
【徹底解説】ゼロから始めるClaude MCP

こんにちは。しまゆずです。
(今日は起業日記をお休みしてこちらを書いています。)
OpenAIやGoogleが、12月の新規発表でしのぎを削っている中、実はその裏でClaudeがとんでもない機能を打ち出していること、ご存知ですか?
今日は、ずぼらなあなたでもAIによってデータ管理が一瞬で出来てしまう魔法のような機能をお伝えします。
その名も
「モデルコンテキストプロトコル(MCP)」
です。
この記事ではこのMCPについての解説・使い方などについて触れていきます。設定の一手間がありますが、一度構築すれば、ずっと使える便利機能です。ぜひ、ブックマークして何度も読めるようにしておきましょう。
モデルコンテキストプロトコル(MCP)とは?
モデルコンテキストプロトコル(MCP)は、AIアシスタントとデータをつなぐための新しい仕組みです。この仕組みを使うと、コンテンツやビジネスツール、開発環境などの情報をAIに簡単に提供できます。これによって、AIがもっと便利で役立つ答えを出せるようになります。
生成AIとデータへのアクセス問題
生成AIのモデルの進化は著しく、直近でもChatGPTのGPT-o1-pro(月額3万円!)やGoogleのGemini 2.0 flashにアップデートされ賢くなりました。
しかし一方で、データに自律的にアクセスするのが難しいという問題があります。GoogleドライブやPC内のデータなど、私たちが選んで渡さないと、使えません。
MCPは、この問題を解決するために作られた共通のルール(プロトコル)です。これを使えば、AIがいろいろなデータに簡単にアクセスできるようになります。
MCPの例え話
MCPをスマートフォンの充電器を例に考えてみましょう。最近のスマートフォンの多くはUSB-Cという共通の差込口を使っていますよね(iPhoneもLightningから最近変わりました)。これのおかげで、メーカーが違うスマートフォンやPCでも同じ充電器が使えます。

ですので、MCPはこのUSB-Cポートのようなもの、と理解すればわかりやすいかと思います。
MCPの原理
図のように、ざっくり、MCPは以下のパーツで構成されています:
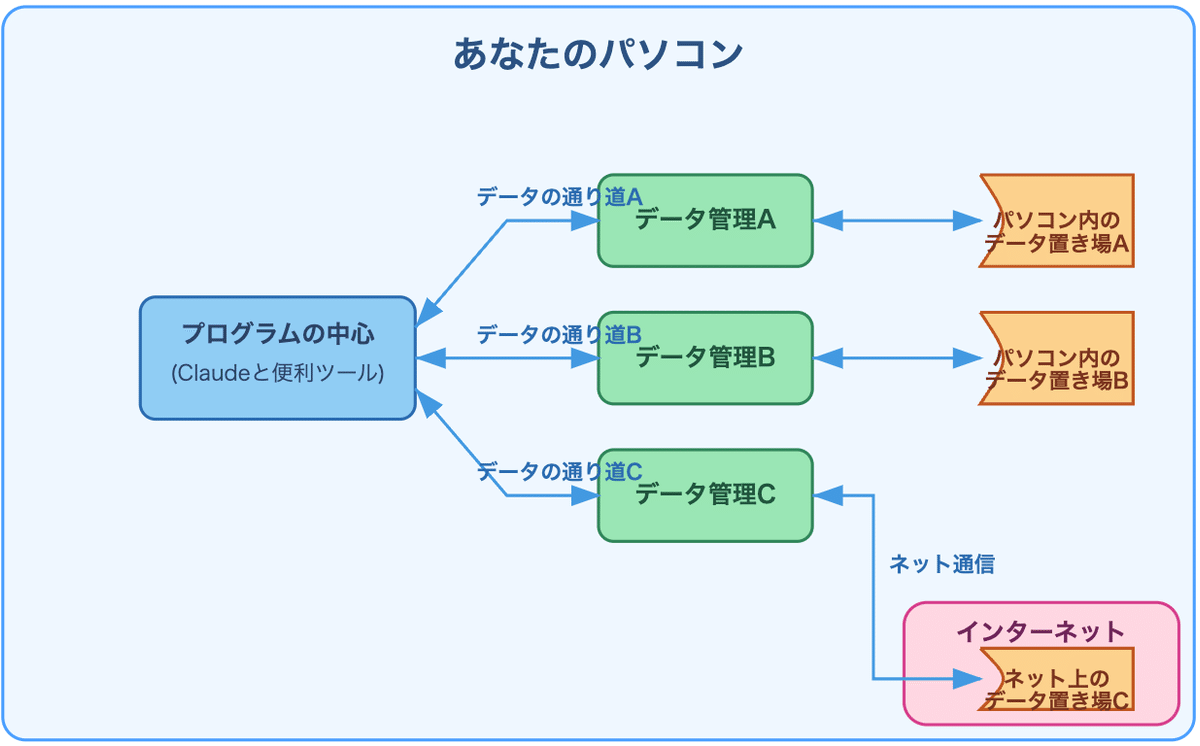
プログラムの中心(ホスト)
Claudeデスクトップアプリのように、MCPを通じてデータにアクセスするためのプログラム
データを管理する部分(サーバー)
必要な情報を整理して、安全に届ける係り
いくつかのグループ(A、B、C)に分かれて働く
データの置き場所(データソース)
パソコンの中にある情報(AとB)
インターネット上にある情報(C)
これらが双方向にアクセスできることによって、大規模言語モデル(LLM)であるClaudeに検索・分析だけでなく、ツール側のデータ格納・記入などが一挙に行えるようになった画期的なシステムなんです。
さらに、MCPはAIサービスがデータに安全にアクセスできるように設計されています。アクセス制御やセキュリティ機能が組み込まれており、機密性の高いデータも安心して利用できる仕組みが整っています(ただし、公式推奨以外のツール連携は自己責任となっています)。
MCPで出来ること
連携できる主なツール
MCPは、代表例として以下のツールやサービスと連携ができます。
Google Drive:AIアシスタントがGoogle Drive内のドキュメントやファイルに直接アクセスし、情報の取得・操作が可能です。
Slack:AIアシスタントがSlackのチャンネルやメッセージにアクセスし、コミュニケーションのサポートや情報抽出を行います。
GitHub:AIアシスタントがリポジトリのコードやドキュメントにアクセスし、コードレビューやドキュメント生成を支援します。
PostgreSQL:AIアシスタントがデータベースに接続し、クエリの実行やデータ分析を行います。
ローカルファイルシステム:AIアシスタントがユーザーのコンピュータ内のファイルやデータにアクセスし、情報の取得・操作を行います。
Brave Search:Braveの検索APIを使用したウェブおよびローカル検索を提供します。
これ以外にもたくさんのツールが公式にMCPで連携が可能なんです。
https://modelcontextprotocol.io/examples#productivity-and-communication
MCPを導入することで、Claudeはこれらのツールとシームレスに連携し、私たちの業務効率を高めることができるようになります。
MCPの始め方
それでは、MCPを活用するための基本的な手順を解説していきましょう。
Claude for Desktopのインストール:公式サイトからデスクトップアプリをダウンロードし、インストールします。
MCPサーバーの設定:必要なMCPサーバー(例:Filesystemサーバー)をインストールし、設定を行います。
設定ファイルの構成:Claude Desktopの設定ファイル(claude_desktop_config.json)にMCPサーバーの情報を追記し、接続を確立します。
ライブラリインストールと再起動:ターミナルまたはコマンドプロンプトでライブラリインストールおよびデスクトップ版Claudeの再起動を行います。
この4ステップを行うだけで、ローカルファイルや外部サービスと直接連携できる環境を構築できます。それでは一つずつ進めましょう。
1. デスクトップ版Claude立ち上げ
まずは、Web版ではなく、以下からアプリ版のClaudeをダウンロードしましょう(※)。
(※)サーバーは自分のPC内の環境(ローカル)で実行されるため、MCP は現在デスクトップのみをサポートしています。Google ChromeなどのWeb上でアクセスするリモートホストは現在開発中とのこと。
デスクトップ版Claudeを立ち上げたら、一番上のタブのHelpを押し、Enable Developer Modeをクリックします。
クリックすると、
(和訳)開発者モードを有効にすると、第三者があなたのコンピュータを変更したり、個人情報にアクセスしたりすることができるようになる可能性があります。特別な理由がない限り、有効にしないでください。
と聞かれるので、Enableを押します。
これで、Claudeの設定は完了しました。
ClaudeデスクトップタブにDeveloperが表示されれば成功です。
2. MCPサーバーの設定
次に、利用するツールをそれぞれ使えるようにしていきましょう。
以下のGitHubのページから、MCPで利用するツールを選択し、その中の
Usage with Claude Desktopからコピペします。
例えば、Filesystemを使いたければ、以下のページのリンクにアクセスして、READ MEの中にあるUsage with Claude Desktopのコードをコピペします。
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/username/Desktop",
"/path/to/other/allowed/dir"
]
}
}
}そして、コピーした上記のコードは、claude_desktop_config.jsonに貼り付けることになります。
また、Claudeに検索をさせたい!というときには、Braveというブラウザシステムも公式のMCPにありますので、こちらもおすすめです(後ほど触れます)。
{
"mcpServers": {
"brave-search": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-brave-search"
],
"env": {
"BRAVE_API_KEY": "YOUR_API_KEY_HERE"
}
}
}
}3. 設定ファイルの構成
コードをコピーしたら、デスクトップ版Claudeに戻り、Settingを開いて、貼り付け先のEdit Cnfigを開きます。
すると、自分のPCフォルダが開き、claude_desktop_config.jsonにカーソルが合っていることを確認して、開きます(右クリックでVScodeやCursorから開くと後々便利です)。
まだVScodeとCursorのアプリを持っていない、という方はこちらからDLしてください。いずれも無料から利用可能です。
最初に、claude_desktop_config.jsonファイルを開くと、以下のような画面になります。ここに、さきほどのコードをペーストします。

"/Users/username/Desktop", #usernameは自身のフォルダ名を利用してください(例 MaMacintoshHDまたはC:>ユーザ>ここの部分をコピペ)
"/path/to/other/allowed/dir" #これは今回なくても大丈夫ですが、複数フォルダアクセスの際はあると便利4. ライブラリインストール
ここまできたら、後一息。最後に、ライブラリのインストールを行います。
ターミナル(またはコマンドプロンプト)を開き、以下のコマンドを実行して、ファイルシステム用のMCPサーバーをグローバルにインストールします。これをそのままコピペしてください。
npm i -g @modelcontextprotocol/server-filesystemもし、Node.jsがインストールされていない人は、下記を参考にインストールしてください。
(Node.jsインストールまだの人用)必要なライブラリのインストール
MCPサーバーを利用するためには、Node.jsとnpm(Node Package Manager)のインストールが前提となります。
手順:
Node.jsとnpmのインストール
Node.js公式サイトからインストーラーをダウンロードし、インストールしてください。
インストール後、以下のコマンドでバージョンを確認します。
node -v
npm -vこれらのコマンドでバージョンが表示されれば、正常にインストールされています。
これでライブラリがインストール完了し、デスクトップ版Claudeを再起動すればOKです。
以下のようにMCP tool🔨マークが出れば成功です!
それでは使ってみましょう。
Prompt:ローカルPCにアクセスした上で、MARP形式のスライド作成し保存して。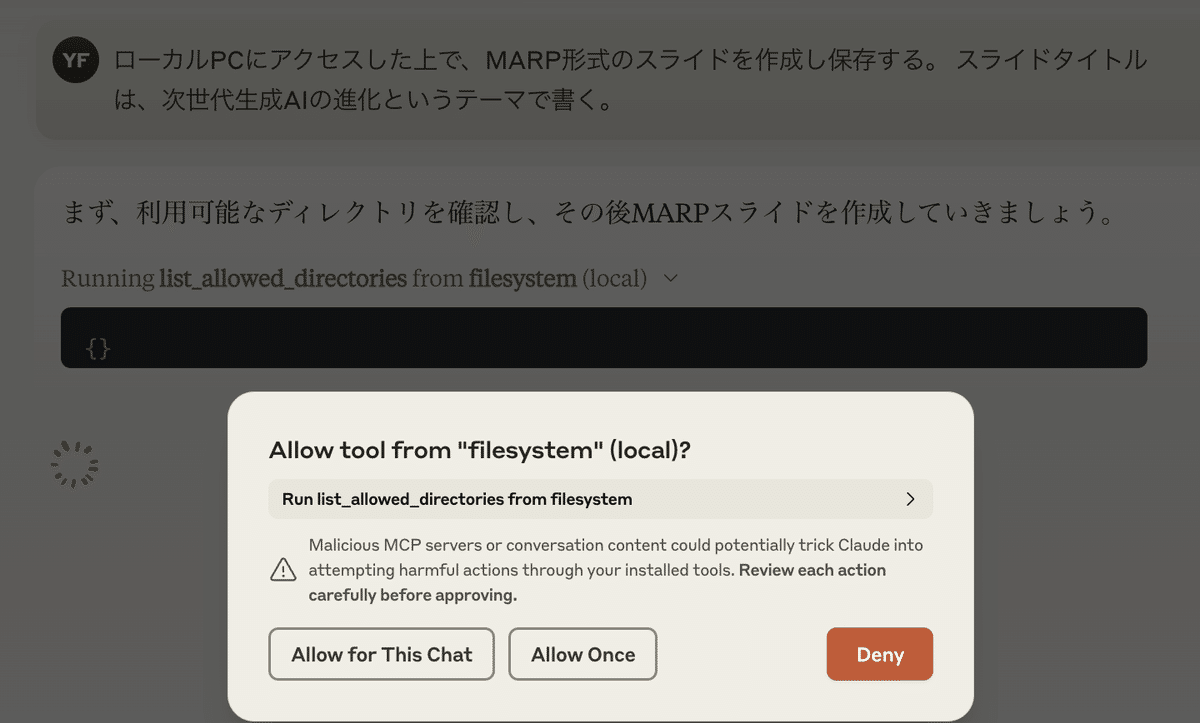
実際にできたものがこちら。
自分のPCに一瞬でスライドが保存されました。

MCPの実際
検索ブラウザと連携し最新情報取得
次は、ブラウザ検索ツールのBraveとの連携をしていきます。
BraveのAPIが必要になりますので、以下のリンクから登録を済ませてください。
API keyを作成するためにはクレジットカード登録が必要ですが、無料サブスクで十分ですので、Freeプランから申し込んでください。
次に、GitHubから、jsonファイルをコピーします。
"brave-search": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-brave-search"
],
"env": {
"BRAVE_API_KEY": "YOUR_API_KEY_HERE"
}
}2つ目以降は、mcpServersという項目が不要になります。そのため一部のコピーのみで問題ないのですが、どうしても階層やコードエラーが多くなるので、これはClaude自身に解決してもらいましょう。
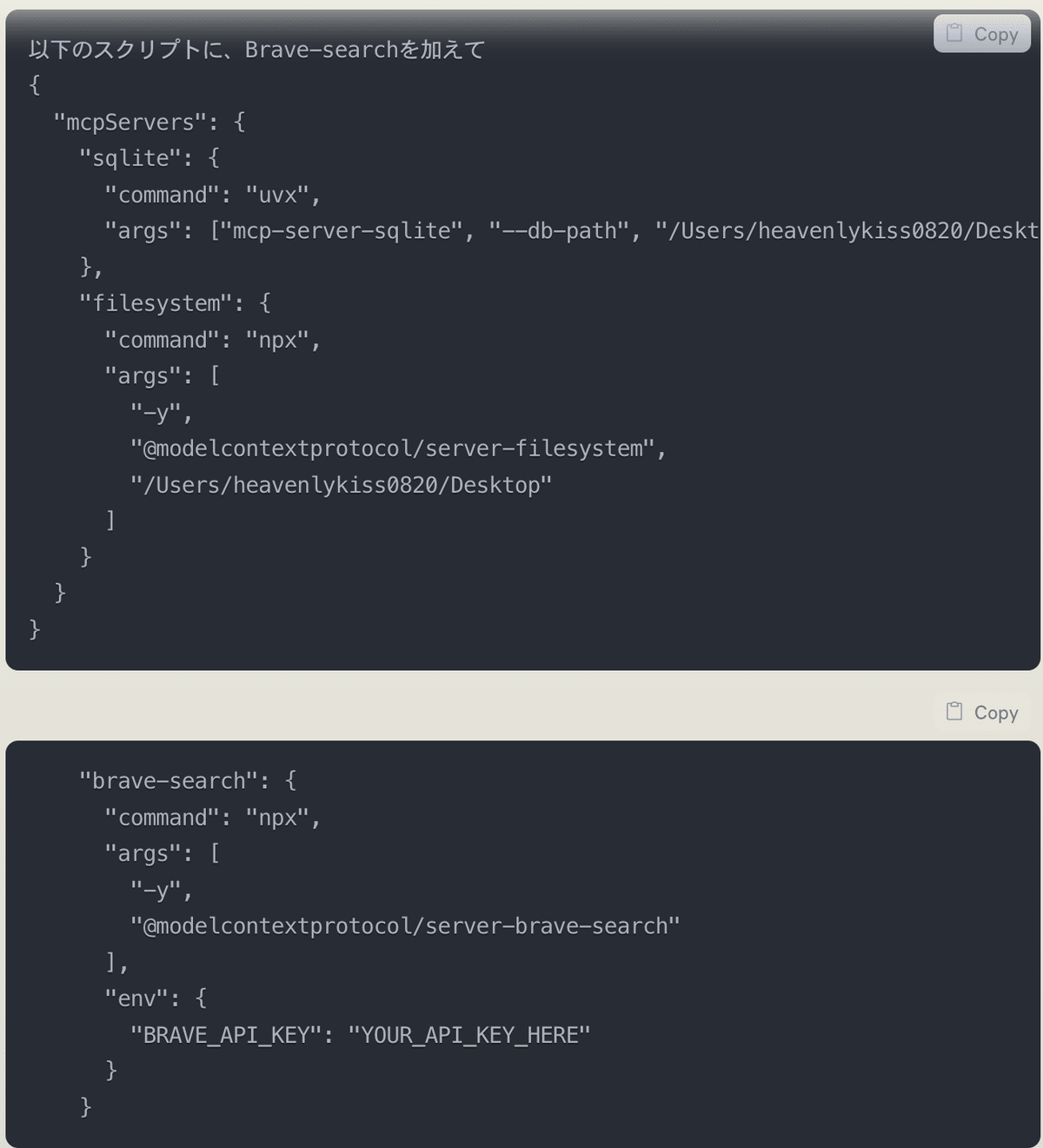
このように聞くと、整理されたスクリプトが完成します。
以下のように、Brave-searchを追加したスクリプトを作成します:
```json
{
"mcpServers": {
"sqlite": {
"command": "uvx",
"args": ["mcp-server-sqlite", "--db-path", "/Users/username/Desktop/test/test.db"]
},
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/username/Desktop"
]
},
"brave-search": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-brave-search"
],
"env": {
"BRAVE_API_KEY": "YOUR_API_KEY_HERE"
}
}
}
}
```
追加した設定の内容を確認しましょう:
- Brave-searchのサーバー設定を`mcpServers`オブジェクト内に追加
- `command`と`args`の設定を維持
- 環境変数`env`でBrave Search APIキーを設定できるように構成
この設定を使用する際は、`YOUR_API_KEY_HERE`の部分を実際のBrave Search APIキーに置き換える必要があります。それでは、利用した結果をご覧ください。本来学習データが2024年4月までのClaude 3.5 sonnetですが、最新の画像生成AIであるFLUX.1やRecraft V3を解説できています。

さらに深掘り
Braveを用いた検索システムを構築しましたが、そのほかにもGoogle Driveとの連携も可能です。
Google Drive連携でデータ取得
Google Cloud Project(GCP)を作成
Google Drive APIを有効化
OAuth設定
この順に進めることで、Google Driveとの連携も可能です。手順書は別途作成したのでリンクを参照してみてください。
さらに、notionとの連携も行っていきましょう。
こちらの記事を参考にしました。
検索精度がイマイチでしたが、notion側への保存ができていることを確認しました。

いかがでしたか?
やるまでのハードルは高そうですが、公式のGitHubもあるため、意外とすんなりいけます。
ただハマると、沼です(笑)
今回は「始めること」を中心に書きましたが、ぜひ色々と試してみてください。
私もまだ試していないツールがたくさんあるので、また続編でご報告しますね。
それでは!