AWS Glue DataBrewを早速試す

この記事はfreeeデータに関わる人たち Advent Calendar 2020の1日目です。
さて、2020年11月12日、AWS Glue DataBrewという新しいサービスが突然発表されました。即日で東京リージョンでも使えるようになっています。ジャンル的にはVisual Data Preparation Toolらしいですが、今回はこのDataBrewの使い勝手を試していこうと思います。GUIのツールなので気持ちスクショ多めでお届けします。
データセットの準備

AWSコンソールからGlue DataBrewにアクセスすると上記のような画面になります。サイドバーには"データセット"、"プロジェクト"、"レシピ"、"ジョブ"が並んでいます。軽く説明すると大体以下のような概念になります。
・データセット:一つのテーブル(あるいはDataframe)に相当。S3から直接読み込んだりRDS、Glue、Redshiftの既存テーブルに接続できる
・プロジェクト:レシピを作ったりデータのサンプルを眺めたりするインタラクティブセッション。ここでデータを眺めたりレシピを作る
・レシピ:各前処理ステップをまとめたもの
・ジョブ:データセットとレシピを元にGlueジョブを実行する
まずは何かしらのデータセットを作る必要があります。データセットタブで"新しいデータセットの接続"を押すと次のような画面が出るのでデータソースを選びます。今回は以下のデータセットを使わせてもらいました。

このデータセットは"Question"、"Answer"、"Tag"の3つのファイルに分かれているのですが、今回は試すだけなので"Question"と"Answer"だけ使います。
データセットを作ると、プレビューが表示されるのはわかりやすくていいです。
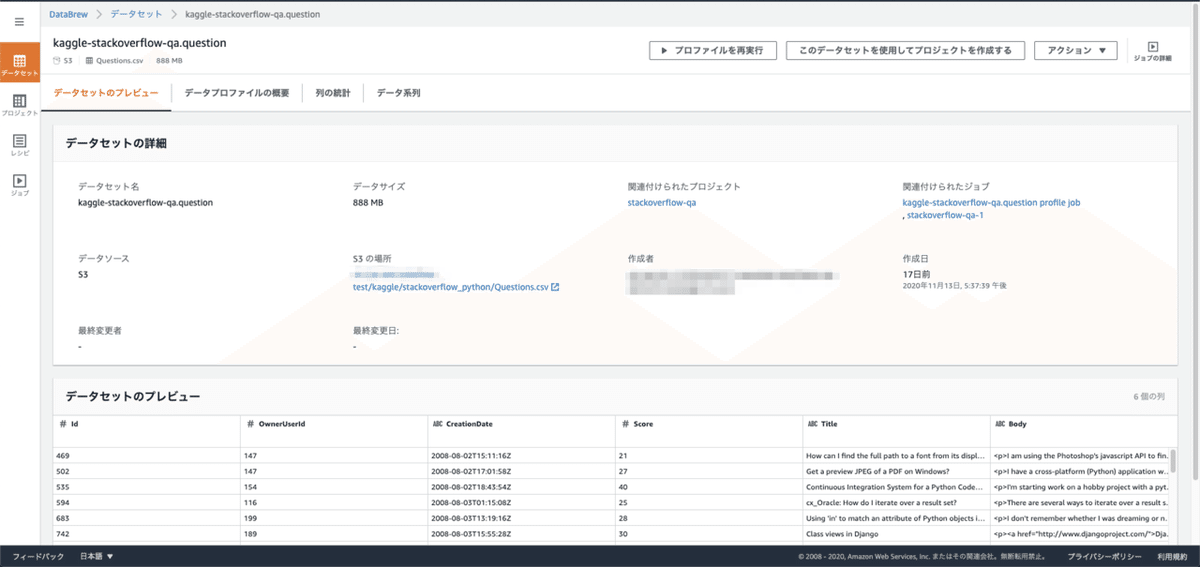
ここでプロファイルジョブと呼ばれる特別なGlueジョブを実行すると、データセットのサンプリングデータから統計を取ってくれます(ジョブの実行については後で説明します)。こんな感じです。

プロジェクトを作る
データセットを作ったので、それに対応するプロジェクトを作ります。プロジェクトには対応するレシピがあり、セットで作成されるようです。
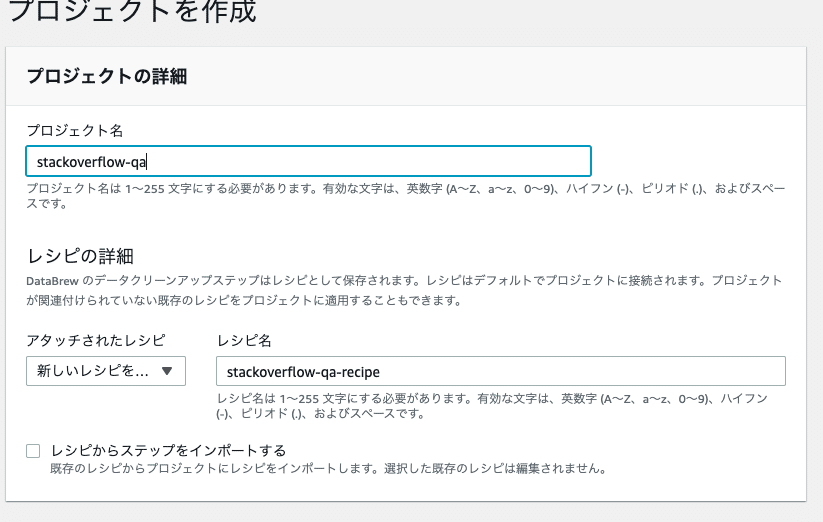
また、プロジェクトに必ず1つ、起点となるデータセットを紐付ける必要があります。

その他にはDataBrewが処理を実行するためのIAM Roleとサンプリングするサイズを指定します。IAM Roleはデータセットにアクセスできる権限が必要になるので注意です。サンプリング方法はデータセットの最初からn行、最後のn行、ランダムにn行、の3つから選ぶことが出来ます。

"プロジェクトを作成"ボタンを押すとセッションが起動します。約1分とありましたが、体感的には2分くらいかかっていたような気がします。このあたりはサンプルサイズにも依存しますし、既にレシピを作っている場合は途中の変換処理も挟まるので多少前後する感覚です。尚、セッションが起動するとお金がかかります(30分1ドル)。

レシピを作る

セッションを開くと上のような画面になります。データセットのテーブルのプレビューが大きく表示され、ヘッダには各カラムのサマリー情報が表示されています。
前処理を追加するにはツールバーを押すか、各カラム名の右側にあるボタンをおします。
さて、早速いくつか処理ステップを追加してみます。手始めに数値の正規化を試してみます。今選べる正規化オプションは次のものなようです。信頼区間でtruncate、みたいなちょっと凝った事ができるかな?と思って探してみましたが、割とまだシンプルな処理しか出来ないようです。

変更のプレビューを押すと処理内容がひと目で分かるのはとても便利です。

続いて、本文の文字列をキレイにしてみます。色んなオプションが有るようですが、今回はこんな感じの処理にします。

ここで、BodyカラムにHTMLのタグがあることが見えているので、このタグを削除しようと思います。
置換処理には正規表現も使えるらしいので、ざっくりとタグを取る処理を追加します。しかし空文字への置換は出来ないようで、仕方ないので半角スペースに置換してスペースを正規化する処理で面倒を見ることにします。

尚、正規表現ではパターンも使えるようです。下の画像は句点を切り離す例です。

さて、テーブルの結合(Join)も試してみます。ツールバーから結合を選ぶと、

データセットを選ぶ画面になります。データセットを選ぶと、

結合方式を選ぶ画面になります。where句のようなものは無いので、結合前後でフィルタする事になります。ここで結合後のプレビューが見られるのは良いですね。尚、"列リスト"タブで結合に含めるカラムを選択することが出来ます。

結合ステップを追加すると、データセットのビューにも結合後のカラムが見えるようになります。
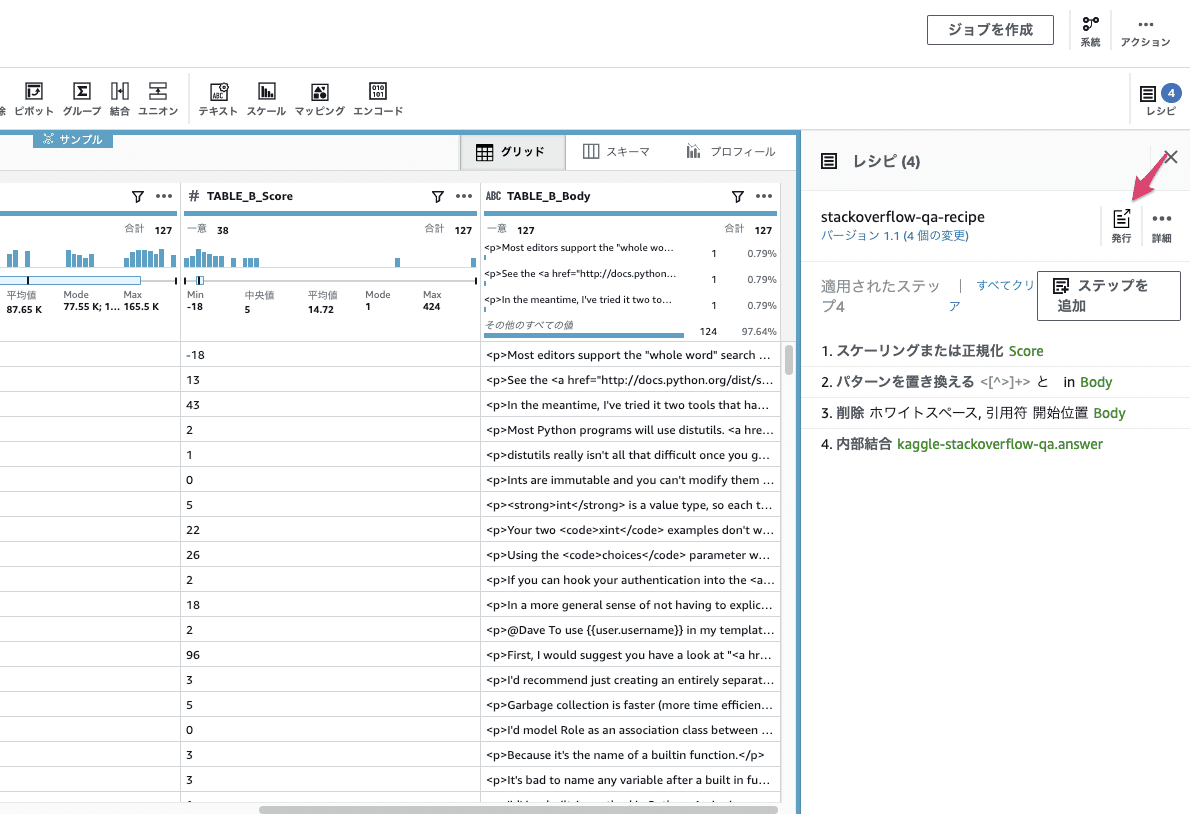
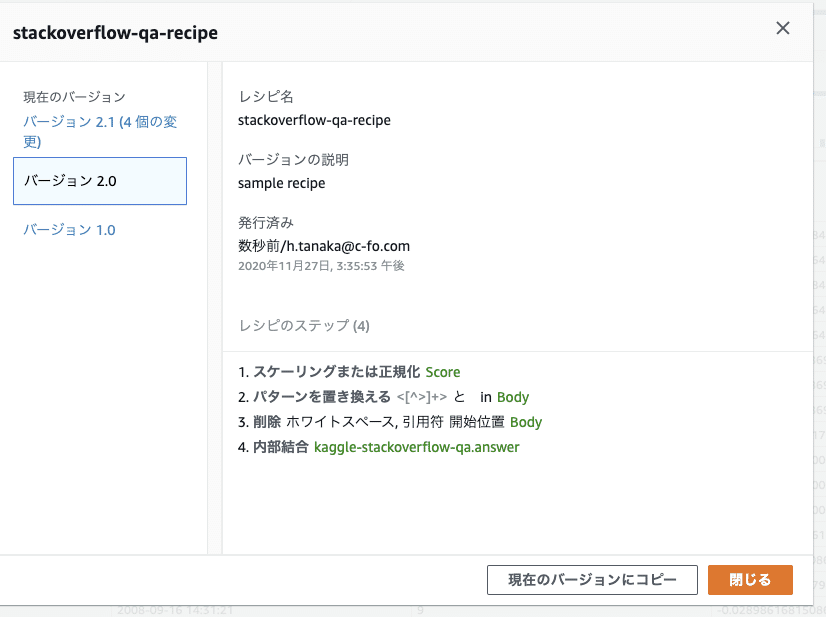
上の画像右上の発行ボタンを押すと、レシピのバージョニングが出来ます。過去のバージョンに切り戻したりといった操作も可能なようです。
ジョブを実行する
今まではサンプリングされたデータを使って処理を記述=レシピを作成してきました。このレシピを使って、データ全体に実際に処理を行う為にはジョブを作成します。先程のセッションの画面のレシピ→実行を押すか、サイドバーかのレシピ一覧からジョブを作成を押して、データセット、レシピ、出力先の組を選んで実行を押すだけです。裏側ではGlueのジョブが実行されているはずですが、その諸々を気にしなくて良いのはとても簡単で良いです。

今回作ったジョブは4分30秒で終わりました。ドキュメントを読む限りノードの最大数を指定することしか出来ず、実際にノードがいくつ立ち上がったのかわからないので感覚的に速いのか遅いのかよくわかりませんでした。また、ノード最大数を5にしても2にしても速度は変わりませんでした。

まとめ
AWS Glue DataBrew、たしかにデータの前処理に特化したサービスのようですが、UIがちゃんと作り込まれていて大きな可能性を感じるサービスでした。今回は触れませんでしたが、こうして作ったレシピをスケジュール実行する機能もあるのでデータ処理の自動化も簡単に出来ます。
今後の改善を期待して、記事執筆時点でのGoodポイントと今後への期待をまとめてみました。
Good
👍 データ処理を直感的に行える所。各処理ステップをプレビューしながら進められるので結果が想像しやすい
👍 一通りやりたいことがDataBrew上で完結する所。処理結果のスケジュール実行など、開発陣は自動化の面も考えてくれていそう
👍 Glueがバックエンドなので自由度が高そう。今はできることが少なめだが、今後の拡張に期待できる
今後への期待
😘 まだUIが結構不安定。執筆時点で以下の現象が確認された
・ステップ追加時、変更のプレビューをクリックしても動かない事がある
・ステップの編集時、ステップの内容が正しく反映された状態で開かないので元のステップが具体的にどういう内容だったかわからない事がある
・ジョブ実行履歴画面で違うジョブの履歴が一度だけ表示された
😘 UIがまだ出来たばかりなので機能が少なめ。例えばステップの順番を入れ替えたい、みたいな事は頻繁に起こると思うのだが、現状は入れ替えたいところまで消して再度作成するか、一度YAMLをダウンロードして編集し、aws cli経由で操作するしかなさそう
😘 使える関数が微妙に少ない。例えばテキストの削除でも正規表現を使いたくなるが、その選択肢が無いなど。ここらへんは言い出したらきりがないので今後に期待
😘 処理をIf-Then-Else的に書きたいことがある。このカラムの値がXだったら処理Yを行う、みたいな事がやりたいが、現状ではかなり大変。例えば、文字列長が10以下ならsmall、10-20ならmedium、30ならlargeというタグを振る、みたいな事が今は出来ない(LEN関数はあるが、数値の条件式が作れないのでおそらく無理。)パターンマッチ(例えばRust)のように処理を記述できると嬉しいのだが。
😘 ユーザー定義関数(スクリプト)が作りたい。用意されたステップだけではどうしても出来ないユースケースがあった時、後処理でEMRやGlueで別途処理しましょうみたいな事になってしまうと本末転倒になってしまう。すべての前処理をDataBrewで完結出来ないと本格的に利用するのは難しい。そのために少し複雑になっても構わないので拡張できる仕組みは必須だと思う
😘 複数ジョブを順番に走らせるような仕組み、あるいはマルチレシピなジョブが欲しい。DataBrewはデータセットにレシピを紐付けてジョブを実行する仕組みなのだが、大抵の機械学習や分析タスクだと複数のテーブルをJoinする事が多いと思う。現状でもメインのテーブル=データセットを選んだ上で結合を繰り返すレシピは作れるのだが、こうするとレシピの中のステップの再利用性が失われてしまう。特定のテーブルをクリーンにするジョブとクリーンになったデータセットを結合するジョブ、みたいに分けられると割とキレイだと思うのだがどうだろうか。
😘 権限管理について。このサービスはコンソールで作業することが多いはずだが、例えば複数チームで可視性をうまくコントロールしたい状況などでどう使うのが良いのか。タグを常に振ってもらう運用(指定し忘れが怖い)か、それともリソースにPrefixなりを付けてもらうか。AthenaのWorkgroupのようなグループ設定ができると嬉しい。
最後までお読みいただきありがとうございました。この記事を読んでみて気になった人は是非自分でもDataBrewを触ってみてはいかがでしょうか。
明日はnagomisoさんの採用関係の話だそうです。お楽しみに。
この記事が気に入ったらサポートをしてみませんか?