利点があり、プロジェクトの要件やチームのスキルセットに応じて適切なものを選択することが重要です。
17. AWSでデータレイクを構築することに対する比較
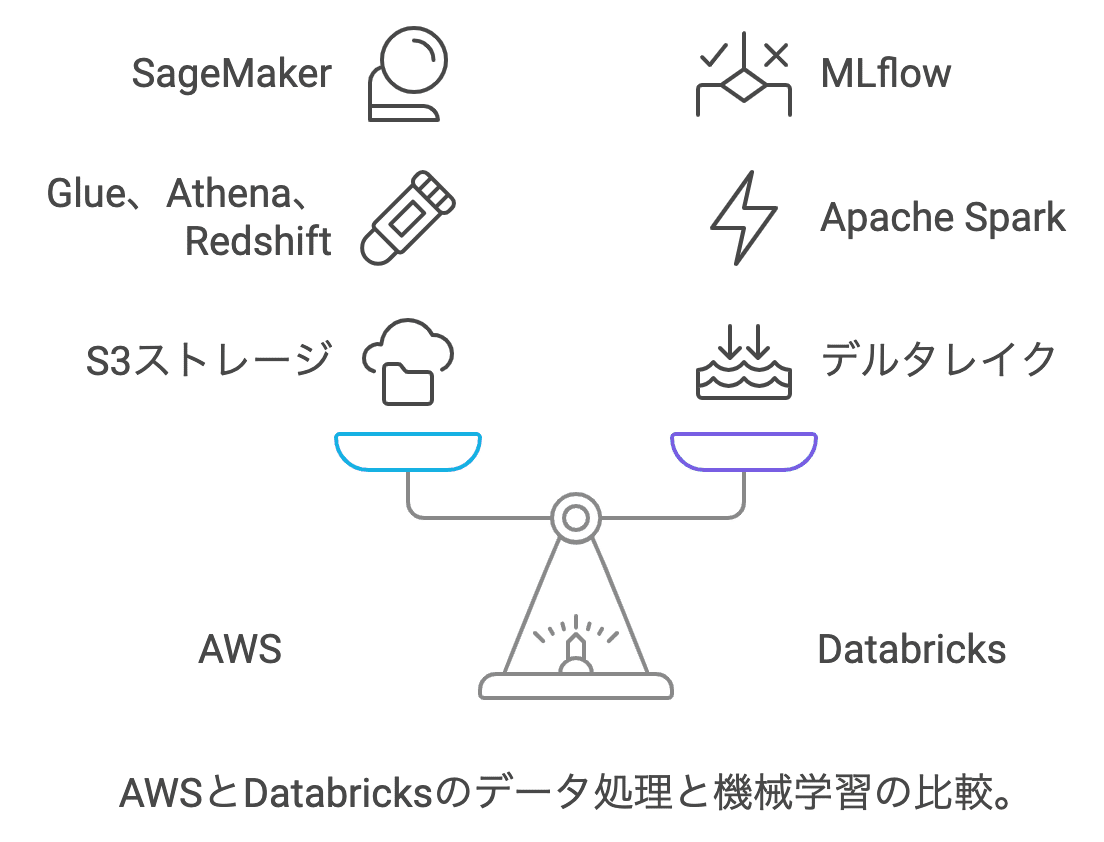
最後に、DatabricksとAWSでデータレイクを構築する場合の違いを比較します。Databricksは、データ処理と分析のために高度に最適化されたプラットフォームですが、AWSのネイティブサービスと比較することで、どちらがどのユースケースに最適かを理解できます。
AWSのデータレイク構築の特徴:
S3: 大規模データのストレージに最適で、低コストなデータレイクを簡単に構築できます。
Glue: データカタログとETLジョブを自動化するツールで、サーバーレス環境でのデータ変換が可能です。
Athena: S3に保存されたデータに対して、直接SQLクエリを実行できるサーバーレスのクエリサービスです。
Databricksの特徴:
高い処理能力: Apache Sparkに基づいた分散処理エンジンにより、大規模データの迅速な処理が可能です。
統合環境: データ処理、機械学習、分析を1つのプラットフォームで実行でき、ノートブックやワークスペースを活用したコラボレーションが容易です。
Delta Lake: ACIDトランザクションをサポートし、信頼性の高いデータ処理が行えます。
比較まとめ:
特徴AWSDatabricksストレージS3Delta Lakeデータ処理Glue(Apache Spark利用可)、Athena、RedshiftApache Sparkベース機械学習SageMakerMLflow統合データの整合性基本的なデータ処理(ETLが中心)ACIDトランザクションをサポートコスト柔軟な価格設定大規模データ処理に向いているがコスト高め
Databricksは、複雑なデータ処理や機械学習を必要とする大規模なプロジェクトに適しています。一方で、AWSのサービスは、シンプルなデータレイク構築や軽量なデータ処理に向いています。
両者を使い分けることで、ニーズに応じた最適なデータ基盤を構築できます。
以上で、Databricksを勉強してみる シリーズはひとまず終了です。 今回はAWSでデータ活用基盤を作成経験のある人向けにDatabricksでデータ活用基盤を作っていくための基礎知識の観点でブログを書いてみました。
実際はここに紹介していないテクニックもたくさんあります。 Databricksに触れる環境にある人は是非触り倒して理解を深めていただければ幸いです。 今後のプロジェクトで、ぜひDatabricksの強力な機能を活用してください。