
顧客の購買行動を予測する!機械学習実践ガイド【AI,機械学習】【Rコード付】

この記事は、偏愛とマーケティング研究所がお届けする「小売店のためのデータ分析マガジン」に収録されています。隔週月曜に更新されていくのでぜひご覧ください。
今回の記事では、顧客の購買行動を予測できる機械学習の手法と応用例を丁寧に解説していきます。(最新のAIを使った手法も含む)
❶はじめに
機械学習とは何か

「機械学習とは何か」
正直これだけで2万字を超える記事が書けます。
しかし、これは今回の記事の本題ではないので概要が掴める程度に説明します。
機械学習
コンピューターによる学習。人工知能の一分野であり、人間がもつ学習能力と同じく、コンピューターも経験から学習し、将来予測や意思決定を実現できるようにする技術や手法をさす。マシンラーニング。
辞書には上記のように書いてあります。
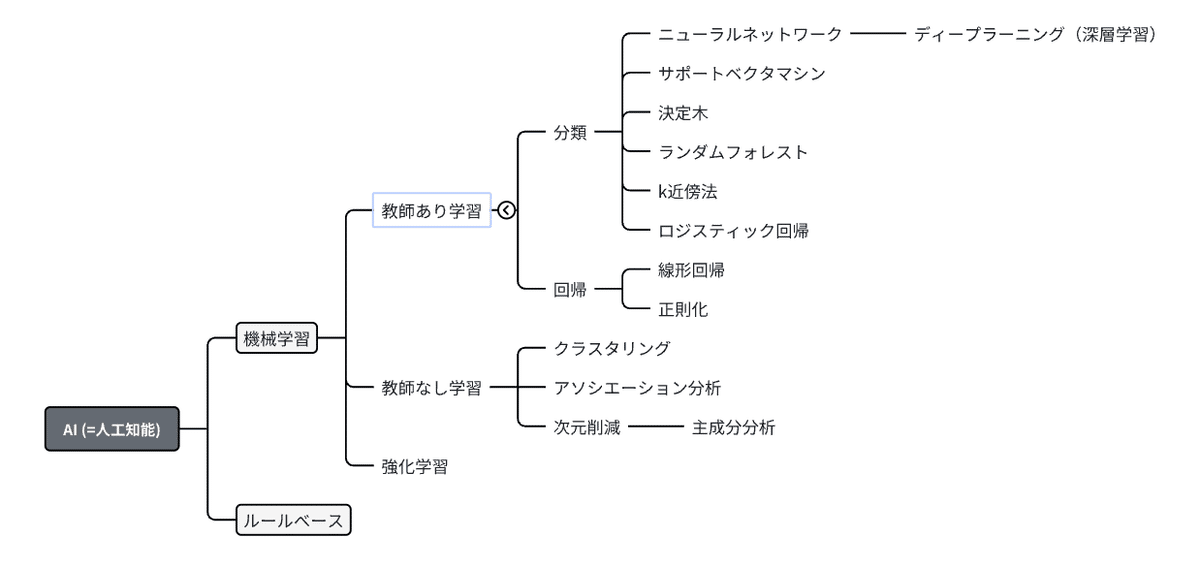
近年はAIブームも相まって「AI」「人工知能」「機械学習」「ディープラーニング」「ニューラルネット」などがごっちゃになってしまっている様子をよく目にします。これらを一旦整理しましょう。
最近よく耳にする「ChatGPT」や「Stable Diffusion」のような生成AIはAIの中でもディープラーニングを使った技術です。
AI = ChatGPTってなってる方多いですが、あくまで手法の1つです。
なぜこんなにも最近はChatGPTのようなものが有名になったのかというと、ニューラルネットを使った分類手法の精度が一気に向上したことが原因の1つになっています。(20年前はニューラルネットワークよりもサポートベクタマシンって手法の方が精度高いよねってなってたらしいです…)
そしてAI(=人工知能)はあくまで概念的なものであり、何か特定の手法を指しているものではありません。
ここまでの話をまとめると、機械学習とは「ディープラーニングを含んだもっと大枠の手法のことを指しており、AIという概念の中にある将来予測や意思決定を実現できるようにする技術や手法」ということになります。
(この辺り興味ある方教えてください。詳しく説明します。)
機械学習を使うことで、これまでルールベースで行われることが多かった顧客パターンの分類をもっと統計的に正しく分類することができます。
(「30代の女性の人は〜〜〜のはず」的な感覚的な分類とおさらばできます)
なぜ顧客行動の予測が重要なのか
小売業界において、顧客の購買行動を正確に把握することは何よりも重要な要素です。例えば、以下のようなものがあります。
在庫最適化
個別最適化した販促
季節や特定イベントに合わせた販促
顧客離反の早期防止
新規顧客の獲得
リソースの最適配分
競争優位性の確保
etc……
パッと思いつくだけでもこれだけ出てきます。
これらはなかなか機械学習以外で実現することは難しい内容です。
特に勘や経験に大きく左右されてしまいます。
確かに勘や経験も大切ですが、データに基づいた意思決定をすることで意思決定までのスピードを上げたり、より根拠を持った意思決定を行ったりすることができます。
❷機械学習の基本ステップ

機械学習を実践するにあたって、基本的には前回の記事にも書いたデータ分析の手順と進め方は同じです。まだ読んでいない方は是非こちらの記事も読んでください。
今回は「機械学習の基本ステップ」なので、上記の記事のSTEP6-7の部分に絞って紹介します。
STEP①:データの収集と整形
データ分析の中で最も重要なのがこのステップです。今回の機械学習を利用するときも、このステップがいかに正しく処理できているのかで結果が大きく変わってきます。
STEP②:特徴量の選択と作成
集められる全ての特徴量(例:性別, 購入金額, 購入頻度, 家族人数, 居住地, etc…)を扱うことはできないので、特徴量の選択をしなくてはなりません。どの特徴量が大きな影響を与えているのかを見極めます。特徴量の中に、相関係数が高い組み合わせがある(これを統計学では「多重共線性」と呼びます)と予測はうまくいかないことが多いので、どちらか一方に減らします。この中でどれを残すのかはドメイン知識(小売業界の専門知識)をフルに活用しなければならないのです。
STEP③:モデルの選択
今回結果として出力したいものが2値で表現できる(購入するorしない)のか、またはできない(次回の購入金額)のか。またどのような特徴量があるのかを加味してモデルの選択を行います。
モデルは有名なものだけでも、階層クラスタリング, 非階層クラスタリング, ニューラルネットワーク, ロジスティック回帰, 決定木, ランダムフォレスト, サポートベクタマシン, 線形回帰, etc…と様々あります。どれがいいのかは実際にデータを見てみないと分かりません。(なんなら全て実行してみてどれが良さそうなのか見てみることもザラにあります)
STEP④:モデルの学習〜チューニング
モデルの学習を行うのは、機械学習の中でも「教師あり学習」と呼ばれるものですが、教師あり学習では準備してある訓練データの一部を使ってモデルを学習させます。この過程で、モデルは入力されたデータと出力(予測したい結果)の関係性を学習します。その後、実際にテストデータを使ってどれくらい当てはまっているのかを確認しつつ、微調整を行い予測精度が上がるようチューニングを行います。
(微調整では、係数を変えたり特徴量を再選択したりします)
ちなみに、教師なし学習(階層クラスタリング, 非階層クラスタリング, etc…)でも似たようなことはします。うまくクラスタリング(グルーピング)できていなければ特徴量をチューニングすることもあります。
STEP⑤:予測と解釈
最終的に完成したモデルを使って、新しいデータに対しての予測を行います。そしてその予測結果から分かるようなことをドメイン知識を活かしながら解釈していきます。
❸実践例:リピート購入の予測
Excelにも基本的な分析機能はありますが、
今回のように予測にはあまり適していません。
そこで今回は無料の統計ツール「R」を使った方法を紹介します。

ここでは、架空の食品スーパー「フレッシュマート」を例に、
顧客のリピート購入を予測する方法を実践的に解説していきます。
もう少し具体的に以下のようなシナリオを設定します。
フレッシュマートでは、新しく導入した有機野菜シリーズの定期購入サービスについて、ある顧客がリピート購入するのかどうかを予測したいと考えている。
STEP①:データの収集と整形
まずは、必要なデータを収集します。
今回は以下の7つのデータを使用します。
顧客ID
年齢
性別
過去3ヶ月間の有機野菜の購入回数
過去3ヶ月の総購入金額
会員ランク(ゴールド、シルバー、ブロンズ)
リピート購入の有無 ←最終的にはこれを予測
続いては、データの整形を行います。
上記の7つの項目は以下の画像のようになっているのですが、量的変数(数字だけで表された列)と質的変数(文字列で表された列)が混在しており、このままではうまく処理することができません。

そこで、質的変数に関してはダミー変数に変換を行います。
ダミー変数の変換の仕方もいくつか種類があるのですが、
今回の会員ランク(ゴールド、シルバー、ブロンズ)のように順序構造があるものは、そのまま数値で置き換えるだけで問題ありません(ブロンズ=1, シルバー=2, ゴールド=3)。
また、性別も男性と女性の2パターンしかないので、
男性=0, 女性=1のように置き換えてしまいます。


上記のような整形を行うことで、全て量的変数(数字だけのもの)になりこれで準備万端です。
STEP②:特徴量の選択と作成
今回はそれほど変数(列の数と思ってもらえればOKです)が多くないので、減らしたりはせずに全て使いたいと思います。
したがってこのステップは飛ばします。
(変数が100を超えるようなことがあったりするので、そういった場合には変数を厳選します)
STEP③:モデルの選択
今回のゴールは「リピート購入の有無 」に対して0(=リピートなし)もしくは1(=リピート有)を出力することであり、このような2値の結果を予測するのに適している「ロジスティック回帰」というモデルを使用します。

ロジスティック回帰は、Excelに基本機能として搭載されていません。
ロジスティック回帰について詳しく理解してある方であればExcelを使って自分で関数を打ち込みながら実施できないこともないですが、あまりにも手順が増えてしまうので今回は無料の統計ツール「R」を使いたいと思います。
STEP④:モデルの学習〜チューンング
実際にモデルの学習〜チューニングに入っていくのですが、
まずは先ほど説明したRの実行環境を整えます。

Rのソフトをダウンロードしてもいいのですが、
Googleで「Googleコラボ」と検索すると、一番上に「Colaboratory」(以下Colabとする)というものが出てきます。最もRを手軽に使えるのがこのColabなので、今回はこちらを使うことにします。
(ColabはPythonやRを無料で、しかもブラウザ上で使える神ツールです)

「ランタイム」>「ランタイムのタイプを変更」>「ランタイムのタイプ」でPythonからRに変更します。
(Colab自体は元々Pythonがメインのツールです)
今からプログラミングっぽいことをしますが、
Excelで関数を入力するのとほとんど変わらないので、
最後までついてきてください。
まずはデータをColabで読み込むために、
以下の画像のようにコードを記入します。
(※データ・コードはこのページの一番下からダウンロードできます)

次は、トレーニングデータとテストデータに分けます。

機械学習に慣れていない方だとなぜ2つに分けるのかと疑問に思う方もいらっしゃると思うので、それぞれのデータの役割を簡単に説明します。
トレーニングデータ:法則を見つけるために使用する
テストデータ:法則が合っているのか確認するために使用する
この記事の最初の方に機械学習について説明しましたが、機械学習とは
「人間がもつ学習能力と同じく、コンピューターも経験から学習し、将来予測や意思決定を実現できるようにする技術や手法をさす。」と定義されています。この「経験から学習する」ためにトレーニングデータを利用します。
そして、学習したものが実際に合っているのかを確かめるためにテストデータを用いるのです。そのため元々手元にあるデータをトレーニングデータとテストデータに分割します。
これで、モデルで学習させるための準備は整ったので、
いよいよ学習させます。
トレーニングデータ(訓練データ)をもとに学習させるためには、
以下のような、たった数行のコードを書けば終了です。

コードの詳細を書き出すと難易度が上がるので、ここではあえて触れませんが、summary関数というものを使うとどの変数がどれくらい影響しているのか、また統計的に有意なのかを表示させることができます。この結果を見ながらチューニングを行うこともありますが、今回は統計的に有意なので手順をスキップします。
(この辺りの見方が気になる方はXかお問い合わせフォームで連絡ください)
STEP⑤:予測と解釈
さて、あとは以下のようにテストデータと照らし合わせて、
正答率を表示させるためのコードをちゃちゃっと書きます。

そうすると今回の正答率は88.67%となりました。
つまり、この結果から分かることは
ある顧客に対して、「年齢」「性別」「過去3ヶ月間の有機野菜の購入回数」「過去3ヶ月の総購入金額」「会員ランク」のデータがあれば、有機野菜をリピート購入するか否かを88.67%の精度で予測することができる
ということです。
ちなみに、どういった顧客が有機野菜をリピート購入するか否かは先ほどのsummary関数の出力内容を見ると分かります。
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.695e+01 1.524e+00 -11.128 < 2e-16 ***
顧客ID -6.091e-06 4.784e-04 -0.013 0.99
年齢 6.163e-02 1.058e-02 5.826 5.69e-09 ***
性別.ダミー変換. 3.777e+00 4.107e-01 9.196 < 2e-16 ***
過去3ヶ月間の有機野菜の購入回数 5.802e-01 6.778e-02 8.560 < 2e-16 ***
過去3ヶ月間の総購入金額 1.172e-04 1.029e-05 11.386 < 2e-16 ***
会員ランク.ダミー変換. 2.486e+00 2.503e-01 9.931 < 2e-16 ***summary関数で出力した結果の中でも、
顧客の情報がわかる部分を抜き出しました。
Estimate:各変数の係数
Std.Error:標準誤差
z value:z値
Pr(>|z|):p値
今回は上記のうち、Estimateの列だけを見ればOKです。
(正確には他の列も見なければいけませんが、今回は省略します)
まず初めに年齢ですが、年齢が1単位増加することで、リピート購入の係数が0.06163増加します。これは、年齢が高くなるほどリピート購入の可能性が高まることを示しています。
次に性別ですが、性別が女性であることで、リピート購入の係数が3.777増加します。つまり男性よりも女性の方がリピート購入に非常に大きな影響を与えていることを示しています。
次に過去3ヶ月間の購入回数ですが、購入回数が1回増えるごとに、リピート購入の係数が0.5802増加します。これは、過去3ヶ月間の購入回数が多いほど、リピート購入の可能性が高まることを示しています。
次に総購入金額ですが、総購入金額が1円増加するごとにリピート購入の係数が0.0001172増加します。これは小さな影響ですが、累積的にはリピート購入に対する有意な影響を持つことが示されています。
最後に会員ランクですが、会員ランクが1単位上がるごとに、リピート購入の係数が2.486増加します。会員ランクが高いほど、リピート購入の可能性が高まることを示しています。
まとめると、会員ランクが高い高齢女性で購入回数、購入金額ともに多いほど有機野菜のリピート購入率が高いことが分かりました。
会員ランクが高い高齢女性には、「購入金額は高いけれど、まとめ買いをするため購入回数は少ない」なんて顧客もいる可能性はありますが、それよりも同じような高齢女性の顧客であれば購入回数が多い方がいいということが分かります。
ここで、
「会員ランクが高い高齢女性で購入金額は高い、しかし購入回数は少ないような顧客に対して、購入回数を増やすような取り組みを行えば良い」と解釈すればいいのかというとそういうわけではありません。
因果関係が逆の場合もあるからです。
この辺りは、ドメインの知識と照らし合わせながら解釈することが大切です。
❹機械学習の応用例
今回はリピート有無の予測でしたが、機械学習を応用することでできることは多岐に渡ります。
商品レコメンデーション
アプリ等で表示される「あなたへのおすすめ」の部分顧客セグメンテーション
どのような顧客がいるのか把握するキャンペーン効果の予測
同時並行的に行なっているABテストの各施策に対する効果を測定需要予測と在庫最適化
過剰在庫や在庫不足を減らす顧客生涯価値(CLV)予測
顧客生涯価値を知ることで広告にかけることができる予算を算出画像認識を用いた商品管理
残りの在庫数をカメラで認識して自動的にセールを行う顧客離反予測
顧客離反可能性を数値化し離反防止に役立てるクロスセル・アップセル機会の特定
最適なタイミングクロルセル・アップセル訴求を行う売れ筋商品の早期発見
売れ筋傾向のある商品を早期発見することで在庫不足を減らす顧客の感情分析(レビュー、SNSなど)
レビューやSNSで顧客がどのような感情を持っているのか分析従業員のシフト最適化
手作業で行なっていたシフト作成を完全自動化。細かい条件等の反映も対応。
上記は機械学習でできるあくまでも一例です。
「こんなことできるの?」等ご質問あればお気軽に連絡ください。
(お問い合わせフォーム / X(旧Twitter))
❺注意点
ここまで紹介してきた通り機械学習を用いることで分かることはかなり多く、小売業に大きな可能性をもたらすことができます。
しかし、その導入と運用にはいくつか注意すべき点があります。
以下に主な注意点をまとめます。
データの品質と量の問題
機械学習に使用するデータは十分な量の高品質なデータが必要です。ここでいう「高品質なデータ」とは、正しく情報が反映されており、欠損が少ない、かつ最新で重複のない、追跡可能な情報のことです。
「データの整形」はデータ分析の中で一番時間がかかるのですが、これは高品質でないデータの場合は余計に時間がかかってしまいます。
人材の問題
機械学習の結果は、きちんと統計知識のあるデータサイエンティストやデータアナリストがいない場合、間違った解釈をしてしまう場合があります。
例えば、「予測モデルの精度が90%あってもデータに偏りがあった」なんてこともザラにあります。個人の趣味の範囲で機械学習を使うのであれば問題ないですが、実際のビジネスの現場で取り入れる場合はこのあたりの解釈はしっかりしておかなければ大事故に繋がりかねません。
ブラックボックス問題
ChatGPTなんかもこれが問題になっているのですが、機械学習の中には「どのような理由をもとにその結果が出力されたのか」が不明でブラックボックス化してしまっているものも存在します。そこで原因を知ることが目的であれば選択してはいけないモデルもありこの辺の適切な選択が重要です。
継続的な学習と更新
モデルはずっと同じものを半永久的に使えるものではなく、定期的に再学習・更新を行わなわなければ、トレンドが変わるにつれどんどん精度が落ちていきます。
❻まとめ
ここまで長々と説明してきましたが、機械学習の導入は、現代の小売業にとって避けては通れない重要な施策となってきています。
近年急成長を遂げているAmazon Goは、
もろに機械学習の技術を取り入れています。
また、スーパーのトライアルも機械学習の技術を取り入れています。
機械学習のメリットは、小売業界の様々な側面に及びます。
精度の高い需要予測により在庫を最適化たり、無駄なコストを削減したりできるだけでなく、顧客一人ひとりに合わせた個別最適化した体験を提供することで、顧客満足度を大きく向上させることもできるのです。
始めるためのアクションプラン

では、実際にどのように機械学習の導入を始めればよいのでしょうか。
まずは自社の現状分析から始め、課題を明確化します。
そこから、具体的で測定可能な目標を設定しプロジェクト選定を行います。(最初はquick winを狙える小規模なプロジェクトを選定するのがおすすめです)
それが終わると次は実際に、必要なデータの収集と品質向上に取り組み、内部人材の育成と外部のデータ分析の専門家の活用を通じて適切な体制を構築します。
確かに、機械学習の導入と言われても正直イメージが掴むのが難しいと思います。しかし、データサイエンティスト/アナリストが適切なプロジェクトの進め方を提示することで、機械学習の導入はかなりスムーズになります。
偏愛とマーケティング研究所は、これまで小売業者様と協力し、
機械学習導入の事例を積み重ねてきました。
貴社の独自の課題や目標について、ぜひ一度ご相談ください。
機械学習、データ分析の専門知識と小売業界への理解を基に、
貴社に最適なソリューションを提案させていただきます。
完全無料の初回相談で、機械学習を用いることで貴社のビジネスにどのような可能性があるのか、具体的にお示しします。
まずはお気軽にお問い合わせフォームまたはメール(info●henai-marketing.com ⚫️を@に変更してください)にてご連絡ください。
❼最後に:
偏愛とマーケティング研究所について
偏愛とマーケティング研究所は、
「1%の需要を満たす」データサイエンスカンパニーです。
これまでに、
スーパーマーケットの顧客分析
卸売の需要予測
コンビニの床の汚れ数値化
塾の顧客分析、生徒の成績予測etc…
を実施してきました。
小売はもちろんですが、それ以外の業態に関しても対応しておりますので
ご意見・質問等ある方はこちらのお問い合わせフォームよりお願いいたします。
❽データ&コードのダウンロードについて
今回使用したデータとコードを無料で公開しています。
以下の公式LINEを追加して、「機械学習」とだけ送信してください。
https://lin.ee/YYlS98e

📣お知らせ:
「小売店のためのデータ分析マガジン」
無料購読について
①noteアプリをスマホに入れてる方
この記事をnoteのアプリで見ていただいている方に関しては、以下の記事を読んでいただけるとプッシュ通知の方法が分かります。
②PCで読みたい/アプリを入れるのが面倒な方
以下の公式LINE(のうとみたかし🧠データ人材育成)を追加していただけると、記事更新のタイミングでLINEにお知らせします。(記事が更新される2週間に1度程度の通知になります)
また、公式LINEでは実際の分析手順を動画で紹介しているので、
少しでも興味がある方はぜひ以下のリンクから友達追加していただけると嬉しいです。

◤◢◤◢◤◢◤◢◤◢◤◢◤ ◢
🚨▼公式LINEを追加▼🚨
https://lin.ee/YYlS98e
◤◢◤◢◤◢◤◢◤◢◤◢◤ ◢
著者: 納富 崇 / NOTOMI Takashi (X: @takashi_notomi)
偏愛とマーケティング研究所 代表 / データアナリスト