【海外イベント紹介】The Jamstack and Your Data

今回は、「Prisma Day」で行われたプレゼンテーションから、「The Jamstack and Your Data」の内容をご紹介します!
オープンソースのORMサービスを提供するPrisma。
2022年6月、Prisma主催により、モダンアプリケーション開発とそのデータベースをテーマとする2日間のカンファレンスが行われました。
今回は、そこで行われたプレゼンテーションから「The Jamstack and Your Data」についてご紹介します。
NetlifyのCEOであるMathias Biilmann氏が「Jamstackが変えた、データとWebサービスの関係」について語ってくれました。
目次
Jamstackとは
Jamstackのエコシステム
データモデルの変革
データモデルの将来
まとめ
Jamstackとは
Jamstackという呼び名は
JavaScript
API
Markup
の、それぞれの頭文字に由来しています。
しかし現在では、技術というより、哲学やアーキテクチャを指すように進化しました。
「Jamstackって、単なる静的サイトジェネレーターの枠組みのことでしょ?」と考える方が、実は少なくありません。
しかし、それはJamstackの一つの側面に過ぎず、決してコアな部分ではありません。
Jamstackのコアな部分とは・・・
ランタイムにおいて、サーバーがほとんど(あるいはまったく)稼働しないことです。
サーバーの役割は、CDNから生成されたHTMLやCSS、JavaScriptをブラウザに渡してあげることだけ。
その後の処理は、すべてブラウザに移譲します。

従来の方法と大きく異なる点は・・・
処理がブラウザに移譲される前の段階=ビルド・ステップに注力できることです。
コードをできるだけ先に生成し、APIとの通信もできるだけ先に行っておくことで、その後がスムーズに処理されるようになります。
こうしたエコロジカルな仕組みが、パフォーマンス向上、ひいては最高のユーザー・エクスペリエンスにつながるのです。
Jamstackのエコシステム
従来型の構成の場合、開発者はこんなことを意識します。
サーバーは動いているのか?
どうやってアクセスするのか?
ロードバランサーは必要か?
アップデートの際にはもう一台用意して片方を落とすのか?
ソフトウェアは最新のものに更新されているのか?
など・・・悩みは尽きません。
サーバーに処理を投げる以上、これらの悩みから開放されることはないのです。
そこにJamstackというエコロジカルな仕組みが登場し、状況が一変!
Contentfulのようなサービス、Gatsbyのようなツールを通して、APIレイヤーの心配をする必要が無くなりました。
このアプローチで開発するなら、必要なリソースがいつでも使える状態にあるからです。
商品ページの例

例えば、よくある商品紹介ページ。
このページを生成するには、どうしたらよいでしょうか。
APIから下記のような情報を呼び出し、事前に商品紹介ページを生成しておく。
在庫管理
サイズのバリエーション
顧客からの星の数
価格
関連商品
2. その後の下記のような動的な処理にのみJavaScriptを使用する。
検索
おすすめ商品の紹介
このように、できるだけ事前にページを用意しておけば、動的な動きがスムーズに処理され、サクサクとした軽い動きをユーザーに体感してもらうことができます。
データモデルの変革
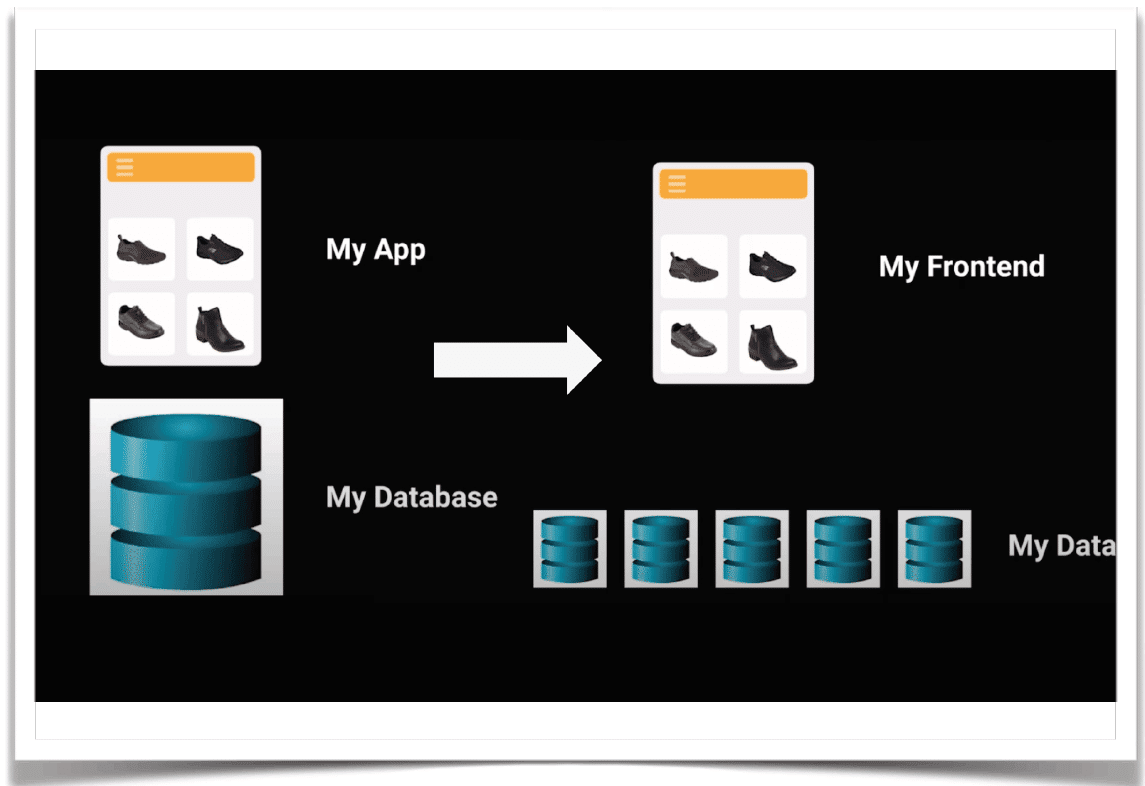
この変化は、データベースを構築する際の考え方に影響してきました。
従来の考え方:自前のアプリケーション、自前のデータベース
新しい考え方:自前のフロントエンド、自前のデータ(※データベースではない)
これまで開発者は、実際のプログラムやデータそのものよりも、
どんなデータベースを選ぶ?
どうやってバックアップを取る?
ディスクスペースをどれくらい割り当てる?
といったことに気を取られることが多かったのではないでしょうか。
しかし!
Jamstackではそのようなことを気にする必要がありません。
書き込むデータそのもの、そして、それらを取得する方法にだけ気を配ればよいのです。
このことは、「すべてのデータが一つのデータベースに格納されている」という、従来の考え方からの脱却を意味します。
データモデルの将来
しかし、新しい考え方にも欠点はあります。
サービスごとにデータが管理される(つまり、データの格納庫が分散する)ことで、データの断片化が生じるという点です。
例えば、商品情報のデータはShopifyに格納され、サブスクリプション情報のデータはStripeに格納される、といった具合です。

そこで期待されるのが、統一クエリレイヤーのような、バラバラに管理されているデータを横断的に問い合わせできるようにするためのサービスです。
例えば、TakeShapeは、ShopifyとContentfulに分かれているデータを、一つのレイヤーとしてGraphQLで取得できるサービスです。
これにより、一つのデータベースからデータを取得しているかのような操作性をユーザーに提供することができます。
このような流れが進んでくると、完全にJamstackで構成されたサービスには、自前のアプリケーションやサーバーが不要になります。
あるのはフロントエンドと各種APIだけ。データベースもサーバーも不要。データは各サービスに格納されるのです。
それらバラバラのデータをつなぎ合わせる方法は、今後どのように確立されていくのでしょう。
最終的には、そんなこと意識すらしなくて済むようになるのではないでしょうか。
近い将来、そんなふうに進化することに期待します!
まとめ
Jamstackの設計思想は従来のものと大きく異なります。
データが格納される箱ではなく、データそのものに注力を注いで開発できることは、質の高いアプリケーション開発に繋がることでしょう。
しかし、データの断片化という欠点があることも否めません。
例えば、Stripeで月額会員になっている人にShopifyの特定の商品を推薦するといった場合には、プログラム側でそれらをつなぎ合わせる必要があります。
このような手間をなくすための、統一クエリレイヤーのようなサービスが開発されつつあるのはうれしいことです。
まだ過渡期であるとは言え、サービスが確立されれば、Jamstackはより多くの開発者に支持される設計思想、仕組みとして認識されるようになるでしょう!
最後まで読んでくださり、ありがとうございました。
株式会社ヒューマンサイエンスは、他社にはない、「ドキュメント制作のノウハウ」×「最新のWeb開発技術(Jamstack)」を用いて、Webコンテンツとプラットフォームのソリューションをご提供します。
関心がある方は、ぜひこちらまでお問い合わせください!
株式会社ヒューマンサイエンス
https://www.science.co.jp/document/jamstack.html
本文書の出典元:https://www.youtube.com/watch?v=2E9yTIeMavg&t=1064s
この記事が気に入ったらサポートをしてみませんか?